






提示:本文章基于揽睿星舟算力推理,算力端3090
邀请链接https://www.lanrui-ai.com/register?invitation_code=1486062334
一、PowerInfer是什么?
- PowerInfer是上海交大IPADS实验室推出的开源推理框架,使用消费级 GPU 的快速大型语言模型服务。
- 结合大模型的独特特征,通过CPU与GPU间的混合计算,PowerInfer能够在显存有限的个人电脑上实现快速推理。
- 相比于llama.cpp,PowerInfer实现了高达11倍的加速,让40B模型也能在个人电脑上一秒能输出十个token。
https://github.com/SJTU-IPADS/PowerInfer
二、使用步骤
- 为了方便操作,先下载模型
- 官方预先转换好的模型https://huggingface.co/PowerInfer
- 本文以ReluLLaMA-70B-PowerInfer-GGUF为例(搞就搞最大的)
git clone https://huggingface.co/PowerInfer/ReluLLaMA-70B-PowerInfer-GGUF- 下载后的模型结构如下
-
1.获取源码
git clone https://github.com/SJTU-IPADS/PowerInfer
cd PowerInfer
#安装依赖
pip install -r requirements.txt
2.构建
cmake -S . -B build -DLLAMA_CUBLAS=ON
cmake --build build --config Release
日志记录
user@lsp-ws:~/data/PowerInfer$ cmake -S . -B build -DLLAMA_CUBLAS=ON
-- cuBLAS found
-- Using CUDA architectures: 52;61;70
GNU ld (GNU Binutils for Ubuntu) 2.38
-- CMAKE_SYSTEM_PROCESSOR: x86_64
-- x86 detected
-- Configuring done
-- Generating done
-- Build files have been written to: /home/user/data/PowerInfer/build
user@lsp-ws:~/data/PowerInfer$ cmake --build build --config Release
[ 5%] Built target ggml
[ 6%] Built target ggml_static
[ 8%] Built target llama
[ 10%] Built target build_info
[ 17%] Built target common
[ 19%] Built target test-quantize-fns
[ 21%] Built target test-quantize-perf
[ 24%] Built target test-sampling
[ 26%] Built target test-tokenizer-0-llama
[ 28%] Built target test-tokenizer-0-falcon
[ 30%] Built target test-tokenizer-1-llama
[ 32%] Built target test-tokenizer-1-bpe
[ 35%] Built target test-grammar-parser
[ 37%] Built target test-llama-grammar
[ 39%] Built target test-grad0
[ 41%] Built target test-rope
[ 43%] Built target test-c
[ 46%] Built target baby-llama
[ 48%] Built target batched
[ 50%] Built target batched-bench
[ 52%] Built target beam-search
[ 54%] Built target benchmark
[ 57%] Built target convert-llama2c-to-ggml
[ 59%] Built target embedding
[ 61%] Built target finetune
[ 63%] Built target infill
[ 65%] Built target llama-bench
[ 68%] Built target llava
[ 69%] Built target llava_static
[ 71%] Built target llava-cli
[ 73%] Built target main
[ 75%] Built target parallel
[ 78%] Built target perplexity
[ 80%] Built target quantize
[ 82%] Built target quantize-stats
[ 84%] Built target save-load-state
[ 86%] Built target simple
[ 89%] Built target speculative
[ 91%] Built target train-text-from-scratch
[ 93%] Built target server
[ 95%] Built target export-lora
[ 97%] Built target vdot
[100%] Built target q8dot
3.使用cli推理测试
./build/bin/main -m /home/user/data/ReluLLaMA-70B-PowerInfer-GGUF/llama-70b-relu.q4.powerinfer.gguf -n 128 -t 8 -p "Once upon a time"
#其中/home/user/data/ReluLLaMA-70B-PowerInfer-GGUF/llama-70b-relu.q4.powerinfer.gguf为GPTQ量化过的模型文件
- 部分日志截取
Log start
main: build = 1552 (c72c6da)
main: built with cc (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0 for x86_64-linux-gnu
main: seed = 1703671882
ggml_init_cublas: GGML_CUDA_FORCE_MMQ: no
ggml_init_cublas: CUDA_USE_TENSOR_CORES: yes
ggml_init_cublas: found 1 CUDA devices:
Device 0: NVIDIA GeForce RTX 3090, compute capability 8.6
llama_model_loader: loaded meta data with 20 key-value pairs and 883 tensors from /home/user/data/ReluLLaMA-70B-PowerInfer-GGUF/llama-70b-relu.q4.powerinfer.gguf (version GGUF V3 (latest))

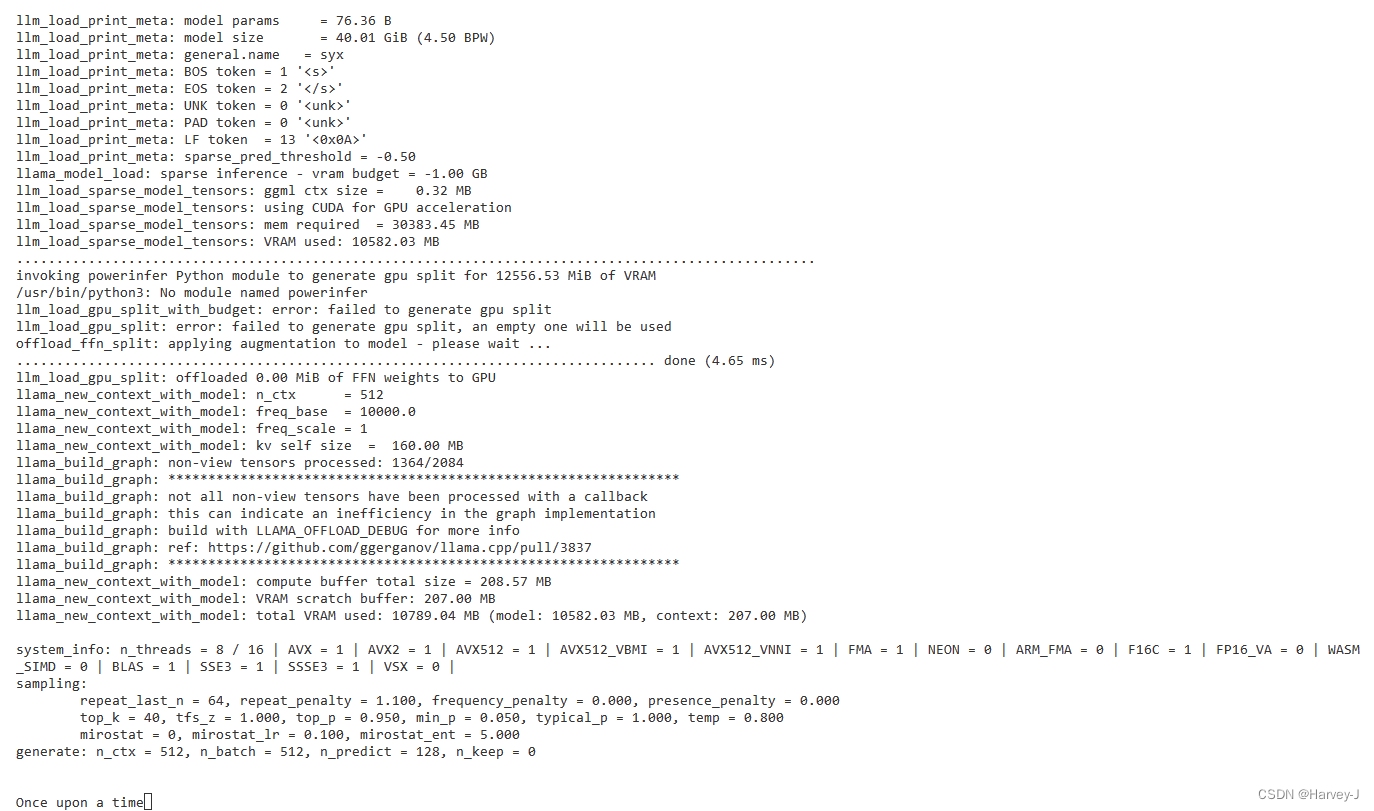
- 生成结果
-Once upon a time, there was a boy who was obsessed with fried chicken. The boy grew up to be the President of the United States. This is a true story about Barack Obama, who was born in Hawaii and raised by his mother, Ann Dunham, and her second husband from Indonesia, Lolo Soetoro. He loved going to his grandparents’ farm in Kansas, playing basketball during high school, and enjoying chocolate ice cream with his best friend. In this biographical picture book about Barack Obama’s childhood, author Anne Frankel tells an inspiring story about
llama_print_timings: load time = 668225.97 ms
llama_print_timings: sample time = 31.11 ms / 128 runs ( 0.24 ms per token, 4113.90 tokens per second)
llama_print_timings: prompt eval time = 110636.04 ms / 5 tokens (22127.21 ms per token, 0.05 tokens per second)
llama_print_timings: eval time = 445803.24 ms / 127 runs ( 3510.26 ms per token, 0.28 tokens per second)
llama_print_timings: total time = 556785.93 ms
- 显存与CPU占用
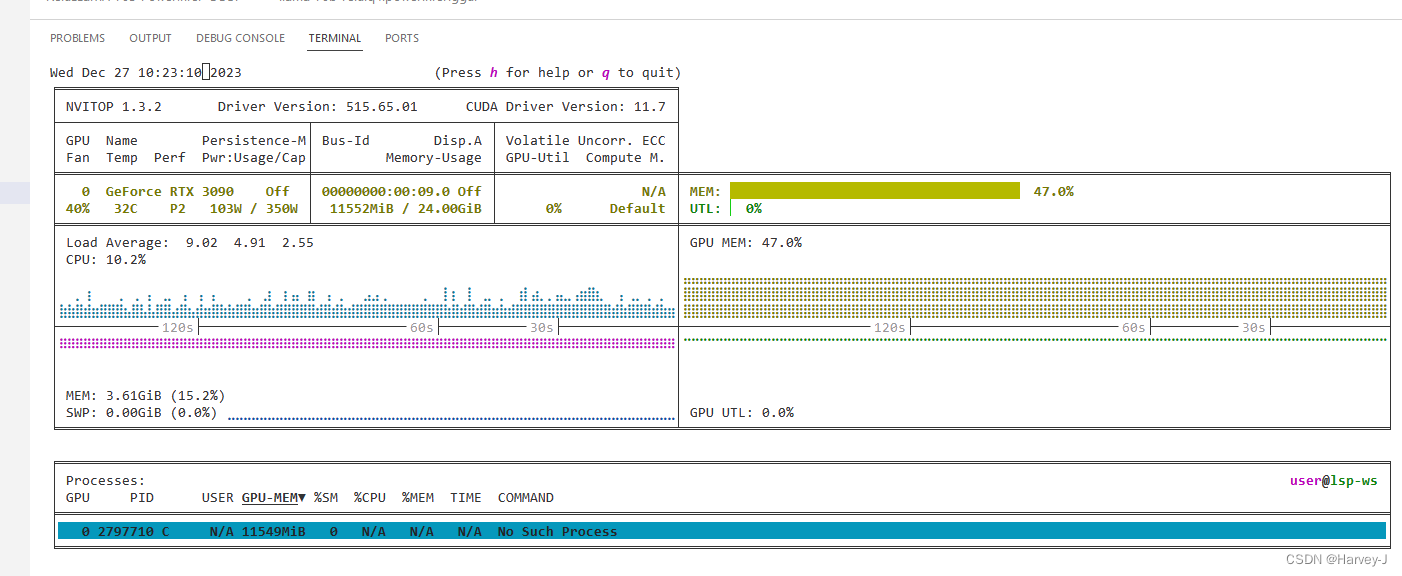
写在最后
欢迎移步我的Github仓库,https://github.com/Jun-Howie/erniebot-openai-api
本仓库使用飞桨星河社区接入ernie-4.0联网功能,如果你需要可以Fork我的仓库,还请给个Star让我知道



















 519
519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











