







Java NIO初探
这篇文章是学习了NIO之后的总结,结合了网上的博客和资料
- 简述:在软件系统中,由于I/O的速度远比内存速度慢,所以I/O很容易成为系统的瓶颈。何为NIO,其实就是New IO的简称,与旧式基于流的I/O相对。
NIO与IO的区别,NIO的特性
- NIO以块(Block)为基本单位处理数据,而IO是以最基础的字节流的形式去写入和读出。由于处理方式的不同,所以在效率上的来讲,NIO效率会比IO效率高出很多。
- NIO不在是和IO一样用OutputStream和InputStream 输入流的形式来进行处理数据的,但是又是基于这种流的形式,为所有的原始类型提供Buffer缓存支持和新增Channel通道对象支持来进行处理数据。
- NIO的通道是双向的,既可读又可写,而IO中的流只能是单向的。
- NIO提供了基于Selector的异步网络I/O,即是多路复用的IO模型,而普通的IO用的是阻塞的IO模型,效率方面多路复用效率更高
两点特性
- 新增Java.nio.charset.Charset作为字符集编码解码解决方案
- 支持锁和内存映射文件的文件访问接口
最重要的两个组件:通道Channel和缓冲Buffer
通道Channel
- 通道是对原 I/O 包中的流的模拟。到任何目的地(或来自任何地方)的所有数据都必须通过一个 Channel 对象(通道)。Channel是一个双向通道,既可读,又可写,拿来与原来的I/O相比,即类似于Stream流,但是Stream是单向的。
- 应用程序不能直接对Channel进行读写操作,必须通过Buffer。比如在读一个Channel的时候,需要将数据读到相应的Buffer,然后从Buffer中读取。在写操作时永远不会将字节直接写入通道中,而是将数据写入包含一个或者多个字节的缓冲区。
缓冲Buffer
- 在NIO中,所有数据都是用缓冲区处理的。在读取数据时,它是直接读到缓冲区中,在写入数据时,它是写入到缓冲区中。任何时候访问 NIO 中的数据,都是将它放到缓冲区中。
- 缓冲区实际上是一块连续的内存,是NIO读写数据的中转地。在代码上缓冲区实质上是一个数组,通常它是一个字节数组,但是也可以使用其他种类的数组。但是一个缓冲区不仅仅是一个数组,它还提供了对数据的结构化访问,以及跟踪系统的读/写进程。
- 通道表示缓冲数据的源头或者目的地,用于向缓冲读取或者写入数据,是访问缓冲的接口,关系下图:
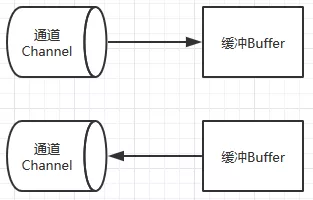
使用实例
- 下面是一个文件复制的例子,展示了NIO的基本使用操作
// 1. 获取数据源和目标传输的输入输出流,此处用文件作为传输流
File source = new File("E:/study/test/source.txt");
File target = new File("E:/study/test/target.txt");
FileInputStream fis = new FileInputStream(source);
FileOutputStream fos = new FileOutputStream(target);
// 2. 获取数据源的输入输出通道
FileChannel fisc = fis.getChannel();
FileChannel fosc = fos.getChannel();
// 3. 创建缓冲区对象
// 方法1:使用allocate()静态方法
ByteBuffer buffer = ByteBuffer.allocate(1024);
// 上述方法创建1个容量为1024字节的ByteBuffer
// 方法2:通过包装一个已有的数组来创建
// 注:通过包装的方法创建的缓冲区保留了被包装数组内保存的数据
// ByteBuffer buffer = ByteBuffer.wrap(new byte[1024]);
// 额外:创建buffer时若需将1个字符串存入ByteBuffer,则如下
// String sendstr = "测试文字";
// ByteBuffer buffer = ByteBuffer.wrap(sendstr.getBytes(StandardCharsets.UTF_8));
while (true){
// 4. 从通道读取数据 & 写入到缓冲区
// 注:若已读取到该通道数据的末尾,则返回-1
int read = fisc.read(buffer);
if (read == -1) {
break;
}
// 5. 传出数据准备:将缓存区的写模式 转换->> 读模式
buffer.flip();
// 6. 从Buffer中读取数据 & 传出数据到通道
fosc.write(buffer);
// 7. 重置缓冲区
// 目的:重用现在的缓冲区,即 不必为了每次读写都创建新的缓冲区,在再次读取之前要重置缓冲区
// 注:不会改变缓冲区的数据,只是重置缓冲区的主要索引值
buffer.clear();
}
// 关闭通道和流
fosc.close();
fisc.close();
fos.close();
fis.close();
System.out.println("完成");
底层工作原理(这里主要讲Buffer)
Buffer有三个重要参数,分别如下
- 写模式
- position位置:当前缓冲区的位置,将从position的下一个位置写数据
- capactiy容量:缓冲区的总容量上限
- limit上限:缓冲区的实际上限,他总是小于或者等于容量
- 读模式
- position位置:当前缓冲区读取的位置,将从此位置后,读取数据
- capactiy容量:缓冲区的总容量上限
- limit上限:代表可读取的总容量,和之前写入的数据量相等
用一个使用buffer的例子讲解
System.out.println("+++++++test begin+++++++");
// 创建一个15字节大小的缓冲区
ByteBuffer buffer = ByteBuffer.allocate(15);
System.out.println("position=" + buffer.position() + ",capacity=" + buffer.capacity() + ",limit=" + buffer.limit());
// 放入10个字节数据
for (int i = 0; i < 10; i++) {
buffer.put((byte) i);
}
System.out.println("position=" + buffer.position() + ",capacity=" + buffer.capacity() + ",limit=" + buffer.limit());
// 重置position
buffer.flip();
System.out.println("position=" + buffer.position() + ",capacity=" + buffer.capacity() + ",limit=" + buffer.limit());
// 取5个字节数据
for (int i = 0; i < 5; i++) {
System.out.print(buffer.get());
}
System.out.println("\nposition=" + buffer.position() + ",capacity=" + buffer.capacity() + ",limit=" + buffer.limit());
// 重置position,剩余的5个字节数据会移动到0下标开始,读操作最多只能读到limit的位置,超过limit位置则会报错
buffer.flip();
System.out.println("position=" + buffer.position() + ",capacity=" + buffer.capacity() + ",limit=" + buffer.limit());
System.out.println("+++++++test end+++++++");
- 首先分配15个字节的缓冲,p=0,c=15,l=15
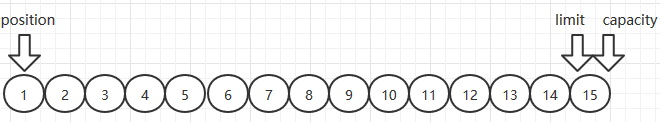
- 接着Buffer中被放入了10个byte,因此p向前移动,因为p位置指向当前缓冲区的位置,所以p=10,c和l不变
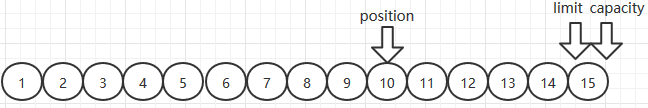
- 接着执行flip()操作。该操作会重置p。通常,将Buffer从写模式转换为读模式时需要执行此方法。flip()操作不仅重置了当前的p=0,还将limit设置到p的位置,这样做是防止在读模式中,读到应用程序根本没有操作的区域
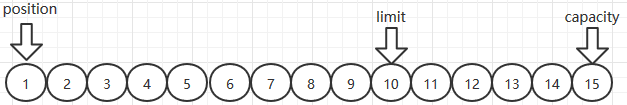
- 接着执行5次读操作,和写操作一样,读操作也会设置p到当前位置
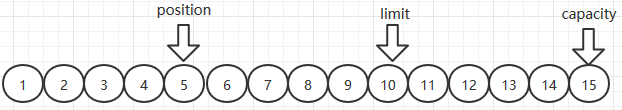
- 最后执行flip(),p归零,limit设置到position的位置
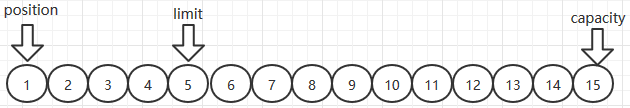
Buffer的相关操作
- 标志缓冲区:标志mark缓冲区是一项在数据处理时很有用的功能,它就像书签一样,在数据处理过程中,可以随时记录当前位置。在任意时刻,回到这个位置,从而加快和简化数据处理流程。主要方法为:
- mark():记录position的当前位置
- reset():恢复到mark所在的位置
- 重置和清空缓冲区
- rewind():将position置零,并清除标志位mark,它的作用在于为提取Buffer的有效数据做准备
- clear():将position置零,同时将limit设置为capacity的大小,并清除标志位mark。由于清除了limit,就无法得知Buffer内哪些数据是真实有效的,该方法用于为重新写Buffer做准备
- flip():先将limit设置到position的位置,然后将position置零,并清除标志位mark,用在读写转换时使用
- 读/写缓冲区:比如get(),put()等方法
- 复制缓冲区:以原缓冲区为基础,生成一个完全一样的新缓冲区,用duplicate()。这个函数主要用于处理复杂的Buffer数据,因为新生成的缓冲区和原缓冲共享相同的内存数据,并且一方的数据改动都相互可见,但两者又独立维护了各自的position、limit、mark,增加了灵活性
- 缓冲分片:slice(),在现有缓冲区中,创建新的子缓冲区,子缓冲区和父缓冲区共享数据。这个方法有助于将系统模块化。当需要处理一个Buffer的一个片段时,可以使用slice()方法获得一个子缓冲区,然后就像处理普通缓冲区一样处理,无需考虑缓冲区的边界问题
- 只读缓冲区:用asReadOnlyBuffer()方法得到一个与当前缓冲区一致的,并且共享内存数据的只读缓冲区。只读缓冲区对于数据安全非常有用,当缓冲区作为参数传递给某对象的某个方法时,由于无法确定该方法是否会破坏缓冲区的数据,此时,使用只读缓冲区可以保证数据不被修改。同时,因为只读缓冲区和原始缓冲区是共享内存块的,因此对原始缓冲区修改,只读缓冲区也同样可见
- 文件映射到内存:使用FileChannel.map()















 5704
5704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









