







企业黄页:每个企业联系方式,主要业务等。
存在意义:找到所需信息
百度等:收集这些信息,以便用户搜索。而百度是自动24小时不间断爬取每个链接第相关信息,遇到一个链接再打开页面中的连接,拿到这个页面的简介,标题,链接等,叫外链。跳转到别的网页后再搜别的网页的关键字等。跳着跳转就永远停不下来,源源不断的查。蜘蛛网很多蚊子,把蜘蛛放到网上,最终把蚊子全吃了。目的是自动获取想要的信息,省去了人为的查找。
今日头条,抽屉,自动获取资讯,然后分类。把别的网站拿到数据库,然后点击相关数据连接到别的网站。
如:
爬取汽车之家资讯的信息
- 通过代码伪造浏览器访问给定网站。
import requests
response = requests.get('https://www.autohome.com.cn/news/') # 通过代码伪装浏览器发送get请求,拿到结果
response.encoding = 'gbk'
print(response.text) # 查看响应体
运行结果

2. 分析要提取的数据
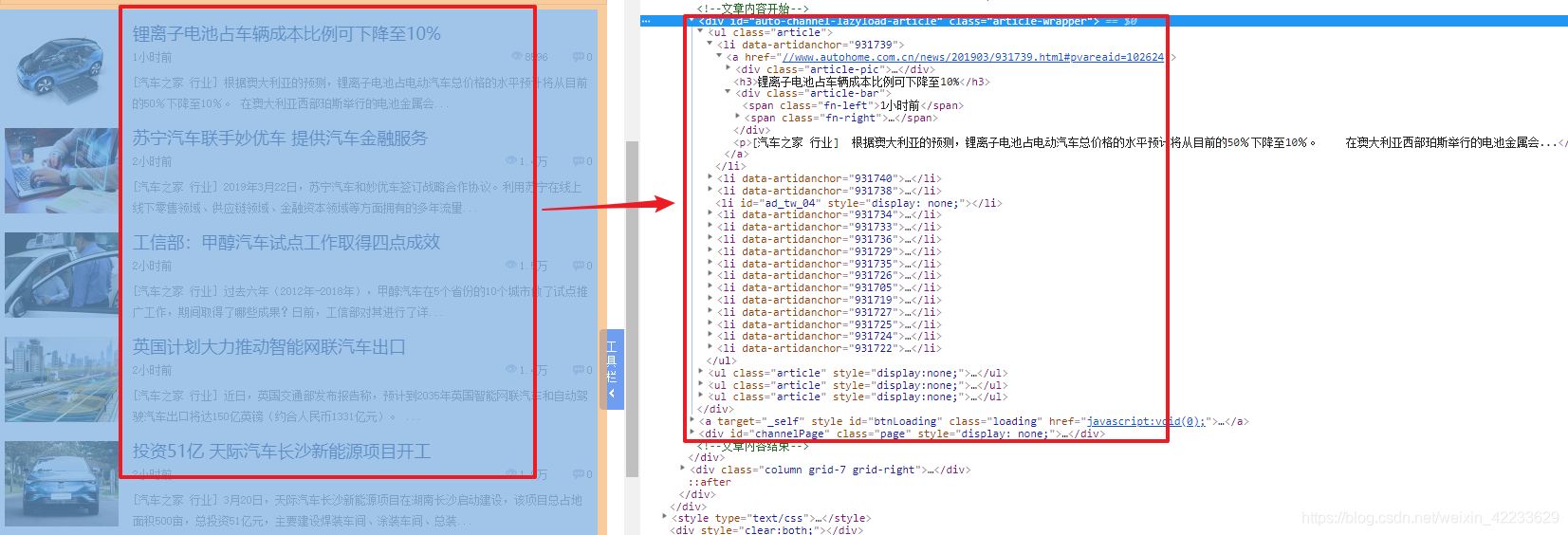
仅仅只需这一段内容
3. 提取所需内容
可以使用re正则模块,但python的Beauitifulsoup模块可以解析html格式字符串,并找到指定标签,
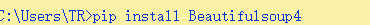
import requests
from bs4 import BeautifulSoup # bs4,给html格式字符串解析成字符串对象。find、find_all
response = requests.get('https://www.autohome.com.cn/news/') # 伪装浏览器发送get请求,拿到结果
response.encoding = 'gbk'
soup = BeautifulSoup(response.text, 'html.parser') # python中默认的解析器解析html,解析成soup对象
div = soup.find(name='div', attrs={'id': 'auto-channel-lazyload-article'}) # 找便签名和属性,id唯一
print(div)
运行结果

此时div为一个对象。还可以继续找
import requests
from bs4 import BeautifulSoup
response = requests.get('https://www.autohome.com.cn/news/') # 通过代码伪装浏览器发送get请求,拿到结果
response.encoding = 'gbk'
soup = BeautifulSoup(response.text, 'html.parser') # python中默认的解析器解析html,解析成soup对象
div = soup.find(name='div', attrs={'id': 'auto-channel-lazyload-article'}) # 找便签名和属性,id唯一,find表示找到与之相匹配的第一个标签。
li_list = div.find_all(name='li') # 找到所有li标签
for li in li_list:
print(33333333333, li)
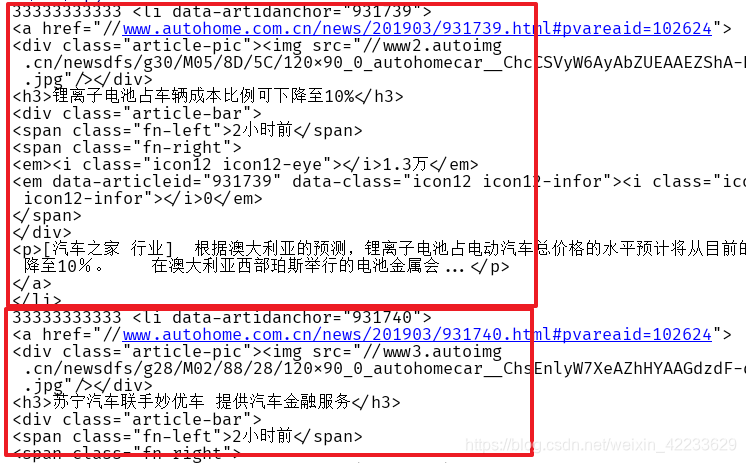
此时已经找到每个li标签,接下来,需要每个li标签也就是每条新闻的链接,标题,图片,简介,并把图片放到本地
import requests
from bs4 import BeautifulSoup
response = requests.get('https://www.autohome.com.cn/news/') # 通过代码伪装浏览器发送get请求,拿到结果
response.encoding = 'gbk'
soup = BeautifulSoup(response.text, 'html.parser') # python中默认的解析器解析html,解析成soup对象
div = soup.find(name='div', attrs={'id': 'auto-channel-lazyload-article'}) # 找便签名和属性,id唯一,find表示找到与之相匹配的第一个标签。
li_list = div.find_all(name='li') # 找到所有li标签
for li in li_list:
title = li.find(name='h3')
if not title:
continue
p = li.find(name='p')
# find默认取第一个
a = li.find(name='a')
print(title.text)
print(p.text)
print(a.attrs.get('href'))
img = li.find(name='img')
src = 'https:' + img.get('src') # 调用attr
print(src)
# 再次发起请求,下载图片
img_name = src.rsplit('/', maxsplit=1)[1]
ret = requests.get(src)
with open(img_name, 'wb') as f:
f.write(ret.content) # content:返回二进制,相当于没转换的。text: 把二进制转换成字符串
运行结果

本地文件

接下来,把刚刚得到的数据放到数据库,把图片放到静态文件夹statics,用户进入你的网页后连接到数据库同样可以连接到新闻,而数据库中不用存详细内容,直接跳转到别的网页就可以了
网站建设者也会写反爬机制,而爬取者又见招拆招。有些网站需登录成功才能看,这时需提供cookie和session,csrf_token等方法绕过这些限制,所以需对web的知识很熟悉。有时伪造得不像浏览器也会限制。
百度google等全部数据都爬,














 855
855











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









