







前言
论文导读
- 【论文解读】 图像分割 & 目标识别 | Selective Search和python实现| <Selective Search for Object Recognition>
- 【论文解读】深度学习目标检测的开山鼻祖 |R-CNN详解 | 两阶段目标检测代表
- 【论文解读】目标检测的发展之作|Ross大神续作 | Fast R-CNN
R-CNN系列发展
R-CNN 将深度学习应用到目标检测之中、有了初步探索,精度有了较大提升,达到了SOTA 水平。

但是明显是存在着重大的缺陷:
- 还是通过
Selective Search提取ROI,这个传统的图像处理方法精度确实还是堪忧;而且这个参数是不能随着反向传播而不断迭代更新的,只能通过初期的参数设置确定,也就是说不具有训练优化可能。 - 多过程训练
img input -> SS -> ALexNet -> SVM+ Regressor, 这几个过程只能分开训练、而且在positive/negtive sample也不一致、每个ROI都要进行feature map extract并且也没有数据共享;中间也需要保存卷基层数据,可谓是耗时耗力 - 检测时间非常慢,精度还有进步空间
于是, 在次年,ross大神提出了改进版本- Fast R-CNN
该paper 主要是问题2、 3解决;

- 整体过程变为
img input -> VGG16 -> img ROI映射到feature map ROI ->ROI pooling -> FC layer -> classfication FC+ regressor FC - 借鉴了
SPPNet网络结构, 只是提取一次feature map,将img roi 映射到feature map roi, 并且不在使用独立的SVM、regressor,而是使用统一的一个网络结构训练,可以进行数据共享和反向传播更新。 - svd trucated for FC layer / min batch size/ muti -task 等也都提升了精度和训练时间
唯一的一个遗憾是,没有使用CNN 替代SS进行提取ROI。这才有了Faster R-CNN。
自此R-CNN系列才从传统图像处理,彻底的、完全地步入到了完全深度学习图像处理!
后起之秀的改进

看看这篇paper的作者, 第一位是任少卿,第二位是何恺明,第三位才是ROSS大神,第四位就是孙剑了(这个显然是何和任曾经的指导老师了,不过孙老师也是真的强)。
前2个中国籍的cv学者,说是同龄同领域学术界的天花板也一点也不为过,只是一个最终选择了低调地学术,另一个步入了风云诡异的工业界。。。。
挂出大神们的简历来镇楼, 真的膜拜一下:
--------------------不好意思,跑题了-----------------------

此时的任少卿,还是在微软和中科大的联合培养Phd。
虽然任总监善于发现、并且解决问题这个能力是非常强的, 但是这个论文写的还是赶脚有一点蹩脚,并不是那种酣畅淋漓、100%小白能读的非常爽、论点阐述的非常透彻、对比非常明显的赶脚,可能鄙人的paper功底道行还比较低微吧.
1 简介
1.1 摘要

这篇paper目的性很强, Fast R-CNN的bottleneck就是RPN(因为还用着SS,耗时又不能共享训练)。
所以最大的改进,就是提出了使用fully-connect 网络(RPN)代替SS, 从而提取 ROI和给出分类scores。
(显然后面的部分,大概率是使用Fast R-CNN的其他部分来实现了)
但是不得不说,这个paper的精度和检测时间相比Fast R-CNN有了较大提高,可能达到了当时的SOTA。
1.2 代码
这个版本的复现,显然要RCNN、Fast R-CNN多了很多,特此记录以备读者选择:
[Faster R-CNN, RPN] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks | [NIPS’ 15] |[pdf]
[official code(任少卿实现版本) - matlab]
[official code(ross大神实现版本) - caffe]
[unofficial code - tensorflow]
[unofficial code - pytorch]
[unofficial code - keras]
2 Faster R-CNN网络结构
2.1 整体网络结构简介

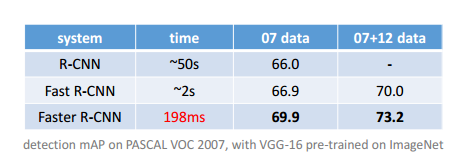
slides下载 参见 reference 2
注意:
1. 这张图只是为了说明和Fast R-CNN的不同之处,因为后面和Fast R-CNN一样了就没写了,detector之后还有ROI Pooling -> FC -> 2 sibling FC(class + bounding box regressor)
2. 整体的过程是:
-> img input
-> ZF / VGG16提取feature map
-> RPN提取ROI : 通过3x3 conc + 2个不同的1x1 conv, 计算 class score (positive / negative) + bounding box regression,确定proposals并且编码到feature map形成 feature map ROI
-> ROI Pooling 形成length-fixed feature map ROI
-> FC layer
-> 2 sibling FC(class scores + bounding box regressor)
3. 可以看到,相比于Fast R-CNN检测时间缩短了10倍,检测mAP精度提升了3%左右,效果还是非常明显的。
4. Faster R-CNN = RPN 提取Proposals + Fast R-CNN主干部分
从论文或者相关作者slides找的图,如上图所示。但是以便于只读本文的读者明白整个过程,可以参见下图:

注:
使用2次reshape是因为caffe本身结构问题,需要调整hcw,并非提出的算法必须,使用别的框架可能就没有这个过程了.
或者更加生动一点的:

2.2 backbone提取feature map
2.2.1 实验对比

关于使用的用于提取feature map的backbone, 限于当时相关网络架构的发展情况,当年的paper只是使用了ZF/VGG16作为对比。
相关性能参数如下所示:

结论1:
1、可以看出Fast R-CNN大部分时间都浪费在SS用于提取proposal了
2、卷积网络深度越深、用于提取特征和处理的时间越长(vgg > zf)
相关检测精度的对比,参见如下:

结论2:
使用RPN的方式并且共享数据、联合训练的话,相关的mAP结果相比于SS方法,还是提升了2% - 5%,效果还是不错。
tips:
当然后续也有人使用别的主干网络之类的,相关精度和准确度肯定是使用更深的网络结构(例如说resnet),相关准确度会更好;使用更轻量级的网络结构(例如说mobilenet v2),检测时间会更短、但是精度肯定也会略低。
2.2.2 说明
为了方便理解,conv layer使用VGG16相关结构予以说明:
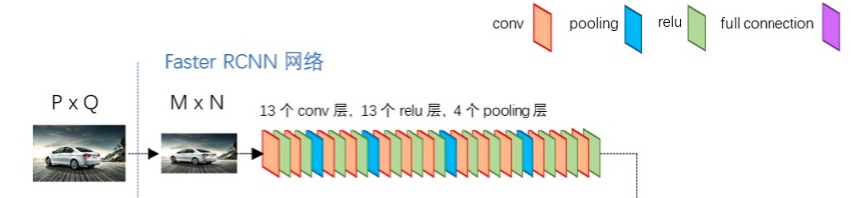
Conv layers包含了conv,pooling,relu三种层。以python版本中的VGG16模型网络结构为例,如上图所示,Conv layers部分共有13个conv层,13个relu层,4个pooling层。这里有一个非常容易被忽略但是又无比重要的信息,在Conv layers中:
所有的conv层都是:kernel_size=3,pad=1,stride=1
所有的pooling层都是:kernel_size=2,pad=0,stride=2
为何重要?在Faster RCNN Conv layers中对所有的卷积都做了扩边处理( pad=1,即填充一圈0),导致原图变为 (M+2)x(N+2)大小,再做3x3卷积后输出MxN 。正是这种设置,导致Conv layers中的conv层不改变输入和输出矩阵大小。

而通过pooling层,相关w, h都会变为1/2。经过4个pooling 层,w,h都会变成原来的1/16。
所以,整体过程的尺寸变化:
原来的图像的尺寸 M X N -> feature map 尺寸 ceil[M/16] X ceil[N/16]
eg: 800 x 600 -> 50 x 38
这也就是说,conv layer生成feature map上的一个特征点,对应的是原图像上的 16 x 16的感受野
2.3 RPN
2.3.1 流程和结构简介
使用backbone提取了feature map之后,后续就分为了2条:
1、送入region proposals network(RPN)网络,替代Fast R-CNN中的SS生成初步的bounding box的相对位移, classification scores
2、整张图片的feature map,送往下一环节,利用1中选出的positive sample的相对位移,生成feature map ROI,然后送往ROI Pooling
RPN整体结构如下所示:
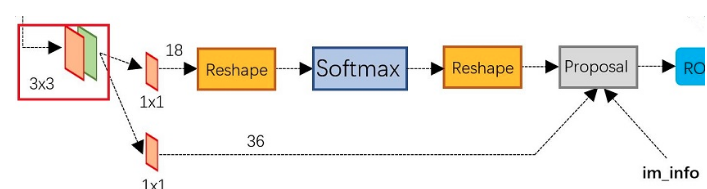
相关的尺寸变化大致如下所示:

2.3.2 anchor
- 基本思路
1.这边文章的最大点就是提出了anchor来规划所有潜在的框。
2.在经过(vgg16) conv layer之后,所提取的feature map ,每一个点都映射的是原图像上的一个感受野,如果对于这个感受野通过固定面积、改变w/h的比例的方式,就可以初步提取出来原图上的bounding box;如果对于这个框,在进行二分类判断(前景、背景),判断到底是否包含目标,划归为positive/negative的分类,并且通过soft max计算相关概率。这样就可以初步实现分类、提出目标的坐标位置。这就是初步的proposals.
3.并且如果参照Fast R-CNN, 训练出来一种从proposals bounding box到 ground truth bounding box的映射函数,那通过训练之后,利用这种映射关系可以近似地得到新图像、经过校正较为准确的bounding box。
-
基本实现

paper中是以ZF为例说明的(如上图所示)。生成的conv feature map每一个点对应的感受野,通过改变w/h比例、固化面积,可以得到不同尺度大小的bounding box。具体如paper:

即, 通过以下两个参数的不同组合,可以得到k =3x3= 9个不同的anchor (bounding box)面积的不同 -> area = {128x128, 256x256, 512x512} bounding box长宽比的不同 -> ratio = {1:1, 1:2, 2:1}
因为要分开计算positive/negative的score,所以每一个feature map上的点,最终对应的class score -> 2k=18个
因为要知道中心点的x,y,以及相关bounding box的尺寸w,h, 所以每一个feature map上的点,最终对应的regression -> 4k=36 个。
tips:
1.计算一下一个800x600的图像共有多少个bounding box?
img_w / stride_all × img_h / stride_all × anchor_num
= ceil [800/16] × ceil[600/16] × 9
= 50 × 38 × 9
=17100

看到了吧,800x600的图片提取完了特征层,直接可以得到17100个bounding box,几乎可以涵盖了大部分的尺寸的目标(当然如果超边界会被忽略,但是这也已经是非常多的候选框了)。没有包含目标的话,后续还有校正。
2. bounding box具体是如何在投影到feature map ROI的?
我们以input img =800x600, VGG16为例说明。
上一步可知feature map = 50 x 38
(1)寻找原图像中心点: 例如说第一个feature map上的点(0, 0 ), 他在原图上的感受野应该是16 x 16,在原图上也就是(0,0)(15,0)(0,15)(15,15).所以他的中心点的位置就是(7.5, 7.5);
feature map上第二个点(0, 1)在原图上的中心点就是(7.5, 7.5+16)…以此类推可以找到所有中心点的位置。
(2)寻找原图像的w, h: paper中用来确定k=9就是通过组合面积、长宽比的方式来计算的。例如:
area = 128x128 、ratio = 2:1
这就是二元次方程而已, 设置bounding box长宽为w,h
w * h = 128^2
w / h = 2:1
最终可得 w =188 , h = 90
(3)映射到ROI :这个参照SPP-Net, 比较容易办到

3. Anchor到底与网络输出如何对应?

4. paper上显示的统计的bounding box为什么和计算不太一样?
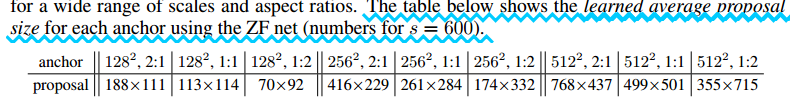
area = 128x128 、ratio = 2:1, 理论上应该是w =188 , h = 90.为啥显示是188x111啊?注意,人家这是统计的learned average proposal size。也就是说,这个是学习过的(经过校正)的、统计的平均尺寸。这188:111比例也不是2:1啊!如何进行校正呢?
主要有2次:(1)在进行RPN网络训练时候,使用类似Fast RCNN的loss进行bounding box regression计算(2)在送入后续的环节(Fast RCNN剩余部分),最终进行bounding box regression. 这也是我们能够在前面的slides那也能够看到"one net , four losses"的原因。
2.3.3 RPN bounding box校正
2.3.3.1 positive vs negative
800 × 600的1张图片,可以得到大约1.7w个bounding box,在做训练的时候,是不是全部都送入训练呢?
肯定不是。
需要选择positive / negative,然后随机选择其中选择128 positive : 128 negative 的样本,送入进行训练。
如何确定positive / negative?
正样本:与ground truth IOU > 0.7 or class score max
负样本:与ground truth IOU < 0.3
那0.3<IOU<0.7怎么办呢?全部忽略掉
2.3.3.2 从proposal -> ground truth的映射
已知:
1. 已知feature map进行RPN的结果bbox (即最终得到的proposals结果: 2k class + 4k reg->有分类有坐标)。
2. 并且通过2.3.2 的内容,可以得到1.7w的anchor(相当于已知固定点的中心点坐标(xc, yc),以及相关矩形框的 wc, hc);
3. 已知ground truth 的label, bbox;
4. 现在可以通过IOU判定positive, negative。
但是开始的时候, proposal bbox这个显然是不准确的,那如何让这些框和真实框(ground truth bbox)非常接近呢?
基本思路:
是训练一个映射关系G_hat,让G_hat 近似于G。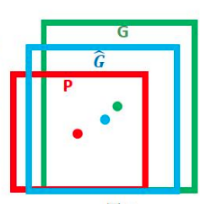
相关的映射关系如下所示:
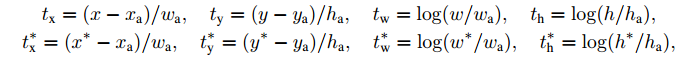
说明:
x/y/w/h: 通过RPN得到的结果,即4k res的值,是运行RPN网络得到proposals
xa/ya/wa/ha: 是通过计算anchor得到的 50x38x9个的bbox坐标点,也是距离ground truth最近的那个,即anchor bbox
x_star/y_star/w_star/h_star : 就是真实目标框
t(x,y,w,h) : 从anchor bbox -> proposals的映射
t_star(x_star,y_star,w_star, h_star) : 从 anchor bbox -> ground truth bbox的映射
最终想要的结果是 proposal 接近于 ground truth,所以求取 t 和 t_star的最小值,或者让两种映射关系最接近,就是提升proposal的办法。
训练完成后, 这样在每次计算出proposals(x,y,w,h) 之后,可以通过class score设置阈值筛选,从而近似等于(x_star,y_star,w_star, h_star).
2.3.3.3 mutil-task loss
在paper中,RPN网络是单独训练的,相关的loss函数如下所示:
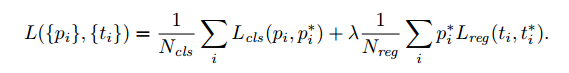
说明:
1.为了保持cls,reg数量等级, λ = 10;
2. i表示在一个mini-batch中anchor的序号;pi表示anchor i成为目标而不是背景的概率;N表示mini-batch中总共的proposal的数目
3. Pi* 相当于label, 如果是positive,则 Pi*=1;反之,Pi*=0
4. Lcls = P* x Log(pi) + (1-P*) x Log(1-pi)
5. Lreg(ti; t∗ i ) = R(ti − t∗ i ), R()表示smooth L1
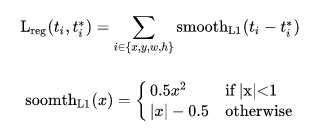
2.4 Fast R-CNN
在2.3 已经提取了RPN之后,剩下的过程就是跟Fast R-CNN一样的结构了:
ROI Pooling -> FC Layer -> sibling FC layer for classfication and bbox regression
这个过程已经叙述过了, 不再赘述,详细参见 Fast R-CNN 链接
2.4 train and test


Faster R-CNN还有一种end-to-end的训练方式,可以一次完成train,有兴趣请自己看ross大神 GitHub吧
3 实验和评估
1 使用不同region proposals method的比较

2 使用不同IOU(和ground truth的IOU)、不同proposal数目相关的recall率

综合比较,可以看到使用300个proposals的效果还是比较好一些
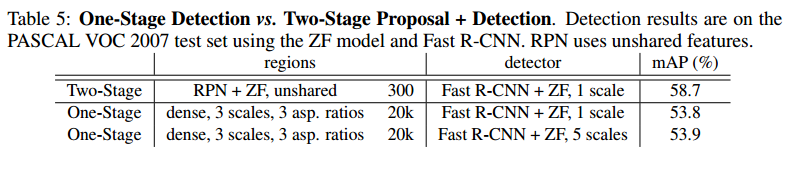
3 one-stage vs two stage
Reference
-
1 [Faster R-CNN, RPN] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks | [NIPS’ 15] |
[pdf]
[official code(任少卿实现版本) - matlab]
[official code(ross大神实现版本) - caffe]
[unofficial code - tensorflow]
[unofficial code - pytorch]
[unofficial code - keras] -
2
[iccc-2015 slides by kaiming He]|[iccc-2015 slides by rbg]

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











