







目录
简介
有关anything相关的主流任务: 2d检测相关(AnyObject), 3d检测相关(Any3D),AI生成相关(AnyGeneration), AI模型优化相关(), AI任务相关, etc.
- AnyObject - 分割、检测、分类、医学图像、OCR、姿态等。
- AnyGeneration - 文本到图像的生成、编辑、修复、样式转换等。
- Any3D - 3D 生成、分割等。
- AnyModel - 任何修剪、任何量化、模型重使用。
- AnyTask -LLM 控制器 + ModelZoo,通用解码,多任务学习。
- AnyX - 其他主题:字幕等
anything项目整理
AnyObject
| Title & Authors | Intro | Useful Links |
|---|---|---|
Segment Anything Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick > Meta Research > Preprint’23 [Segment Anything (Project)] |  | [Github] [Page] [Demo] |
OVSeg: Open-Vocabulary Semantic Segmentation with Mask-adapted CLIP Feng Liang, Bichen Wu, Xiaoliang Dai, Kunpeng Li, Yinan Zhao, Hang Zhang, Peizhao Zhang, Peter Vajda, Diana Marculescu > Meta Research > Preprint’23 [OVSeg (Project)] |  | [Github] [Page] |
Learning to Segment Every Thing Ronghang Hu, Piotr Dollar, Kaiming He, Trevor Darrell, Ross Girshick > UC Berkeley, FAIR > CVPR’18 [seg_every_thing (Project)] |  | [Github] [Page] |
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection Shilong Liu and Zhaoyang Zeng and Tianhe Ren and Feng Li and Hao Zhang and Jie Yang and Chunyuan Li and Jianwei Yang and Hang Su and Jun Zhu and Lei Zhang > IDEA-Research > Preprint’23 [Grounded-SAM, GroundingDINO (Project)] |  | [Github] [Demo] |
SegGPT: Segmenting Everything In Context Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, Tiejun Huang > BAAI-Vision > Preprint’23 [SegGPT (Project)] |  | [Github] |
| V3Det: Vast Vocabulary Visual Detection Dataset Jiaqi Wang, Pan Zhang, Tao Chu, Yuhang Cao, Yujie Zhou, Tong Wu, Bin Wang, Conghui He, Dahua Lin > Shanghai AI Laboratory, CUHK > Preprint’23 |  | – |
segment-anything-video (Project) Kadir Nar | 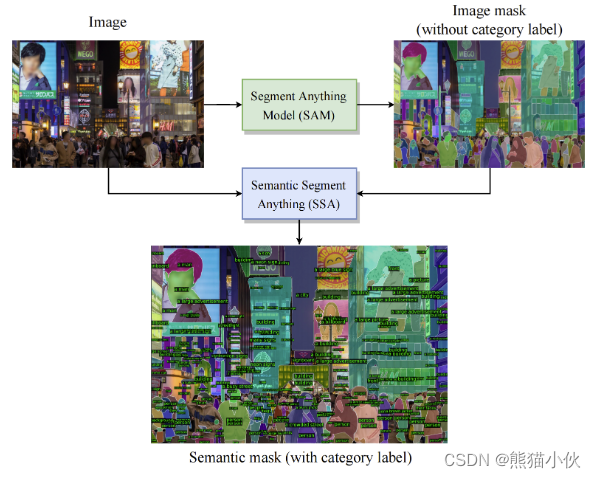 | |
[Github] | ||
Towards Segmenting Anything That Moves Achal Dave, Pavel Tokmakov, Deva Ramanan > ICCV’19 Workshop [segment-any-moving (Project)] |    | [Github] |
Semantic Segment Anything Jiaqi Chen, Zeyu Yang, Li Zhang [Semantic-Segment-Anything (Project)] |  | [Github] |
Grounded Segment Anything: From Objects to Parts (Project) Peize Sun and Shoufa Chen | [Github] | |
GroundedSAM-zero-shot-anomaly-detection (Project) Yunkang Cao |  | [Github] |
Segment Anything Labelling Tool (SALT) (Project) Anurag Ghosh | [Github] | |
Prompt-Segment-Anything (Project) Rockey | [Github] | |
SAM-RBox (Project) Qingyun Li |  | [Github] |
VISAM (Project) Feng Yan, Weixin Luo, Yujie Zhong, Yiyang Gan, Lin Ma | [Github] | |
Segment Anything EO tools: Earth observation tools for Meta AI Segment Anything (Project) Aliaksandr Hancharenka, Alexander Chichigin | [Github] | |
napari-segment-anything: Segment Anything Model (SAM) native Qt UI (Project) Jordão Bragantini, Kyle I S Harrington, Ajinkya Kulkarni |  | [Github] |
SAM-Medical-Imaging: Segment Anything Model (SAM) native Qt UI (Project) Jordão Bragantini, Kyle I S Harrington, Ajinkya Kulkarni | 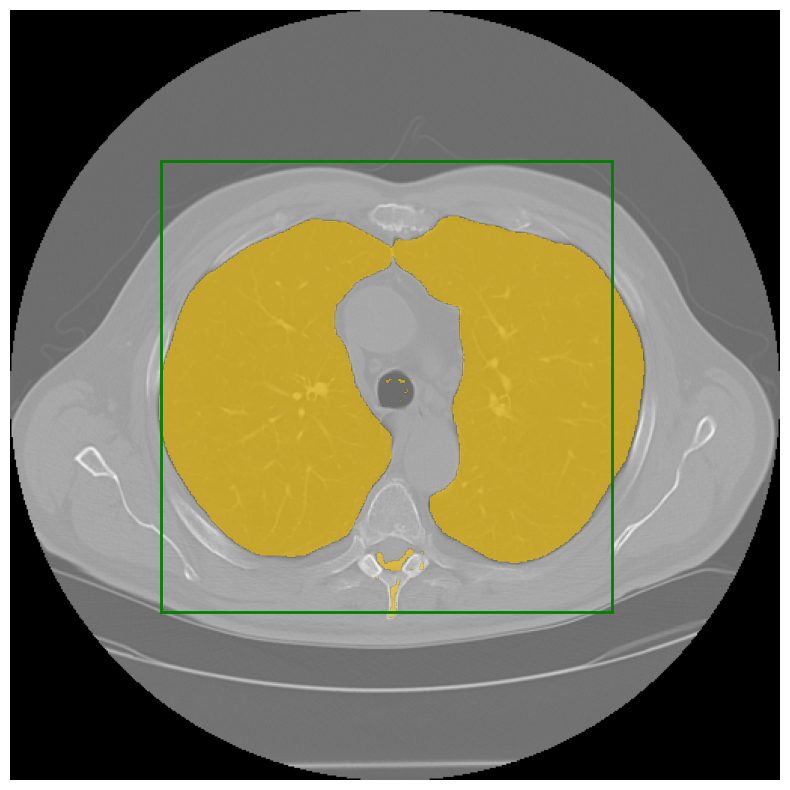 | [Github] |
OCR-SAM: Combining MMOCR with Segment Anything & Stable Diffusion. (Project) Zhenhua Yang, Qing Jiang | [Github] | |
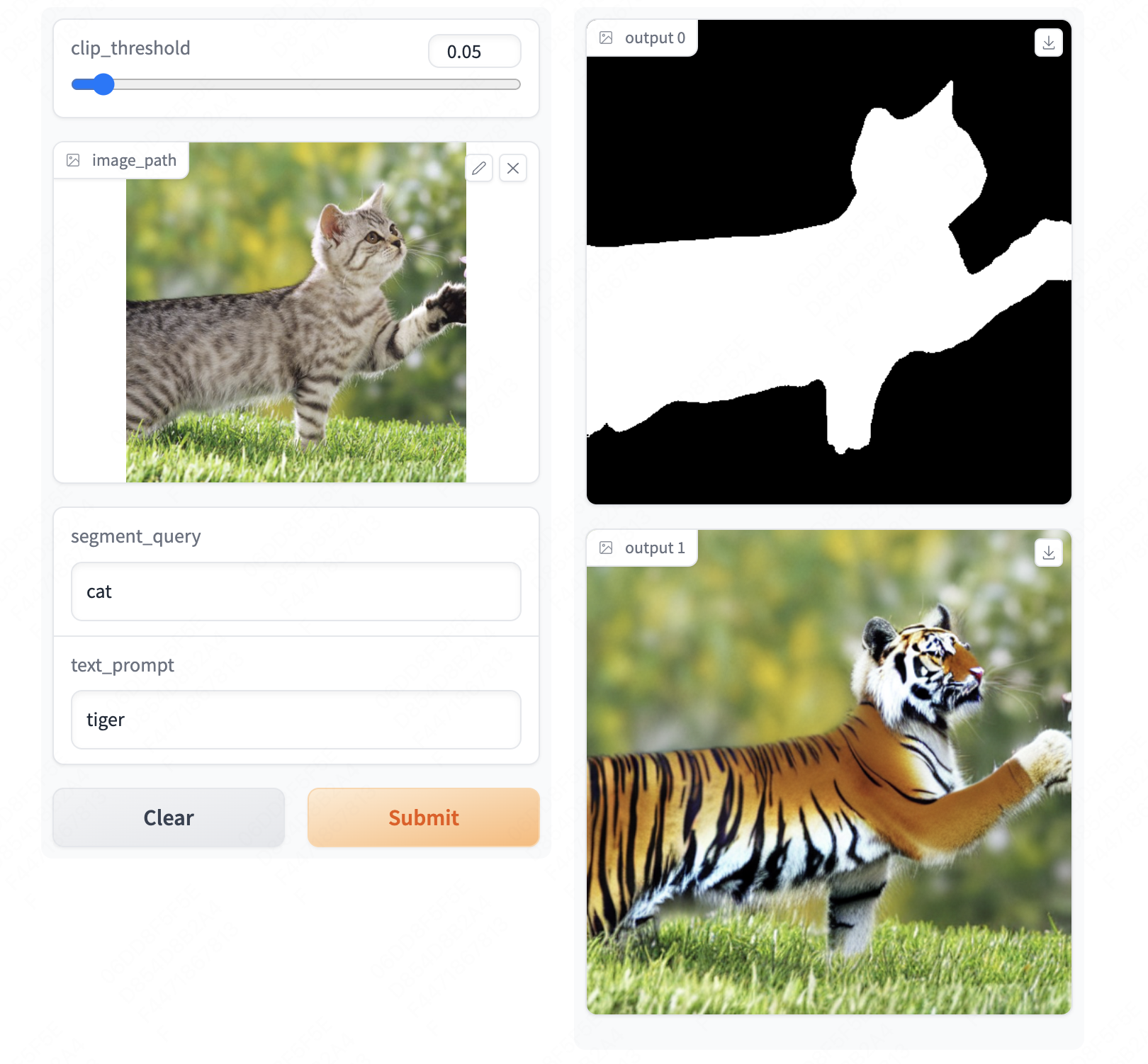
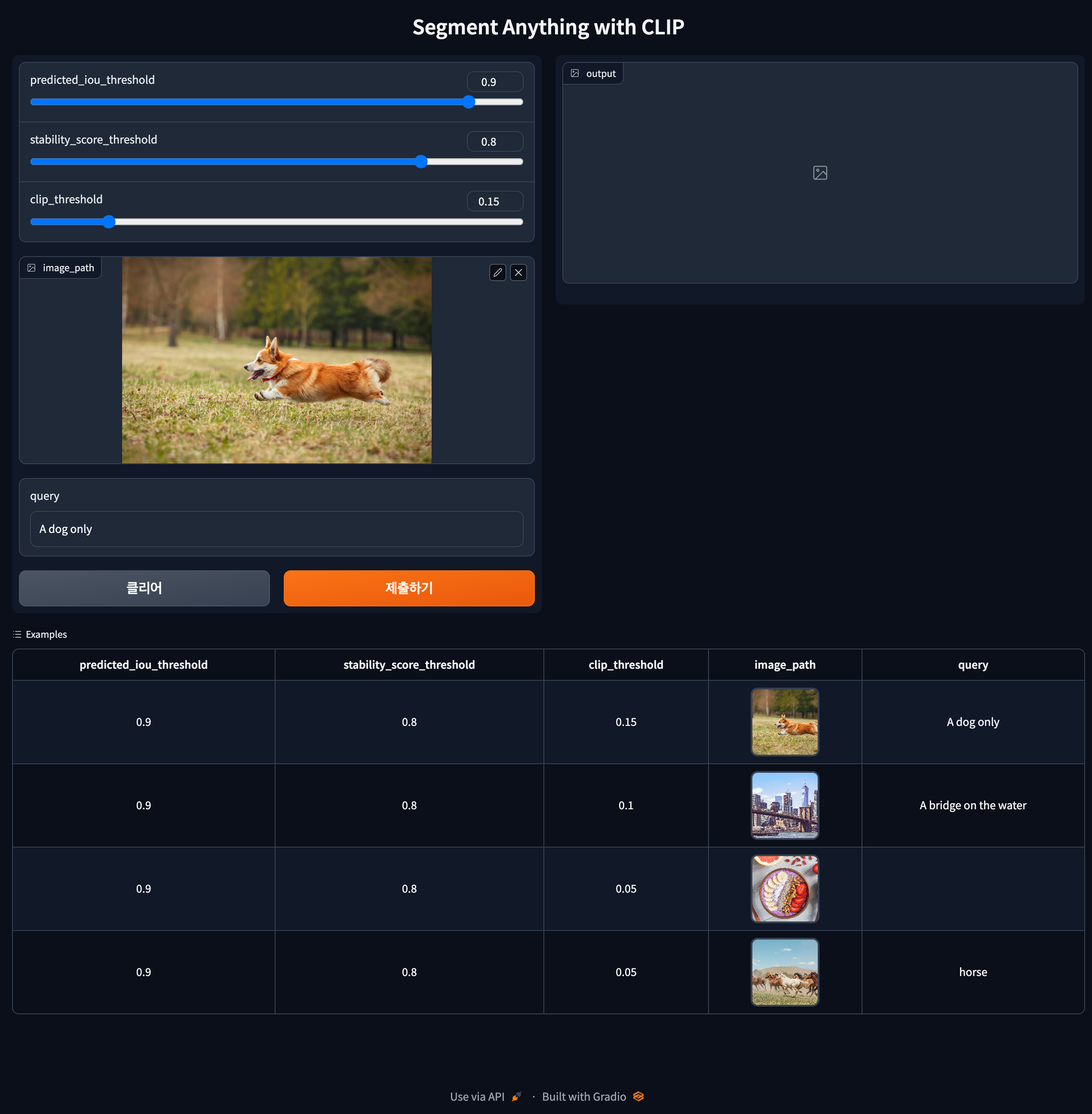
segment-anything-u-specify: using sam+clip to segment any objs u specify with text prompts. (Project) MaybeShewill-CV | [Github] | |
Segment Everything Everywhere All at Once Xueyan Zou, Jianwei Yang, Hao Zhang, Feng Li, Linjie Li, Jianfeng Gao, Yong Jae Lee [SEEM (Project)] | [Github] | |
SegDrawer: Simple static web-based mask drawer (Project) Harry | [Github] | |
Magic Copy: a Chrome extension (Project) Harry |  | [Github] |
Track Anything: Segment Anything Meets Videos Jinyu Yang, Mingqi Gao, Zhe Li, Shang Gao, Fangjing Wang, Feng Zheng [Track-Anything (Project)] | [Github] [Demo] | |
Count Anything (Project) Liqi Yan |  | [Github] |
Segment-and-Track-Anything (Project) Zongxin Yang |  | [Github] |
Pose for Everything: Towards Category-Agnostic Pose Estimation Lumin Xu*, Sheng Jin*, Wang Zeng, Wentao Liu, Chen Qian, Wanli Ouyang, Ping Luo, Xiaogang Wang > CUHK, SenseTime > ECCV’22 Oral [Pose-for-Everything (Project)] | [Github] | |
Relate Anything Model (Project) Zujin Guo*, Bo Li*, Jingkang Yang*, Zijian Zhou*, Ziwei Liu > MMLab@NTU > VisCom Lab, KCL/TongJi | Github | |
SegmentAnyRGBD (Project) Jun Cen, Yizheng Wu, Xingyi Li, Jingkang Yang, Yixuan Pei, Lingdong Kong > Visual Intelligence Lab@HKUST, > HUST, > MMLab@NTU, > Smiles Lab@XJTU, > NUS | Github |
AnyGeneration




Any3D
| Title & Authors | Intro | Useful Links |
|---|---|---|
Anything-3D: Segment-Anything + 3D, Let’s lift the anything to 3D (Project) LV-Lab, NUS | Github | |
SAM 3D Selector: Utilizing segment-anything to help the region selection of 3D point cloud or mesh. (Project) Nexuslrf | Github | |
3D-Box via Segment Anything. (Project) dvlab-research | [Github] | |
Segment Anything 3D (Project) Yunhan Yang, Xiaoyang Wu | [Github] |
AnyModel
| Title & Authors | Intro | Useful Links |
|---|---|---|
| [ DepGraph: Towards Any Structural Pruning Gongfan Fang, Xinyin Ma, Mingli Song, Michael Bi Mi, Xinchao Wang > Learning and Vision Lab @ NUS > CVPR’23 [Torch-Pruning (Project)] | [Github] [Demo] | |
MQBench: Towards Reproducible and Deployable Model Quantization Benchmark Yuhang Li and Mingzhu Shen and Jian Ma and Yan Ren and Mingxin Zhao and Qi Zhang and Ruihao Gong and Fengwei Yu and Junjie Yan > SenseTime Research > NeurIPS’21 [MQBench (Project)] | 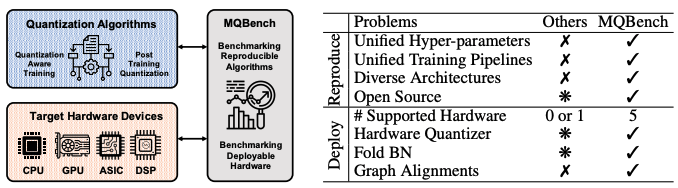 | [Github] [Page] |
OTOv2: Automatic, Generic, User-Friendly Tianyi Chen, Luming Liang, Tianyu Ding, Ilya Zharkov > Microsoft > ICLR’23 [Only Train Once (Project)] | 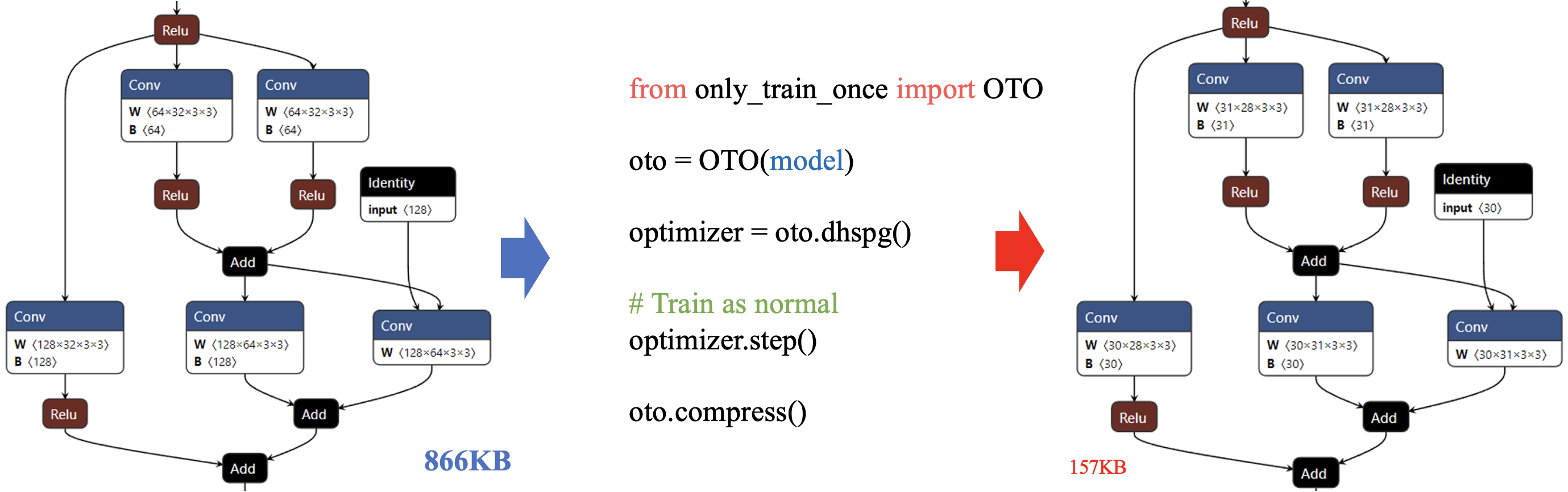 | [Github] |
Deep Model Reassembly Xingyi Yang, Daquan Zhou, Songhua Liu, Jingwen Ye, Xinchao Wang LV Lab, NUS > NeurIPS’22 [Deep Model Reassembly (Project)] | [Github] [Page] |
AnyTask
| Title & Authors | Intro | Useful Links |
|---|---|---|
HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in HuggingFace Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, Yueting Zhuang > Zhejiang University, MSRA Preprint’23 [Jarvis (Project)] |  | [Github] [Demo] |
| TaskMatrix.AI: Completing Tasks by Connecting Foundation Models with Millions of APIs Yaobo Liang, Chenfei Wu, Ting Song, Wenshan Wu, Yan Xia, Yu Liu, Yang Ou, Shuai Lu, Lei Ji, Shaoguang Mao, Yun Wang, Linjun Shou, Ming Gong, Nan Duan > Microsoft > > Preprint’23 | [Github] | |
Generalized Decoding for Pixel, Image and Language Xueyan Zou, Zi-Yi Dou, Jianwei Yang, Zhe Gan, Linjie Li, Chunyuan Li, Xiyang Dai, Harkirat Behl, Jianfeng Wang, Lu Yuan, Nanyun Peng, Lijuan Wang, Yong Jae Lee, Jianfeng Gao > Microsoft > CVPR’23 [X-Decoder (Project)] | 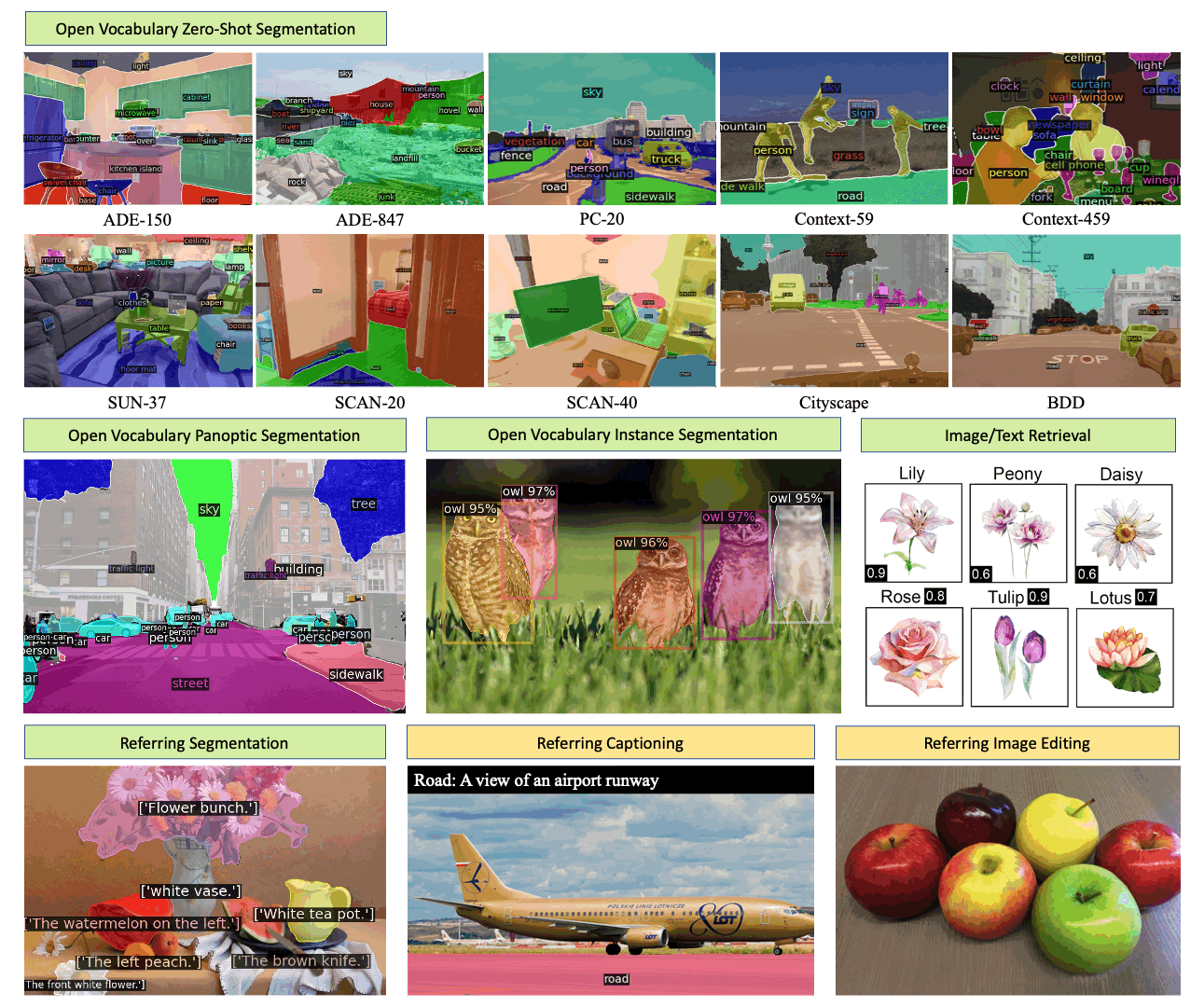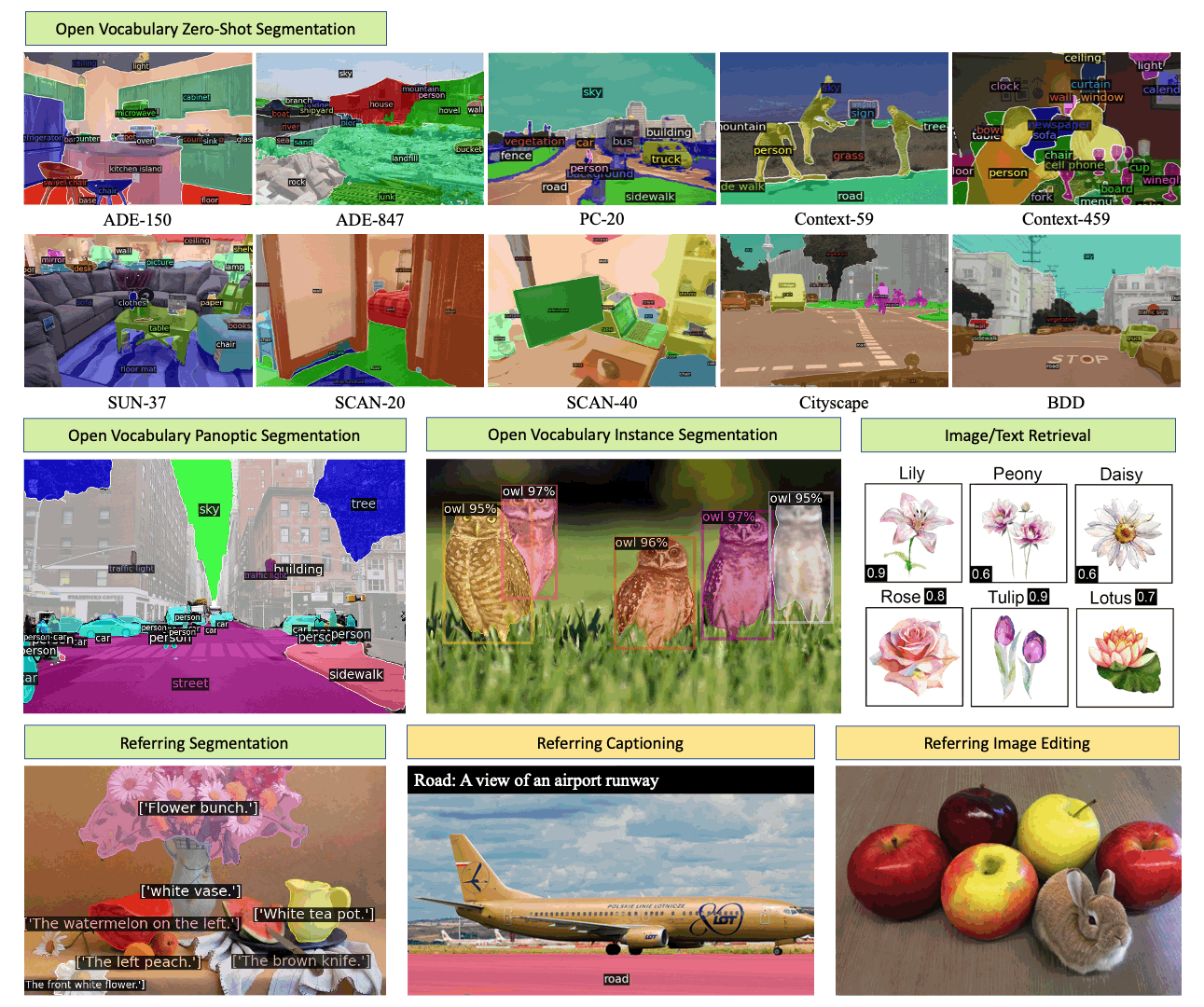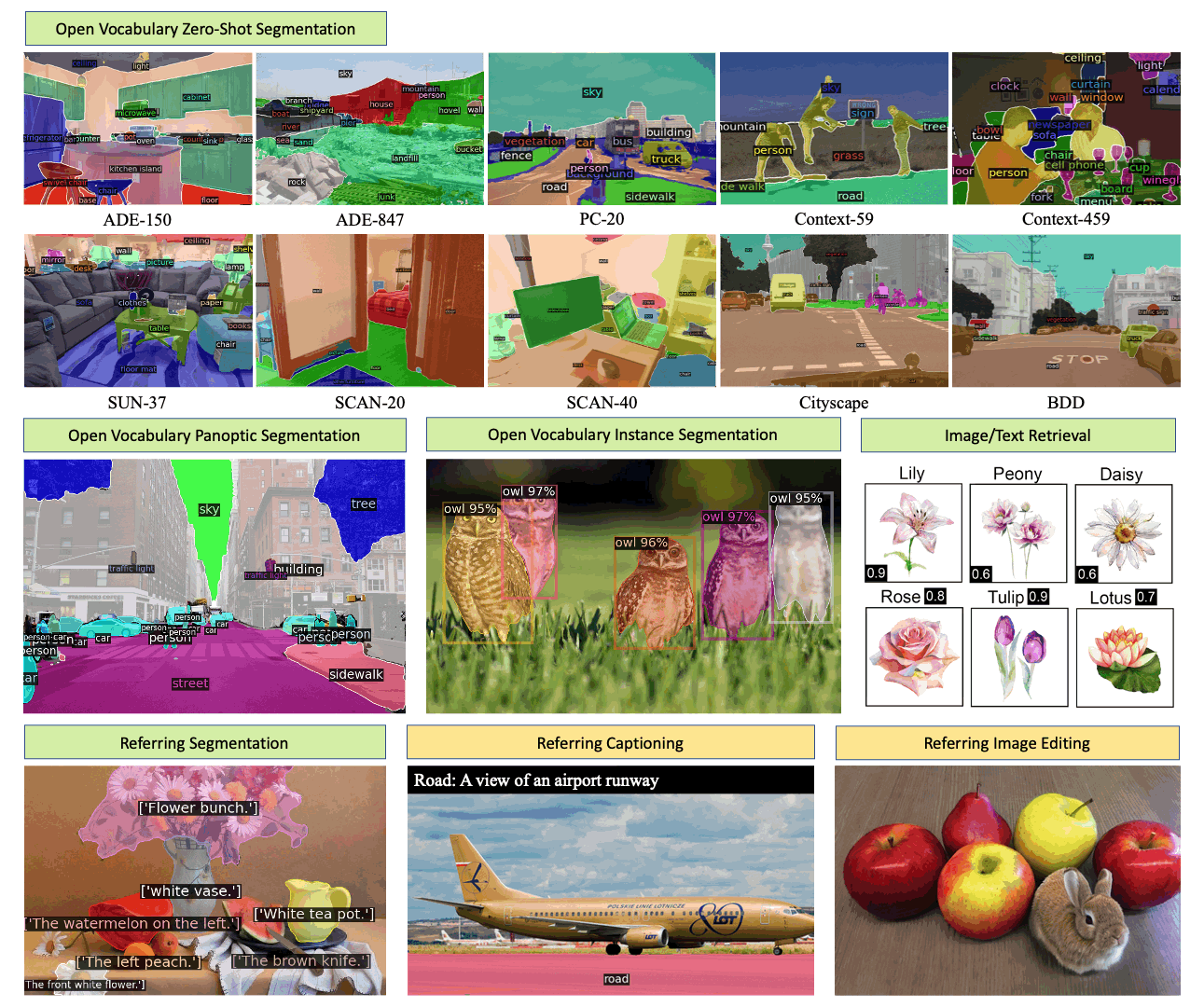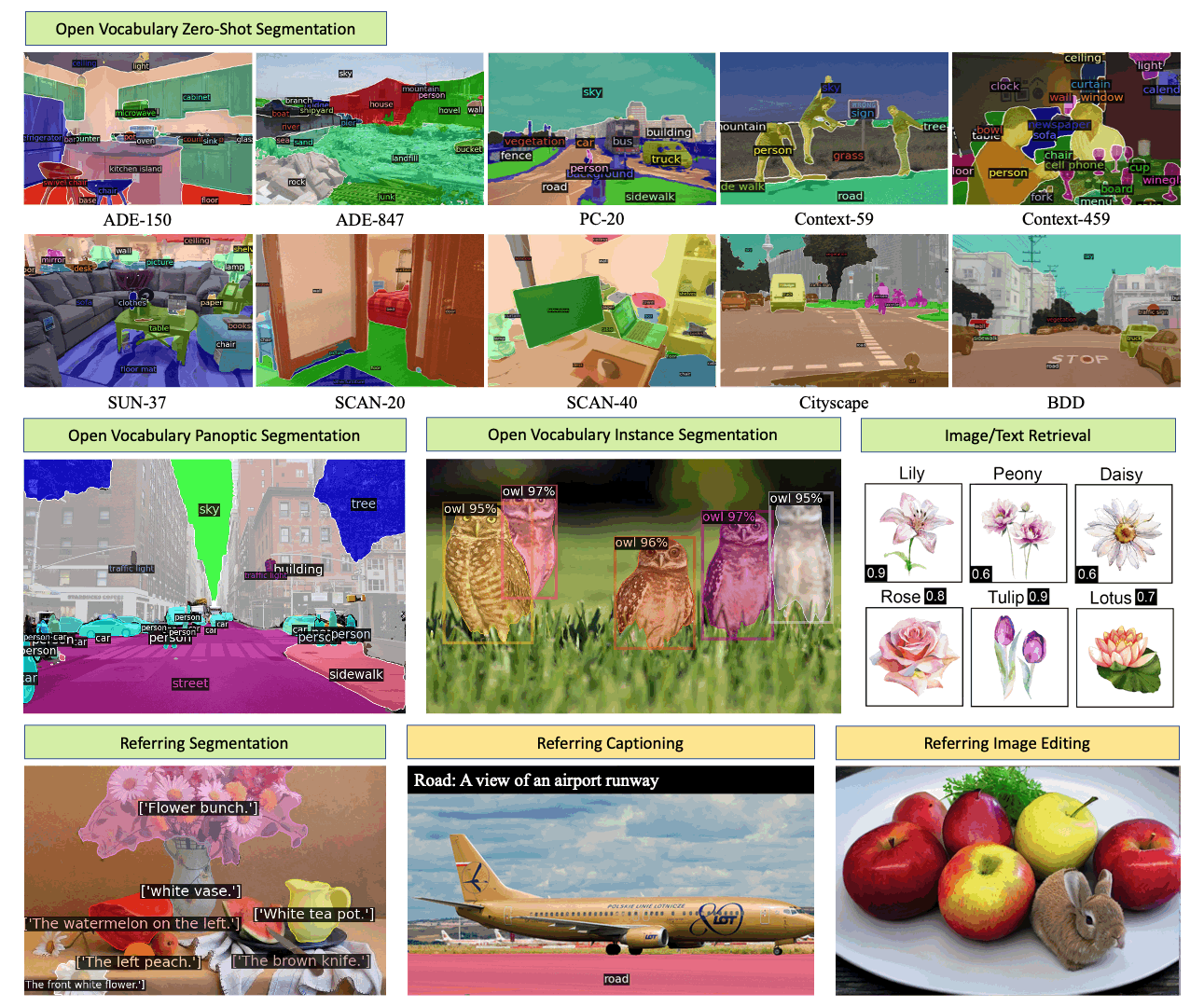 | [Github] [Page] [Demo] |
Pre-Trained Image Processing Transformer Chen, Hanting and Wang, Yunhe and Guo, Tianyu and Xu, Chang and Deng, Yiping and Liu, Zhenhua and Ma, Siwei and Xu, Chunjing and Xu, Chao and Gao, Wen > Huawei-Noah > CVPR’21 [Pretrained-IPT (Project)] | [Github] | |
OpenAGI: When LLM Meets Domain Experts Yingqiang Ge, Wenyue Hua, Jianchao Ji, Juntao Tan, Shuyuan Xu, Yongfeng Zhang > Rutgers University > Preprint’23 [OpenAGI (Project)] | Github |
AnyX
| Title & Authors | Intro | Useful Links |
|---|---|---|
Caption Anything: Interactive Image Description with Diverse Multimodal Controls Teng Wang, Jinrui Zhang, Junjie Fei, Hao Zheng, Yunlong Tang, Zhe Li, Mingqi Gao, Shanshan Zhao > SUSTech VIP Lab > Preprint’23 Caption Anything (Project) | [Github] [Demo] | |
Image2Paragraph:Transform Image into Unique Paragraph (Project) Jinpeng Wang | Github | |
| … |
论文汇总
AnyObejct
| Paper | First Author | Venue | Topic |
|---|---|---|---|
| Segment Anything | Alexander Kirillov | Preprint’23 | Segmentation |
| Learning to Segment Every Thing | Ronghang Hu | CVPR’18 | |
| Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection | Shilong Liu | Preprint’23 | Grouding+Detection |
| SegGPT: Segmenting Everything In Context | Xinlong Wang | Preprint’23 | Segmentation |
| V3Det: Vast Vocabulary Visual Detection Dataset | Jiaqi Wang | Preprint’23 | Dataset |
| Pose for Everything: Towards Category-Agnostic Pose Estimation | Lumin Xu | ECCV’22 Oral | Pose |
AnyGeneration
| Paper | First Author | Venue | Topic |
|---|---|---|---|
| High-Resolution Image Synthesis with Latent Diffusion Models | Robin Rombach | CVPR’22 | Text-to-Image Generation |
| Adding Conditional Control to Text-to-Image Diffusion Models | Lvmin Zhang | Preprint’23 | Controlllable Generation |
| GigaGAN: Large-scale GAN for Text-to-Image Synthesis | Minguk Kang | CVPR’23 | Large-scale GAN |
| Inpaint Anything: Segment Anything Meets Image Inpainting | Tao Yu | Preprint’23 | Inpainting |
AnyModel
| Paper | First Author | Venue | Topic |
|---|---|---|---|
| DepGraph: Towards Any Structural Pruning | Gongfan Fang | CVPR’23 | Network Pruning |
| MQBench: Towards Reproducible and Deployable Model Quantization Benchmark | Yuhang Li | NeurIPS’21 | Network Quantization |
| OTOv2: Automatic, Generic, User-Friendly | Tianyi Chen | ICLR’23 | Network Pruning |
| Deep Model Reassembly | Xingyi Yang | NeurIPS’22 | Model Reuse |
AnyTask
| Paper | First Author | Venue | Topic |
|---|---|---|---|
| HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in HuggingFace | Yongliang Shen | Preprint’23 | Modelzoo + LLM |
| TaskMatrix.AI: Completing Tasks by Connecting Foundation Models with Millions of APIs | Yaobo Liang | Preprint’23 | Modelzoo + LLM |
| Generalized Decoding for Pixel, Image and Language | Xueyan Zou | CVPR’23 | Multi Tasking |
| Pre-Trained Image Processing Transformer | Chen, Hanting | CVPR’21 | Low-level Vision |



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











