






 本文探讨深度学习论文中的代码实现结构,尤其是模型压缩和GAN/网络设计/模型压缩等领域。理解代码结构能加速代码阅读和复现,作者分享了常见代码结构,并提供实际案例和模版,旨在帮助读者更快实现深度学习模型。
本文探讨深度学习论文中的代码实现结构,尤其是模型压缩和GAN/网络设计/模型压缩等领域。理解代码结构能加速代码阅读和复现,作者分享了常见代码结构,并提供实际案例和模版,旨在帮助读者更快实现深度学习模型。

深度学习论文的复现一直是一个比较耗时的事情(感谢那些发paper带code的作者!)。与此同时,由于一些作者的编程习惯不太好(比如不写文档,不写注释),让阅读代码的速度也慢上不少。如果各位的代码能力不强,读起代码就是真滴难受(比如我。。),于是乎我就想办法尽可能减缓以上问题代码的损失,所以就写下本文。
本专题主要分两部分:
- 深度学习相关论文中常见的代码实现结构(这篇文章讲这个)
- 各种各样奇形怪状loss的实例
最近偷偷看了一筐论文(我吹的),主要是GAN/网络设计/模型压缩方面的,发现不同子领域之间的代码风格和结构有较大的差异(比如GAN/网络架构设计/模型压缩就是三个子领域),但是同个子领域内的代码结构大体相同。同时我发现了,当对代码结构有足够的理解之后,在看其他相似结构的代码的时候速度会快上许多。而且在尝试复现某篇论文代码的时候,采用相应领域常见的结构设计方式也会使得复现的速度加快不少。同时我发现采用同领域的代码结构可以大大加快idea的代码实现,就像自己的utils(工具包),就像现成的数学公式往里套数字一般。
于是我就把常见的一些代码结构总结了一下,相似结构的代码和论文我之后总结完会附在下面(可以加深理解)。
- 压缩模型
模型压缩大致可以分三种:
- Logits-based Knowledge
- Relation-based Knowledge
- Feature-based Knowledge
其中挺多官方代码会呈现这样的结构(特别是最新的一些论文),同时一些比较比较早之前的文章(比如fitnet)虽然官方代码没有给出这样的结构,但是思想的差不多,也就是说他们的代码也是按照这个思路写的,只不过存在耦合过高的之类的问题(你乐意的话完全可以很简单的改写成下面的结构)。
结构图以及解析:
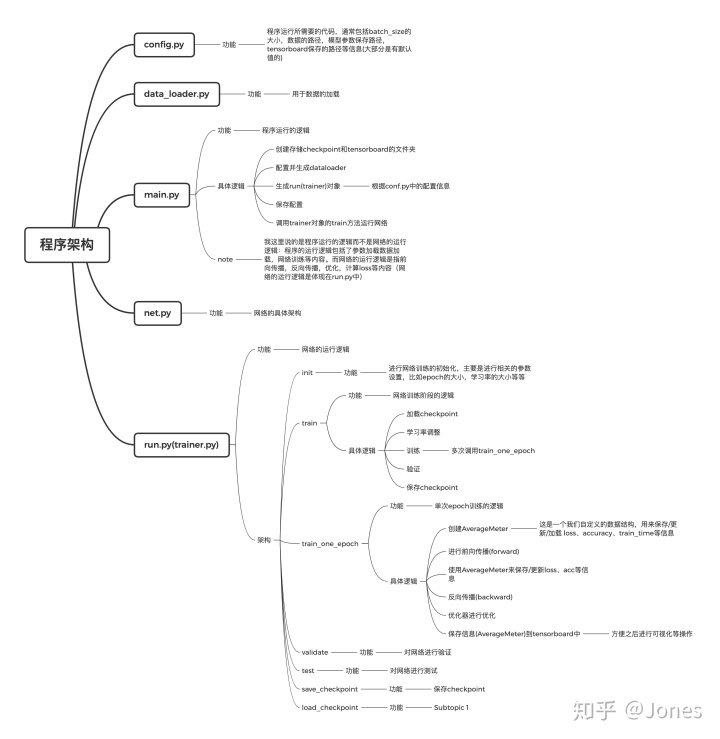
实际代码案例以及模版:
等我更新,绝对不鸽[Doge]........
2. 网络设计
3. GAN

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









