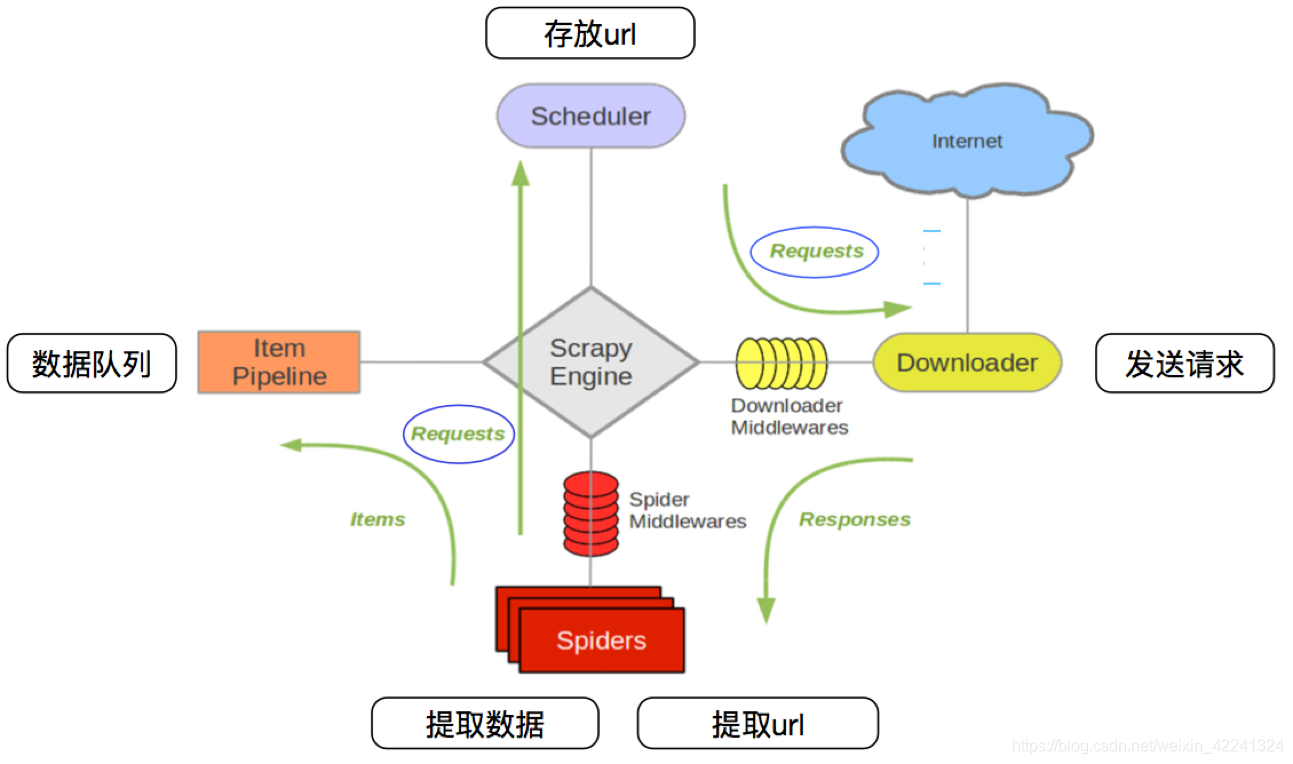
流程图 流程分析: 爬虫开启,通知管道open_spiderstart_urls中所有请求放入调度器队列从调度器中取出一个请求通过引擎 --> 下载器中间件 --> 交给下载器下载器去Internet获得响应响应通过下载器中间件 --> 引擎 --> 爬虫中间件 --> 交给爬虫爬虫经过处理 若是请求对象,返回爬虫中间件 --> 引擎 --> 放入调度器若是数据,不经过爬虫中间件,通过引擎交给管道 管道进行数据的清洗及保存爬虫关闭,通知管道close_spider






















 345
345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






