






 文章讨论了在深度学习中,数据在进入模型前未进行深拷贝会造成的性能问题。不进行深拷贝会导致在反向传播时搜索原始数据地址,增加计算时间。解决方案是使用`clone().detach()`或`deepcopy`在数据进入模型前创建副本。示例代码展示了如何在训练循环中应用此方法,结果表明性能有显著提升。
文章讨论了在深度学习中,数据在进入模型前未进行深拷贝会造成的性能问题。不进行深拷贝会导致在反向传播时搜索原始数据地址,增加计算时间。解决方案是使用`clone().detach()`或`deepcopy`在数据进入模型前创建副本。示例代码展示了如何在训练循环中应用此方法,结果表明性能有显著提升。
直接原因是:数据在进入模型之前没有进行深拷贝
深层原因大概是:如果不进行深拷贝,在梯度反向传播过程中,要寻找原始数据的地址,这个过程非常耗时间。(直接等号是前拷贝,是将新的变量指向原来变量的地址)
解决办法:
tensor_a = tensor_b.clone().detach()
或者用deepcopy也行。
位置呢,就放到数据进入模型之前就可以。大概如下:
data = loader.get_batch('train')
data_copy = data.clone().detach()
optimizer.zero_grad()
out,loss = model(data_copy)
loss.backward()
optimizer.step()如果data是tensor构成的字典或者list,遍历处理里面的每一项即可。
效果展示:
加之前
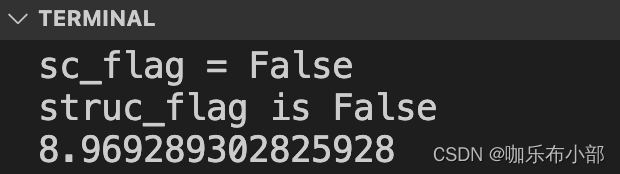
加之后
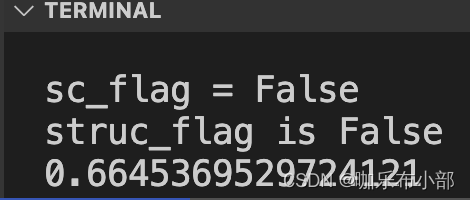
效果十分显著

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









