







前言
上一篇文章我们实现了和大模型聊天的记忆功能,但是由于我们采用的是默认的记忆组件,实际聊天数据是存放在内存中的,这种方案是有缺陷的,我需要更换一种更适合的存储介质。那么本文就来探讨一下,存储介质的选择以及实际方案的落地。
一、内存方案主要缺陷
① 数据易丢失
默认内存通常意味着数据仅保存在应用程序的运行时内存中,一旦进程重启、服务器重启或发生崩溃,所有的聊天记忆都会全部丢失,无法恢复。
在分布式或多实例部署场景下,每个实例维护独立的内存副本,彼此之间无法同步记忆数据。这样当用户请求被路由到另一台实例时,就无法访问之前会话的上下文,造成对话上下文不连贯。
② 容量受限与性能瓶颈
随着对话的深入占用越来越多的 RAM,导致整体系统可用内存迅速饱和。
③ 扩展性与并发问题
在微服务架构或 Kubernetes 等容器编排环境下,如果要实现聊天机器人水平扩展,单纯把内存当作唯一存储介质会导致各实例之间无法共享同一份记忆,需要额外的同步机制;
如果多线程/多协程并发写入同一个内存数据结构,容易出现竞态条件(Race Condition),需要额外的锁或并发数据结构,增加开发和运维成本。
④ 安全性与隐私可控
默认内存通常不具备细粒度的访问控制或审计日志功能,一旦保存在内存中的聊天历史中包含敏感信息(如个人隐私、认证令牌等),难以做到可靠的安全审计与回滚。一旦出现安全事件,也无法通过日志追踪每条对话的具体内容。
⑤ 故障恢复
内存本身并不易于快照、备份或集群冗余。一旦出现故障或灾难,无法通过快照或异地备份将内存中的会话状态恢复,业务连续性受到严重影响。
二、存储介质选择
① 向量数据库
例如:Pinecone、Weaviate、Milvus 等。将对话记忆(包括每条消息)转换为向量嵌入(Embedding),并将向量存储在专门的向量数据库中。后续可通过相似度搜索(Approximate Nearest Neighbor)快速检索与当前上下文最相关的历史对话或知识片段。
(1) 优点
高效相似度检索:针对大规模会话(百万级或以上),向量 DB 能快速返回与当前查询语义最匹配的历史片段;
支持长文本摘要分段检索:可以先将历史长对话分段或摘要为关键向量,再检索更有针对性的上下文;
易于横向扩展:商业向量库通常提供托管服务,可按需扩容节点,支持高并发读写;
可与长期知识库结合:向量数据库不仅适用于会话历史,也可用于 FAQ、知识图谱、文档检索等多种场景的统一存储。
(2) 缺点
实时写入延迟:相比内存直接写入,向量化并写入向量库会有额外开销;若对延迟极度敏感,需要做好性能调优;
存储成本相对较高:向量索引占用较多存储空间,尤其在嵌入维度较高时;商业化服务可能产生较高的按量计费。
复杂度提升:需要额外的向量化组件(Embedding 模型)、向量索引配置和管理。
(3) 适用场景
大型、多轮、跨会话的聊天机器人,需要基于上下文和历史对话做语义检索。
希望实现长期记忆、知识库检索和实时会话上下文融合的智能助手。
② 关系型数据库
例如:MySQL、PostgreSQL、MariaDB 等。将每条聊天消息作为一条记录,存储在结构化表中,字段通常包括 conversation_id、message_id、speaker、content、timestamp 等。
(1) 优点
成熟稳定:关系型数据库多年应用于生产环境,支持事务、索引、复杂查询;
容易进行审计与权限管理:可结合数据库原生的行级安全、加密、角色权限等;
持久化与备份成熟:能够方便地做逻辑备份、物理备份、主从复制、灾备;
支持更复杂的业务逻辑:可通过 SQL 进行多表关联、聚合分析等。
(2) 缺点
扩展性有限:关系型数据库在写入量极大时(如每秒成千上万条聊天消息)可能成为瓶颈,需要水平拆表或分库分表;
读写隔离时延:跨区域或跨 AZ 的同步可能会出现延迟,影响实时检索;
结构化开销:每条消息都要存为行,相对文档存储会有更多 Schema 维护成本。
(3) 适用场景
对安全、事务一致性、审计要求较高的企业级聊天系统;
聊天日志需与其他业务数据(如用户表、订单表、工单表)进行强关联的场景;
需要丰富 SQL 查询与分析能力进行报表和统计。
③ 文档数据库
例如:MongoDB、Couchbase、DynamoDB 等。将每个对话会话或对话片段存储为一个 JSON 文档,字段可包含 conversation_id、messages(数组形式)等,嵌套结构灵活。
(1) 优点
Schema 灵活:可动态添加字段,适合存储各种非结构化或半结构化对话数据;
水平扩展性好:多数文档型数据库支持自动分片(Sharding),能适应大规模数据存储;
支持索引与聚合:可对常用查询字段(如 conversation_id、timestamp)建立索引,对于检索性能友好;
易于存储对话上下文:可以把一次会话当成一个文档完整存储,方便一次性读取所有消息。
(2) 缺点
单文档大小限制:MongoDB 默认单文档最大 16MB,若一次会话包含大量历史消息则需拆分打包;
事务与强一致性相对有限:虽然新版 MongoDB 支持多文档事务,但在跨分片环境下性能开销较大;
复杂查询效率不如关系型数据库:对于需要做多表 JOIN 或复杂聚合时,性能可能不及 RDBMS。
(3) 适用场景
需要快速迭代、存储非结构化聊天内容的中小规模项目;
对会话文档进行分类、标签化、全文检索等需求;
需要配合全文索引(Text Index)或地理位置索引(Geo Index)等特性。
④ 内存缓存数据库
例如:Redis、Memcached。将对话历史短暂地存储在键值对缓存中,常用的数据结构包括列表(List)、哈希(Hash)、有序集合(Sorted Set)等。
(1) 优点
极低延迟读写:在毫秒级别即可完成读写操作,适合实时对话场景;
支持过期策略:可为会话数据设置 TTL,自动淘汰过期对话,节省内存;
数据结构丰富:内置 List、Stream、Sorted Set 等,灵活支撑多种对话记录需求。
(2) 缺点
非持久化风险:虽然 Redis 支持 RDB/AOF 持久化配置,但如果未开启持久化,一旦重启或宕机,缓存会丢失;
容量成本高:与纯硬盘存储相比,内存资源昂贵,无法无限制存储历史对话;
不适合长期存储:更适合存储近期会话上下文,长期历史还是需要持久化到数据库;
(3) 适用场景
需要存储短期(如 30 分钟内)会话状态以快速检索和更新;
辅助其他存储方案,如把最近若干轮对话缓存到 Redis,超过缓存后再落盘到文档库;
高并发环境下,确保多实例之间共享“热对话”上下文。
⑤ 对象存储
例如:Amazon S3、阿里 OSS、Google Cloud Storage。将每次会话或定期的对话数据批量打包成 JSON、Parquet、CSV 等格式文件,上传到对象存储中。之后可以通过文件名或元数据查询,辅以外部索引系统检索。
(1) 优点
海量低成本:对象存储容量几乎无限,适合存储多年累积的聊天日志;
持久化可靠:具备高冗余和自动备份,数据耐久性达到 99.999999999%;
与大数据平台兼容:下游可直接用 Spark、Hive、Flink 等工具对批量对话文件做分析。
(2) 缺点
实时性差:上传和下载都有一定延迟,不适合在线实时检索对话;
检索复杂:需要额外的元数据索引或构建文件列表才可找到特定对话;
更新不便:文件上传后不可修改,只能整体重写或增量追加。
(3) 适用场景
归档历史对话日志,作为离线分析与训练数据;
将当日会话数据合并打包后批量上云,满足合规审计;
对实时性要求不高的大规模存储与大数据分析。
⑥ 专用记忆管理系统
例如:Zep、Chroma、MemDB 等。这些系统专为 LLM 记忆设计,通常集成了向量存储、持久化、索引检索、权限管理等功能,可直接对接常见的聊天框架。
(1) 优点
开箱即用的记忆能力:内置短期、长期记忆管理策略,可按需配置;
支持聚合管道:有些系统(如 Zep)支持把历史对话做摘要、编排并映射到知识图谱;
跨实例分布式一致性:通常在后台同时使用多副本存储与协调机制,保证多实例可实时协同访问;
内置安全与审计:通常都支持访问控制、审计日志、加密传输等,满足合规要求。
(2) 缺点
学习与集成成本:需要额外学习专有 API 和存储原理;
服务成本:商用版本依赖云托管或打包部署,需要额外成本;
通用性限制:部分功能可能无法满足高度定制化需求,需要自行扩展。
(3) 适用场景
希望快速构建具备长期与短期记忆能力的 AI Agent,无需自行设计存储架构;
需要统一管理向量化记忆和原始对话,支持多模式检索;
对审计、权限、跨实例同步有严格要求。
⑦ 总结
从成本-开发复杂度-系统适合程度等多方面考量,适用MongoDB比较合适。
| 存储介质 | 持久化 | 扩展性 | 检索性能 | 实时性 | 成本 | 复杂度 | 适用场景 |
|---|---|---|---|---|---|---|---|
| 默认内存 | ✕(非持久) | ✕(单机) | 受内存大小限制 | 极高(毫秒级) | 最低 | 简单 | 原型开发、低并发、单实例测试 |
| 向量数据库 | ✔ | ✔(水平扩展) | 高(ANN检索) | 较高 | 较高(存储与查询费用) | 中等(需向量化、索引管理) | 多轮对话、语义检索、多用户长期记忆 |
| 关系型数据库 | ✔ | 中(需分库分表) | 中等(SQL检索) | 中等 | 中等(运维和硬件) | 中等(需设计 Schema) | 企业级系统、复杂关联查询、审计合规 |
| 文档数据库 | ✔ | ✔(自动分片) | 中高(索引优化) | 中高 | 中等(存储成本) | 中等(Schema 灵活) | 半结构化对话存储、全文检索、快速原型 |
| 内存缓存数据库 | ✕(可选持久) | ✔(集群模式) | 高(Key-Value) | 极高 | 较高(内存成本) | 中等(数据结构设计) | 热对话缓存、短期上下文存储、低延迟场景 |
| 对象存储 | ✔ | ✔(无限扩展) | 低(批量/文件) | 低 | 低(按量付费) | 低(上传/下载) | 历史归档、离线分析、大数据处理 |
| 专用记忆管理系统 | ✔ | ✔(分布式) | 高(定制检索) | 高 | 高(托管或专用部署) | 较高(需学习与集成) | 需要复杂长期+短期记忆、多实例一致性、审计和安全要求的 AI Agent 系统 |
三、MongoDB简单部署
开发过程使用可以使用 docker 快速部署单实体,生产环境建议采购高可用商业版本。
docker 运行命令如下:
docker run -d
--name mongo
--restart=always
--privileged=true
-p 27017:27017
-v /home/mongo/data:/data/db
-e MONGO_INITDB_ROOT_USERNAME=root
-e MONGO_INITDB_ROOT_PASSWORD=123456
mongodb/mongodb-community-server:7.0.16-ubi9
四、引入MongoDB依赖
① 父工程
使用 spring-boot-dependencies 版本清单管理器
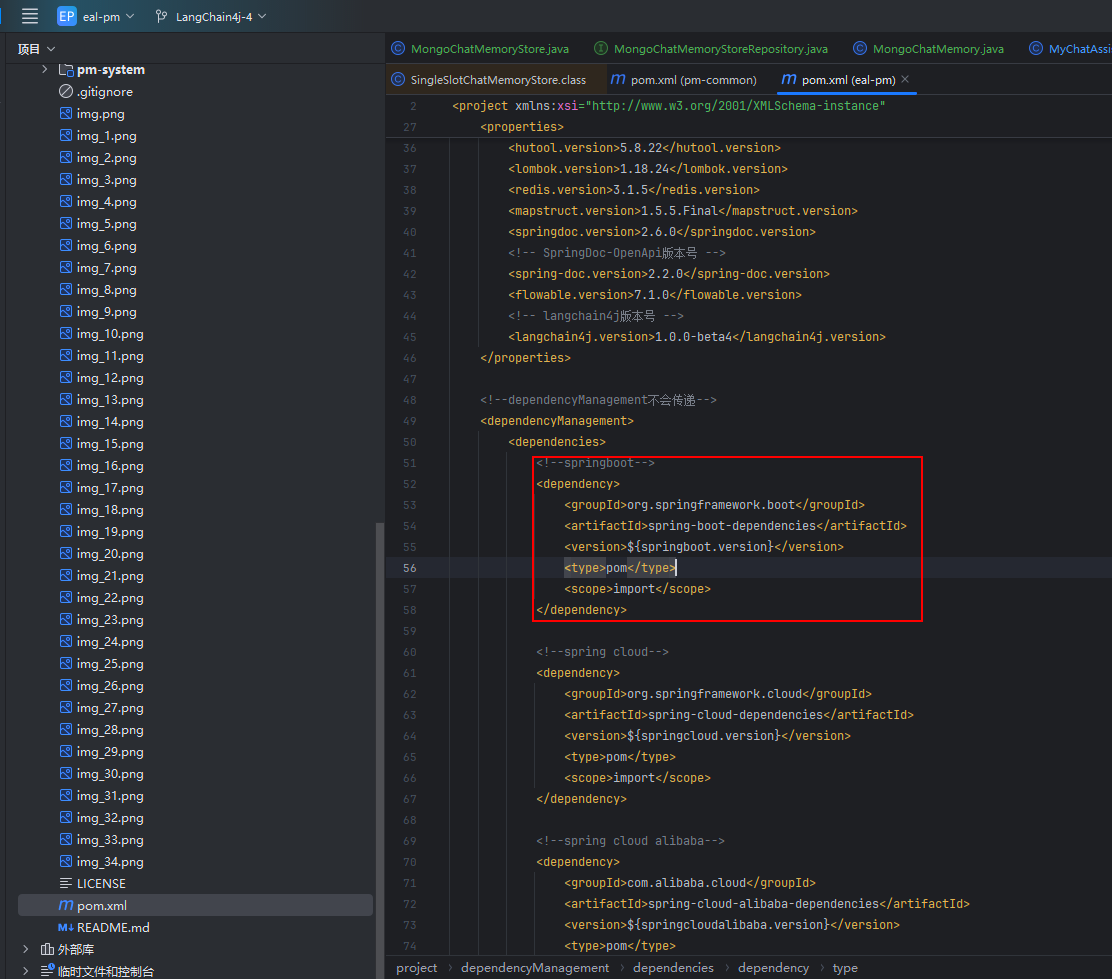
<!--springboot-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${springboot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>② 子工程
引入 spring-boot-starter-data-mongodb 即可,并且不需要指定版本号,由父工程统一管理。
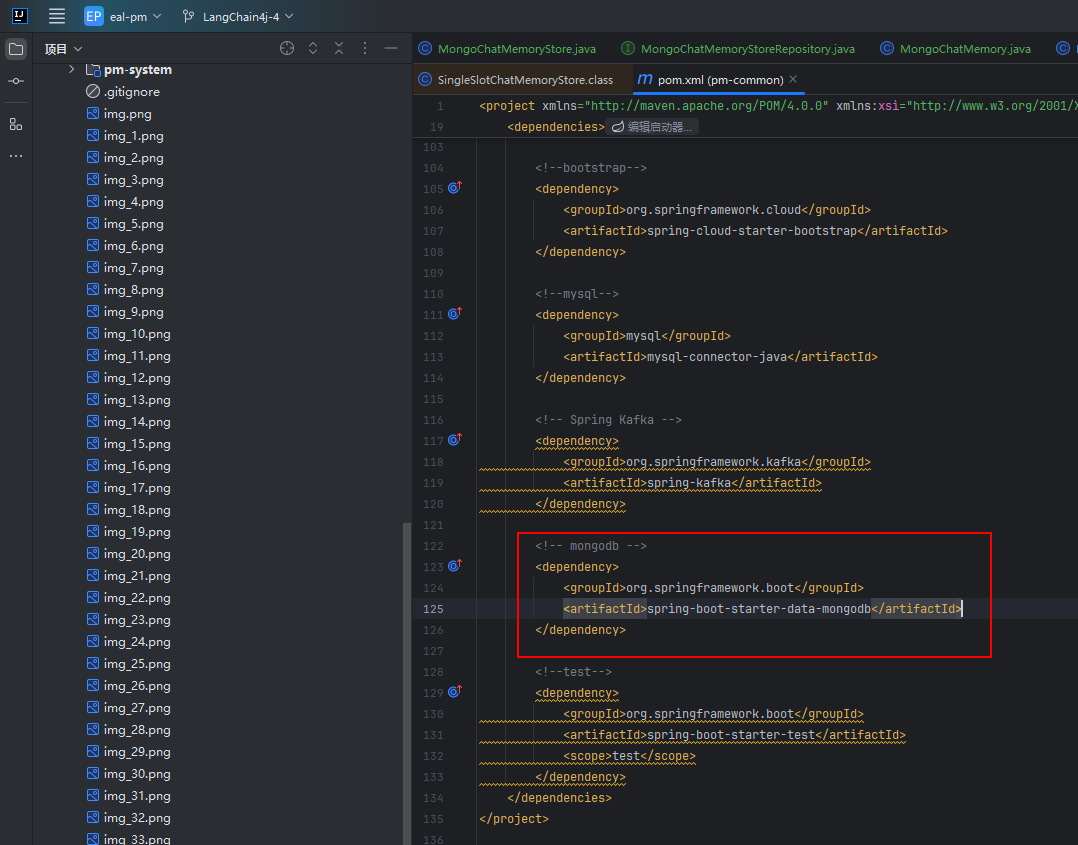
<!-- mongodb -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>③ 配置文件
在配置文件的 spring.config.data.mongodb 的配置项,配置 uri 连接信息,需要设置正确登录信息。
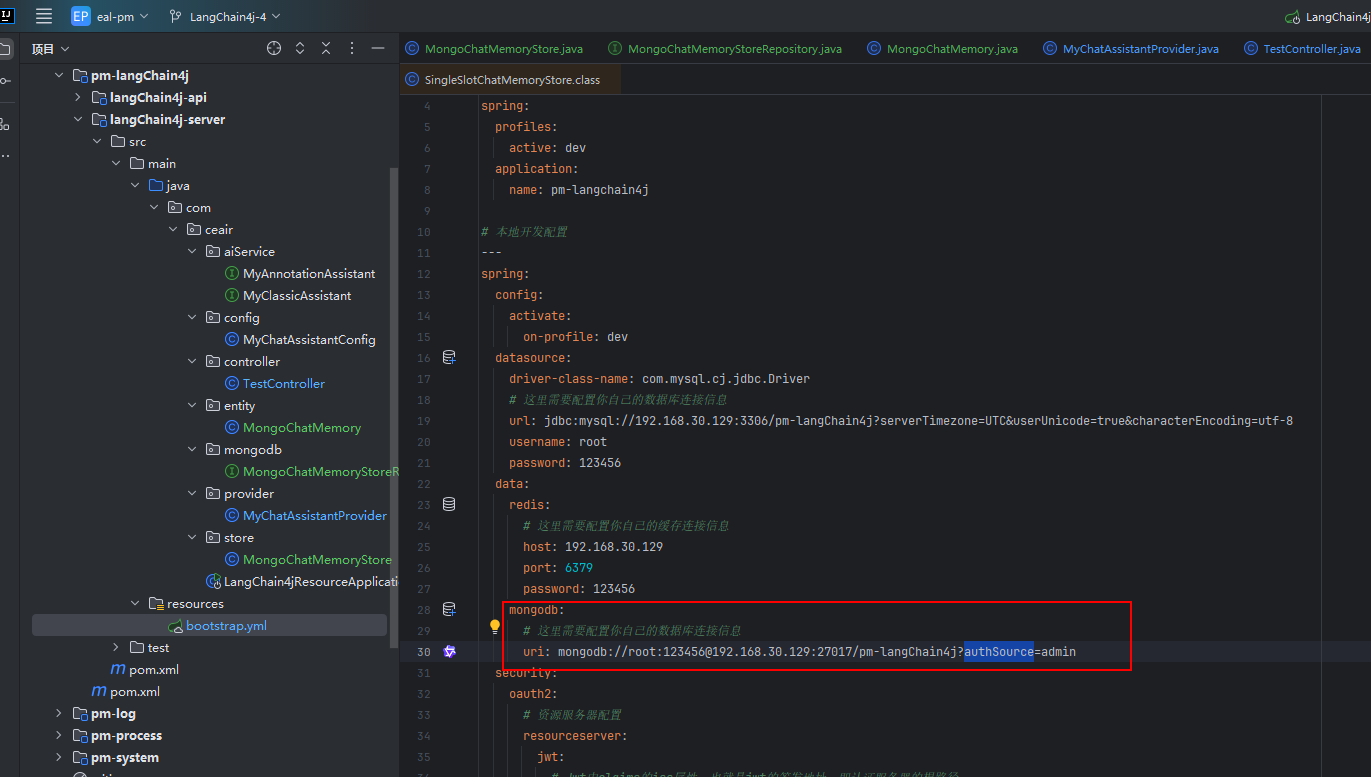
mongodb:
# 这里需要配置你自己的数据库连接信息
uri: mongodb://root:123456@192.168.30.129:27017/pm-langChain4j?authSource=admin五、源码解析
我们使用 MessageWindowChatMemory 工具构建记忆存储的,我们来看看源码,首先看看builder,可以看到实际存储的数据是通过实现 【ChatMemoryStore】接口的,如果当前没有则使用【SingleSlotChatMemoryStore】这个默认的实现类去保存数据 。
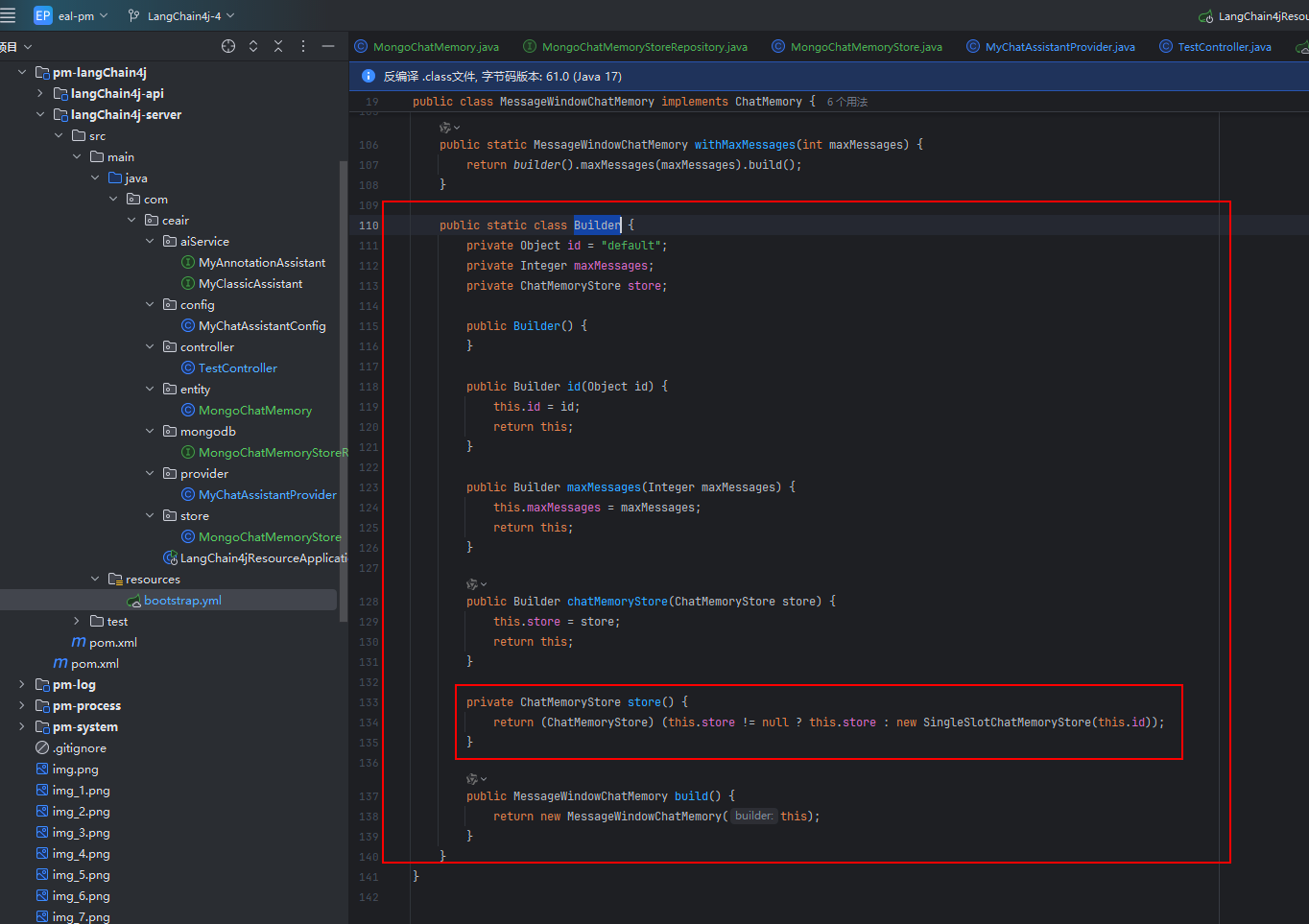
仔细看一下 【ChatMemoryStore】里有啥,原来是3个接口需要实现。
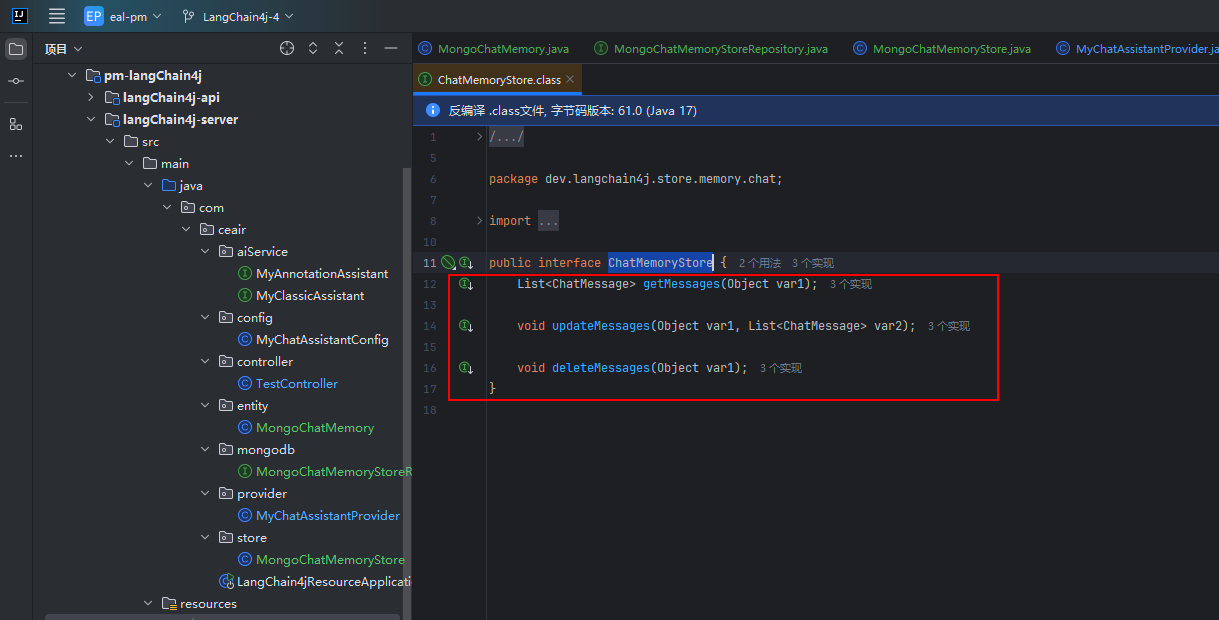
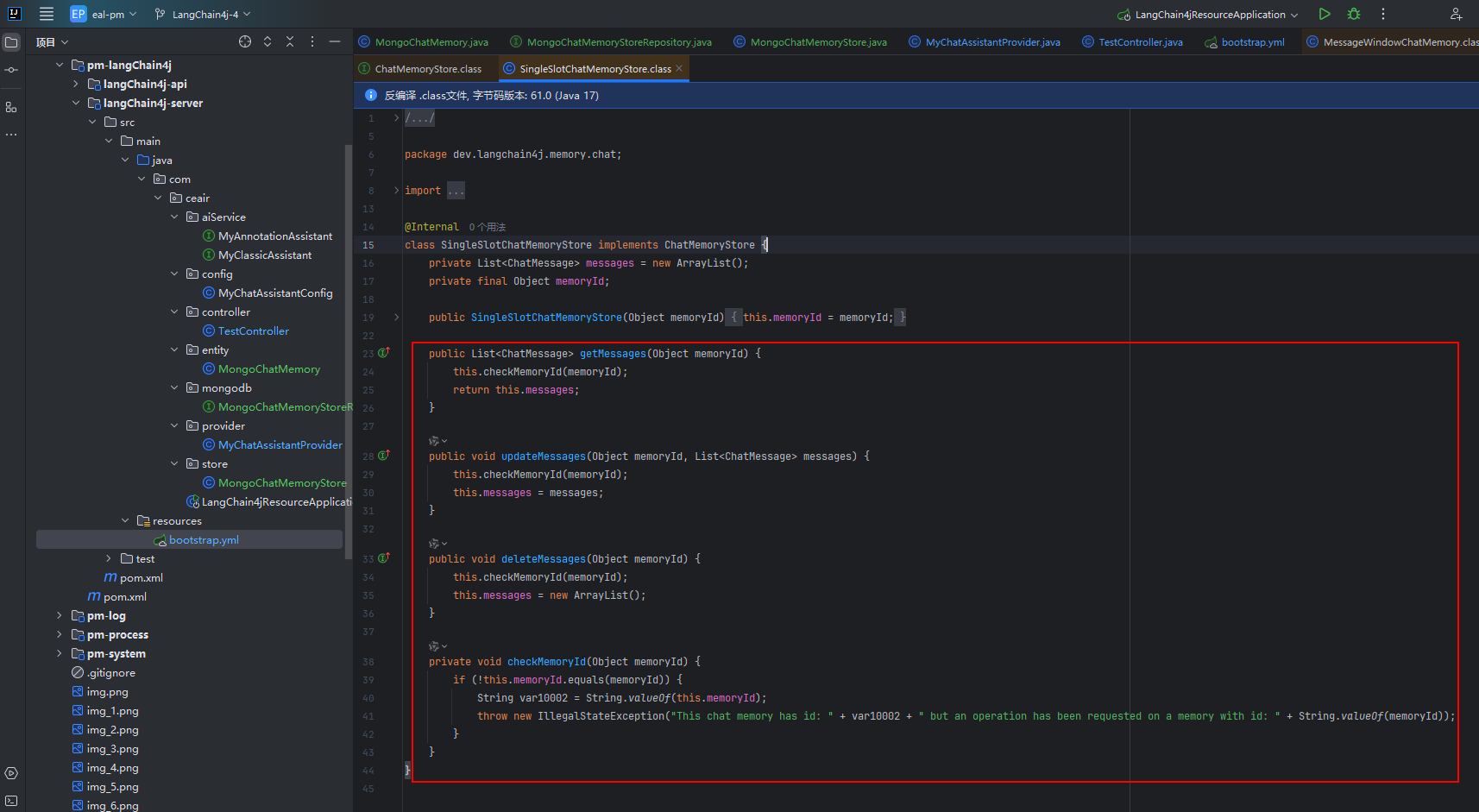
那我们看看默认的实现是怎么搞得,可以看到实际数据是通过 ArrayList 保存的,查询/更新/删除数据都是根据 【memoryId】来先判断是否符合和构造时的相等,只有相等时才会真正操作。
特别需要注意的一点:updateMessages方法执行的时候,源码里是直接用传入的数据替换了当前数据,所以其实是需要实现有数据就更新,没有数据就新增的逻辑。
六、自定义实现 ChatMemoryStore
根据源码可以知道,只要我们自定义实现 ChatMemoryStore,然后在 【MessageWindowChatMemory】Builder的时候设置进去,就可以替换默认的实现,也就可以修改默认的存储方式啦。
① 创建文档实体类
我们需要先定义文档的结构,参考源码,我们需要保存 【memoryId】用户区别用户,保存聊天内容。
package com.ceair.entity;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.mongodb.core.mapping.Document;
import java.io.Serial;
import java.io.Serializable;
/**
* @author wangbaohai
* @ClassName MongoChatMemory
* @description: 会话记忆实体-mongodb
* @date 2025年05月18日
* @version: 1.0.0
*/
@Data
@Document(collection = "mongo_chat_memory")
public class MongoChatMemory implements Serializable {
@Serial
private static final long serialVersionUID = 1L;
@Id
private String id;
// 聊天记录id
private int memoryId;
// 聊天记录列表的json字符串
private String content;
}
② 创建数据库操作工具
我们需要创建两个工具,一个是根据 【memoryId】修改内容,一个是根据【memoryId】删除数据。
修改工具使用@Query 注解来定位文档,使用 @Update 注解来更新文档。
删除工具使用默认在By关键字加首字母大写的字段名的方式实现。
package com.ceair.mongodb;
import com.ceair.entity.MongoChatMemory;
import org.springframework.data.mongodb.repository.MongoRepository;
import org.springframework.data.mongodb.repository.Query;
import org.springframework.data.mongodb.repository.Update;
import org.springframework.stereotype.Repository;
/**
* @author wangbaohai
* @ClassName MongoChatMemoryStore
* @description: 会话记忆存储读写工具
* @date 2025年05月18日
* @version: 1.0.0
*/
@Repository
public interface MongoChatMemoryStoreRepository extends MongoRepository<MongoChatMemory, String> {
/**
* 根据 memoryId 更新消息内容
* 此方法使用 MongoDB 的 @Query 注解来定位文档,然后使用 @Update 注解来更新文档中的 content 字段
* 这种方法确保了只更新匹配 memoryId 的文档的内容,而不会影响其他文档
*
* @param memoryId 消息的唯一标识符,用于定位要更新的消息
* @param content 新的消息内容,用于替换旧的内容
*/
@Query("{ 'memoryId' : ?0}")
@Update("{ '$set' : { 'content' : ?1 } }")
void updateMessagesByMemoryId(int memoryId, String content);
/**
* 根据memoryId删除特定的项
* 此方法用于从数据库或数据结构中删除与给定memoryId关联的项
*
* @param memoryId 需要删除的项的ID
*/
void deleteByMemoryId(int memoryId);
}
③ 实现类
主要就是实现3个方法
【getMessages】:根据传入的参数 【memoryId】查询数据,就有返回实际数据,没有数据则返回空集合。
【updateMessages】:根据传入的参数 【memoryId】查询数据,有数据就根据参数更新数据;没有数据则直接插入新数据。如果不插入新数据,在执行聊天的时候,会报错提示必须要有聊天数据传入。
【deleteMessages】:根据传入的参数 【memoryId】删除数据。
package com.ceair.store;
import com.ceair.entity.MongoChatMemory;
import com.ceair.mongodb.MongoChatMemoryStoreRepository;
import dev.langchain4j.data.message.ChatMessage;
import dev.langchain4j.data.message.ChatMessageDeserializer;
import dev.langchain4j.data.message.ChatMessageSerializer;
import dev.langchain4j.store.memory.chat.ChatMemoryStore;
import lombok.RequiredArgsConstructor;
import org.springframework.data.domain.Example;
import org.springframework.stereotype.Component;
import java.util.Collections;
import java.util.LinkedList;
import java.util.List;
import java.util.Objects;
/**
* @author wangbaohai
* @ClassName MongoChatMemoryStore
* @description: 存储会话记忆自定义实现-基于mongodb
* @date 2025年05月18日
* @version: 1.0.0
*/
@Component
@RequiredArgsConstructor
public class MongoChatMemoryStore implements ChatMemoryStore {
private final MongoChatMemoryStoreRepository mongoChatMemoryStoreRepository;
/**
* 根据输入的标识符对象获取对应的聊天消息列表。
*
* <p>该方法首先尝试将输入对象转换为字符串,并解析为整数类型的 messageId,
* 然后通过 Spring Data 的 Example 查询机制在 MongoDB 中查找对应的 MongoChatMemory 记录,
* 最后将其内容反序列化为 ChatMessage 列表返回。</p>
*
* <ul>
* <li>如果输入为 null 或无法解析为整数,则返回空列表。</li>
* <li>若数据库中未找到对应记录,也返回空列表。</li>
* </ul>
*
* @param o 表示消息标识符的对象,通常应为可解析为整数的字符串或数字类型。
* @return 与指定标识符关联的聊天消息列表,若不存在则返回空列表。
*/
@Override
public List<ChatMessage> getMessages(Object o) {
// 用于存储解析后的消息ID
int memoryId;
// 如果输入对象为空,直接返回空列表
if (o == null) {
return new LinkedList<>();
}
try {
// 将输入对象转为字符串并尝试解析为整数
String str = o.toString();
memoryId = Integer.parseInt(str);
} catch (NumberFormatException e) {
// 若字符串无法解析为整数,返回空列表
return new LinkedList<>();
}
// 构建查询条件:根据 memoryId 查询 MongoChatMemory 记录
MongoChatMemory mongoChatMemoryQuery = new MongoChatMemory();
mongoChatMemoryQuery.setMemoryId(memoryId);
Example<MongoChatMemory> example = Example.of(mongoChatMemoryQuery);
// 执行查询操作,findOne 返回 Optional 对象以避免空指针异常
MongoChatMemory mongoChatMemory = mongoChatMemoryStoreRepository.findOne(example).orElse(null);
// 如果查到记录,使用 ChatMessageDeserializer 反序列化 JSON 内容为 ChatMessage 列表
if (mongoChatMemory != null) {
return ChatMessageDeserializer.messagesFromJson(mongoChatMemory.getContent());
} else {
// 若未查到记录,返回空列表
return new LinkedList<>();
}
}
/**
* 更新消息列表
* 此方法旨在将给定的消息列表更新到数据库中,基于一个标识符来定位消息组
* 它首先检查提供的对象是否可以转换为整数(消息ID),然后使用该ID更新消息列表
* 如果提供的对象为空或消息列表为空,此方法将不执行任何操作
*
* @param o 一个对象,预期为一个可以转换为整数的字符串,用作消息ID
* @param list 一个ChatMessage对象列表,包含要更新的消息
*/
@Override
public void updateMessages(Object o, List<ChatMessage> list) {
// 用于存储解析后的消息ID
int memoryId;
// 如果输入对象为空,直接返回空列表
if (o != null && !list.isEmpty()) {
try {
// 将输入对象转为字符串并尝试解析为整数
String str = o.toString();
memoryId = Integer.parseInt(str);
} catch (NumberFormatException e) {
// 若字符串无法解析为整数,不执行更新操作
return;
}
// 构建查询条件:根据 memoryId 查询 MongoChatMemory 记录
MongoChatMemory mongoChatMemoryQuery = new MongoChatMemory();
mongoChatMemoryQuery.setMemoryId(memoryId);
Example<MongoChatMemory> example = Example.of(mongoChatMemoryQuery);
// 先执行查询操作,findOne 返回 Optional 对象以避免空指针异常
MongoChatMemory mongoChatMemory = mongoChatMemoryStoreRepository.findOne(example).orElse(null);
if (!Objects.isNull(mongoChatMemory)) {
// 如果查到记录,使用 ChatMessageDeserializer 反序列化 JSON 内容为 ChatMessage 列表
// 调用MongoDB存储库方法,按消息ID更新消息列表
mongoChatMemoryStoreRepository.updateMessagesByMemoryId(memoryId,
ChatMessageSerializer.messagesToJson(list));
} else {
// 如果未查到记录,执行新增操作
MongoChatMemory toAddMongoChatMemory = new MongoChatMemory();
toAddMongoChatMemory.setMemoryId(memoryId);
toAddMongoChatMemory.setContent(ChatMessageSerializer.messagesToJson(list));
mongoChatMemoryStoreRepository.save(toAddMongoChatMemory);
}
}
}
/**
* 重写删除消息方法
* 该方法旨在处理和删除给定的对象所代表的消息
* 它首先尝试将输入对象解析为消息ID,然后执行删除操作
*
* @param o 待删除的消息的标识对象它可以是一个能够被转换为整数字符串的任意对象
*/
@Override
public void deleteMessages(Object o) {
// 用于存储解析后的消息ID
int memoryId;
// 如果输入对象为空,直接返回空列表
if (o != null) {
try {
// 将输入对象转为字符串并尝试解析为整数
String str = o.toString();
memoryId = Integer.parseInt(str);
} catch (NumberFormatException e) {
// 若字符串无法解析为整数,不执行删除操作
return;
}
// 派生查询方式 执行删除操作
mongoChatMemoryStoreRepository.deleteByMemoryId(memoryId);
}
}
}
七、创建 AiService
上一篇文章,我们是通过 AiServices 的 Builder工具创建的 AiService。
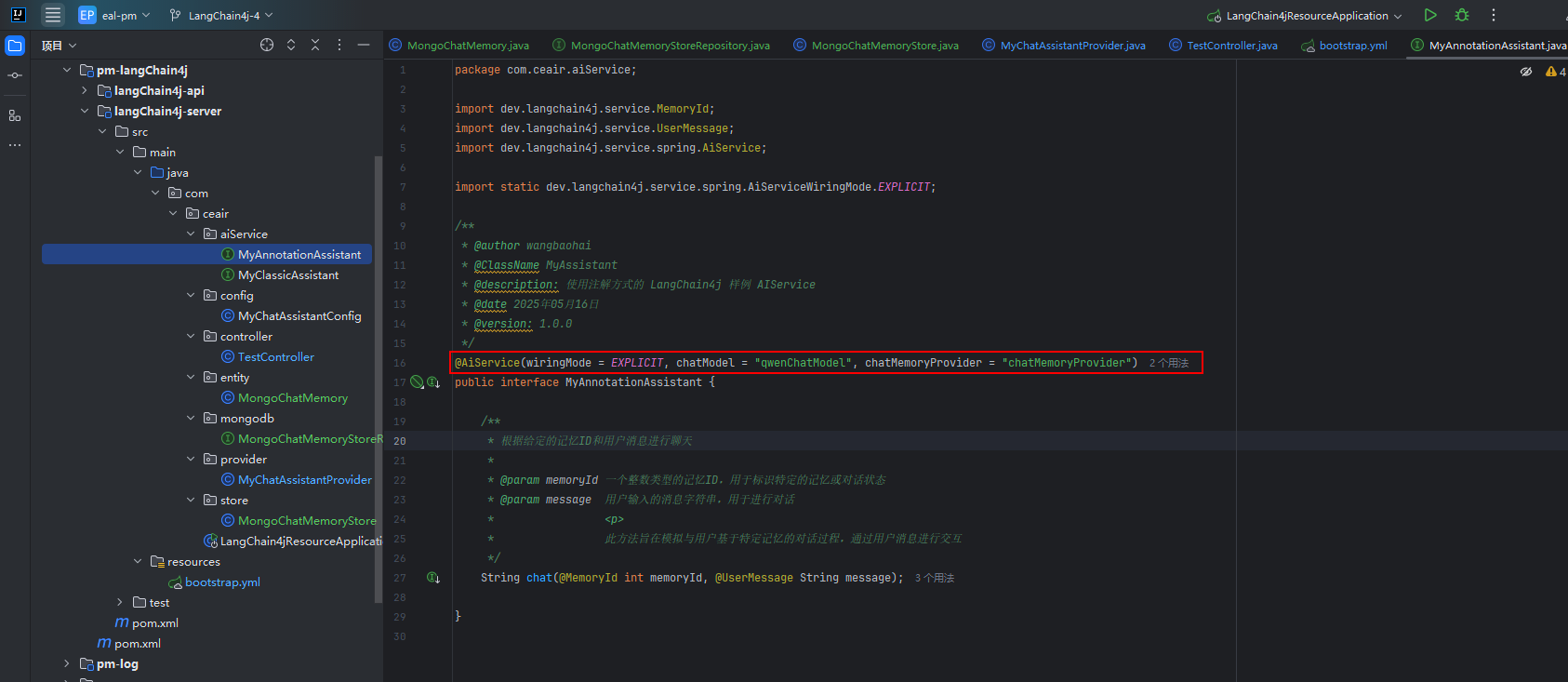
AiSerivce 同时还提供了注解的方式创建,我们可以在注解中直接指定模型能力和 chatMemoryProvider。
package com.ceair.aiService;
import dev.langchain4j.service.MemoryId;
import dev.langchain4j.service.UserMessage;
import dev.langchain4j.service.spring.AiService;
import static dev.langchain4j.service.spring.AiServiceWiringMode.EXPLICIT;
/**
* @author wangbaohai
* @ClassName MyAssistant
* @description: 使用注解方式的 LangChain4j 样例 AIService
* @date 2025年05月16日
* @version: 1.0.0
*/
@AiService(wiringMode = EXPLICIT, chatModel = "qwenChatModel", chatMemoryProvider = "chatMemoryProvider")
public interface MyAnnotationAssistant {
/**
* 根据给定的记忆ID和用户消息进行聊天
*
* @param memoryId 一个整数类型的记忆ID,用于标识特定的记忆或对话状态
* @param message 用户输入的消息字符串,用于进行对话
* <p>
* 此方法旨在模拟与用户基于特定记忆的对话过程,通过用户消息进行交互
*/
String chat(@MemoryId int memoryId, @UserMessage String message);
}
chatMemoryProvider 这个工具需要我们向SpringIOC容器声明注入Bean,需要注意的是,注解指定的名字一定要和 Bean 名保持一致,在声明 chatMemoryProvider 的时候,我们就可以注入我们自定义的存储实现了。
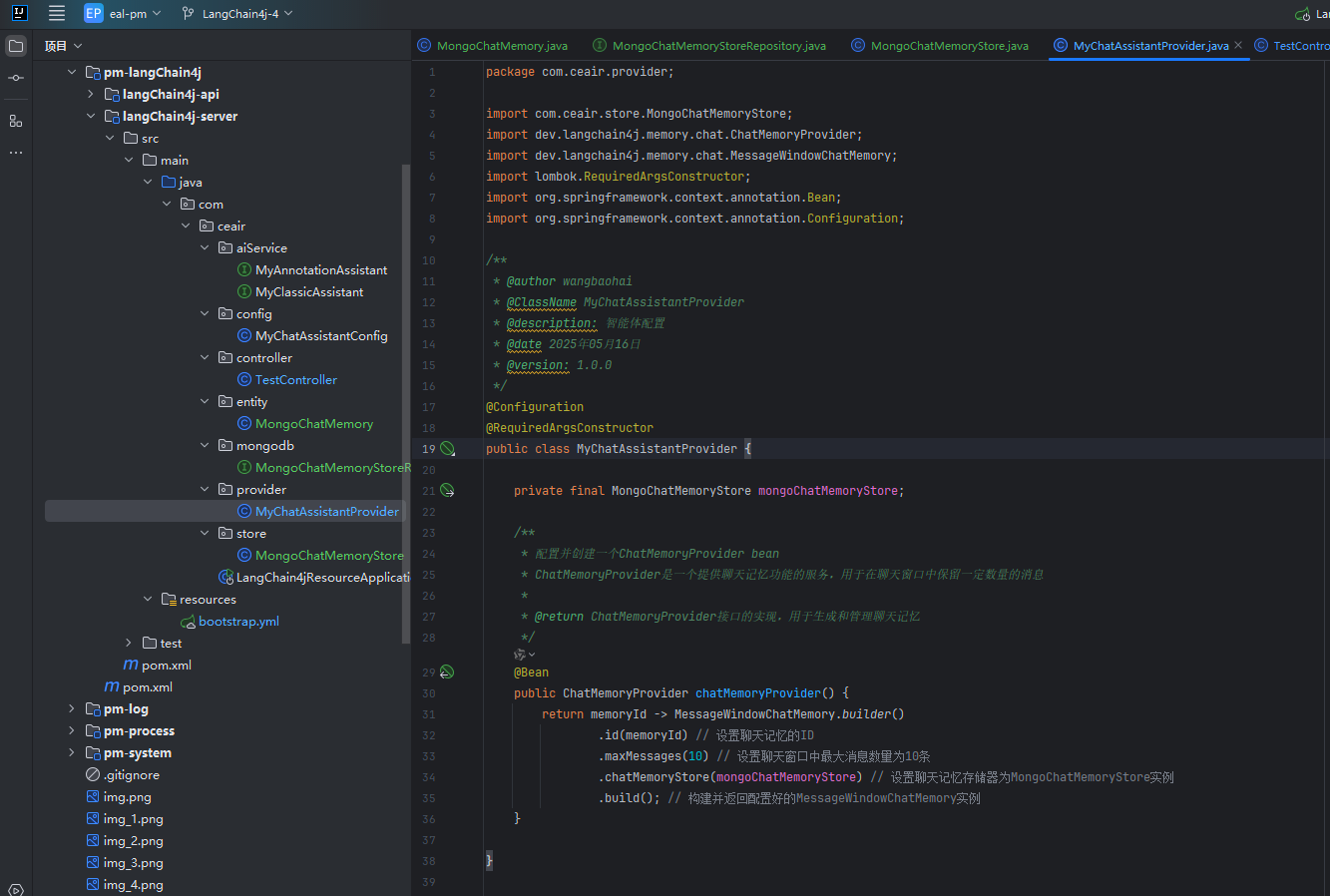
package com.ceair.provider;
import com.ceair.store.MongoChatMemoryStore;
import dev.langchain4j.memory.chat.ChatMemoryProvider;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import lombok.RequiredArgsConstructor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author wangbaohai
* @ClassName MyChatAssistantProvider
* @description: 智能体配置
* @date 2025年05月16日
* @version: 1.0.0
*/
@Configuration
@RequiredArgsConstructor
public class MyChatAssistantProvider {
private final MongoChatMemoryStore mongoChatMemoryStore;
/**
* 配置并创建一个ChatMemoryProvider bean
* ChatMemoryProvider是一个提供聊天记忆功能的服务,用于在聊天窗口中保留一定数量的消息
*
* @return ChatMemoryProvider接口的实现,用于生成和管理聊天记忆
*/
@Bean
public ChatMemoryProvider chatMemoryProvider() {
return memoryId -> MessageWindowChatMemory.builder()
.id(memoryId) // 设置聊天记忆的ID
.maxMessages(10) // 设置聊天窗口中最大消息数量为10条
.chatMemoryStore(mongoChatMemoryStore) // 设置聊天记忆存储器为MongoChatMemoryStore实例
.build(); // 构建并返回配置好的MessageWindowChatMemory实例
}
}
八、验证功能
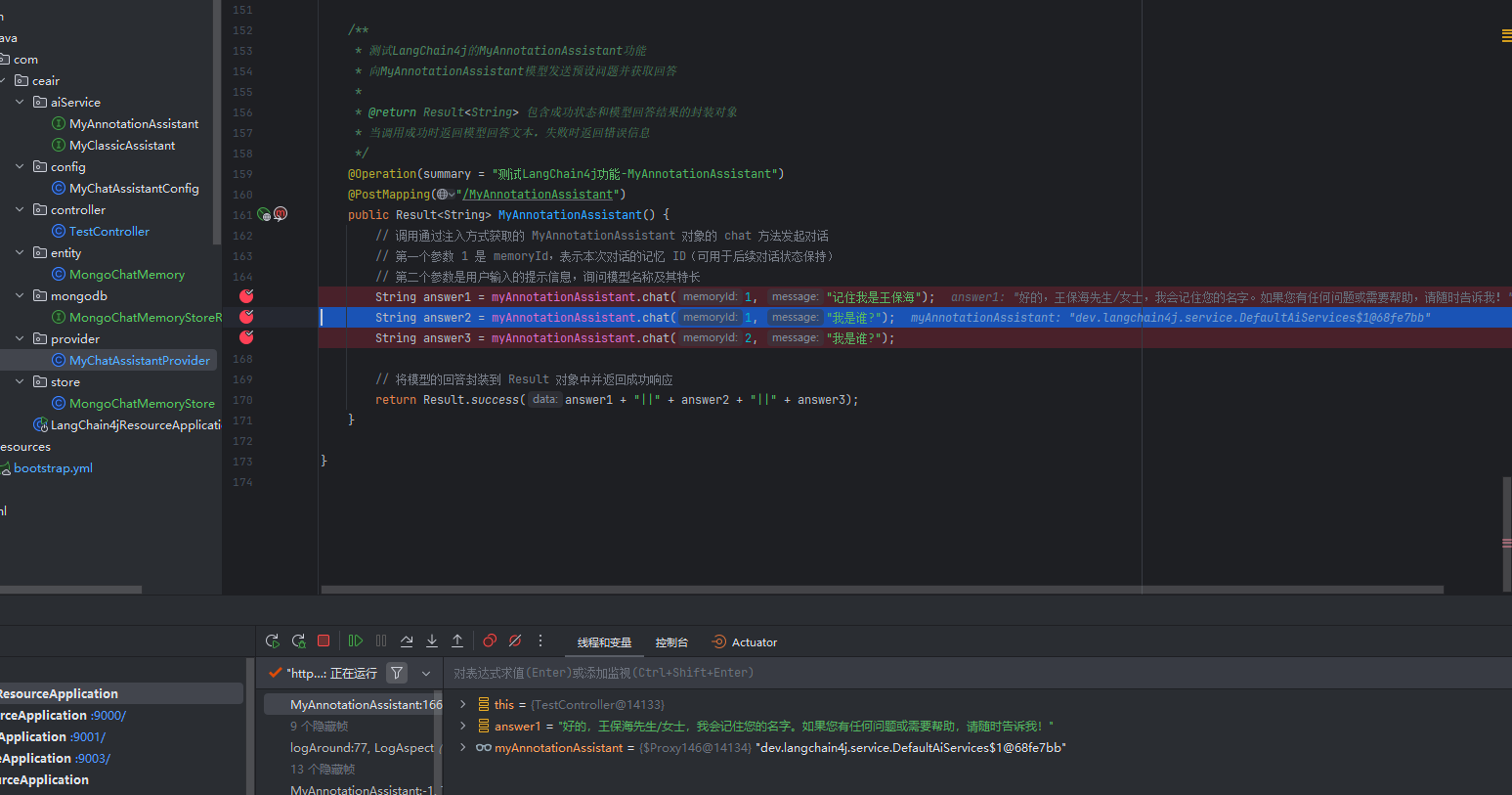
① 创建测试接口
/**
* 测试LangChain4j的MyAnnotationAssistant功能
* 向MyAnnotationAssistant模型发送预设问题并获取回答
*
* @return Result<String> 包含成功状态和模型回答结果的封装对象
* 当调用成功时返回模型回答文本,失败时返回错误信息
*/
@Operation(summary = "测试LangChain4j功能-MyAnnotationAssistant")
@PostMapping("/MyAnnotationAssistant")
public Result<String> MyAnnotationAssistant() {
// 调用通过注入方式获取的 MyAnnotationAssistant 对象的 chat 方法发起对话
// 第一个参数 1 是 memoryId,表示本次对话的记忆 ID(可用于后续对话状态保持)
// 第二个参数是用户输入的提示信息,询问模型名称及其特长
String answer1 = myAnnotationAssistant.chat(1, "记住我是王保海");
String answer2 = myAnnotationAssistant.chat(1, "我是谁?");
String answer3 = myAnnotationAssistant.chat(2, "我是谁?");
// 将模型的回答封装到 Result 对象中并返回成功响应
return Result.success(answer1 + "||" + answer2 + "||" + answer3);
}② 执行测试
此步骤直接展示接口调用结果,测试具体步骤请查看专栏第一篇文章的测试章节。
(1) 第一次问答
我们看一下第一次回答后,我们持久化的数据是什么,可以发现一开始没有问题数据,我们成功创建了初始的数据。
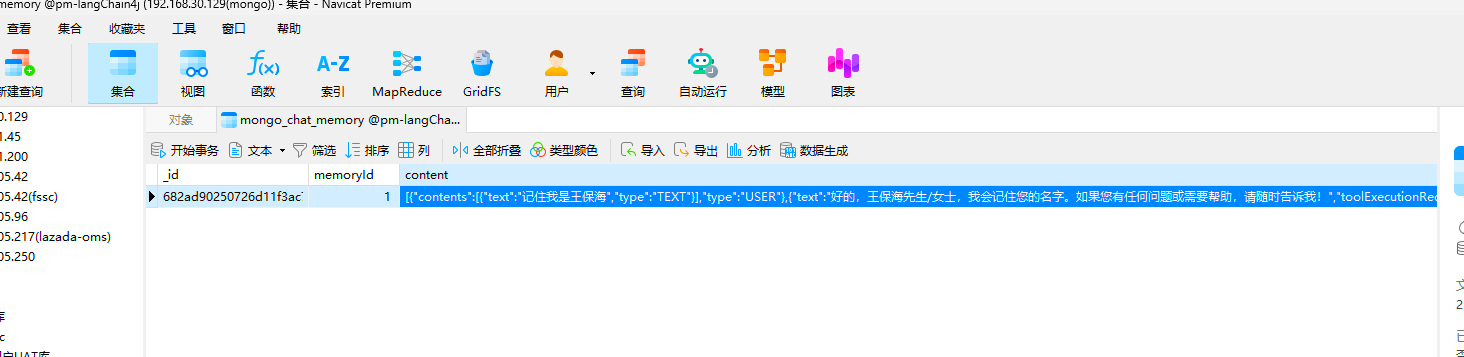
[{"contents":[{"text":"记住我是王保海","type":"TEXT"}],"type":"USER"},{"text":"好的,王保海先生/女士,我会记住您的名字。如果您有任何问题或需要帮助,请随时告诉我!","toolExecutionRequests":[],"type":"AI"}]
(2) 第二次问答
我们再看一下第二次回答后数据的样子,可以看到由于第二次问答的 menoryId 是一样的,直接降新的问答数据更新进去了。
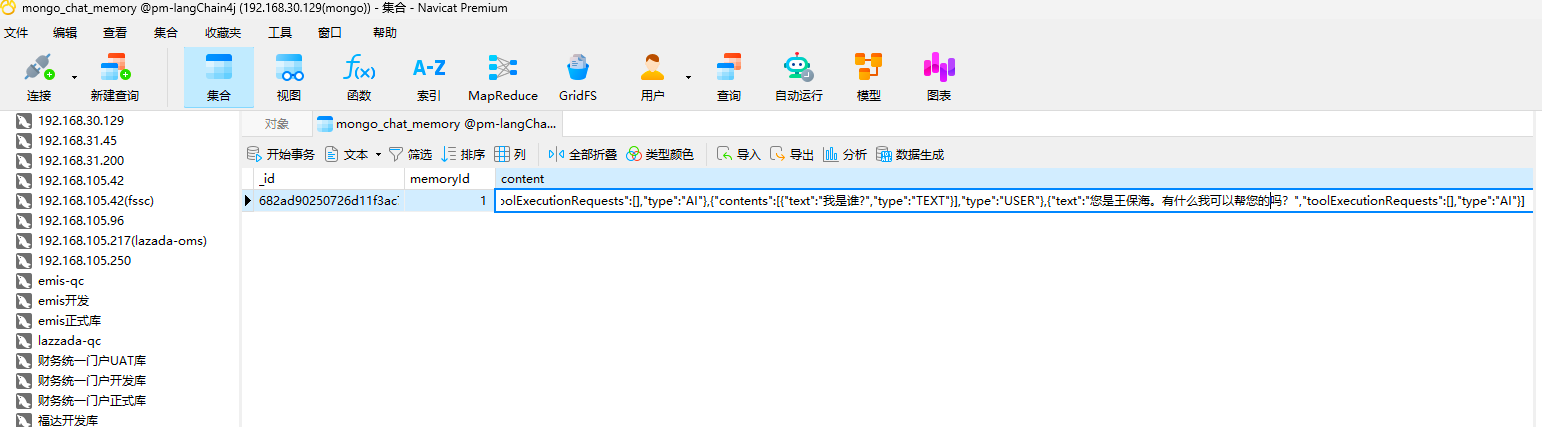
[{"contents":[{"text":"记住我是王保海","type":"TEXT"}],"type":"USER"},{"text":"好的,王保海先生/女士,我会记住您的名字。如果您有任何问题或需要帮助,请随时告诉我!","toolExecutionRequests":[],"type":"AI"},{"contents":[{"text":"我是谁?","type":"TEXT"}],"type":"USER"},{"text":"您是王保海。有什么我可以帮您的吗?","toolExecutionRequests":[],"type":"AI"}]
(3) 第三次问答
看一下最后一次问答后的数据,可以看到由于第二次问答的 menoryId 是不一样的,创建了一个新的问答数据,也没有能获得记忆数据。
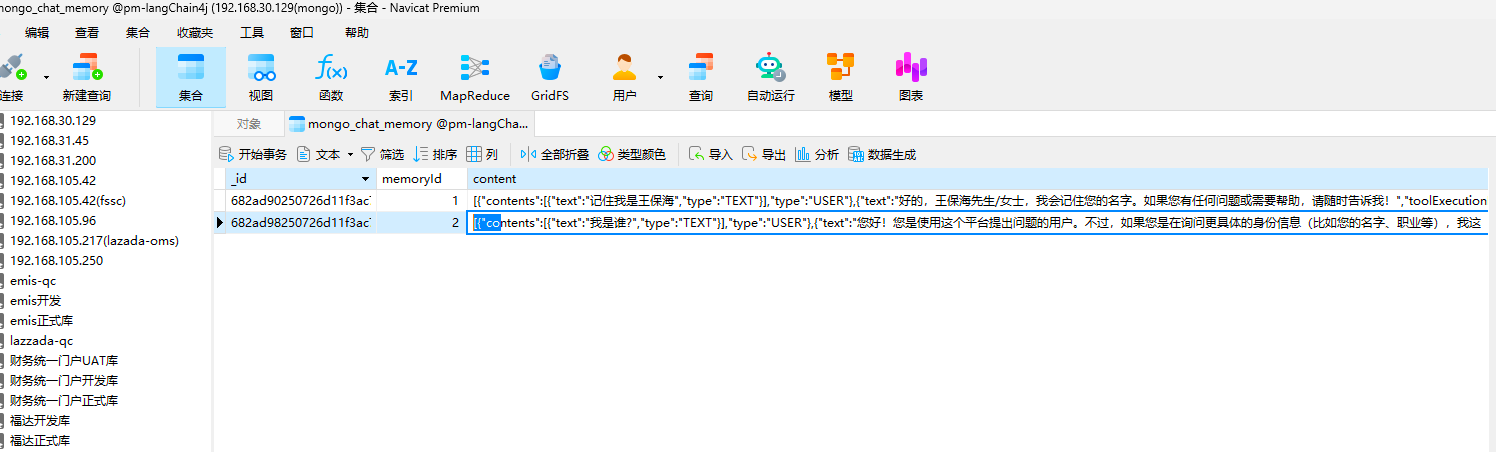
[{"contents":[{"text":"我是谁?","type":"TEXT"}],"type":"USER"},{"text":"您好!您是使用这个平台提出问题的用户。不过,如果您是在询问更具体的身份信息(比如您的名字、职业等),我这边无法获取到这些个人信息,因为我是根据保护用户隐私的原则设计的。如果您有其他想要了解的问题或需要帮助的地方,欢迎您告诉我!","toolExecutionRequests":[],"type":"AI"}]
后记
按照一篇文章一个代码分支,本文的后端工程的分支都是 LangChain4j-4,前端工程的分支是 LangChain4j-1。
后端工程仓库:后端工程
前端工程仓库:前端工程

















 3981
3981

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









