






文章目录
前言
参考资料:
一、Attention机制原理
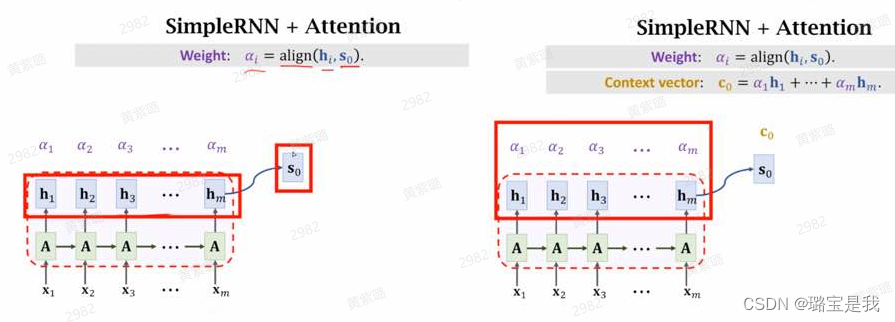
这里的c0是表示加权和。
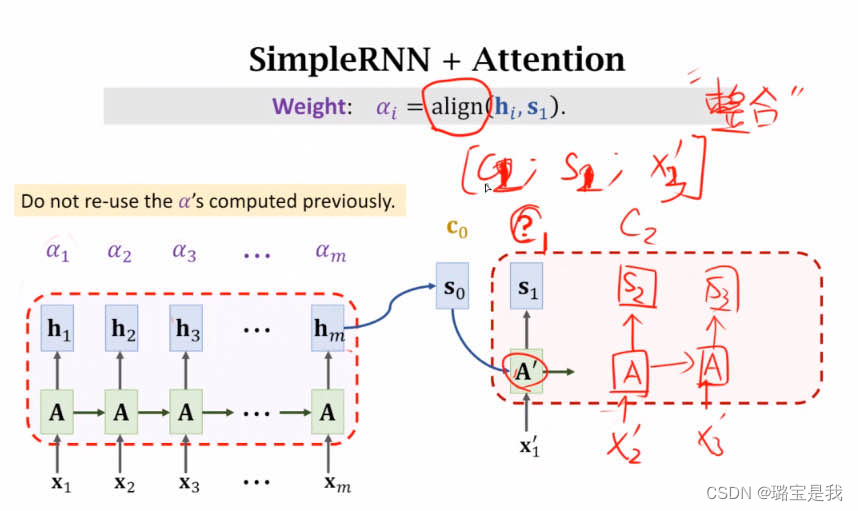
得到c0后,将[c0; s0; x1’]作为输入,通过隐藏层A’得到s1;
之后再用weight的公式,计算s1与hi的相似度ai,再次对应相乘相加得到c1;
得到c1后,将[c1; s2; x2’]作为输入,通过隐藏层A’得到s2;
如此循环。
这里的x1’,x2’,等表示decoder的input,即标签。
1. align函数

2. [c0; s0; x1’]如何做整合?
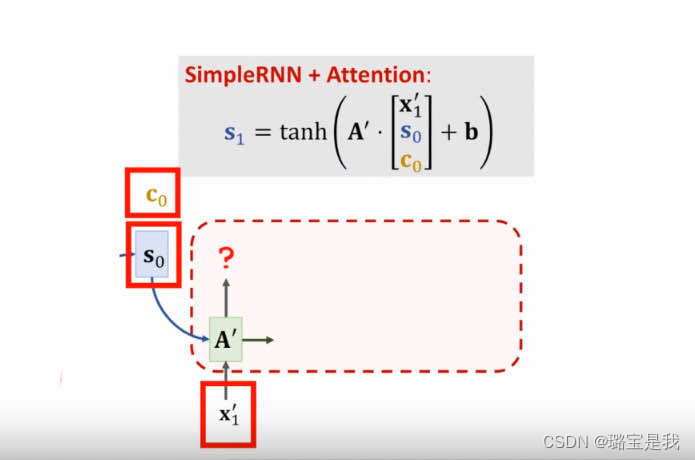
大括号中为一个放射变换。
二、pytorch实现
1.数据预处理
不管是英语还是德语,每句话长度都是不固定的,所以我对于每个 batch 内的句子,将它们的长度通过加 《PAD》 变得一样,也就说,一个 batch 内的句子,长度都是相同的,不同 batch 内的句子长度不一定相同。
- 开头加上《sos》作为开始标志,结尾加上《eos》作为结束标志。
- 如果句子不够长,再《eos》后面加《pad》作为填充。
- 德语和英语(本例中)需要分别构建词库,分别创建索引,不能共用词库。
2.Encoder

- 此处的output对应上面第一张图中的h1…hm
- hidden表示最后一个时刻所有隐藏层的输出,如下图所示

- s0表示最后一层最后一个时刻的输出,而hidden是指最后一个时刻的所有隐藏层的输出,因此要通过索引得到最后一层的输出
- 把hidden[-1, ; , ;]与-2拼接起来,得到s0
hidden的维度:【4,b,enc_hid_dim】
hidden[-1, ; , ;]【b, enc_hid_dim】
hidden[-2, ; , ;]【b, enc_hid_dim】
拼接之后:s0【b, enc_hid_dim*2】


class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, enc_hid_dim, dec_hid_dim, dropout):
super().__init__()
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.GRU(emb_dim, enc_hid_dim, bidirectional = True)
self.fc = nn.Linear(enc_hid_dim * 2, dec_hid_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, src):
'''
src = [src_len, batch_size]
'''
src = src.transpose(0, 1) # src = [batch_size, src_len]
embedded = self.dropout(self.embedding(src)).transpose(0, 1) # embedded = [src_len, batch_size, emb_dim]
# enc_output = [src_len, batch_size, hid_dim * num_directions]
# enc_hidden = [n_layers * num_directions, batch_size, hid_dim]
enc_output, enc_hidden = self.rnn(embedded) # if h_0 is not give, it will be set 0 acquiescently
# enc_hidden is stacked [forward_1, backward_1, forward_2, backward_2, ...]
# enc_output are always from the last layer
# enc_hidden [-2, :, : ] is the last of the forwards RNN
# enc_hidden [-1, :, : ] is the last of the backwards RNN
# initial decoder hidden is final hidden state of the forwards and backwards
# encoder RNNs fed through a linear layer
# s = [batch_size, dec_hid_dim]
s = torch.tanh(self.fc(torch.cat((enc_hidden[-2,:,:], enc_hidden[-1,:,:]), dim = 1)))
return enc_output, s
3.Attention
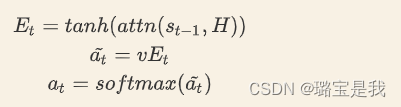
class Attention(nn.Module):
def __init__(self, enc_hid_dim, dec_hid_dim):
super().__init__()
self.attn = nn.Linear((enc_hid_dim * 2) + dec_hid_dim, dec_hid_dim, bias=False)
self.v = nn.Linear(dec_hid_dim, 1, bias = False)
def forward(self, s, enc_output):
# s = [batch_size, dec_hid_dim]
# enc_output = [src_len, batch_size, enc_hid_dim * 2]
batch_size = enc_output.shape[1]
src_len = enc_output.shape[0]
# repeat decoder hidden state src_len times
# s = [batch_size, src_len, dec_hid_dim]
# enc_output = [batch_size, src_len, enc_hid_dim * 2]
s = s.unsqueeze(1).repeat(1, src_len, 1)
enc_output = enc_output.transpose(0, 1)
# energy = [batch_size, src_len, dec_hid_dim]
energy = torch.tanh(self.attn(torch.cat((s, enc_output), dim = 2)))
# attention = [batch_size, src_len]
attention = self.v(energy).squeeze(2)
return F.softmax(attention, dim=1)
4.Seq2Seq
传统 Seq2Seq 是直接将句子中每个词连续不断输入 Decoder 进行训练,而引入 Attention 机制之后,我需要能够人为控制一个词一个词进行输入(因为输入每个词到 Decoder,需要再做一些运算)
Teacher Forcing
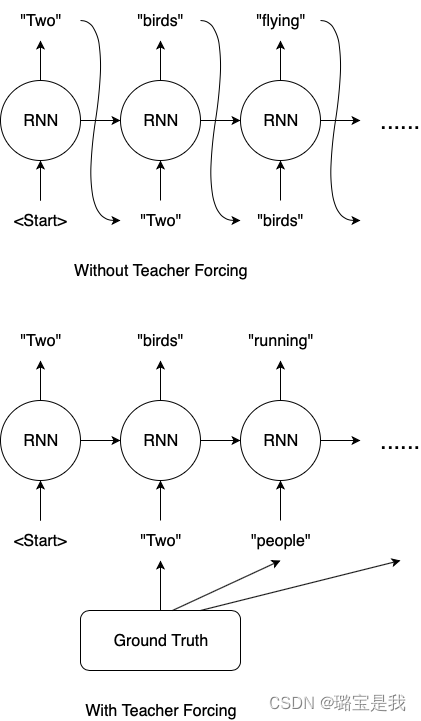
两种不同的训练方式:
- 不管上一时刻输出是什么,当前时刻的输入总是规定好的,按照给定的 target 进行输入。
- 当前时刻的输入和上一时刻的输出,是有关联的。具体来说就是,当前时刻的输入就是上一时刻的输出。
第一种训练方法的问题:
-
在解码的时候生成的字符都会受到 Ground-Truth 的约束,希望模型生成的结果都必须和参考句一一对应。这种约束在训练过程中减少模型发散,加快收敛速度。但是一方面也扼杀了翻译多样性的可能。
-
在这种约束下,还会导致一种叫做 Overcorrect (矫枉过正) 的问题。
第二种训练方法的问题:
- 难以收敛。
Teacher Forcing
- 而 Teacher Forcing 正好介于上述两种训练方法之间。具体来说就是,训练过程中的每个时刻,有一定概率使用上一时刻的输出作为输入,也有一定概率使用正确的 target 作为输入。
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, src, trg, teacher_forcing_ratio = 0.5):
# src = [src_len, batch_size]
# trg = [trg_len, batch_size]
# teacher_forcing_ratio is probability to use teacher forcing
batch_size = src.shape[1]
trg_len = trg.shape[0]
trg_vocab_size = self.decoder.output_dim
# tensor to store decoder outputs
outputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device)
# enc_output is all hidden states of the input sequence, back and forwards
# s is the final forward and backward hidden states, passed through a linear layer
enc_output, s = self.encoder(src)
# first input to the decoder is the <sos> tokens
dec_input = trg[0,:]
for t in range(1, trg_len):
# insert dec_input token embedding, previous hidden state and all encoder hidden states
# receive output tensor (predictions) and new hidden state
dec_output, s = self.decoder(dec_input, s, enc_output)
# place predictions in a tensor holding predictions for each token
outputs[t] = dec_output
# decide if we are going to use teacher forcing or not
teacher_force = random.random() < teacher_forcing_ratio
# get the highest predicted token from our predictions
top1 = dec_output.argmax(1)
# if teacher forcing, use actual next token as next input
# if not, use predicted token
dec_input = trg[t] if teacher_force else top1
return outputs
5.Decoder
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, enc_hid_dim, dec_hid_dim, dropout, attention):
super().__init__()
self.output_dim = output_dim
self.attention = attention
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.GRU((enc_hid_dim * 2) + emb_dim, dec_hid_dim)
self.fc_out = nn.Linear((enc_hid_dim * 2) + dec_hid_dim + emb_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, dec_input, s, enc_output):
# dec_input = [batch_size]
# s = [batch_size, dec_hid_dim]
# enc_output = [src_len, batch_size, enc_hid_dim * 2]
dec_input = dec_input.unsqueeze(1) # dec_input = [batch_size, 1]
embedded = self.dropout(self.embedding(dec_input)).transpose(0, 1) # embedded = [1, batch_size, emb_dim]
# a = [batch_size, 1, src_len]
a = self.attention(s, enc_output).unsqueeze(1)
# enc_output = [batch_size, src_len, enc_hid_dim * 2]
enc_output = enc_output.transpose(0, 1)
# c = [1, batch_size, enc_hid_dim * 2]
c = torch.bmm(a, enc_output).transpose(0, 1)
# rnn_input = [1, batch_size, (enc_hid_dim * 2) + emb_dim]
rnn_input = torch.cat((embedded, c), dim = 2)
# dec_output = [src_len(=1), batch_size, dec_hid_dim]
# dec_hidden = [n_layers * num_directions, batch_size, dec_hid_dim]
dec_output, dec_hidden = self.rnn(rnn_input, s.unsqueeze(0))
# embedded = [batch_size, emb_dim]
# dec_output = [batch_size, dec_hid_dim]
# c = [batch_size, enc_hid_dim * 2]
embedded = embedded.squeeze(0)
dec_output = dec_output.squeeze(0)
c = c.squeeze(0)
# pred = [batch_size, output_dim]
pred = self.fc_out(torch.cat((dec_output, c, embedded), dim = 1))
return pred, dec_hidden.squeeze(0)
代码(from nlp tutorial)
# %%
# code by Tae Hwan Jung @graykode
# Reference : https://github.com/hunkim/PyTorchZeroToAll/blob/master/14_2_seq2seq_att.py
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
# S: Symbol that shows starting of decoding input
# E: Symbol that shows starting of decoding output
# P: Symbol that will fill in blank sequence if current batch data size is short than time steps
def make_batch():
input_batch = [np.eye(n_class)[[word_dict[n] for n in sentences[0].split()]]]
output_batch = [np.eye(n_class)[[word_dict[n] for n in sentences[1].split()]]]
target_batch = [[word_dict[n] for n in sentences[2].split()]]
# make tensor
return torch.FloatTensor(input_batch), torch.FloatTensor(output_batch), torch.LongTensor(target_batch)
class Attention(nn.Module):
def __init__(self):
super(Attention, self).__init__()
self.enc_cell = nn.RNN(input_size=n_class, hidden_size=n_hidden, dropout=0.5)
self.dec_cell = nn.RNN(input_size=n_class, hidden_size=n_hidden, dropout=0.5)
# Linear for attention
self.attn = nn.Linear(n_hidden, n_hidden)
self.out = nn.Linear(n_hidden * 2, n_class)
def forward(self, enc_inputs, hidden, dec_inputs):
enc_inputs = enc_inputs.transpose(0, 1) # enc_inputs: [n_step(=n_step, time step), batch_size, n_class]
dec_inputs = dec_inputs.transpose(0, 1) # dec_inputs: [n_step(=n_step, time step), batch_size, n_class]
# enc_outputs : [n_step, batch_size, num_directions(=1) * n_hidden], matrix F
# enc_hidden : [num_layers(=1) * num_directions(=1), batch_size, n_hidden]
enc_outputs, enc_hidden = self.enc_cell(enc_inputs, hidden)
trained_attn = []
hidden = enc_hidden
n_step = len(dec_inputs)
model = torch.empty([n_step, 1, n_class])
for i in range(n_step): # each time step
# dec_output : [n_step(=1), batch_size(=1), num_directions(=1) * n_hidden]
# hidden : [num_layers(=1) * num_directions(=1), batch_size(=1), n_hidden]
dec_output, hidden = self.dec_cell(dec_inputs[i].unsqueeze(0), hidden)
attn_weights = self.get_att_weight(dec_output, enc_outputs) # attn_weights : [1, 1, n_step]
trained_attn.append(attn_weights.squeeze().data.numpy())
# matrix-matrix product of matrices [1,1,n_step] x [1,n_step,n_hidden] = [1,1,n_hidden]
context = attn_weights.bmm(enc_outputs.transpose(0, 1))
dec_output = dec_output.squeeze(0) # dec_output : [batch_size(=1), num_directions(=1) * n_hidden]
context = context.squeeze(1) # [1, num_directions(=1) * n_hidden]
model[i] = self.out(torch.cat((dec_output, context), 1))
# make model shape [n_step, n_class]
return model.transpose(0, 1).squeeze(0), trained_attn
def get_att_weight(self, dec_output, enc_outputs): # get attention weight one 'dec_output' with 'enc_outputs'
n_step = len(enc_outputs)
attn_scores = torch.zeros(n_step) # attn_scores : [n_step]
for i in range(n_step):
attn_scores[i] = self.get_att_score(dec_output, enc_outputs[i])
# Normalize scores to weights in range 0 to 1
return F.softmax(attn_scores).view(1, 1, -1)
def get_att_score(self, dec_output, enc_output): # enc_outputs [batch_size, num_directions(=1) * n_hidden]
score = self.attn(enc_output) # score : [batch_size, n_hidden]
return torch.dot(dec_output.view(-1), score.view(-1)) # inner product make scalar value
if __name__ == '__main__':
n_step = 5 # number of cells(= number of Step)
n_hidden = 128 # number of hidden units in one cell
sentences = ['ich mochte ein bier P', 'S i want a beer', 'i want a beer E']
word_list = " ".join(sentences).split()
word_list = list(set(word_list))
word_dict = {w: i for i, w in enumerate(word_list)}
number_dict = {i: w for i, w in enumerate(word_list)}
n_class = len(word_dict) # vocab list
# hidden : [num_layers(=1) * num_directions(=1), batch_size, n_hidden]
hidden = torch.zeros(1, 1, n_hidden)
model = Attention()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
input_batch, output_batch, target_batch = make_batch()
# Train
for epoch in range(2000):
optimizer.zero_grad()
output, _ = model(input_batch, hidden, output_batch)
loss = criterion(output, target_batch.squeeze(0))
if (epoch + 1) % 400 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
loss.backward()
optimizer.step()
# Test
test_batch = [np.eye(n_class)[[word_dict[n] for n in 'SPPPP']]]
test_batch = torch.FloatTensor(test_batch)
predict, trained_attn = model(input_batch, hidden, test_batch)
predict = predict.data.max(1, keepdim=True)[1]
print(sentences[0], '->', [number_dict[n.item()] for n in predict.squeeze()])
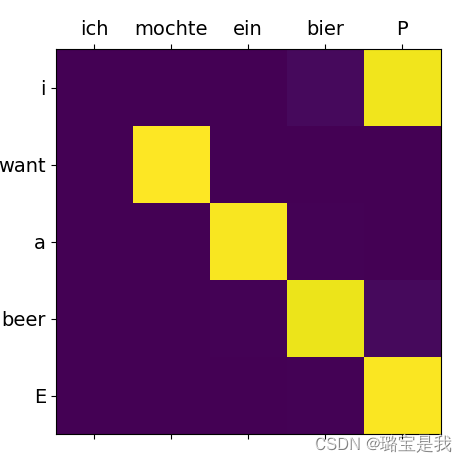
# Show Attention
fig = plt.figure(figsize=(5, 5))
ax = fig.add_subplot(1, 1, 1)
ax.matshow(trained_attn, cmap='viridis')
ax.set_xticklabels([''] + sentences[0].split(), fontdict={'fontsize': 14})
ax.set_yticklabels([''] + sentences[2].split(), fontdict={'fontsize': 14})
plt.show()















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









