






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言:增量学习
增量学习作为机器学习的一种方法,现阶段得到广泛的关注。在其中,输入数据不断被用于扩展现有模型的知识,即进一步训练模型,它代表了一种动态的学习的技术。对于满足以下条件的学习方法可以定义为增量学习方法:
- 可以学习新的信息中的有用信息
- 不需要访问已经用于训练分类器的原始数据
- 对已经学习的知识具有记忆功能
- 在面对新数据中包含的新类别时,可以有效地进行处理
许多机器学习的算法可以应用增量学习,例如:决策树,Learn++,Fuzzy ARTMAP,TopoART IGNG以及增量SVM等。
增量算法经常应用于对数据流或大数据的处理,比如对股票趋势的预测和用户偏好的分析等。在这些数据流中,新的数据可以持续地输入到模型中来完善模型。此外,将增量学习应用于聚类问题,维度约减,特征选择,数据表示强化学习,数据挖掘等等。
提示:以下是本篇文章正文内容,下面案例可供参考
1 Abstract
无示范的类增量学习是指在旧类样本无法保存的情况下,同时识别新旧两类。这是一项具有挑战性的任务,因为只有在新类的监督下才能实现表征优化和特征保留。为了解决这个问题,我们提出了一个新颖的自我维持的表征扩展方案。我们的方案包括一个结构重组策略,该策略融合了主枝扩展和侧枝更新来保持旧的特征,以及一个主枝蒸馏方案来转移不变的知识。此外,还提出了一种原型选择机制,通过有选择地将新样本纳入蒸馏过程来提高新旧类别之间的区分度。在三个基准上进行的广泛实验显示了显著的增量性能,分别以3%、3%和6%的幅度超过了最先进的方法。
2 intro
常用的增量学习方法:
- 微调(Fine-tuning):微调没有旧任务参数和样本的指导,因此模型在旧任务上的表现几乎一定会变差,也就是发生灾难性遗忘。
- 联合训练(Joint Training):联合训练相当于在所有已知数据上重新训练模型,效果最好,因此通常被认为是增量学习的性能上界,但训练成本太高。
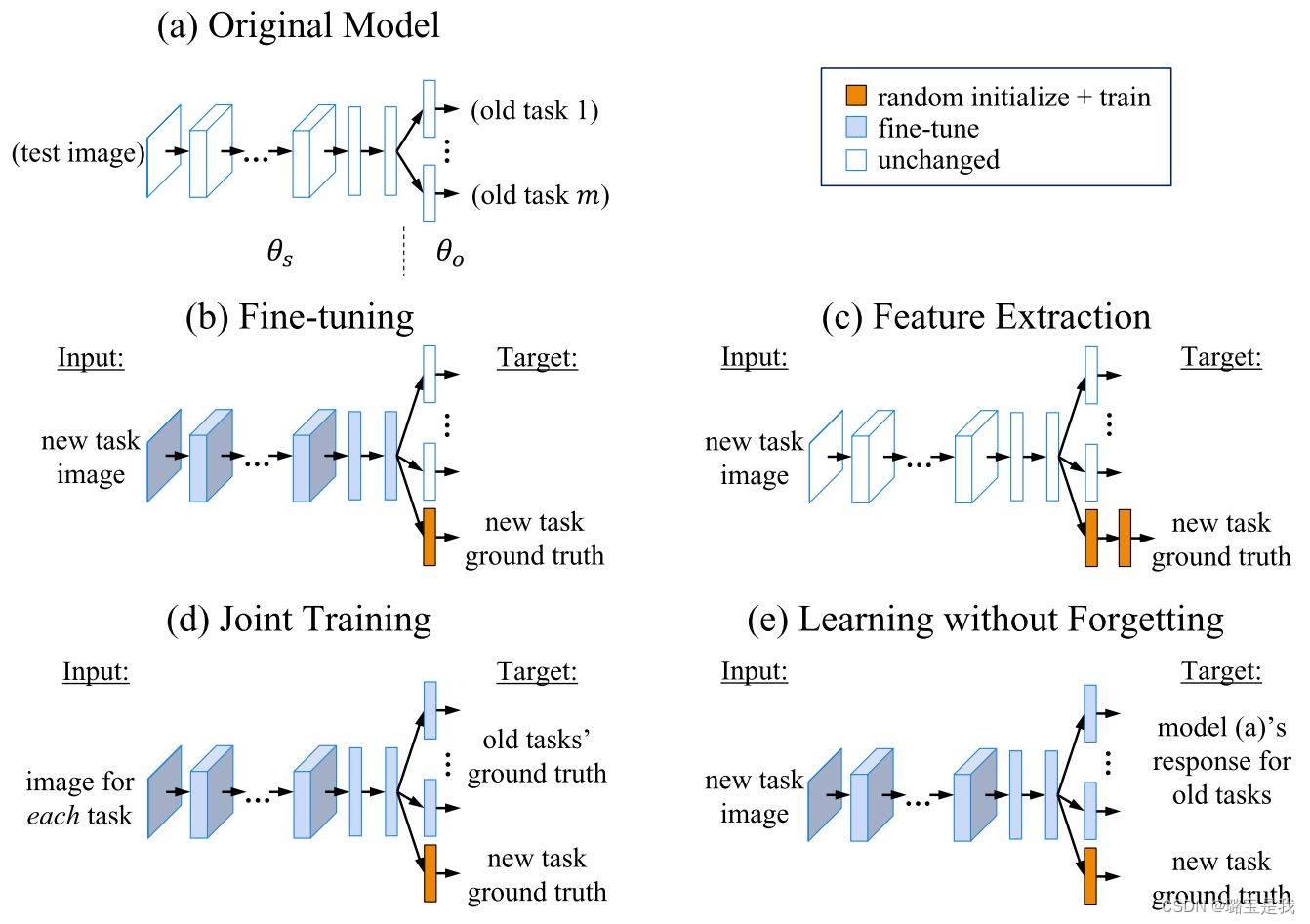
然而,大多数现有方法假设一定数量的示例可以存储在存储器中,由于用户隐私或设备限制,这在实践中通常难以满足。本文将重点放在增量学习不能保留旧类样本的新类的能力上。(Non-Exemplar Class-Incremental Learning,NECIL)
本文做法:
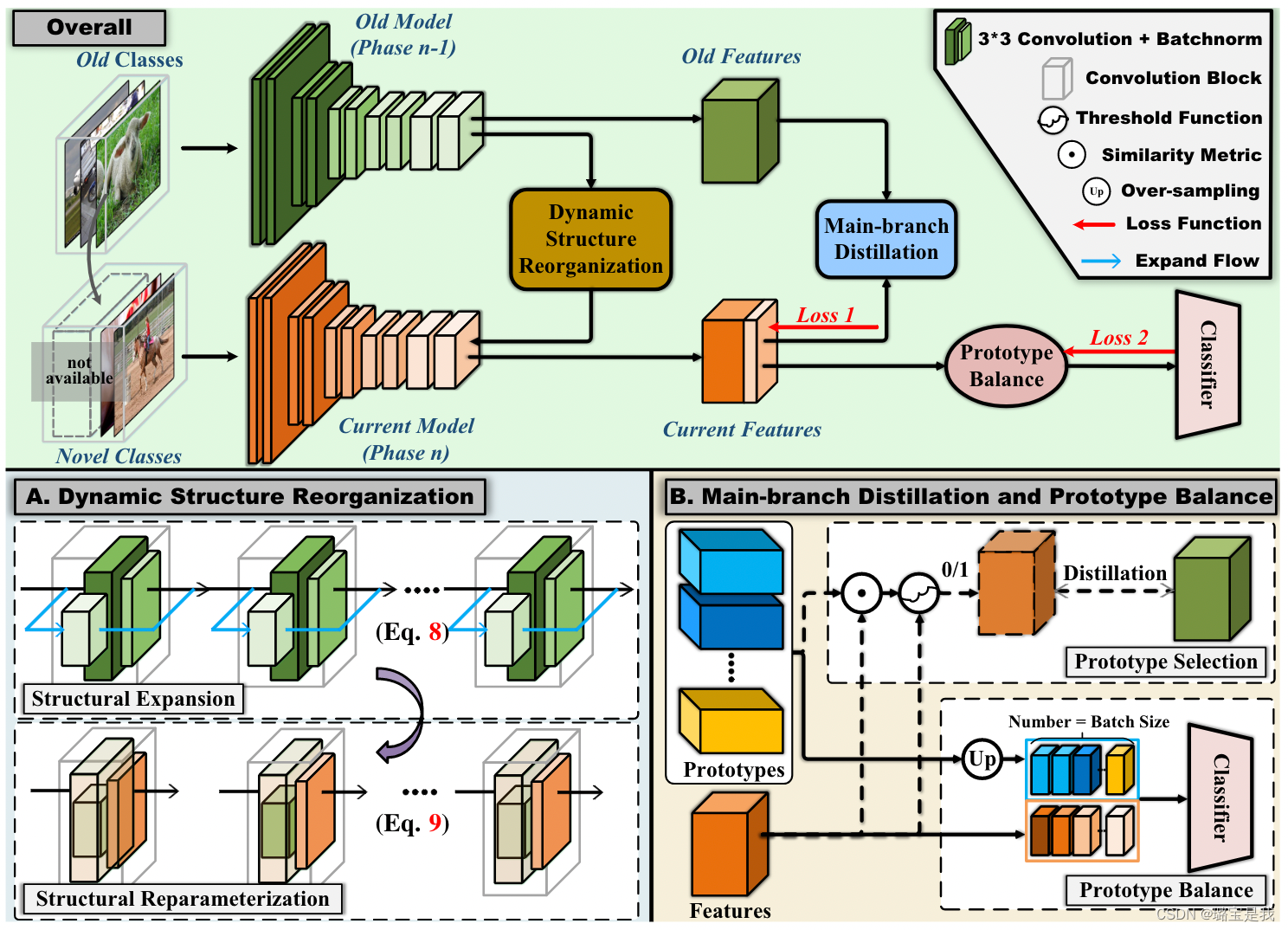
1. 动态结构重组(DSR):为学习类留出结构化空间,同时通过在主支保持旧知识和在分支融合更新来稳定地保留旧类空间。
2. 主支蒸馏(MBD):通过对齐旧类上的不变分布知识来保持新网络相对于旧特征的区分。
3. 原型选择机制(PSM):为了减少新的增量类和原始类之间的混淆。首先使用归一化余弦值测量新表征和旧原型之间的相似性,类似于old class的样本被用于蒸馏,与old class不相似的样本用于训练new class。
3 Problem Description

4 Method
4.1 标准NECIL范式
增量表示学习Incremental Representation Learning

相关公式:
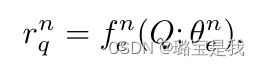
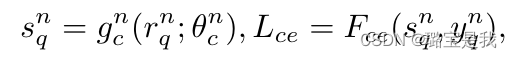
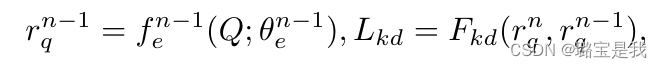
增量分类器校准Incremental Classifier Calibratio
(待补充)
4.2 优化
与以往专注于分类器效果的工作不同,本文试图分析其表示r
在以往的类增量学习中:
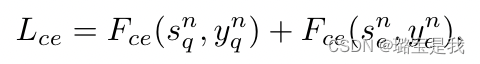
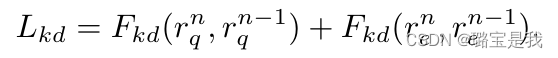
Lce由两部分组成,Sne表示保存的示例,其数量比Snq的数量要少得多。虽然这种不平衡会使操作定时过程偏向于新类别更具辨别力的特征,但蒸馏可以缓解这一问题。
rne表示范例的表示。在这种情况下,将保留对旧类和新类重要的特性。
然而在NECIL中,我们是没有old data的,因此在传统类增量学习中对新类旧类的联合优化转变为仅与增量类相关的特征优化。第一部分反映的是,交叉熵损失将只关注有助于识别新类别的特征,而在第二部分,它将关注与新类别相关的特征的维护,这两者都会加速旧类别的代表性特征的遗忘。
4.3.自我维持代表扩展
动态结构重组Dynamic Structure Reorganization
DSR包含Structural Expansion与Structural Reparameterization两个部分。
Structural Expansion,字面意思,结构扩充,就是为深度网络添加的额外的层,以增大网络参数量的形式使得网络在学习新知识的同时,减少对旧知识的覆盖。但是,持续增大参数量的话会使网络变得臃肿,从而违背增量学习的原则。实际上,本文添加的结构仅仅是为了辅助网络进行学习。我们来回看一下示意图:
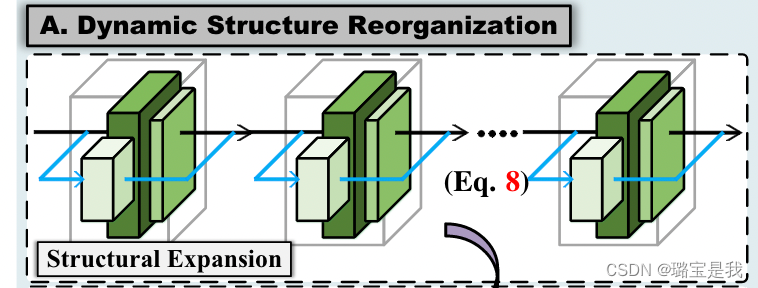
其中灰色立方体框出来的部分就是深度网络的一个Encoder Block。Encoder Block由若干个卷积组成,而一个深度网络一般包含五个Encoder Block。本文的做法是,在Encoder Block的基础上添加额外的residual connection,对应蓝色连接线部分。在训练时,首先冻结主网络参数,只对这些residual connection进行训练。在训练完后,这些residual block中就可以包含一些新类的知识。
接下来,问题就成了怎么把这一额外结构中的新类知识给融合回主网中。这一过程对应着Structural Reparameterization,其结构如下:
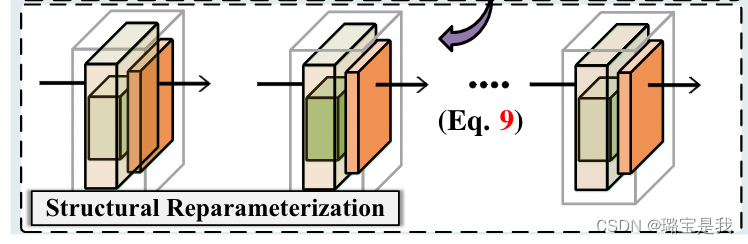
具体做法可能源自于RepVGG[2],通过zero-padding与linear transformation实现。在新类知识被融合后,额外的residual connection被移除以保证网络参数不变。
原型选择Prototype Selection
具体做法是,对于新类样本,计算其embedding与原型向量的相似性。如果这个相似性超过了某个阈值,说明该新类样本与旧类样本相似,容易混淆,此时为蒸馏损失增加一个mask,强调对新旧类的区分;如果这个相似性低于某个阈值,则说明该新类样本与旧类样本差异很大,此时为交叉熵损失增加一个mask,强调对新类特征的学习。
(待补充)















 537
537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









