








CVPR 2025 decisions are now available on OpenReview!22.1% = 2878 / 13008
会议官网:https://cvpr.thecvf.com/Conferences/2025
目前计划整理六个合集,部分合集未发布
【合集一】AIGC
【合集二】Mamba、MLLM
【合集三】底层视觉
【合集四】检测与分割
【合集五】三维视觉
【合集六】视频理解
欢迎转载,转载注明出处哦
——————————————————————————————————————————————————————————————
OOD 检测
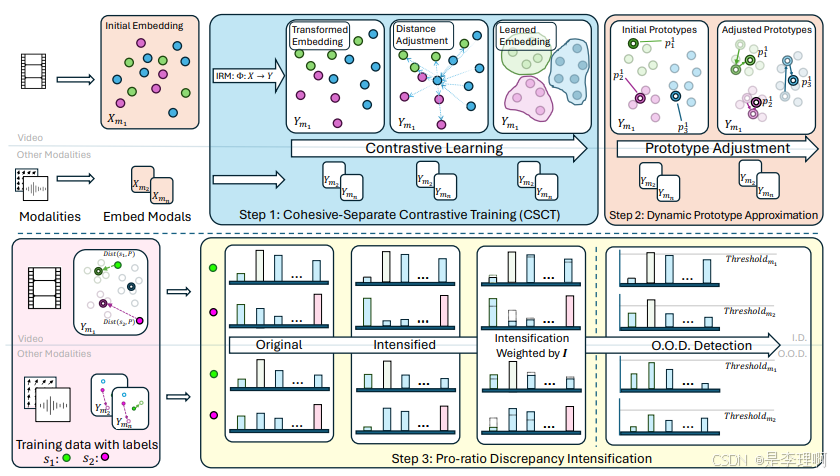
1.《DPU: Dynamic Prototype Updating for Multimodal Out-of-Distribution Detection》
Paper: https://arxiv.org/pdf/2411.08227
Code: https://github.com/lili0415/DPU-OOD-Detection
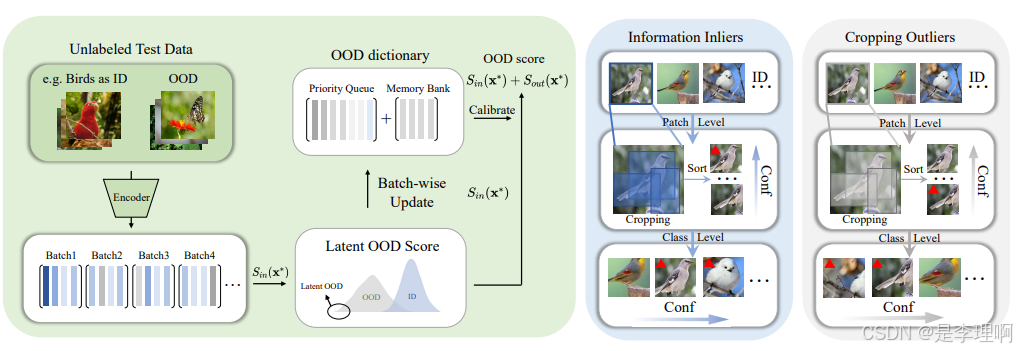
2.《OODD: Test-time Out-of-Distribution Detection with Dynamic Dictionary》
Paper: https://arxiv.org/pdf/2503.10468
Code: https://github.com/zxk1212/OODD
目标检测
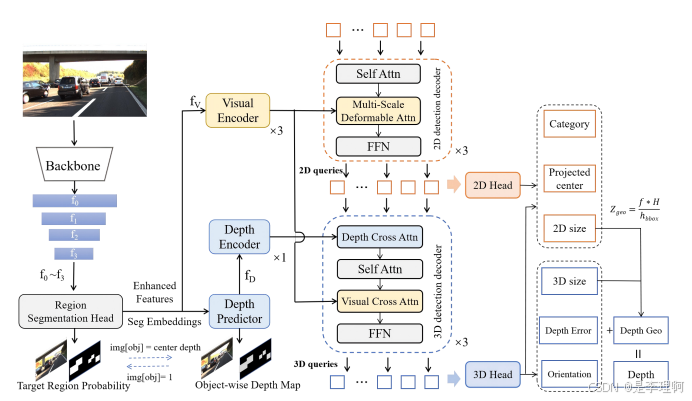
1.《MonoDGP: Monocular 3D Object Detection with Decoupled-Query and Geometry-Error Priors》
Paper:https://arxiv.org/pdf/2410.19590
Code:https://github.com/PuFanqi23/MonoDGP
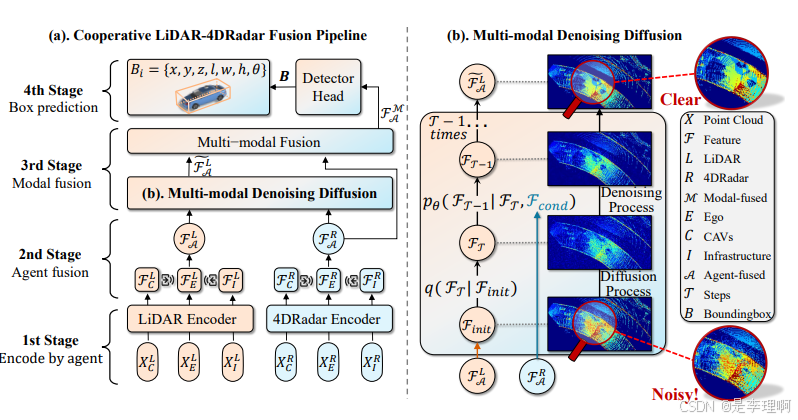
2.《V2X-R: Cooperative LiDAR-4D Radar Fusion with Denoising Diffusion for 3D Object Detection》
Paper: https://arxiv.org/pdf/2411.08402
Code: https://github.com/ylwhxht/V2X-R
3.《FASTer: Focal Token Acquiring-and-Scaling Transformerfor Long-term 3D Object Detection》
Paper: https://arxiv.org/pdf/2503.01899
Code: https://github.com/MSunDYY/FASTer
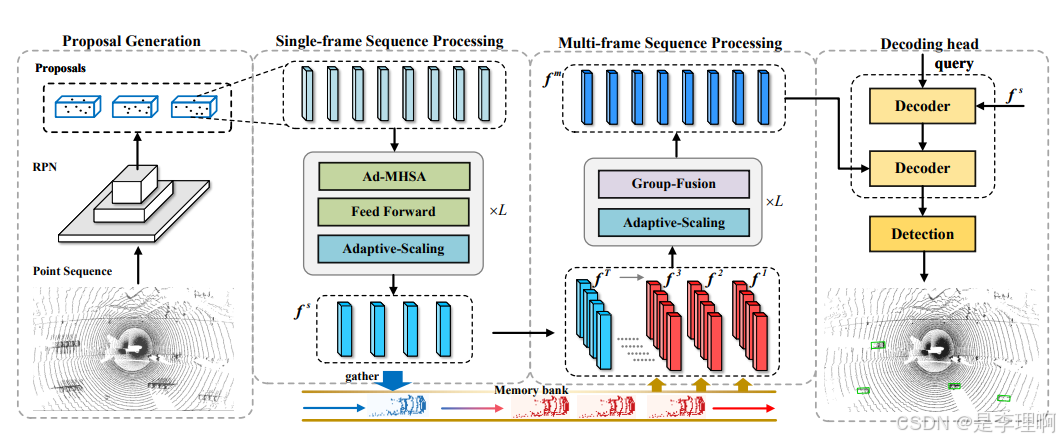
4.《Object Detection using Event Camera: A MoE Heat Conduction based Detector and A New Benchmark Dataset》
Paper: https://arxiv.org/pdf/2412.06647
Code: https://github.com/Event-AHU/OpenEvDET
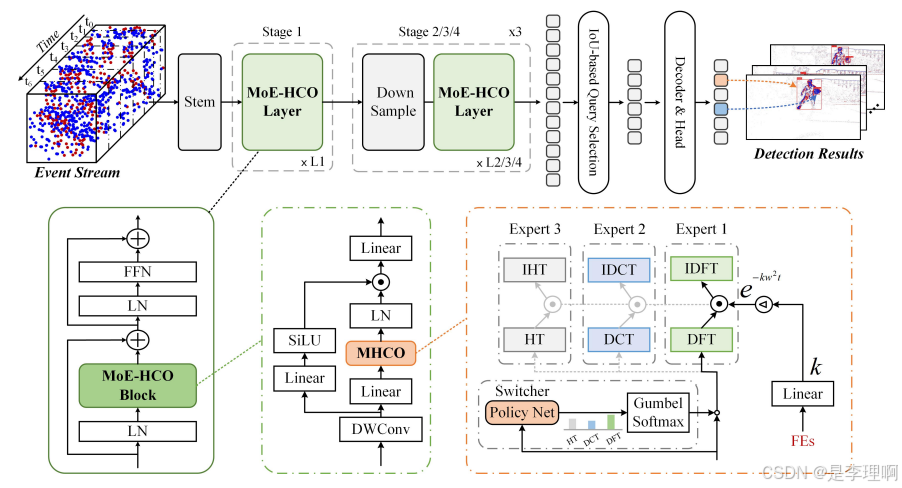
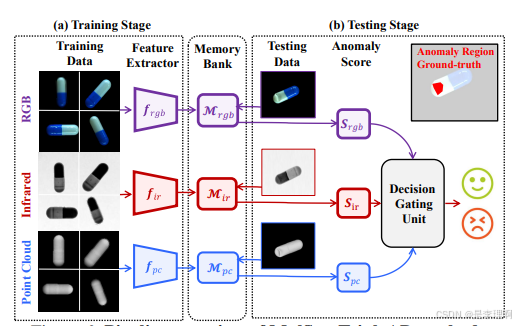
5.《Multi-Sensor Object Anomaly Detection:Unifying Appearance, Geometry, and Internal Properties》
Paper: https://arxiv.org/pdf/2412.14592
Code: https://github.com/ZZZBBBZZZ/MulSen-AD
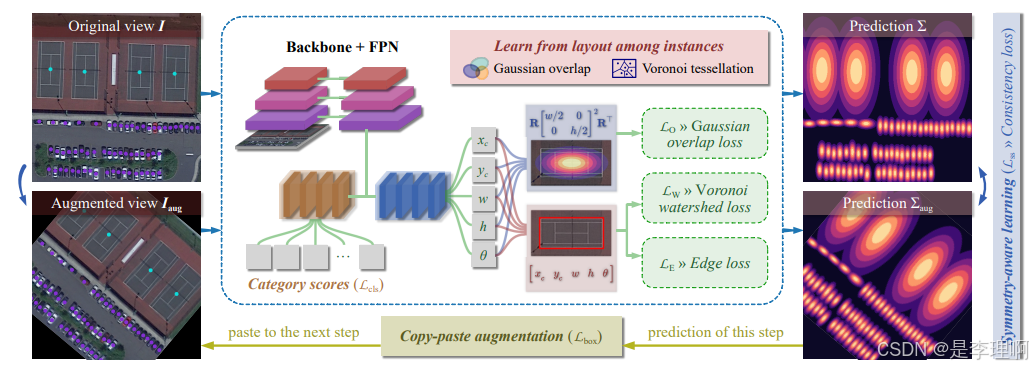
6.《Point2RBox-v2: Rethinking Point-supervised Oriented Object Detection with Spatial Layout Among Instances》
Paper: https://arxiv.org/pdf/2502.04268
Code: https://github.com/VisionXLab/point2rbox-v2
7.《LLMDet: Learning Strong Open-Vocabulary Object Detectors under the Supervision of Large Language Models》
Paper: https://arxiv.org/pdf/2501.18954
Code: https://github.com/iSEE-Laboratory/LLMDet
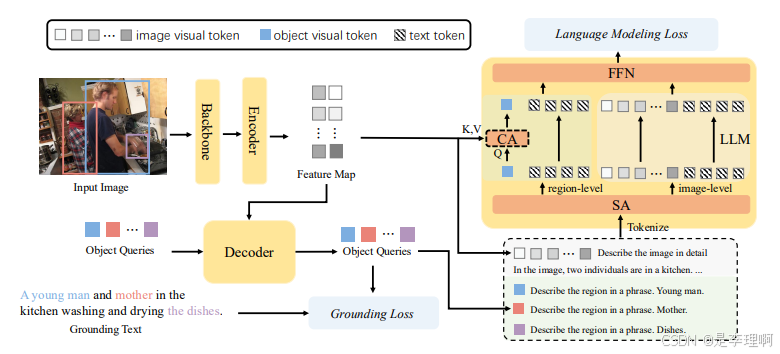
8.《MonoTAKD: Teaching Assistant Knowledge Distillation for Monocular 3DObject Detection》
Paper: https://arxiv.org/pdf/2404.04910
Code: https://github.com/hoiliu-0801/MonoTAKD
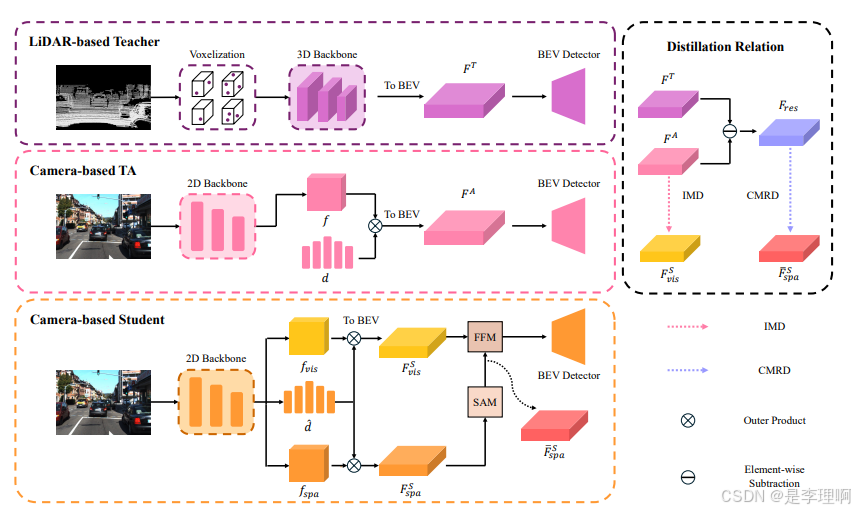
语义分割
1.《SegMAN: Omni-scale Context Modeling with State Space Modelsand Local Attention for Semantic Segmentation》
Paper: https://arxiv.org/pdf/2412.11890
Code: https://github.com/yunxiangfu2001/SegMAN
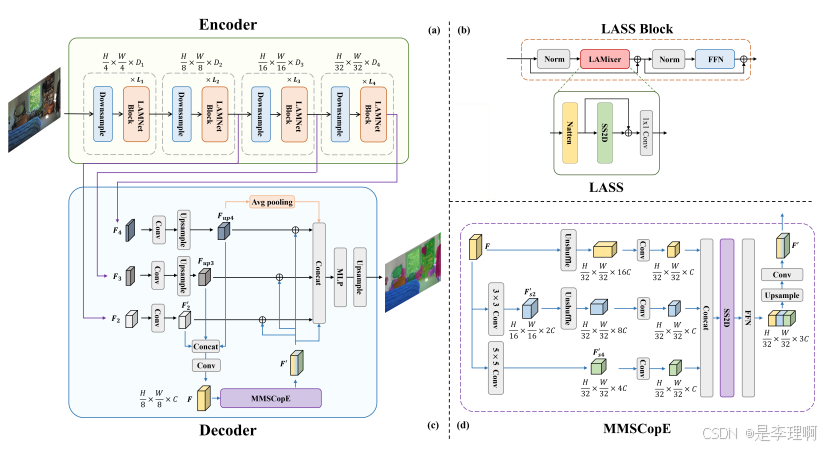
2.《An End-to-End Robust Point Cloud Semantic SegmentationNetwork with Single-Step Conditional Diffusion Models》
Paper: https://arxiv.org/pdf/2411.16308
Code: https://github.com/QWTforGithub/CDSegNet
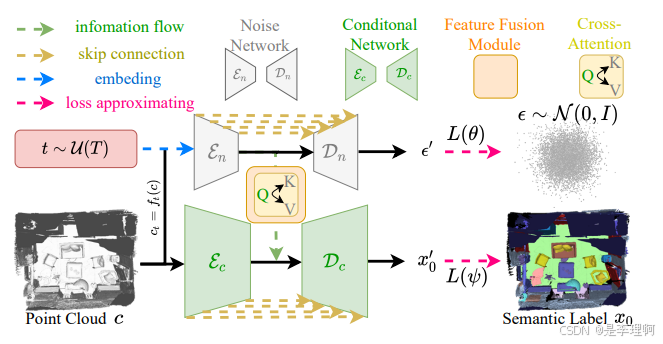
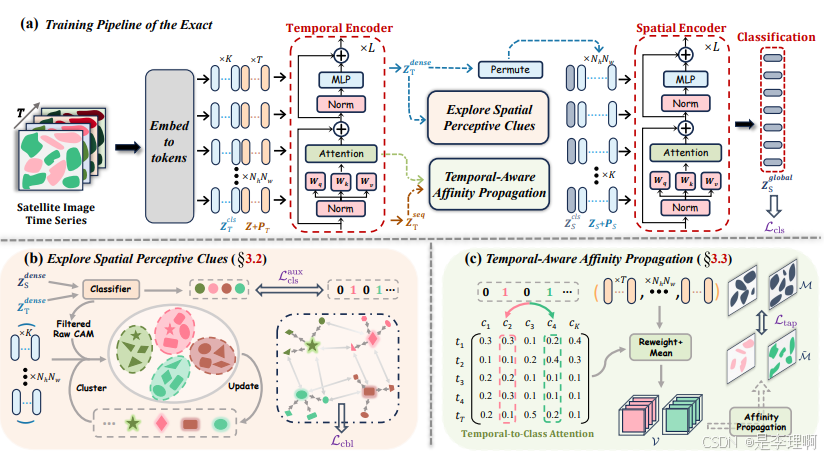
3.《Exact: Exploring Space-Time Perceptive Clues for Weakly SupervisedSatellite Image Time Series Semantic Segmentation》
Paper: https://arxiv.org/pdf/2412.03968
Code: https://github.com/MiSsU-HH/Exact
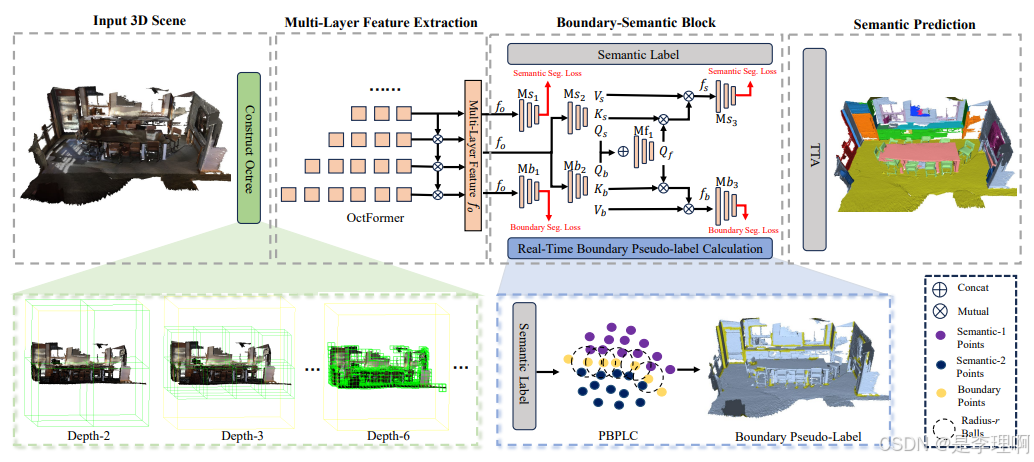
4.《BFANet: Revisiting 3D Semantic Segmentation with Boundary Feature Analysis》
Paper:https://arxiv.org/pdf/2503.12539
Code:https://github.com/weiguangzhao/BFANet
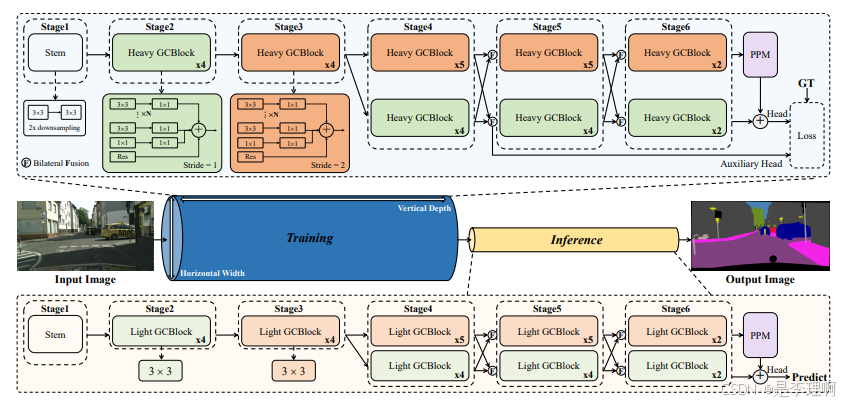
5.《Golden Cudgel Network for Real-Time Semantic Segmentation》
Paper: https://arxiv.org/pdf/2503.03325
Code: https://github.com/gyyang23/GCNet


















 2520
2520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









