








CVPR 2025 decisions are now available on OpenReview!22.1% = 2878 / 13008
会议官网:https://cvpr.thecvf.com/Conferences/2025
目前计划整理六个合集,部分合集未发布
【合集一】AIGC
【合集二】Mamba、MLLM
【合集三】底层视觉
【合集四】检测与分割
【合集五】三维视觉
【合集六】视频理解
欢迎转载,转载注明出处哦
——————————————————————————————————————————————————————————————
三维重建
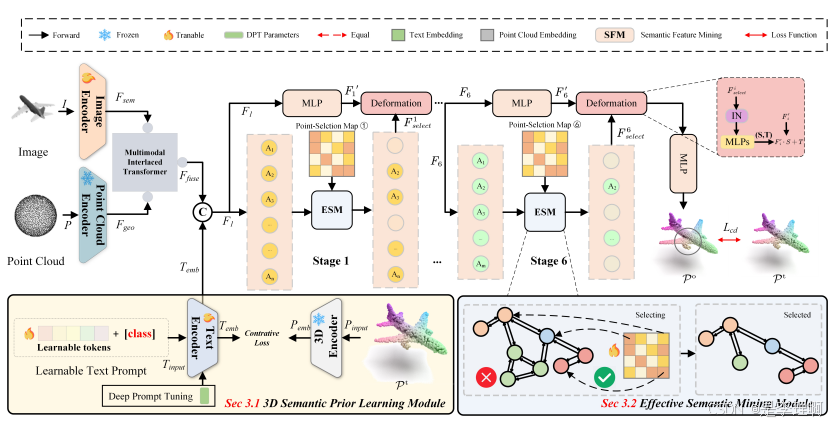
1.《MESC-3D:Mining Effective Semantic Cues for 3D Reconstructionfrom a Single Image》
paper: https://arxiv.org/pdf/2502.20861
code: https://github.com/QINGQINGLE/MESC-3D
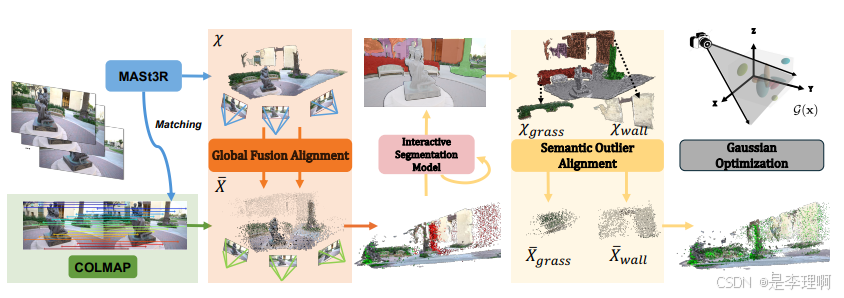
2.《SPARS3R: Semantic Prior Alignment and Regularization for Sparse 3DReconstruction》
paper: https://arxiv.org/pdf/2411.12592
code: https://github.com/snldmt/SPARS3R
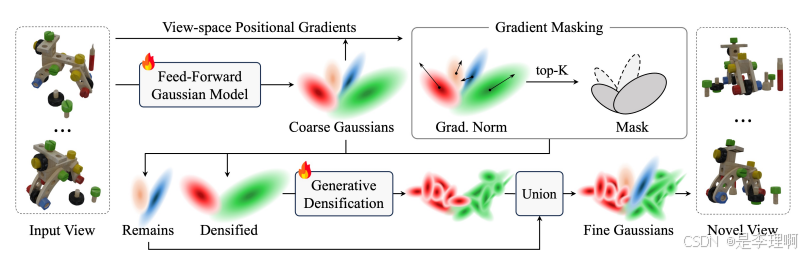
3.《Generative Densification: Learning to Densify Gaussians for High-FidelityGeneralizable 3D Reconstruction》
paper: https://arxiv.org/pdf/2412.06234
code: https://github.com/stnamjef/GenerativeDensification
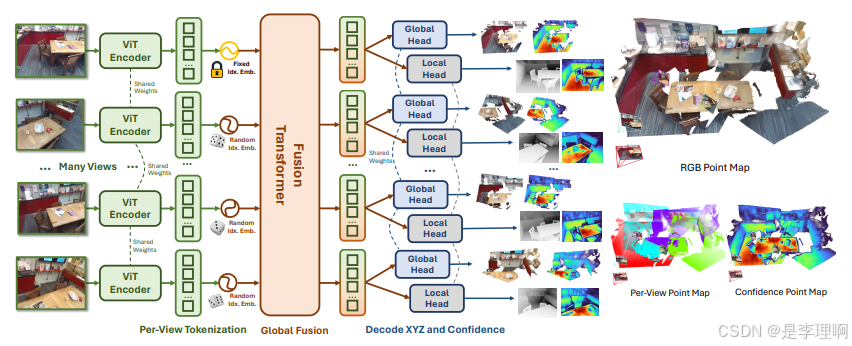
4.《Fast3R: Towards 3D Reconstruction of 1000+ Images in One Forward Pass》
paper: https://arxiv.org/pdf/2501.13928
code: https://github.com/facebookresearch/fast3r
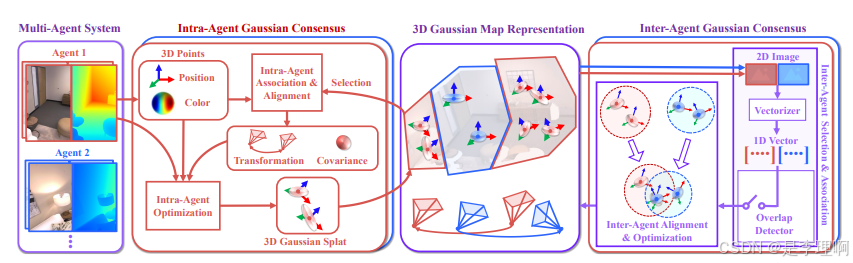
5.《MAC-Ego3D: Multi-Agent Gaussian Consensus forReal-Time Collaborative Ego-Motion and Photorealistic 3D Reconstruction》
paper: https://arxiv.org/pdf/2412.09723
code: https://github.com/Xiaohao-Xu/MAC-Ego3D
SLAM
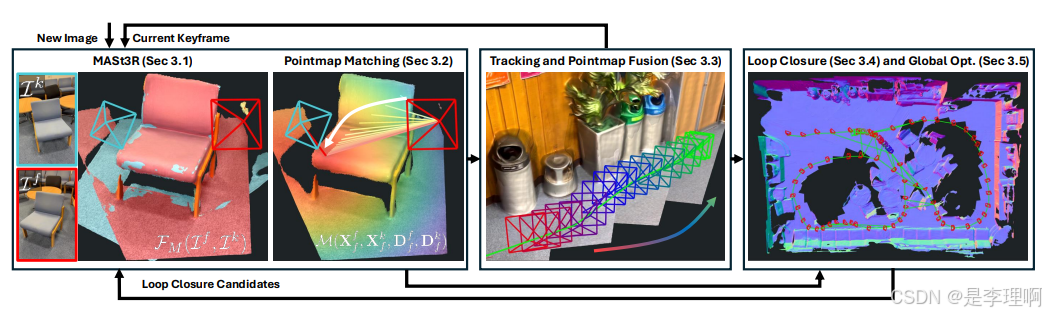
1.《MASt3R-SLAM: Real-Time Dense SLAM with 3D Reconstruction Priors》
paper: https://arxiv.org/pdf/2412.12392
code: https://github.com/rmurai0610/MASt3R-SLAM
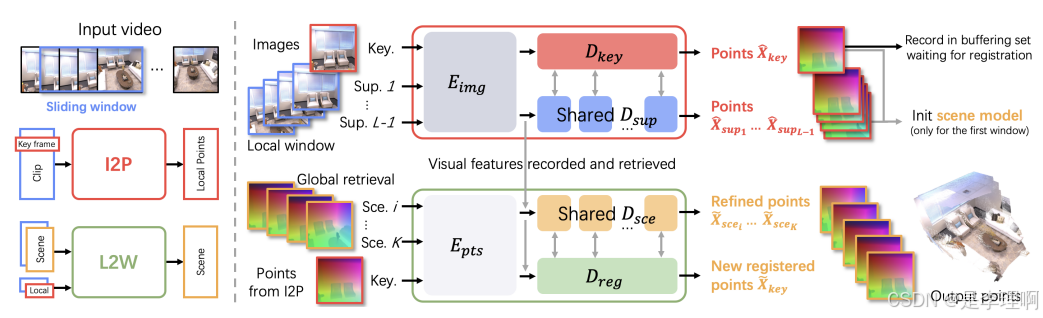
2.《SLAM3R: Real-Time Dense Scene Reconstruction from Monocular RGB Videos》
paper: https://arxiv.org/pdf/2412.09401
code: https://github.com/PKU-VCL-3DV/SLAM3R
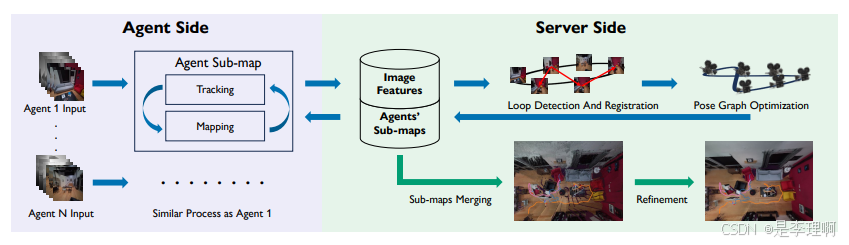
3.《MAGiC-SLAM: Multi-Agent Gaussian Globally Consistent SLAM》
paper: https://arxiv.org/pdf/2411.16785
code: https://github.com/VladimirYugay/MAGiC-SLAM
深度估计
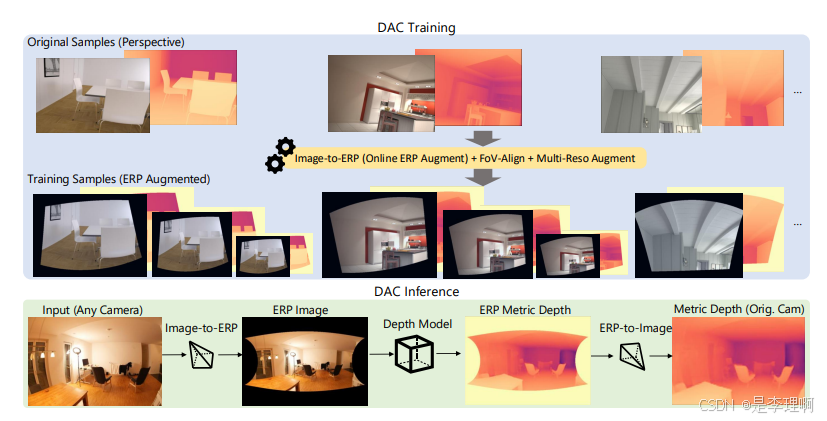
1.《Depth Any Camera: Zero-Shot Metric Depth Estimation from Any Camera》
paper: https://arxiv.org/pdf/2501.02464
code: https://github.com/yuliangguo/depth_any_camera
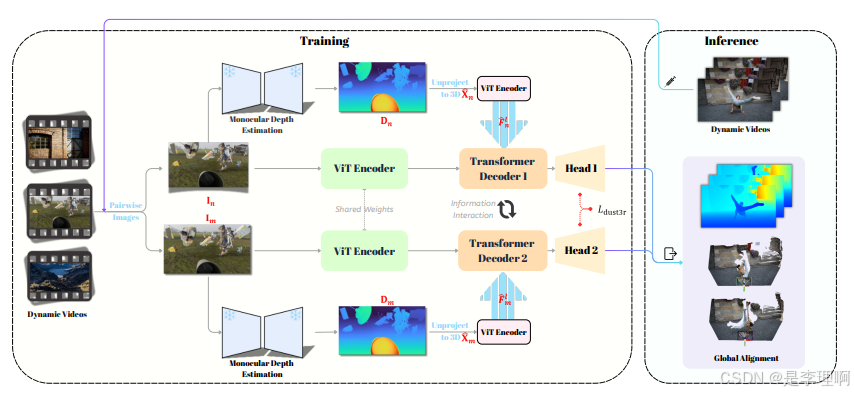
2.《Align3R: Aligned Monocular Depth Estimation for Dynamic Videos》
paper: https://arxiv.org/pdf/2412.03079
code: https://github.com/jiah-cloud/Align3R
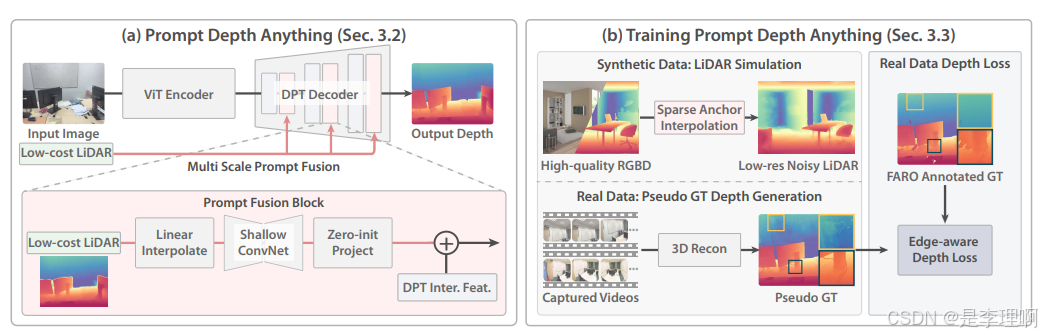
3.《Prompting Depth Anything for 4K Resolution Accurate Metric Depth Estimation》
paper: https://arxiv.org/pdf/2412.14015
code: https://github.com/DepthAnything/PromptDA
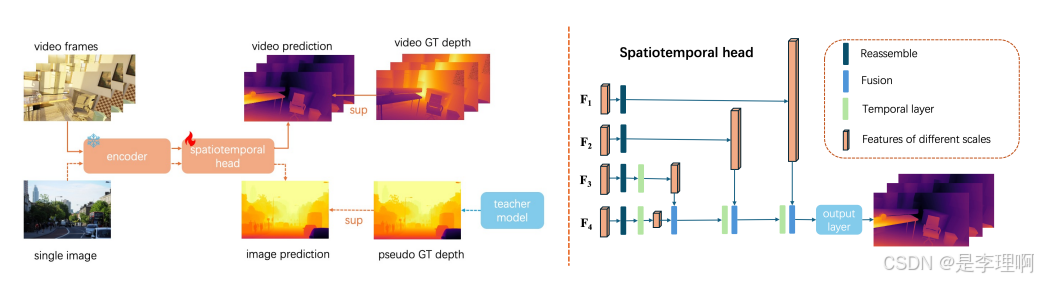
4.《Video Depth Anything: Consistent Depth Estimation for Super-Long Videos》
paper: https://arxiv.org/pdf/2501.12375
code: https://github.com/DepthAnything/Video-Depth-Anything
点云
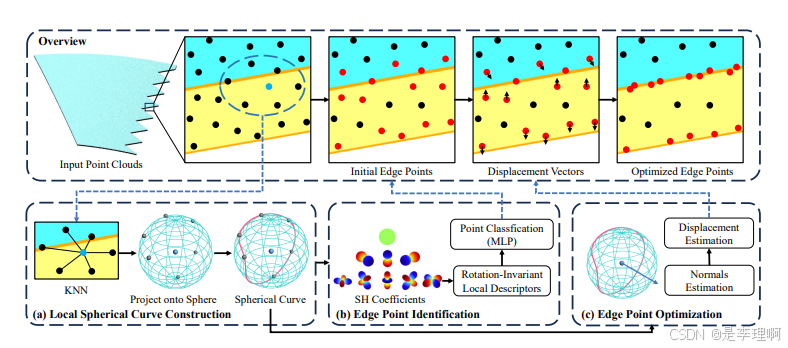
1.《STAR-Edge: Structure-aware Local Spherical Curve Representation forThin-walled Edge Extraction from Unstructured Point Clouds》
paper: https://arxiv.org/pdf/2503.00801
code: https://github.com/Miraclelzk/STAR-Edge
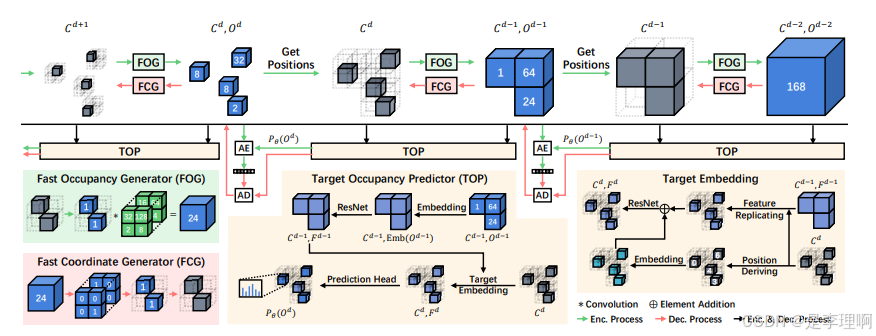
2.《RENO: Real-Time Neural Compression for 3D LiDAR Point Clouds》
paper: https://arxiv.org/pdf/2503.12382
code: https://github.com/NJUVISION/RENO
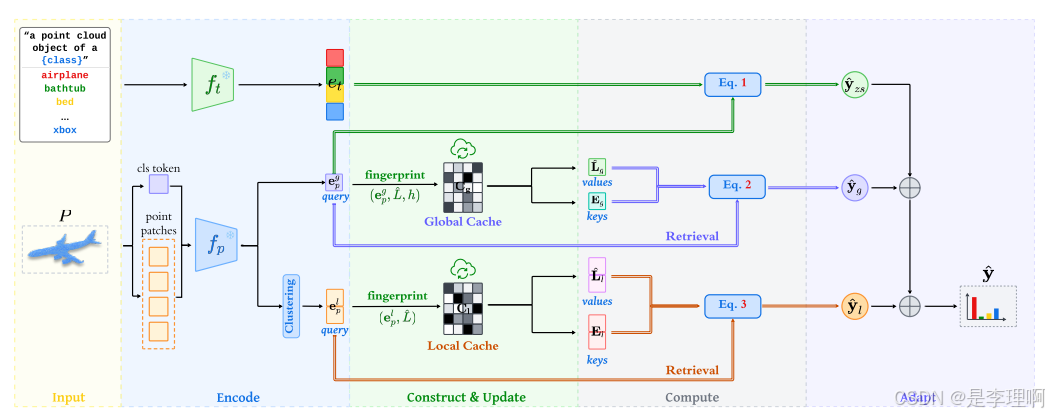
3.《Point-Cache: Test-time Dynamic and Hierarchical Cache for Robust andGeneralizable Point Cloud Analysis》
paper: https://arxiv.org/pdf/2503.12150
code: https://github.com/auniquesun/Point-Cache
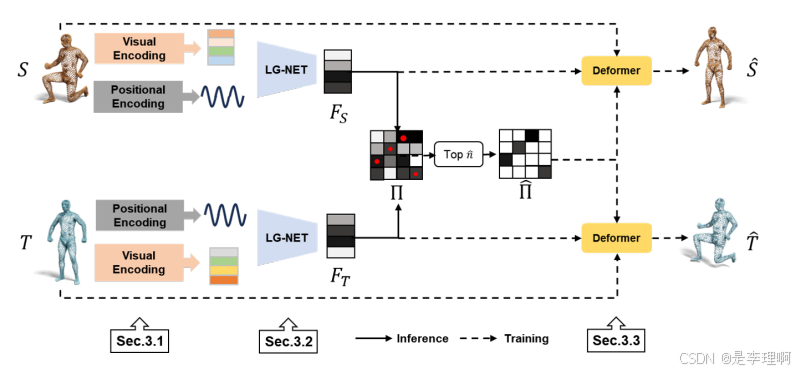
4.《DV-Matcher: Deformation-based Non-Rigid Point Cloud Matching Guided byPre-trained Visual Features》
paper: https://arxiv.org/pdf/2408.08568
code: https://github.com/rqhuang88/DV-Matcher

















 607
607

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









