







Speech Recognition:语音识别
即输入一段音频,输出为这段音频的内容。由于语音的变化比较丰富,不同的人说出同样的内容语音波形差异很大,加上环境噪声的扰动等等,都增加了语音波形的复杂性。因此语音识别一般不将语音直接输入模型处理,而是先根据人为设计的方法提取声学特征,再输入模型处理。
如图所示:

Speech: a sequence of vector (length T, dimension d)
语音即用一个由vector组成的sequence表示, 每个vector的维度是d,sequence的长度为T。
Text: a sequence of token (length N, V different tokens)
输出为文本格式,文本是一个由token组成的sequence,sequence的长度为N,V表示token的个数。比如以字为token,V表示词表里一共有多少个字。
下面介绍输出端不同的token:
Phoneme:表示发音的基本单位(英文对应音素,也可以理解为中文的拼音)。当建模单元为phoneme时,需要一个从词映射到phoneme的lexicon, 即发音字典,如图:

Grapheme:表示文本的基本单位。当以grapheme为建模单元时,是不需要发音字典的。对应英文,建模单元即为26个英文字母+空格+标点。中文则对应汉字+标点符号。
Word:比Grapheme更大的含有语义的单位。
输入端的Acoustic Feature:
声学特征有很多种,如图所示:
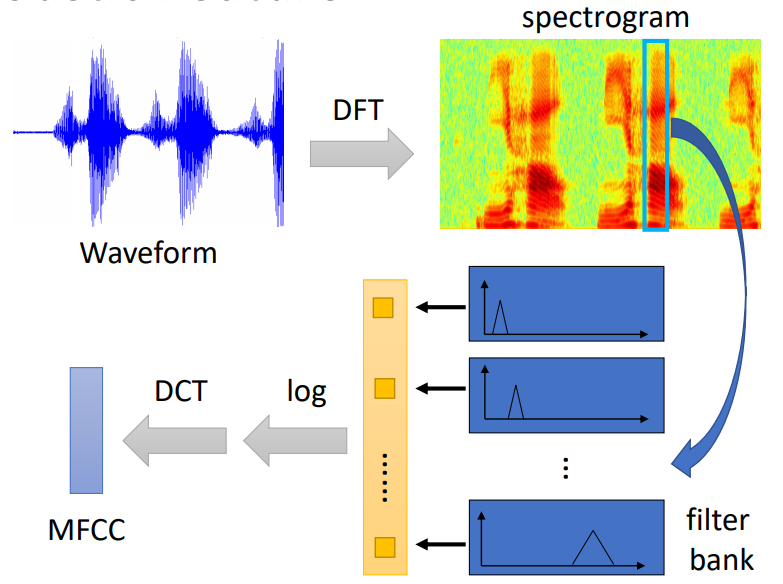
waveform, spectrogram,filter bank(fbank), mfcc都可以作为声学特征,作为进一步处理的输入。mfcc/fbank特征提取的具体过程见link。
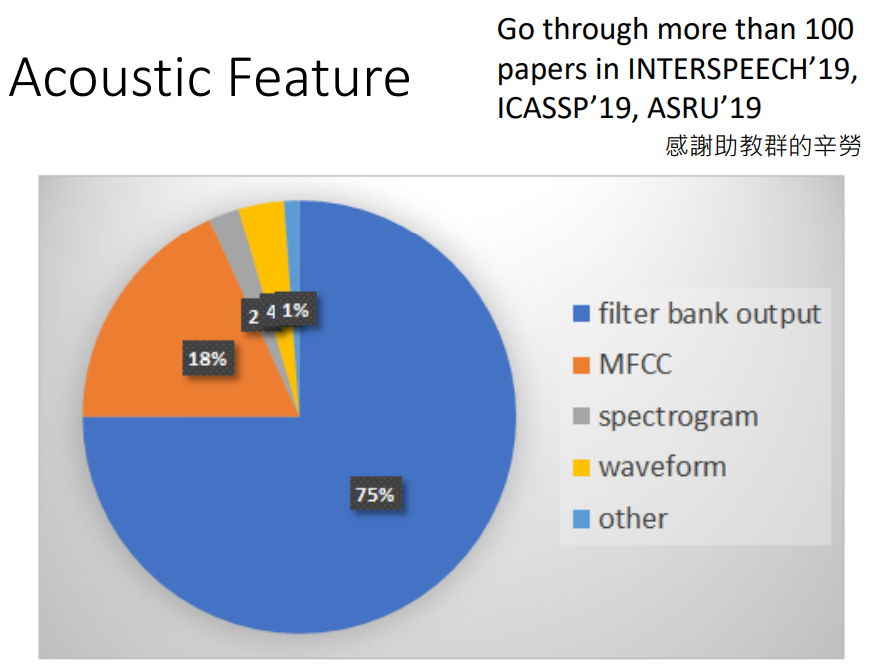
那么大家都爱用什么特征呢?图中可见,fbank深受欢迎。
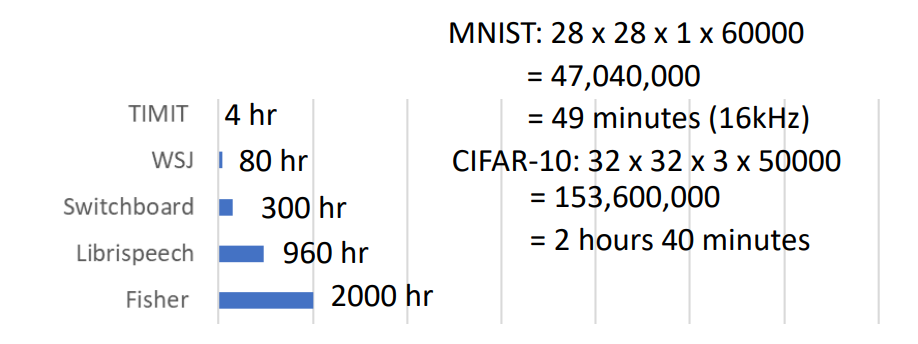
训练一个语音识别模型需要多少数据呢?(English corpora)
几个公开数据集的数据量:














 663
663











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









