









M2BART: Multilingual and Multimodal Encoder-Decoder Pre-Training for Any-to-Any Machine Translation
Abstract
语音和语言模型向着统一的方向发展,一个单独的模型可以解决200种语言的翻译和100种语言的转写。统一的模型简化了开发,部署,更重要的是在低资源的音频上实现了知识的迁移。这篇论文引入了M2BART,一个流式的多语言和多模态的encoder-decoder模型。他应用了自监督的speech tokenizer, 建立起语音和文本之间的桥梁。用统一的学习目标学习单模态和多模态知识,应用unsupervised 和 supervised的数据。在西班牙语->英语和英语->Hokkien上测试,M2BART超过了其他的baseline,同时也实验了zero shot的翻译能力。
Introduction
机器翻译现在可以用一个模型解决多个语言对的翻译,对于speech-to-text的翻译和speech-to-speech的翻译,由级联方案逐步转移到端到端方案。这篇论文中,引入了多语言,多模态,与训练方法M2BART。结合了BART和Hubert,M2BART应用了大量的没有标注的数据以及语音,同时少量的监督数据。实现了很好的翻译能力,同时具有一定zero shot翻译能力。
Related work
之前的工作与训练数据,与与训练任务。
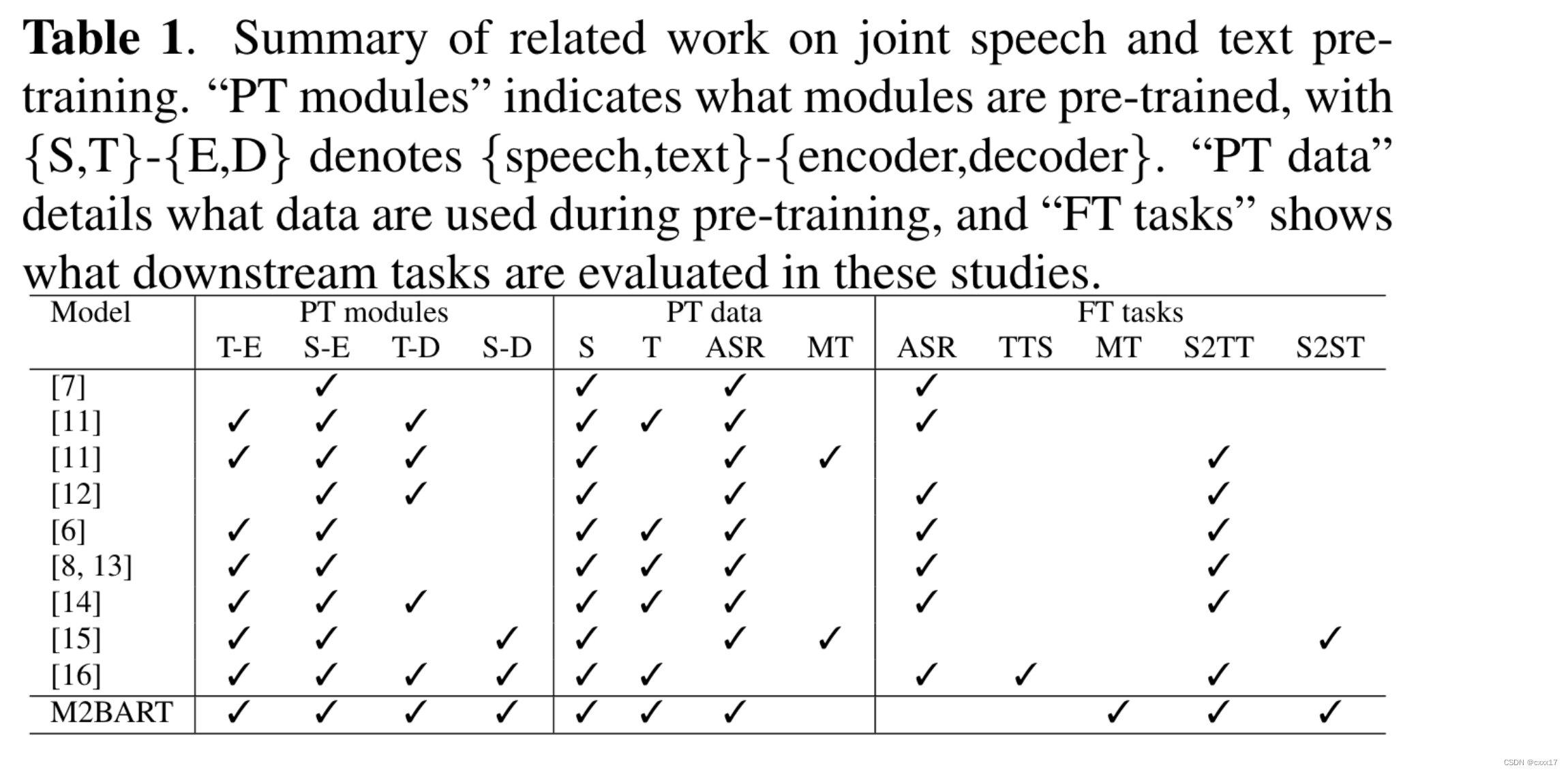
与speecht5是最接近的,主要的差异在于:
- speecht5应用了mel,而M2BART应用了SSL speech units, 能够更好的align文本,(用去重和BPE技术)。
- M2BART验证了当asr数据可以获得的时候,不成对的文本的收益
- speecht5是单语言的,但M2BART是多语言的。
Proposed method
Speech tokenizer and detokenizer
speech tokenizer: hubert, 去重, 为了进一步缩短speech units和text的粒度差异,对speech units也应用了bpe
text tokenizer: bpe
detokenizer: unit hifigan, single speaker
Masked sequence transduction
pre-training 阶段:
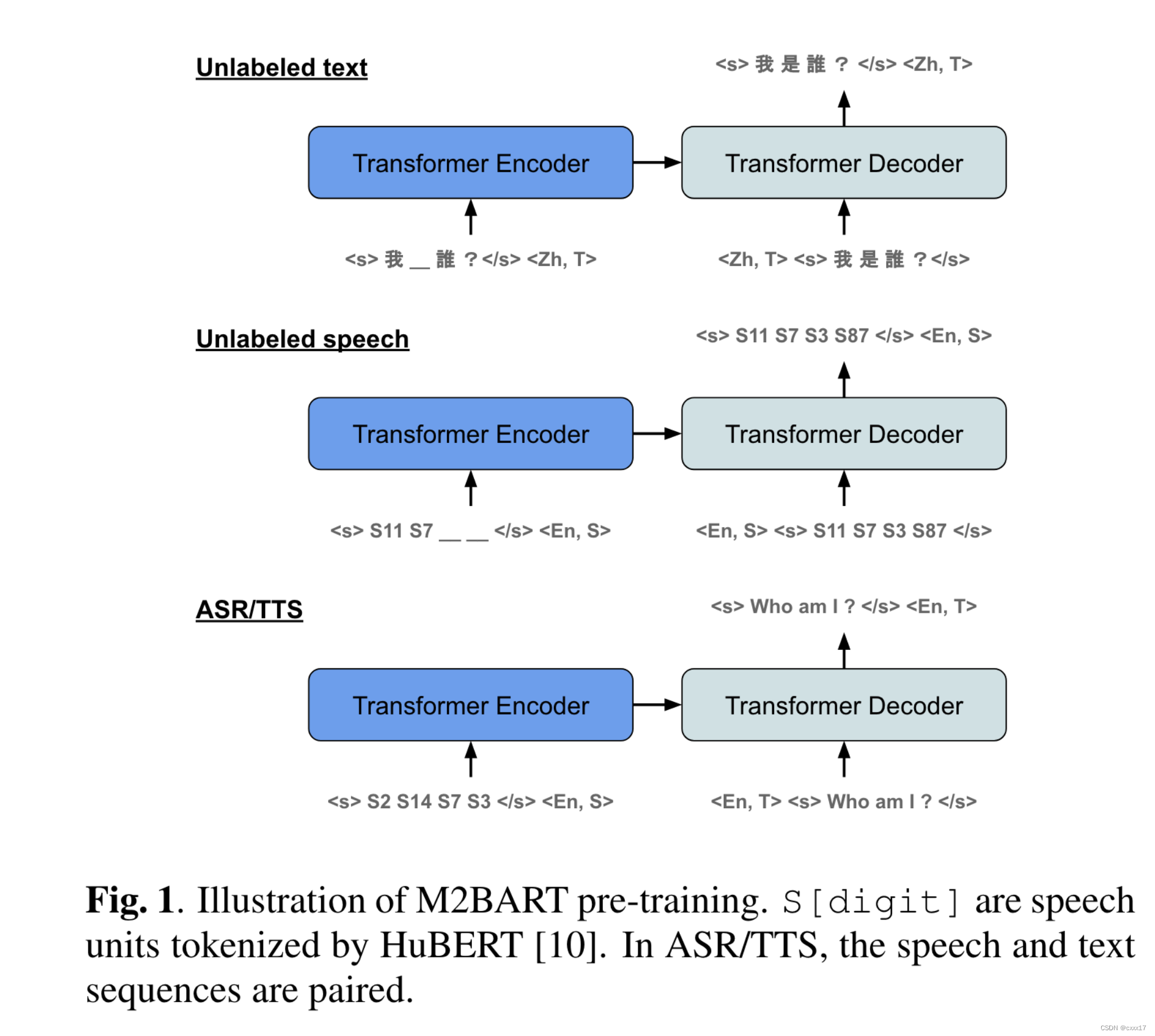
Fine-tuning for machine translation
finetune阶段:用了4个方向的translation的数据,s-t, t-s, s-s, t-t.
Experimental Setup
data
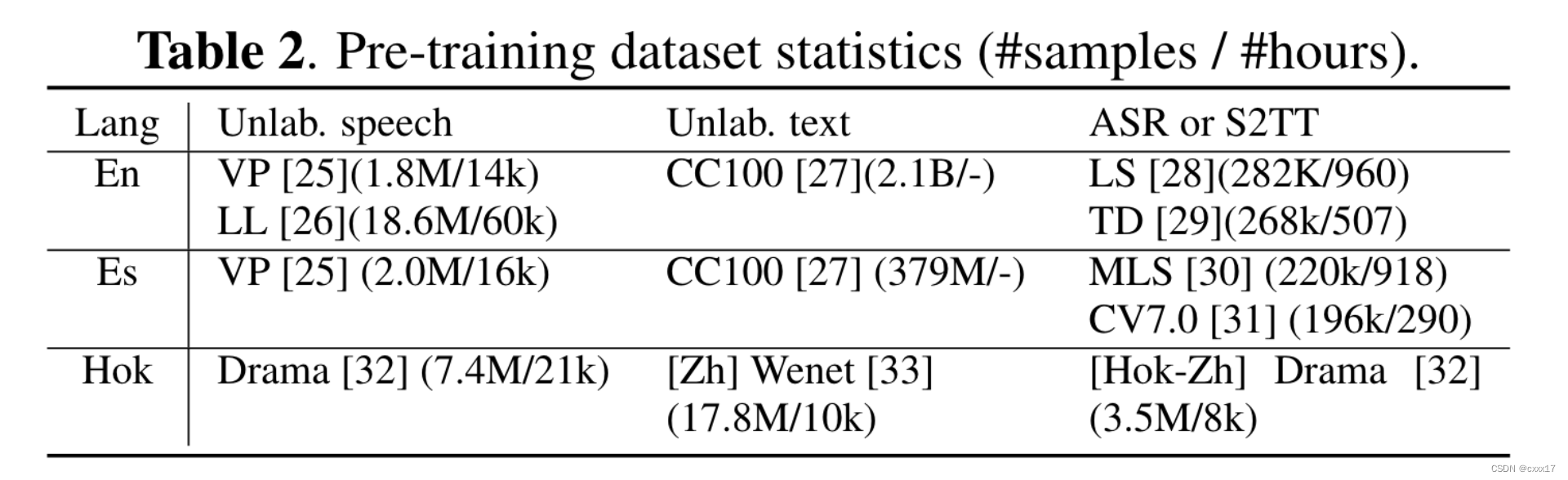
pretraining data
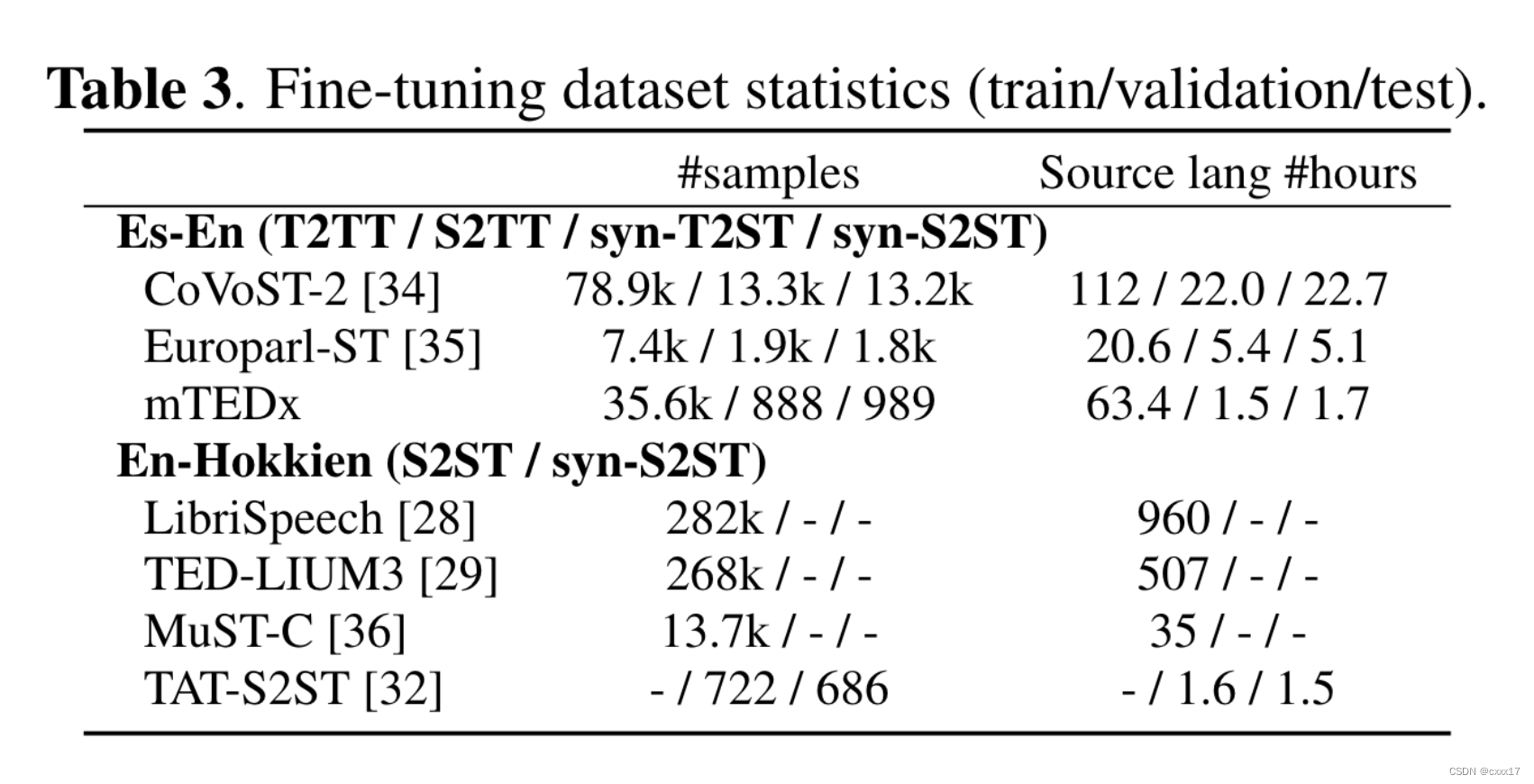
finetuning data
Tokenizaton
文本bpe:降低了69%~74%的文本长度
speech unit bpe: 降低了68.
Model and Training
HuBERT
不同数据集用不同的hubert,靠langguage区别
M2BART
用了12层的配置,数据不平衡,做了不同的下采样。
finetuning
应用24层的conformer-based wav2vec encoder, decoder 用u-mbart, t-mbart, m2bart初始化。同时根据之前工作里提到的encoder-decoder结构的finetune策略,本文finetune了整个encoder和decoder的self attention层及LayerNorm。
Results
Es-En Speech-to-speech translation:
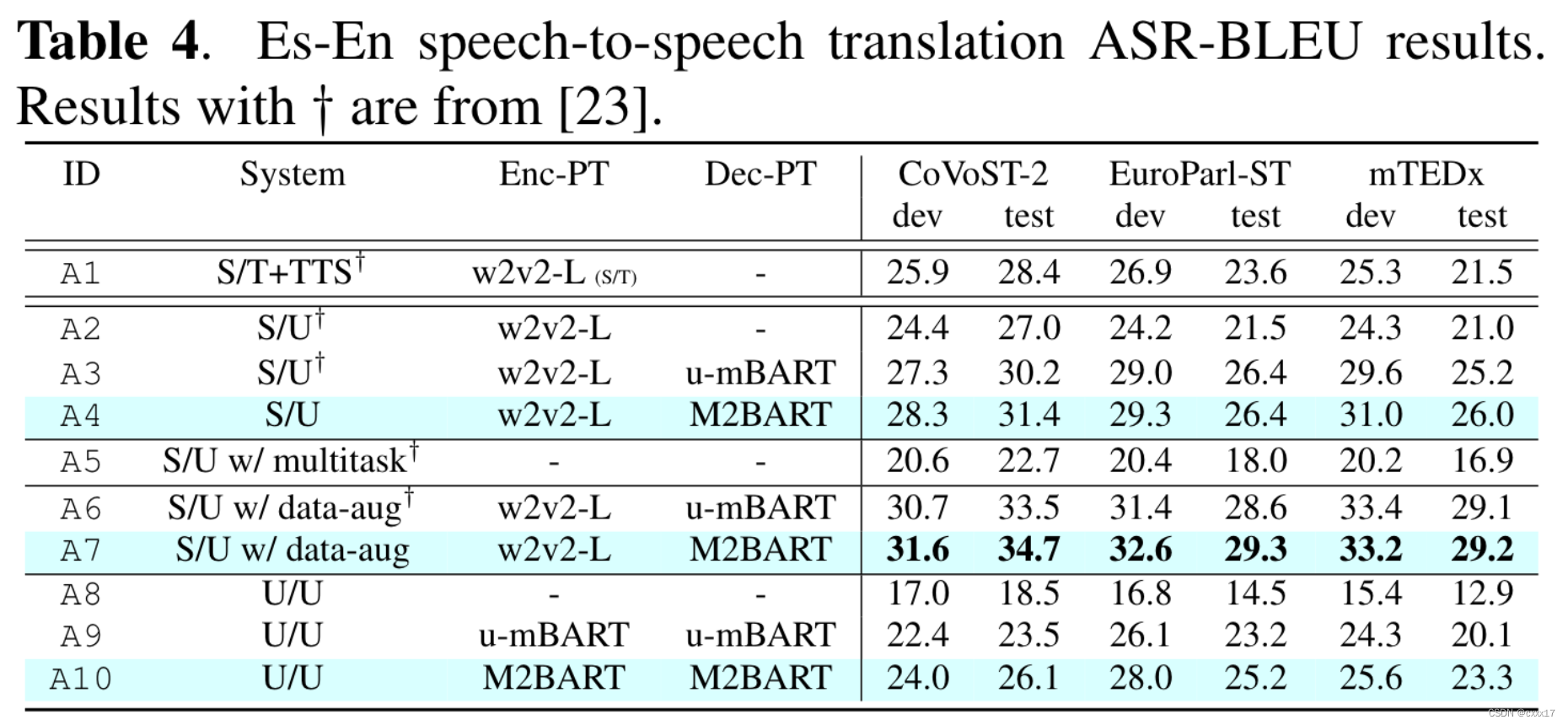
A3 vs A4 and A6 vs A7: m2bart better than u-mbart
Es-En Speech-to-text translation

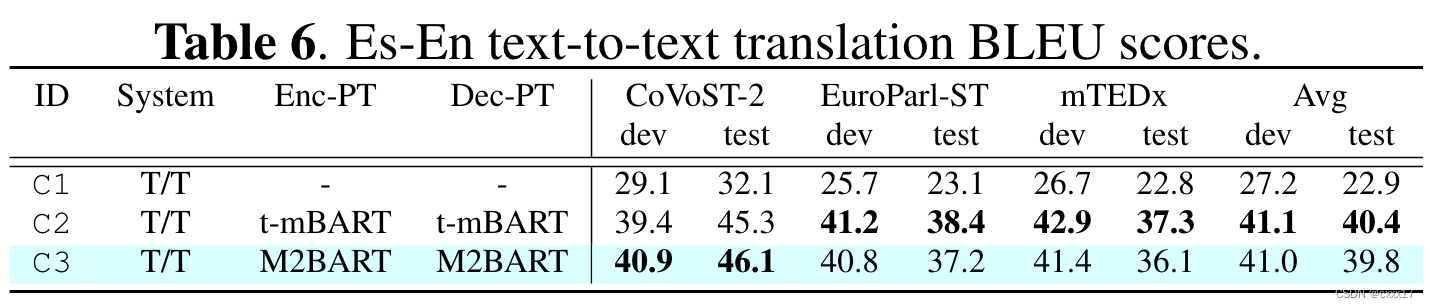
Es-En Text-to-text translation
En-Hokkien translation

Single system for any-to-any translation

Ablation
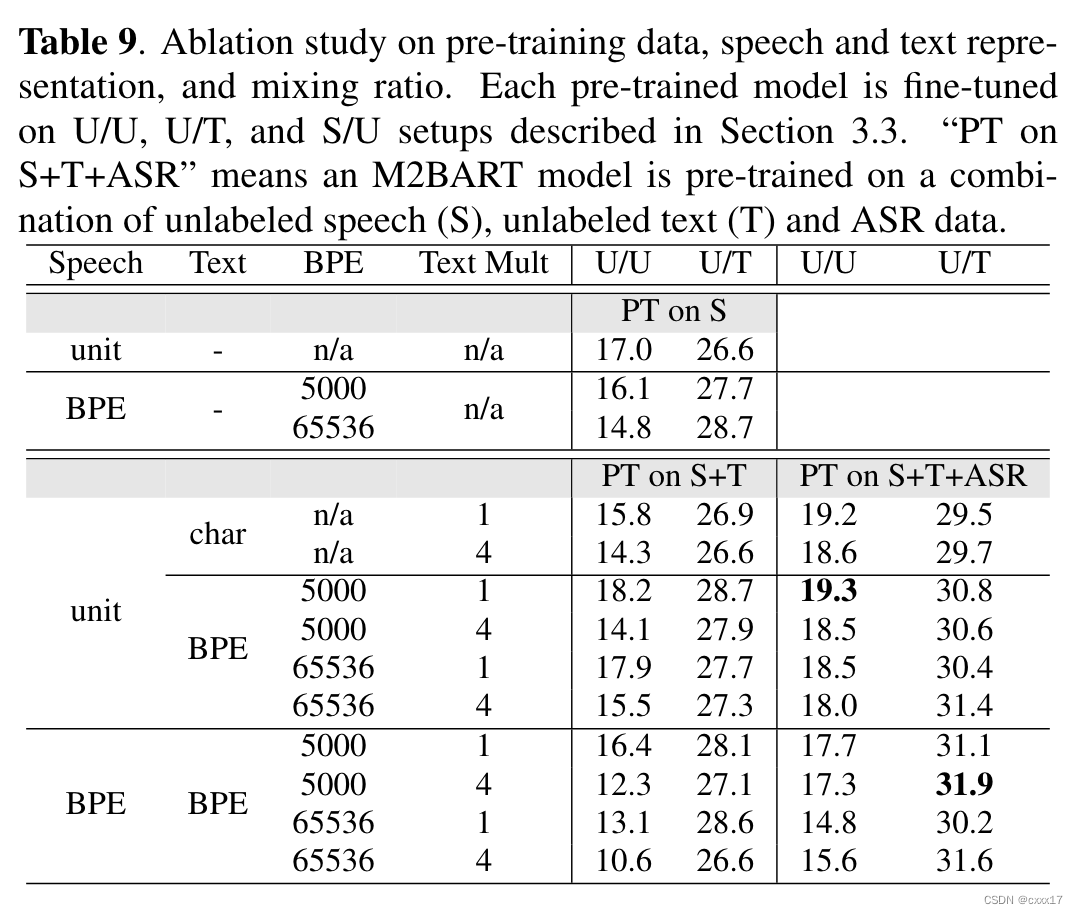















 2754
2754











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









