






 本文介绍了PolyVoice,一种使用语言模型的语音到语音翻译系统,包括解码器-only模型、前端的翻译模块、后端的合成模块以及用于语义和音频单位预测的额外语言模型。它利用MHubert提取semanticunits,采用自回归和非自回归模型处理Acousticunits和SoundStreamCodec。
本文介绍了PolyVoice,一种使用语言模型的语音到语音翻译系统,包括解码器-only模型、前端的翻译模块、后端的合成模块以及用于语义和音频单位预测的额外语言模型。它利用MHubert提取semanticunits,采用自回归和非自回归模型处理Acousticunits和SoundStreamCodec。
PolyVoice: Language Models for Speech to Speech Translation
LM-based method in S2ST
contributions
- Decoder-only model for speech2speech translation.
- Unit-based audio LM predicts the SoundStream Codec
Overview of PolyVoice
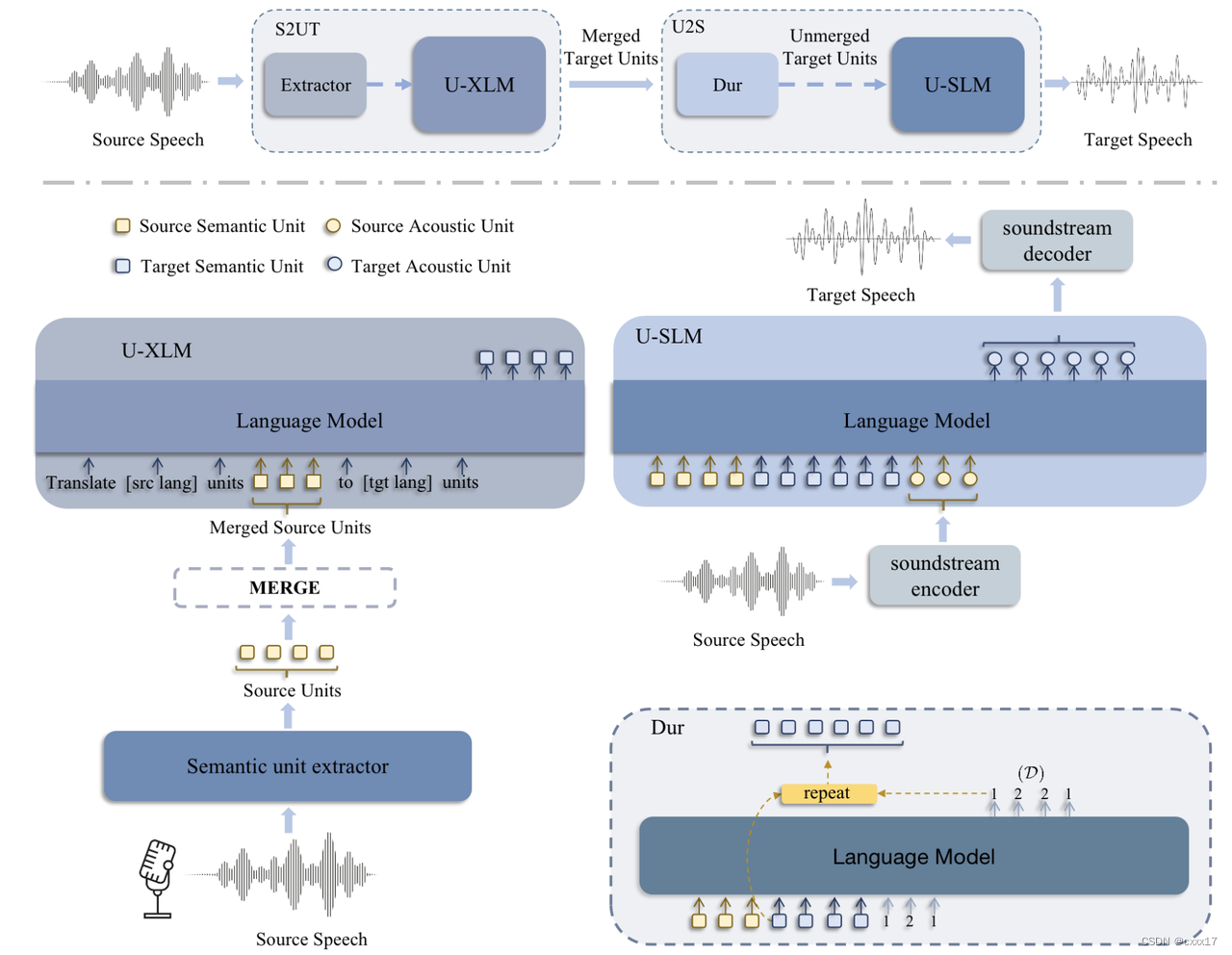 two LM-based components: a S2UT front-end for translation and a U2S back-end for synthesis.
two LM-based components: a S2UT front-end for translation and a U2S back-end for synthesis.
An extra language model for duration prediction.
- Semantic unit are extracted by mhubert
- Acoustic units are soundstream codec(residual vector quantizer), using a autoregressive model and a non-autoregressive model.















 938
938











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









