







安装完Elasticsearch后,需要对其进行配置,包括以下几部分:节点和集群配置、系统配置、安全配置。
此篇记录节点和集群配置的内容,后续将更新系统配置和安全配置。
节点和集群配置:
通过编辑/usr/local/elasticsearch-8.10.2/config/elasticsearch.yml文件进行配置,在集群内每个节点上都要进行配置。
1、Cluster部分:
cluster.name: 设置集群名称,保证所有集群内所有节点cluster.name保持一致。
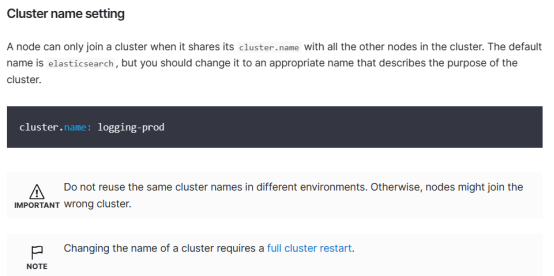
图片来源:Important Elasticsearch configuration | Elasticsearch Guide [8.10] | Elastic
改变集群名称需要完整的集群重启:
Full-cluster restart and rolling restart | Elasticsearch Guide [8.10] | Elastic
2、Node部分:
node.name: 设置节点名称,为每个节点设置不同的名称。
node.roles: 设置节点角色
Node | Elasticsearch Guide [8.10] | Elastic
说明:ES 7.9之前的版本配置节点用类似node.master:true方式,此方法在ES 8.x已舍弃。
(1)主节点
主节点负责轻量级的集群范围的操作,例如创建或删除索引,跟踪哪些节点是集群的一部分,并决定将哪些分片分配给哪些节点。拥有一个稳定的主节点对集群的健康状况很重要。
每个符合主节点条件的节点在磁盘上包含以下数据:集群中每个索引的索引元数据,以及集群范围的元数据,例如设置和索引模板。
专用的主节点配置方式:node.roles: [ master ]

(2)数据节点
数据节点包含包含已编制索引的文档的分片。数据节点处理与数据相关的操作,如 CRUD、搜索和聚合。这些操作会占用大量 I/O、内存和 CPU 资源。监控这些资源,并在数据节点过载时添加更多数据节点很重要。
每个数据节点在磁盘上包含以下数据:分配给该节点的每个分片的分片数据,与分配给该节点的每个分片对应的索引元数据,以及集群范围的元数据,例如设置和索引模板。
专用的数据节点配置方式:node.roles: [ data ]

(3)协调节点
只有协调功能的协调节点作用类似于智能负载均衡器。
专用的协调节点配置方式:node.roles: [ ]

(4)采集节点
采集节点可以执行预处理管道,该管道由一个或多个采集处理器组成。取决于采集处理器执行的操作类型和所需的资源,拥有专用的采集节点是有意义的,该节点将仅执行此特定任务。
专用的采集节点配置方式:node.roles: [ ingest ]
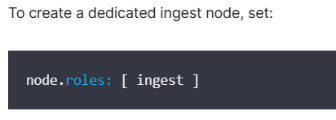
3、Path部分:
(1)path.data:设置节点数据的存储路径,默认在$ES_HOME/data目录下。
每个符合数据和主节点条件的节点都需要访问一个数据目录,其中将存储分片、索引和集群的元数据。

说明:设置多个数据路径的方式,已经在ES 7.13.0版本中弃用。
(2)path.logs: 设置节点日志的存储路径,默认在$ES_HOME/logs目录下。
Elasticsearch 将应用日志况写入到一个logs目录,其中包含集群的健康和运行状。
在生产模式下,建议将path.data和path.logs设置在$ES_HOME之外。
4、Network部分:
Networking | Elasticsearch Guide [8.10] | Elastic
默认情况下,Elasticsearch 仅绑定到localhost,这意味着它无法被远程访问。此配置足以满足本地开发集群(一个或多个节点都在同一主机上运行)的使用。如果集群有多个主机,或者需要被远程客户端访问,则必须调整某些网络设置如network.host。
(1)network.host:
绑定到一个可以被客户端和其他节点连接到的地址。可以是IP地址、主机名或者一个特定的值。

(2)http.port:
用于 HTTP 客户端通信的端口。可以是一个值或者一个范围,如果指定了范围,则节点将绑定到范围内第一个可用端口。默认是9200-9300.
(3)transport.port:
传输层节点间通信的端口。可以是一个值或者一个范围,如果指定了范围,则节点将绑定到范围内第一个可用端口。默认是9300-9400。
在每个符合主节点条件的节点上,将它设置为一个值,不要设置为一个范围。
(4)http.host
默认跟network.host保持一致

(5)transport.host
默认跟network.host保持一致。

5、Discovery部分:
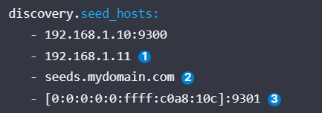
(1)discovery.seed_hosts:
用于集群内节点间互相发现。提供了集群内符合主节点条件的其他节点列表,可以是IP地址或者主机名。可以是数组或序列形式。

(2)cluster.initial_master_nodes
首次启动 Elasticsearch 集群时,集群bootstrapping步骤要确定一组符合主节点条件的节点,其投票计入第一次选举。在开发模式下,没有discovery设置,此步骤由节点自己自动执行。在生产模式下,auto-bootstrapping不安全,必须明确上述节点列表。列表内容可以是节点名称/主机名/IP地址。

注意:集群首次成功形成后,将cluster.initial_master_nodes这项从每个节点的配置中删掉。重启集群或者在已有集群中加入新节点时不要使用这个设置。
cluster bootstrapping:
Bootstrapping a cluster | Elasticsearch Guide [8.10] | Elastic
开发模式vs生产模式
Important system configuration | Elasticsearch Guide [8.10] | Elastic

















 1187
1187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









