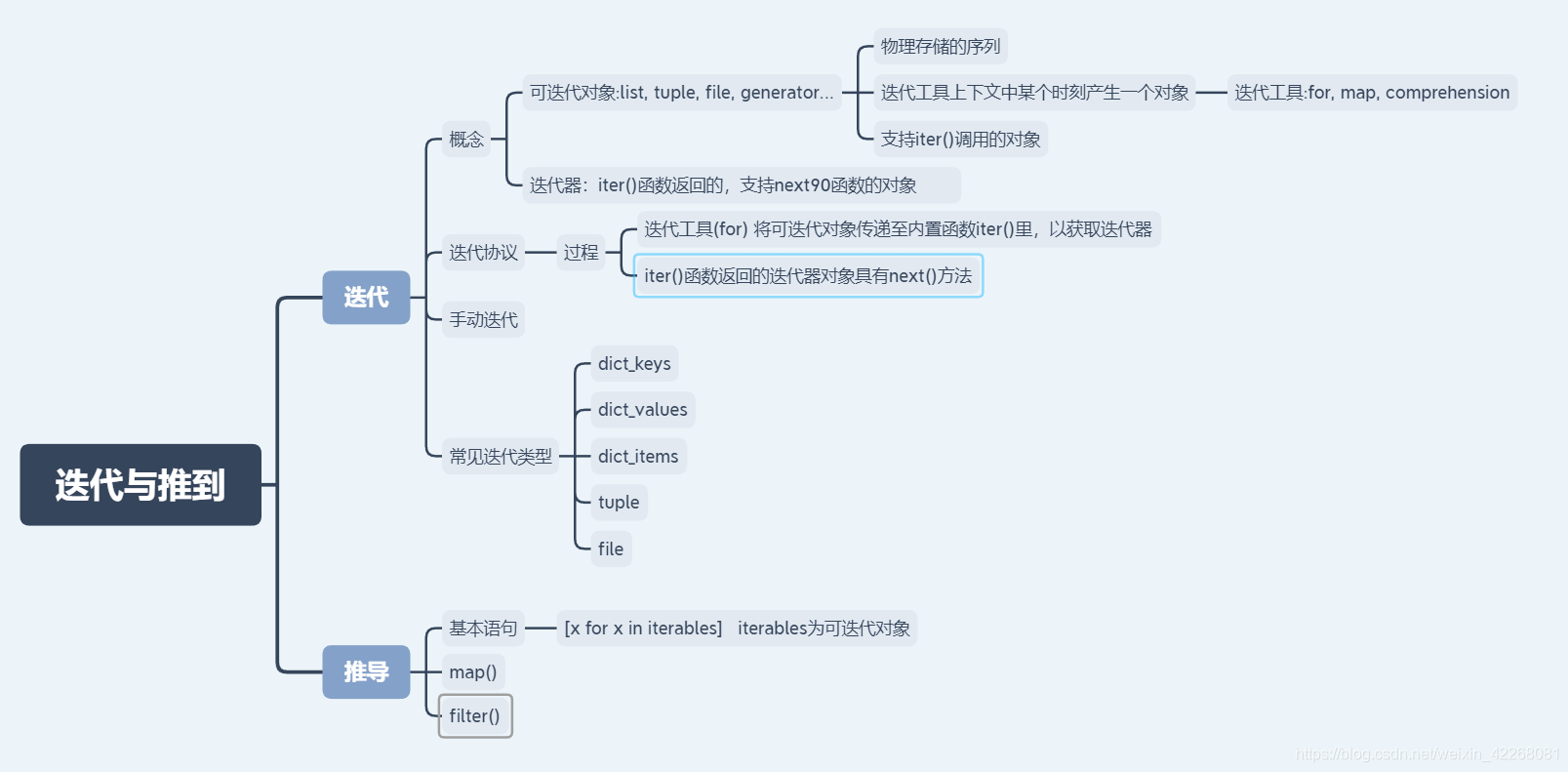
scores =[85,76,42,56,98,77,98]
I =iter(scores)#I为迭代器对象
I.__next__()
I.__next__()....
I.__next__()#直到输出98 再迭代会报错 StopIteration异常#next(I)#捕获异常正常输出whileTrue:try:
s =next(I)except StopIteration:breakprint(s)
students =['tom','Jerry','Nike']
I =iter(students)
s =next(I)
s.upper()#输出TOM
s = I.__next__()
s.upper()#输出 JERRY
s = i.__next__()
s #输出Nikenext(I)#报错 StopIteration异常
字典
emp ={'name':'Tom','salary':8000,'job':'dev'}type(emp.keys())#查看字典 键的类型为dict_keys(可迭代)for key in emp.keys():print(key)#输出 name salary jobtype(emp.values())#查看字典 值的类型为dict_values(可迭代)for value in emp.value.values():print(value)#输出 Tom 8000 devfor k,v in emp.items():print({}>{}.format(k, v))#打印结果'''
name -> Tom
salary -> 8000
job -> dev
'''
f =open('data.txt','r','encoding='utf-8')next(f)
输出'1\n'
f.__next__()
输出'2\n'
f.__next__()
输出'3\n'
f.__next__()#报错 StopIteration异常
f =open('data.txt','r', encoding='utf8')iter(f)is f #运行结果为True 表示f为可迭代对象#可以使用for .. in ..for line inopen('data.txt','r','encoding='utf8'):print(line)
推导
scores =(85,76,42,56,98,77,98)
results =[]for x in scores:
result.append(x)
results #输出[85, 76, 42, 56, 98, 77, 98]#推导式
results =[x for x in scores]
results #输出[85, 76, 42, 56, 98, 77, 98]#map()内置函数
results3 =map(lambda x: x +2, scores)#每个数字加2
results3 #map对象list(results3)#转换为list对象#推导式
results =[x +2for x in scores]
students =['Tom','Jerry','Mike'][n.upper()for n in students]#filter()内置函数print(list(filter(lambda x: x>=60, scores)))#输出分数大于60的#推导式[x for x in scores if x >=60]#使出分数大于60的
students =['Tom','Jerry','Mike'][n for n in students if'e'in n]#输出含有e的[x +2for x in scores if x <=60]#将小于60的加两分#{}返回集合{s for s in scorces}#去重 因为集合是一个无序的不重复元素序列#()推导返回是生成器而不是元组
t =(s for s in scores)type(t)#t为生成器类型





















 8142
8142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









