







 本文详细阐述了线程池的工作机制,包括任务执行流程、状态转换、线程关闭方式、为何需阻塞队列以及线程异常处理。重点讲解了核心线程数和最大线程数的设置原则,并以Tomcat线程池为例进行了实例分析。
本文详细阐述了线程池的工作机制,包括任务执行流程、状态转换、线程关闭方式、为何需阻塞队列以及线程异常处理。重点讲解了核心线程数和最大线程数的设置原则,并以Tomcat线程池为例进行了实例分析。
目录
学习内容重点:
1.线程池的核心线程数、最大线程数该如何设置
2.线程池执行任务的具体流程是怎样的?
3.线程池的五种状态是如何流转的?
4.线程池中的线程是如何关闭的?
5.线程池为什么一定得是阻塞队列?
6.线程发生异常,会被移出线程池吗?
7.Tomcat是如何自定义线程池的?
线程池执行任务的具体流程是怎样的?


execute(Runnable command)方法执行时会分为三步:
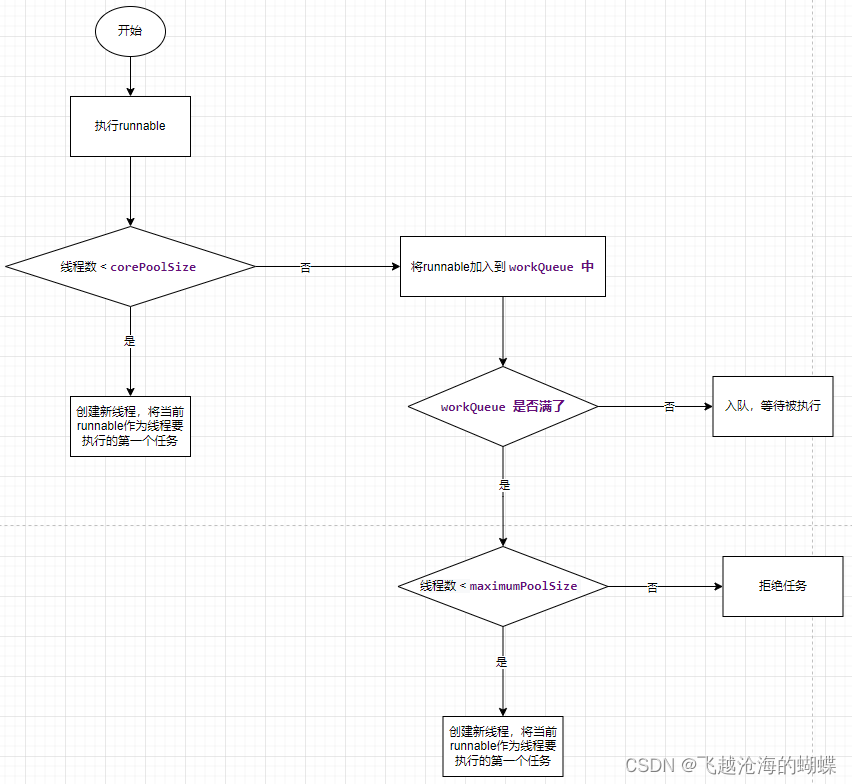
ps:1.提交一个Runnable时,不管当前线程池中的线程是否空闲,只要数量小于核心线程数就会创建新线程。
2.ThreadPoolExecutor相当于是非公平的,比如队列满了之后提交的Runnable可能会比正在排队的Runnable先执行。
线程池的五种状态是如何流转的?
线程池有五种状态:
- RUNNING:会接收新任务并且会处理队列中的任务
- SHUTDOWN:不会接收新任务并且会处理队列中的任务
- STOP:不会接收新任务并且不会处理队列中的任务,并且会中断在处理的任务(注意:一个任务能不能被中断得看任务本身)
- TIDYING:所有任务都终止了,线程池中也没有线程了,这样线程池的状态就会转为TIDYING,一旦达到此状态,就会调用线程池的terminated()
- TERMINATED:terminated()执行完之后就会转变为TERMINATED
这五种状态并不能任意转换,只会有以下几种转换情况:

线程池中的线程是如何关闭的?
我们一般会使用thread.start()方法来开启一个线程,那如何停掉一个线程呢?
Thread类提供了一个stop(),但是标记了@Deprecated,为什么不推荐用stop()方法来停掉线程呢?
因为stop()方法太粗暴了,一旦调用了stop(),就会直接停掉线程,但是调用的时候根本不知道线程刚刚在做什么,任务做到哪一步了,这是很危险的。
这里强调一点,stop()会释放线程占用的synchronized锁(不会自动释放ReentrantLock锁,这也是不建议用stop()的一个因素)。
所以,我们建议通过自定义一个变量,或者通过中断来停掉一个线程,比如:
不同点在于,当我们把stop设置为true时,线程自身可以控制到底要不要停止,何时停止,同样,我们可以调用thread的interrupt()来中断线程:
不同的地方在于,线程sleep过程中如果被中断了会接收到异常。
讲了这么多,其实线程池中就是通过interrupt()来停止线程的,比如shutdownNow()方法中会调用:
void interruptIfStarted() {
Thread t;
if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
}
}
}线程池为什么一定得是阻塞队列?
线程池中的线程在运行过程中,执行完创建线程时绑定的第一个任务后,就会不断的从队列中获取任务并执行,那么如果队列中没有任务了,线程为了不自然消亡,就会阻塞在获取队列任务时,等着队列中有任务过来就会拿到任务从而去执行任务。
通过这种方法能最终确保,线程池中能保留指定个数的核心线程数,关键代码为:
try {
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}某个线程在从队列获取任务时,会判断是否使用超时阻塞获取,我们可以认为非核心线程会poll(),核心线程会take(),非核心线程超过时间还没获取到任务后面就会自然消亡了。
线程发生异常,会被移出线程池吗?
答案是会的,那有没有可能核心线程数在执行任务时都出错了,导致所有核心线程都被移出了线程池?
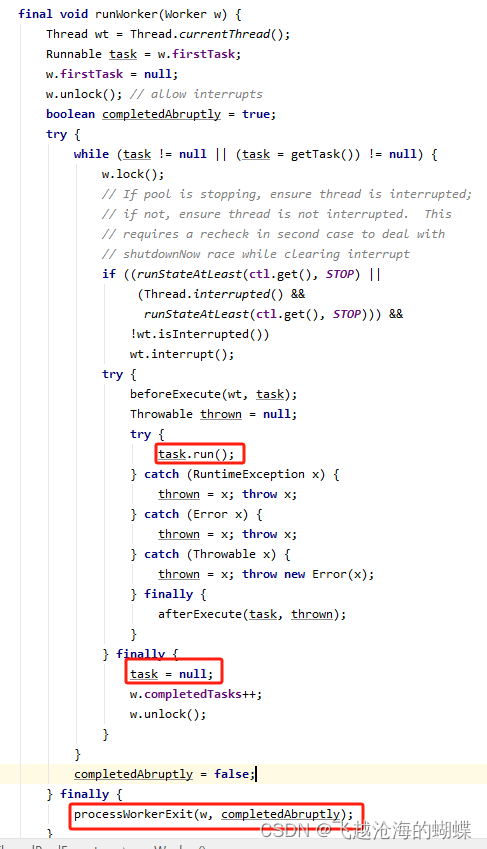
在源码中,当执行任务时出现异常时,最终会执行processWorkerExit(),执行完这个方法后,当前线程也就自然消亡了,但是!processWorkerExit()方法中会额外再新增一个线程,这样就能维持住固定的核心线程数。
Tomcat是如何自定义线程池的?
Tomcat中用的线程池为org.apache.tomcat.util.threads.ThreadPoolExecutor,注意类名和JUC下的一样,但是包名不一样。
Tomcat会创建这个线程池:
public void createExecutor() {
internalExecutor = true;
TaskQueue taskqueue = new TaskQueue();
TaskThreadFactory tf = new TaskThreadFactory(getName() + "-exec-", daemon, getThreadPriority());
executor = new ThreadPoolExecutor(getMinSpareThreads(), getMaxThreads(), 60, TimeUnit.SECONDS,taskqueue, tf);
taskqueue.setParent( (ThreadPoolExecutor) executor);
}注入传入的队列为TaskQueue,它的入队逻辑为:
public boolean offer(Runnable o) {
//we can't do any checks
if (parent==null) {
return super.offer(o);
}
//we are maxed out on threads, simply queue the object
if (parent.getPoolSize() == parent.getMaximumPoolSize()) {
return super.offer(o);
}
//we have idle threads, just add it to the queue
if (parent.getSubmittedCount()<=(parent.getPoolSize())) {
return super.offer(o);
}
//if we have less threads than maximum force creation of a new thread
if (parent.getPoolSize()<parent.getMaximumPoolSize()) {
return false;
}
//if we reached here, we need to add it to the queue
return super.offer(o);
}特殊在:
- 入队时,如果线程池的线程个数等于最大线程池数才入队
- 入队时,如果线程池的线程个数小于最大线程池数,会返回false,表示入队失败
这样就控制了,Tomcat的这个线程池,在提交任务时:
- 仍然会先判断线程个数是否小于核心线程数,如果小于则创建线程
- 如果等于核心线程数,会入队,但是线程个数小于最大线程数会入队失败,从而会去创建线程
所以随着任务的提交,会优先创建线程,直到线程个数等于最大线程数才会入队。
当然其中有一个比较细的逻辑是:在提交任务时,如果正在处理的任务数小于线程池中的线程个数,那么也会直接入队,而不会去创建线程,也就是上面源码中getSubmittedCount的作用。
线程池的核心线程数、最大线程数该如何设置?
线程池中有两个非常重要的参数:
- corePoolSize:核心线程数,表示线程池中的常驻线程的个数
- maximumPoolSize:最大线程数,表示线程池中能开辟的最大线程个数
那这两个参数该如何设置呢?
线程池负责执行的任务分为三种情况:
- CPU密集型任务
- IO密集型任务
- 混合型任务
CPU密集型任务的特点时,线程在执行任务时会一直利用CPU,所以对于这种情况,就尽可能避免发生线程上下文切换。
所以对于CPU密集型任务,线程数最好就等于CPU核心数,可以通过以下API拿到你电脑的核心数:
Runtime.getRuntime().availableProcessors()
只不过,为了应对线程执行过程发生中断或其他异常导致线程阻塞的请求,我们可以额外在多设置一个线程,这样当某个线程暂时不需要CPU时,可以有替补线程来继续利用CPU。
所以,对于CPU密集型任务,我们可以设置线程数为:CPU核心数+1
IO型任务,线程在执行IO型任务时,可能大部分时间都阻塞在IO上,假如现在有10个CPU,如果我们只设置了10个线程来执行IO型任务,那么很有可能这10个线程都阻塞在了IO上,这样这10个CPU就都没活干了,所以,对于IO型任务,我们通常会设置线程数为:2*CPU核心数
通常,如果IO型任务执行的时间越长,那么同时阻塞在IO上的线程就可能越多,我们就可以设置更多的线程,但是,线程肯定不是越多越好,我们可以通过以下这个公式来进行计算:
线程数 = CPU核心数 *( 1 + 线程等待时间 / 线程运行总时间 )
- 线程等待时间:指的就是线程没有使用CPU的时间,比如阻塞在了IO
- 线程运行总时间:指的是线程执行完某个任务的总时间
按上述公式,如果我们执行的任务IO密集型任务,那么:线程等待时间 = 线程运行总时间,所以:
线程数 = CPU核心数 *( 1 + 线程等待时间 / 线程运行总时间 )
= CPU核心数 *( 1 + 1 )
= CPU核心数 * 2
以上只是理论,实际工作中情况会更复杂
总结,我们在工作中,对于:
- CPU密集型任务:CPU核心数+1,这样既能充分利用CPU,也不至于有太多的上下文切换成本
- IO型任务:建议压测,或者先用公式计算出一个理论值(理论值通常都比较小)
- 对于核心业务(访问频率高),可以把核心线程数设置为我们压测出来的结果,最大线程数可以等于核心线程数,或者大一点点,比如我们压测时可能会发现500个线程最佳,但是800个线程时也还行,此时800就可以为最大线程数
- 对于非核心业务(访问频率不高),核心线程数可以比较小,避免操作系统去维护不必要的线程,最大线程数可以设置为我们计算或压测出来的结果。















 75
75











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









