







 本文介绍了WordNet的概念及其在中文和英文语料上的安装与使用方法。包括词义查询、同义词查询等功能,并提供了详细的代码示例。
本文介绍了WordNet的概念及其在中文和英文语料上的安装与使用方法。包括词义查询、同义词查询等功能,并提供了详细的代码示例。
最近在中文语料上数据分析,想借用一些外部资源,就想到了WordNet,在这里记录一下,以备后用。
(一)WordNet的介绍
WordNet是由Princeton 大学的心理学家,语言学家和计算机工程师联合设计的一种基于认知语言学的英语词典。它不是光把单词以字母顺序排列,而且按照单词的意义组成一个“单词的网络”。
它是一个覆盖范围宽广的英语词汇语义网。名词,动词,形容词和副词各自被组织成一个同义词的网络,每个同义词集合都代表一个基本的语义概念,并且这些集合之间也由各种关系连接。
WordNet包含描述概念含义,一义多词,一词多义,类别归属,近义,反义等问题,访问以下网页,可使用wordnet的基本功能: http://wordnetweb.princeton.edu/perl/webwn
(二)WordNet的安装
首先要安装nltk.
pip install nltk
然后用nltk的downloader下载“wordnet”,获取相关的数据。
import nltk
nltk.download('wordnet') # 这是英文的wordnet
如果要使用中文的WordNet,需要再下载一个组件“omw”。
nltk.download('omw') # omw 代表Open Multilingual Wordnet
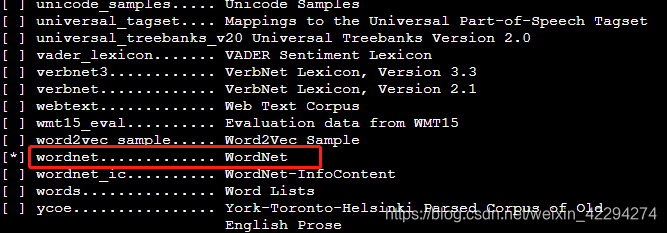
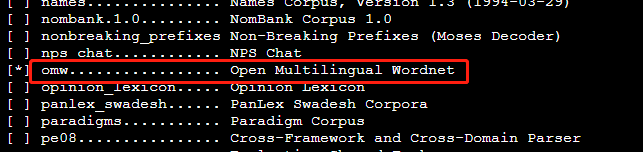
安装好以后,就可以使用啦。
(三)中英文WordNet的使用
(1)词义查询
word.definition()
- 英文
from nltk.corpus import wordnet as wn
# 获得单个词的定义查询
apple = wn.synset('apple.n.01')
print(apple.definition())
# 获得该词的所有词性及解释下的定义
word = 'apple'
for w in wn.synsets(word):
print(w.definition())
# 输出:
# fruit with red or yellow or green skin and sweet to tart crisp whitish flesh
# fruit with red or yellow or green skin and sweet to tart crisp whitish flesh
# native Eurasian tree widely cultivated in many varieties for its firm rounded edible fruits
- 中文
因为中文在查询时,本质上还是映射到英文语义上去,所以不能直接用类似“秘密.n.01”这种形式,只用用synsets来查,synset是没有‘lang’这个参数的。
word = '秘密'
print('origin word:', word)
if len(wn.synsets(word,lang='cmn')) == 0:
print('No this word')
for w in wn.synsets(word,lang='cmn'):
print(w)
print(w.definition())
# 输出:
# origin word:秘密
# Synset('mystery.n.01')
# something that baffles understanding and cannot be explained
# Synset('secret.n.01')
#something that should remain hidden from others (especially information that is not to be passed on)
# Synset('privacy.n.02')
# the condition of being concealed or hidden
一些注释
一个词可能同时具有动词、名词等多种词性,而且每个词性下可能具有多种解释。例如,在查询"privacy"一词时:
- “privacy.n.01” 代表“the quality of being secluded from the presence or view of others”,
- "privacy.n.02"代表“the condition of being cncealed or hidden”
n代表名词,v代表动词,数字代表第几个。
`
(2) 同义词查询
word.lemma_names()
具体调用过程与词义查询基本一致。
- 英文
from nltk.corpus import wordnet as wn
# 方法一:
print(wn.synset('apple.n.01').lemma_names())
# 方法二:
for w in wn.synsets('apple'):
print(w.lemma_names())
- 中文
word = '秘密'
for w in wn.synsets(word,lang='cmn'):
print(w.lemma_names())
# 输出
# ['privacy', 'privateness', 'secrecy', 'concealment']
# ['mystery', 'enigma', 'secret', 'closed_book']
# ['mystery', 'enigma', 'secret', 'closed_book']
这里相当于是,把中文的“秘密”与英文中的词做了一个对应,对应到三个名词,分别是上面提到的’mystery.n.01’,‘secret.n.01’ 和 ‘privacy.n.02’。在找同义词时,分别找到了“秘密”这个中文词对应的三个英文词的同义词。
(3) 其他查询
hypernyms() # 上位(父类)
hyponyms() # 下位(子类)
lemma_names() # 同义
antonyms() # 反义
entailments() # 蕴含关系
part_meronyms() # 部分
substance_meronyms() # 实质
member_holonyms() # 成员
目前只用到了同位词,以后用到什么其他的模块,再来补充吧。
参考:
https://blog.csdn.net/xieyan0811/article/details/82314042
https://blog.csdn.net/MAILLIBIN/article/details/100580676

















 3318
3318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









