







Human-in-the-loop
最近在看这本书,记一些笔记帮助梳理。
基本上是 重点部分翻译+梳理+自己的理解。
(最开始在知乎上看到有人写这本书的笔记,但是好像后面断更了,所以就自己写啦,希望可以坚持看完hh)

文章目录
-
- PART 1: First Steps
-
- Chapter 1. Introduction to Human-in-the-Loop Machine Learning
-
- 1.1 The basic principles of Human-in-the-Loop Machine Learning
- 1.2 Introducing Annotation
- 1.3 Introducing Active Learning: improving the speed and reducing the cost of training data
- 1.4 Machine Learning and Human-Computer Interaction
- 1.5 Machine Learning-Assisted Human vs Human-Assisted Machine Learning
- 1.6 Transfer learning to kick-start your models
- 1.7 What to expect in this text
- Chapter 2. Getting Started with Human-in-the-Loop Machine Learning
PART 1: First Steps
Chapter 1. Introduction to Human-in-the-Loop Machine Learning
AI的“智能”不仅来源于训练数据,还包括人类的反馈。所以一个重要的问题是人和机器学习算法彼此交互来解决问题的正确方式是什么。
标注和主动学习是人在环路机器学习的基石, 它们决定了如何获取训练数据,以及当没有足够的预算或时间对所有数据进行人工标注时,将哪些数据正确地放在标注者面前是更合适。 迁移学习使我们能够避免冷启动,使现有的机器学习模型快速适应新任务。
1.1 The basic principles of Human-in-the-Loop Machine Learning
人在回路的机器学习是人和机器学习过程进行交互,来解决以下的问题:
- 使ML更准确
- 使ML更快达到所需的准确度
- 使人类更准确
- 使人类更高效
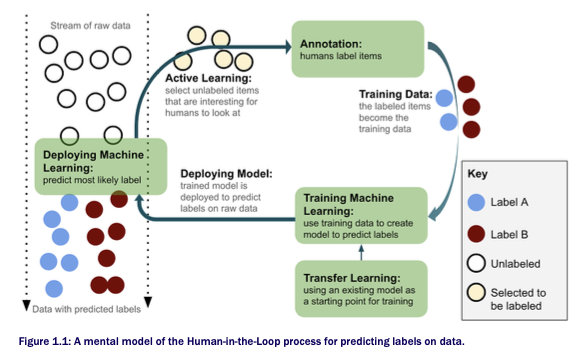
1.2 Introducing Annotation
Annotation就是人工标注。这个过程看似简单,但非常耗时。有些标注很简单,比如就打上一个0或1的标签,但有些标注也挺复杂的,比如在一段视频中标注所有物体的位置等等。标注工作对模型的好坏也有着非常大的影响,甚至和模型本身一样重要。
在学术界,我们倾向于保持数据集不变,因为这样便于比较出各种算法孰优孰劣。但是在工业界,数据集总是在变化。一是因为不断增加标注数据对于提高模型性能还是很重要的,二是实际环境下数据的性质会随着时间的推移而产生变化,在新生产生活中用到的模型需要不断学习和适应新的数据环境。
标注还有一个常见的问题就是人工错误带来的噪声。随机的噪声可能会帮助算法避免过拟合,进而更加准确和鲁棒,但是人类的错误往往都是有一定倾向性、主观性的,就会给数据引入不可恢复的偏差。
1.3 Introducing Active Learning: improving the speed and reducing the cost of training data
- 主动学习策略
标注数据对于监督学习是至关重要的。有三种基本的主动学习策略:不确定性采样(Uncertainty Sampling)、多样性采样(Diversity Sampling)和随机采样(Random Sampling)。一些文献中会将不确定性采样和多样性采样称为“Exploitation”和“Exploration”
Random Sampling 就是随机采样。这种一般都用在标注初期。
Unc
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









