







一、线性回归与逻辑回归
(一)线性回归
1. 算法概述
回归的目的是预测数值型的目标值。
线性回归的优点:结果易于理解,计算上不复杂。缺点:对非线性的数据拟合不好。适用数据类型:数值型和标称型数据。
回归的一般方法:(1) 收集数据:采用任意方法收集数据。(2) 准备数据:回归需要数值型数据,标称型数据将被转成二值型数据。(3) 分析数据:绘出数据的可视化二维图将有助于对数据做出理解和分析,在采用缩减法求得新回归系数之后,可以将新拟合线绘在图上作为对比。(4) 训练算法:找到回归系数。(5) 测试算法:使用或者预测值和数据的拟合度,来分析模型的效果。(6) 使用算法:使用回归,可以在给定输入的时候预测出一个数值,这是对分类方法的提升,因为这样可以预测连续型数据而不仅仅是离散的类别标签。
2.实战:预测A股哪些股票会涨
(1)收集、准备数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import datetime as dt
# 下载某一个公司的股票交易历史
# 600519为贵州茅台
import tushare as ts
data = ts.get_hist_data('600519')
data.to_csv('600519.csv')
data = pd.read_csv(r'600519.csv')
(2)分析数据
print(data.shape)
data.head()
data.info()数据集特征及标签的意义详见:http://tushare.org/trading.html
选择date作为索引,close收盘价作为标签,其余12个变量为特征,特征和标签均为连续型的数值。因此选择回归算法。
# 将每一个数据的键值的类型从字符串转为日期
data['date'] = pd.to_datetime(data['date'])
data = data.set_index('date')
# 按照时间升序排列
data.sort_values(by=['date'], inplace=True, ascending=True)
data.tail()
# 检测是否有缺失数据NaN
data.isna().sum()
#使用dropna()滤除缺失数据
#df.dropna(axis=0 , inplace=True)#作K线图
min_date = data.index.min()
max_date = data.index.max()
print ("first date is",min_date)
print ("last date is",max_date)
print (max_date - min_date)
from plotly import tools
from plotly.graph_objs import *
from plotly.offline import init_notebook_mode, iplot, iplot_mpl
init_notebook_mode()
import plotly.plotly as py
import plotly.graph_objs as go
trace = go.Ohlc(x=data.index, open=data['open'], high=data['high'], low=data['low'], close=data['close'])
data_k = [trace]
iplot(data_k, filename='simple_ohlc')price_change:价格变动、p_change:涨跌幅与涨跌幅两个特征与开盘价、收盘价等特征之间有相关性,因此将其去掉。
data1 = data.drop(['price_change', 'p_change'], axis=1)
data1.shape(3)训练、测试算法
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
#选择后num个数据做预测
num = 5
y = data1['close']
y1 = y[:-num]
X = data1.drop(['close'], axis=1)
scaler = StandardScaler()
X1 = scaler.fit_transform(X)
X2 = X1[:-num,:]
print(X2.shape, y1.shape)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X2, y1, random_state = 0)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
lr = LinearRegression()
lr.fit(X_train, y_train)
result = lr.predict(X_test)在回归类算法中,有两种不同的角度来看待回归的效果:第一,是否预测到了正确的数值。使用均方误差来进行评估。第二,是否拟合到了足够的信息。使用决定系数来进行评估。
from sklearn.metrics import mean_squared_error, r2_score
# 均方误差
print("Mean squared error: %.2f" % mean_squared_error(y_test, result))
# 决定系数: 1代表完美预测
print('Variance score: %.2f' % r2_score(y_test, result))Mean squared error: 22.65
Variance score: 1.00
(4)使用算法
# 做预测
X_pred = X1[-num:]
y_pred = y[-num:]
forecast = lr.predict(X_pred)
trange = y_pred.index
forecast1 = pd.DataFrame(forecast, index = trange, columns=['forecast'])
df_pred = pd.concat([forecast1, y_pred], axis=1)
df_pred
# 画预测值和实际值
df_pred['close'].plot(color='green', linewidth=1)
df_pred['forecast'].plot(color='orange', linewidth=3)
plt.xlabel('Time')
plt.ylabel('Price')
plt.show()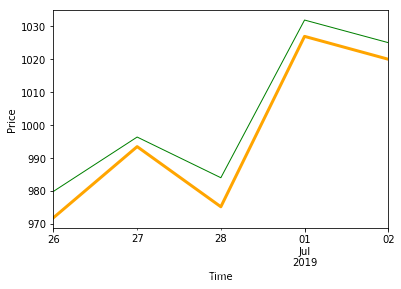
(二)逻辑回归
1. 算法概述
利用Logistic回归进行分类的主要思想是:根据现有数据对分类边界线建立回归公式,以此进行分类。“回归”一词源于最佳拟合,表示要找到最佳拟合参数集。训练分类器时的做法就是寻找最佳拟合参数,使用的是最优化算法。
Logistic回归的一般过程:(1) 收集数据:采用任意方法收集数据。(2) 准备数据:由于需要进行距离计算,因此要求数据类型为数值型。另外,结构化数据格式则最佳。(3) 分析数据:采用任意方法对数据进行分析。(4) 训练算法:大部分时间将用于训练,训练的目的是为了找到最佳的分类回归系数。(5) 测试算法:一旦训练步骤完成,分类将会很快。(6) 使用算法:首先,我们需要输入一些数据,并将其转换成对应的结构化数值;接着,基于训练好的回归系数就可以对这些数值进行简单的回归计算,判定它们属于哪个类别;在这之后,我们就可以在输出的类别上做一些其他分析工作。
Logistic回归优点:计算代价不高,易于理解和实现。缺点:容易欠拟合,分类精度可能不高。适用数据类型:数值型和标称型数据。
2.实战:预测是否银行客户会开设定期存款帐户
逻辑回归要求预测值为 0 或者 1, 自变量特征值应该彼此独立。该数据集来自UCI机器学习库(http://archive.ics.uci.edu/ml/datasets/Bank+Marketing),葡萄牙银行的电话营销。 分类目标是预测客户是否会开设到定期存款账户(预测值y)。
(1) 收集、准备数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rc("font", size=14)
data = pd.read_csv('banking.csv')
(2)分析数据
data.head()
data.info()
data.isna().sum()
print(data.shape)
print(list(data.columns))数据集特征及标签的意义详见:http://archive.ics.uci.edu/ml/datasets/Bank+Marketing
data['education'].unique()
# 将“basic.4y”,“basic.9y”和“basic.6y”组合在一起,称之为“basic”。
data['education']=np.where(data['education'] =='basic.9y', 'basic', data['education'])
data['education']=np.where(data['education'] =='basic.6y', 'basic', data['education'])
data['education']=np.where(data['education'] =='basic.4y', 'basic', data['education'])
data['y'].value_counts()
import seaborn as sns
sns.set(style="white")
sns.set(style="whitegrid", color_codes=True)
sns.countplot(x='y', data = data, palette='hls')
plt.show()
plt.savefig('count_plot')
count_no_sub = len(data[data['y']==0])
count_sub = len(data[data['y']==1])
pct_of_no_sub = count_no_sub/(count_no_sub+count_sub)
print('未开户的百分比: %.2f%%' % (pct_of_no_sub*100))
pct_of_sub = count_sub/(count_no_sub+count_sub)
print('开户的百分比: %.2f%%' % (pct_of_sub*100))
data.groupby('y').mean()
data.groupby('job').mean()
#data.groupby('marital').mean()
#data.groupby('education').mean()
%matplotlib inline
table=pd.crosstab(data.job,data.y)
table.div(table.sum(1).astype(float), axis=0).plot(kind='bar', stacked=True)
plt.title('Stacked Bar Chart of Job title vs Purchase')
plt.xlabel('Job')
plt.ylabel('Proportion of Purchase')
plt.savefig('purchase_vs_job')通过groupby分组函数观察数据可知,购买定期存款的客户的平均年龄高于未购买定期存款的客户的平均年龄。购买定期存款的客户的 pdays(自上次联系客户以来的日子)较低。 pdays越低,最后一次通话的记忆越好,因此销售的机会就越大。令人惊讶的是,购买定期存款的客户的销售通话次数较低。
我们可以计算其他特征值(如教育和婚姻状况)的分布,以更详细地了解我们的数据。具有不同工作、教育的人开立定期存款账户的频率不一样,因此是良好的预测因素。不同婚姻、一周工作时间的人开立定期存款账户的频率基本一样,似乎不是好的预测因素。
'job','marital','education','default','housing','loan','contact','month','day_of_week','poutcome'为名义变量,即变量之间是相互独立的,彼此之间完全没有联系,通过使用哑变量的方式来处理,才能够尽量向算法传达最准确的信息。
cat_vars=['job','marital','education','default','housing','loan','contact','month','day_of_week','poutcome']
for var in cat_vars:
cat_list = pd.get_dummies(data[var], prefix=var)
data=data.join(cat_list)
data_final=data.drop(cat_vars, axis=1)
data_final.columns.values观察数据可知,未开户的百分比: 88.73%,开户的百分比: 11.27%,标签的类别分布不均。使用SMOTE算法(合成少数过采样技术)对已经开户的用户进行上采样。 在高层次上,SMOTE算法原理:通过从次要类(已经开户的用户)创建合成样本而不是创建副本来工作。随机选择一个k-最近邻居并使用它来创建一个类似但随机调整的新观察结果。
X = data_final.loc[:, data_final.columns != 'y']
y = data_final.loc[:, data_final.columns == 'y'].values.ravel()
from sklearn.model_selection import train_test_split
from imblearn.over_sampling import SMOTE
os = SMOTE(random_state=0)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
columns = X_train.columns
os_data_X,os_data_y=os.fit_sample(X_train, y_train)
os_data_X = pd.DataFrame(data=os_data_X,columns=columns )
os_data_y= pd.DataFrame(data=os_data_y,columns=['y'])
# we can Check the numbers of our data
print("过采样以后的数据量: ",len(os_data_X))
print("未开户的用户数量: ",len(os_data_y[os_data_y['y']==0]))
print("开户的用户数量: ",len(os_data_y[os_data_y['y']==1]))
print("未开户的用户数量的百分比: ",len(os_data_y[os_data_y['y']==0])/len(os_data_X))
print("开户的用户数量的百分比: ",len(os_data_y[os_data_y['y']==1])/len(os_data_X))(3)训练、测试算法
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression()
logreg.fit(os_data_X, os_data_y.values.reshape(-1))
result = logreg.predict(X_test)在logistic回归当中使用一下指标说明拟合效果:
精确度:precision,正确预测为正的,占全部预测为正的比例,TP / (TP+FP)
召回率:recall,正确预测为正的,占全部实际为正的比例,TP / (TP+FN)
F1-score:精确率和召回率的调和平均数,2 * precision*recall / (precision+recall)
准确率:分类模型正确分类的样本数与总样本数之比。
宏平均值:macro average,所有标签结果的平均值
加权平均值:weighted average,所有标签结果的加权平均值
from sklearn.metrics import classification_report
print(classification_report(y_test, result)) precision recall f1-score support
0 0.98 0.86 0.92 10981
1 0.44 0.88 0.59 1376
accuracy 0.86 12357
macro avg 0.71 0.87 0.75 12357
weighted avg 0.92 0.86 0.88 12357ROC(Receiver Operating Characteristic)曲线:接收者操作特征,roc曲线上每个点反映着对同一信号刺激的感受性。横轴FPR:1-TNR,1-Specificity,FPR越大,预测正类中实际负类越多。纵轴TPR:Sensitivity(正类覆盖率),TPR越大,预测正类中实际正类越多。理想目标:TPR=1,FPR=0,即(0,1)点,故ROC曲线越靠拢(0,1)点,越偏离45度对角线越好。AUC(Area under Curve):ROC曲线下的面积,由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。AUC作为数值可以直观的评价分类器的好坏,值越大越好。
from sklearn.metrics import roc_auc_score
from sklearn.metrics import roc_curve
logit_roc_auc = roc_auc_score(y_test, logreg.predict(X_test))
fpr, tpr, thresholds = roc_curve(y_test, logreg.predict_proba(X_test)[:,1])
plt.figure()
plt.plot(fpr, tpr, label='Logistic Regression (area = %0.2f)' % logit_roc_auc)
plt.plot([0, 1], [0, 1],'r--')
plt.xlim([-0.01, 1.0])
plt.ylim([0.0, 1.01])
plt.legend(loc="lower right")
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic')
plt.savefig('Log_ROC')
plt.show()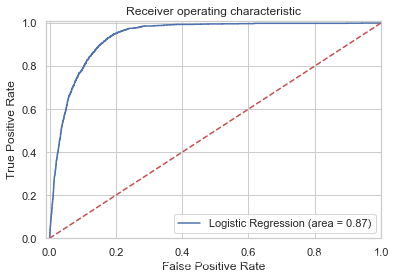
3.作业:通过逻辑回归预测Titanic乘客是否能在事故中生还
(1)作业要求:
a.按照以上处理的方式,处理仍然存在缺失数据的情况
首先看一下缺失值在哪一行。
data[data.isnull().values==True].drop_duplicates()
观察数据可知,缺失值在第1225和1309行,因此将其直接删除。
data = data.drop(data.index[[1225, 1309]])
data.shapeb.训练模型;根据模型,以 X_test 为输入,生成变量 y_pred
先使用sklearn库中的linear_model.LogisticRegression()的默认参数将模型跑出来,看一下结果。
lr = LogisticRegression()
lr.fit(X_train, y_train)
y_pred=lr.predict(X_test)print("准确率为 %2.3f" % accuracy_score(y_test, y_pred))
准确率为 0.817
(2)尝试提升模型的准确率
观察数据可知,age和fare为连续型的数值,无量纲化可以提升模型精度,因此将其数据进行尝试进行标准化处理。
X1 = X.copy()
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X1['fare'] = scaler.fit_transform(X1['fare'].values.reshape(-1, 1))
X1['age'] = scaler.fit_transform(X1['age'].values.reshape(-1, 1))
X1.tail()
# 将 X 和 y 分为两个部分
X_train, X_test, y_train, y_test = train_test_split(X1, y, test_size=0.2, random_state=2)
lr = LogisticRegression()
lr.fit(X_train, y_train)
y_pred=lr.predict(X_test)
print("准确率为 %2.3f" % accuracy_score(y_test, y_pred))准确率为 0.817。可见标准化数据后准确率并没有提升。
sklearn库中的LogisticRegression有很多参数,我们尝试调整penalty和C这两个参数,观察准确率是否有所提升。
class sklearn.linear_model.LogisticRegression (penalty=’l2’, dual=False, tol=0.0001, C=1.0,
fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None, solver=’warn’, max_iter=100,
multi_class=’warn’, verbose=0, warm_start=False, n_jobs=None)
参数说明:
penalty:可以输入"l1"或"l2"来指定使用哪一种正则化方式,不填写默认"l2"。注意,若选择"l1"正则化,参数solver仅能够使用求解方式”liblinear"和"saga“,若使用“l2”正则化,参数solver中所有的求解方式都可以使用。
C:正则化强度的倒数,必须是一个大于0的浮点数,不填写默认1.0,即默认正则项与损失函数的比值是1:1。C越小,损失函数会越小,模型对损失函数的惩罚越重,正则化的效力越强,参数会逐渐被压缩得越来越小。
当正则化强度逐渐增大(即C逐渐变小),参数的取值会逐渐变小,但L1正则化会将参数压缩为0,L2正则化只会让参数尽量小,不会取到0。
l1 = []
l2 = []
l1test = []
l2test = []
c = np.linspace(0.05,1,19)
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X3, y, test_size=0.2, random_state=2)
for i in c:
lrl1 = LogisticRegression(penalty="l1",solver="liblinear",C=i,max_iter=1000)
lrl2 = LogisticRegression(penalty="l2",solver="liblinear",C=i,max_iter=1000)
lrl1 = lrl1.fit(Xtrain,Ytrain)
l1.append(accuracy_score(lrl1.predict(Xtrain),Ytrain))
l1test.append(accuracy_score(lrl1.predict(Xtest),Ytest))
lrl2 = lrl2.fit(Xtrain,Ytrain)
l2.append(accuracy_score(lrl2.predict(Xtrain),Ytrain))
l2test.append(accuracy_score(lrl2.predict(Xtest),Ytest))
graph = [l1,l2,l1test,l2test]
color = ["green","black","lightgreen","gray"]
label = ["L1","L2","L1test","L2test"]
plt.figure(figsize=(6,6))
for i in range(len(graph)):
plt.plot(np.linspace(0.05,1,19),graph[i],color[i],label=label[i])
plt.legend(loc=4) #图例的位置在哪里?4表示,右下角
plt.show()
print("训练集使用L1正则化最高准确性:",max(l1),"其C值:",c[l1.index(max(l1))])
print("测试集使用L1正则化最高准确性:",max(l1test),"其C值:",c[l1test.index(max(l1test))])
print("训练集使用L2正则化最高准确性:",max(l2),"其C值:",c[l1.index(max(l1))])
print("测试集使用L2正则化最高准确性:",max(l2test),"其C值:",c[l2test.index(max(l2test))])
训练集使用L1正则化最高准确性: 0.7810707456978967 其C值: 0.3138888888888889
测试集使用L1正则化最高准确性: 0.8206106870229007 其C值: 0.3138888888888889
训练集使用L2正则化最高准确性: 0.7810707456978967 其C值: 0.3138888888888889
测试集使用L2正则化最高准确性: 0.8206106870229007 其C值: 0.4722222222222222根据结果,我们选择L2正则化,C=0.47来尝试训练模型。
# 将 X 和 y 分为两个部分
X_train, X_test, y_train, y_test = train_test_split(X3, y, test_size=0.2, random_state=2)
lr = LogisticRegression(penalty="l2",solver="liblinear",C=0.47,max_iter=1000)
lr.fit(X_train, y_train)
y_pred=lr.predict(X_test)
print("准确率为 %2.3f" % accuracy_score(y_test, y_pred))结果的准确率为 0.821。可见调整逻辑回归参数可以提升一定的准确率。
二、朴素贝叶斯
(一)算法概述
使用概率论进行分类的算法。
朴素贝叶斯优点:在数据较少的情况下仍然有效,可以处理多类别问题。缺点:对于输入数据的准备方式较为敏感。适用数据类型:标称型数据。
(二)实战1:使用朴素贝叶斯过滤垃圾邮件
1.收集、准备数据
import pandas as pd
df = pd.read_csv("data_spam/spam.csv", encoding='latin')
df.head()
观察数据,一列为邮件内容,一列为标签,其中,正常邮件标记为ham,垃圾邮件标记为spam。
2.分析数据
df.rename(columns={'v1':'Label', 'v2':'Text'}, inplace=True)
df['numLabel'] = df['Label'].map({'ham':0, 'spam':1})
df.head()
# 统计有多少个ham,有多少个spam
print ("# of ham : ", len(df[df.numLabel == 0]), " # of spam: ", len(df[df.numLabel == 1]))
print ("# of total samples: ", len(df))
# 统计文本的长度信息
text_lengths = [len(df.loc[i,'Text']) for i in range(len(df))]
print ("the minimum length is: ", min(text_lengths))
import numpy as np
import matplotlib.mlab as mlab
import matplotlib.pyplot as plt
plt.hist(text_lengths, 100, facecolor='blue', alpha=0.5)
plt.xlim([0,200])
plt.show()
# of ham : 4825 # of spam: 747
# of total samples: 5572正常邮件和垃圾邮件比例大概是6.5:1,不同类别的训练样例数目稍有差别,通常影响不大,但若差别很大,则会对学习过程造成困扰。例如有998 个反例,但正例只有2 个,那么学习方法只需返回一个永远将新样本预测为反例的学习器,就能达到99.8% 的精度;然而这样的学习器往往没有价值,因为它不能预测出任何正例。
3.训练、测试算法
# 导入英文呢的停用词库
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
from sklearn.feature_extraction.text import CountVectorizer
# what is stop wordS? he she the an a that this ...
stopset = set(stopwords.words("english"))
# 构建文本的向量 (基于词频的表示)
#vectorizer = CountVectorizer(stop_words=stopset,binary=True)
vectorizer = CountVectorizer()
# sparse matrix
X = vectorizer.fit_transform(df.Text)
y = df.numLabel在开始分类之前必须先将文本编码成数字。一种常用的方法是单词计数向量。在这种技术中,一个样本可以包含一段话或一篇文章,这个样本中如果出现了10个单词,就会有10个特征(n=10),每个特征代表一个单词,特征的取值表示这个单词在这个样本中总共出现了几次,是一个离散的、代表次数的正整数。在sklearn当中,单词计数向量计数可以通过feature_extraction.text模块中的CountVectorizer类实现。
MultinomialNB()多项式贝叶斯是基于原始的贝叶斯理论,但假设概率分布是服从一个简单多项式分布。多项式分布来源于统计学中的多项式实验,这种实验可以具体解释为:实验包括n次重复试验,每项试验都有不同的可能结果。在任何给定的试验中,特定结果发生的概率是不变的。多项式分布擅长的是分类型变量,虽然sklearn中的多项式分布也可以处理连续型变量,但现实中,如果我们真的想要处理连续型变量,我们应当使用高斯朴素贝叶斯。多项式实验中的实验结果都很具体,它所涉及的特征往往是次数,频率,计数,出现与否这样的概念,这些概念都是离散的正整数,因此sklearn中的多项式朴素贝叶斯不接受负值的输入。由于这样的特性,多项式朴素贝叶斯的特征矩阵经常是稀疏矩阵(不一定总是稀疏矩阵),并且它经常被用于文本分类。可以使用TF-IDF向量技术,也可以使用常见并且简单的单词计数向量手段与贝叶斯配合使用。这两种手段都属于常见的文本特征提取的方法。
参数:alpha : 浮点数, 可不填 (默认为1.0)。拉普拉斯或利德斯通平滑的参数,如果设置为0则表示完全没有平滑选项。但是需要注意的是,平滑相当于人为给概率加上一些噪音,因此设置得越大,多项式朴素贝叶斯的精确性会越低(虽然影响不是非常大),布里尔分数也会逐渐升高。
fit_prior : 布尔值, 可不填 (默认为True)。是否学习先验概率。如果设置为false,则不使用先验概率,而使用统一先验概率(uniformprior),即认为每个标签类出现的概率是。
class_prior:形似数组的结构,结构为(n_classes, ),可不填(默认为None)。类的先验概率。如果没有给出具体的先验概率则自动根据数据来进行计算。
通常在实例化多项式朴素贝叶斯的时候,会让所有的参数保持默认。
# 把数据分成训练数据和测试数据
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=100)
print ("训练数据中的样本个数: ", X_train.shape[0], "测试数据中的样本个数: ", X_test.shape[0])
# 利用朴素贝叶斯做训练
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score
clf = MultinomialNB(alpha=1.0, fit_prior=True)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print("accuracy on test data: ", accuracy_score(y_test, y_pred))
# 打印混淆矩阵
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test, y_pred, labels=[0, 1])混淆矩阵(confusion matrix)衡量的是一个分类器分类的准确程度。真阳性(True Positive,TP):样本的真实类别是正例,并且模型预测的结果也是正例。真阴性(True Negative,TN):样本的真实类别是负例,并且模型将其预测成为负例。假阳性(False Positive,FP):样本的真实类别是负例,但是模型将其预测成为正例。假阴性(False Negative,FN):样本的真实类别是正例,但是模型将其预测成为负例。
accuracy on test data: 0.97847533632287
array([[956, 14],
[ 10, 135]], dtype=int64)
(二)实战2:朴素贝叶斯实现电商网站评论情感分类
1.收集、准备、分析数据
import matplotlib.pyplot as plt
import jieba
import re
from sklearn.feature_extraction.text import TfidfVectorizer
import numpy as np首先导入需要的库,然后对训练集、测试集文本进行预处理,包括将训练集、测试集的评论文件读入,转换成字符串列表的形式进行存储,每一条评论占据一行。利用正则表达式re去除非中文字符、数字,读入外部停用词文件并去除评论中的停用词,然后对每条评论使用jieba进行分词。
print (train_comments_new[0:2], test_comments_new[0:2])['发短信 特别 不 方便 ! 背后 屏幕 很大 起来 不 舒服 UNK 手触 屏 ! 切换 屏幕 很 麻烦 !', '手感 超好 UNK 黑色 相比 白色 转得 不 容易 眼花 UNK 找 童年 记忆 UNK '] ['终于 找到 同道中人 初中 UNK 已经 喜欢 上 UNK 同学 都 鄙夷 眼光 看 UNK 人为 UNK 样子 古怪 说 " 丑 " 当场 气晕 现在 同道中人 UNK 好开心 ! UNK ! UNK ', '看 完 已 深夜 两点 UNK 却 坐在 电脑前 情难 自禁 UNK 这是 最好 结局 UNK 惟有 UNK 就让 前世 今生 纠结 停留 此刻 UNK 再 相逢 时 UNK 愿 人生 不再 人 唏嘘 UNK 身心 会 只 居 一处 UNK 痛心 人 UNK 爱 UNK ']2.训练、测试算法
TF-IDF全称term frequency-inverse document frequency,词频逆文档频率,是通过单词在文档中出现的频率来衡量其权重,也就是说,IDF的大小与一个词的常见程度成反比,这个词越常见,编码后为它设置的权重会倾向于越小,以此来压制频繁出现的一些无意义的词。在sklearn当中,我们使用feature_extraction.text中类TfidfVectorizer来执行这种编码。
# 利用tf-idf从文本中提取特征,写到数组里面.
# 参考:https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.TfidfVectorizer.html
tfidf = TfidfVectorizer()
X_train = tfidf.fit_transform(train_comments_new) # 训练数据的特征
y_train = train_labels # 训练数据的label
X_test = tfidf.transform(test_comments_new) # 测试数据的特征
y_test = test_labels# 测试数据的label
print (np.shape(X_train), np.shape(X_test), np.shape(y_train), np.shape(y_test))from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score
clf = MultinomialNB()
# 利用朴素贝叶斯做训练
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print("accuracy on test data: ", accuracy_score(y_test, y_pred))accuracy on test data: 0.6368
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier(n_neighbors=1)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print("accuracy on test data: ", accuracy_score(y_test, y_pred))accuracy on test data: 0.524
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression(solver='liblinear')
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print("accuracy on test data: ", accuracy_score(y_test, y_pred))accuracy on test data: 0.7136观察结果可知,三种不同算法分类准确性从大到小依次为:逻辑回归>朴素贝叶斯>KNN。














 966
966











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









