







前提:本例适合那些没有顺序要求的消息主题。
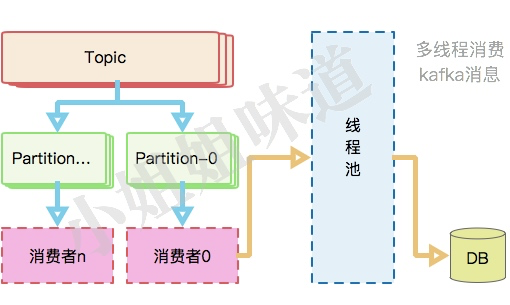
kafka通过一系列优化,写入和读取速度能够达到数万条/秒。通过增加分区数量,能够通过部署多个消费者增加并行消费能力。但还是有很多情况下,某些业务的执行速度实在是太慢,这个时候我们就要用到多线程去消费,提高应用机器的利用率,而不是一味的给kafka增加压力。
使用Spring创建一个kafka消费者是非常简单的。我们选择的方式是继承kafka的ShutdownableThread,然后实现它的doWork方法即可。
多线程消费某个分区的数据
即然是使用多线程,我们就需要新建一个线程池。
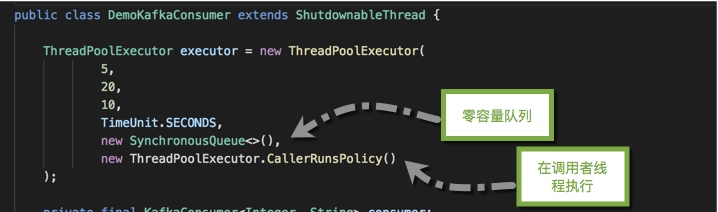
我们创建了一个最大容量为20的线程池,其中有两个参数需要注意一下。(参考《JAVA多线程使用场景和注意事项简版》)。
我们使用了了零容量的SynchronousQueue,一进一出,避免队列里缓冲数据,这样在系统异常关闭时,就能排除因为阻塞队列丢消息的可能。
然后使用了CallerRunsPolicy饱和策略,使得多线程处理不过来的时候,能够阻塞在kafka的消费线程上。
然后,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1411
1411











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









