










CNN
课程来源:深度学习与计算机视觉
卷积
全连接层的网络输入是一个一维的
而卷积神经网络输入是一个三维的
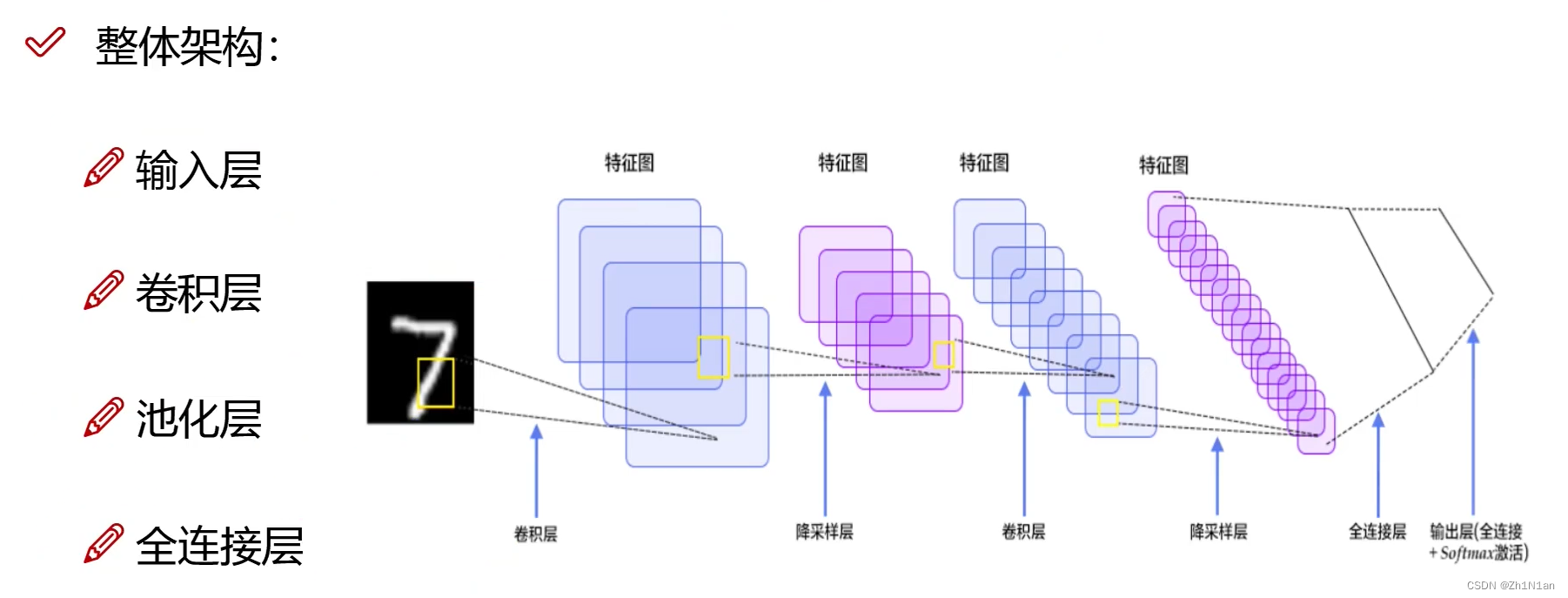
输入层

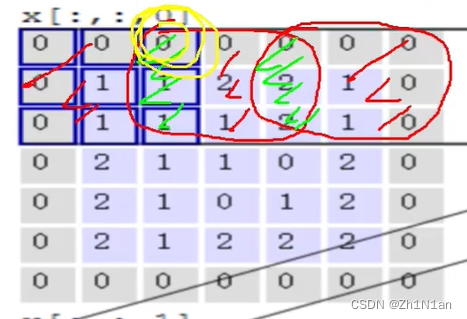
对不同的区域提取出不同的特质,也就是每个小区域可以是一群像素点(像眼睛是聚焦一小块地方去识别特征)
这一个区域就是卷积核,得到的绿色矩阵就像一个特征图!
卷积层
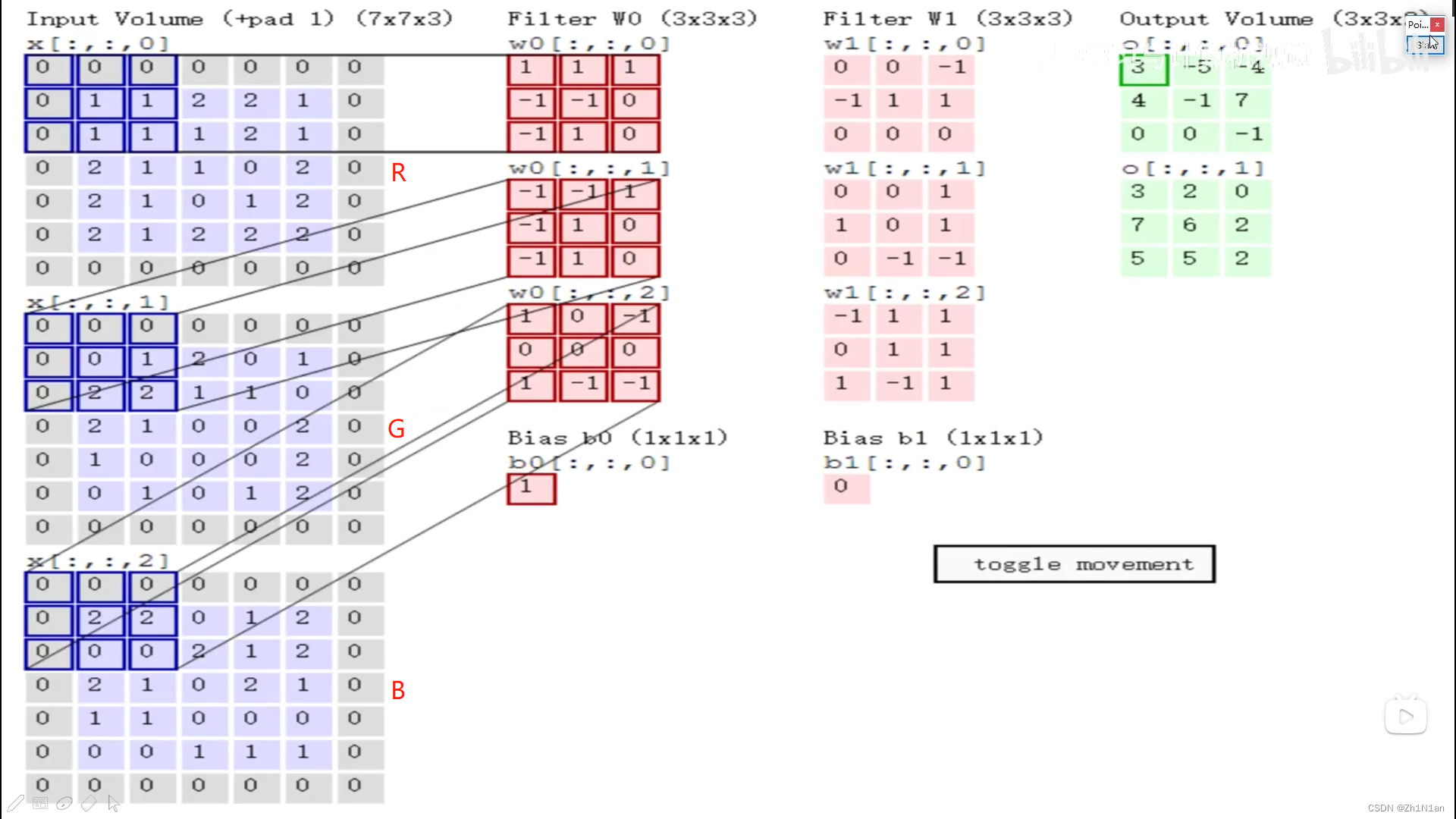
7x7x3 的最后一个3 是RGB三通道。
多个Filter(卷积核)获取不同特征。
同一个卷积层的卷积核一定是要相同的
经过几次卷积

先用六个不同的卷积核得到六个特征图,再用十个不同的卷积核得到十个特征图
卷积核的第三个值(第三维度)一定是和前面输入的第三个值(第三维度)是一样的

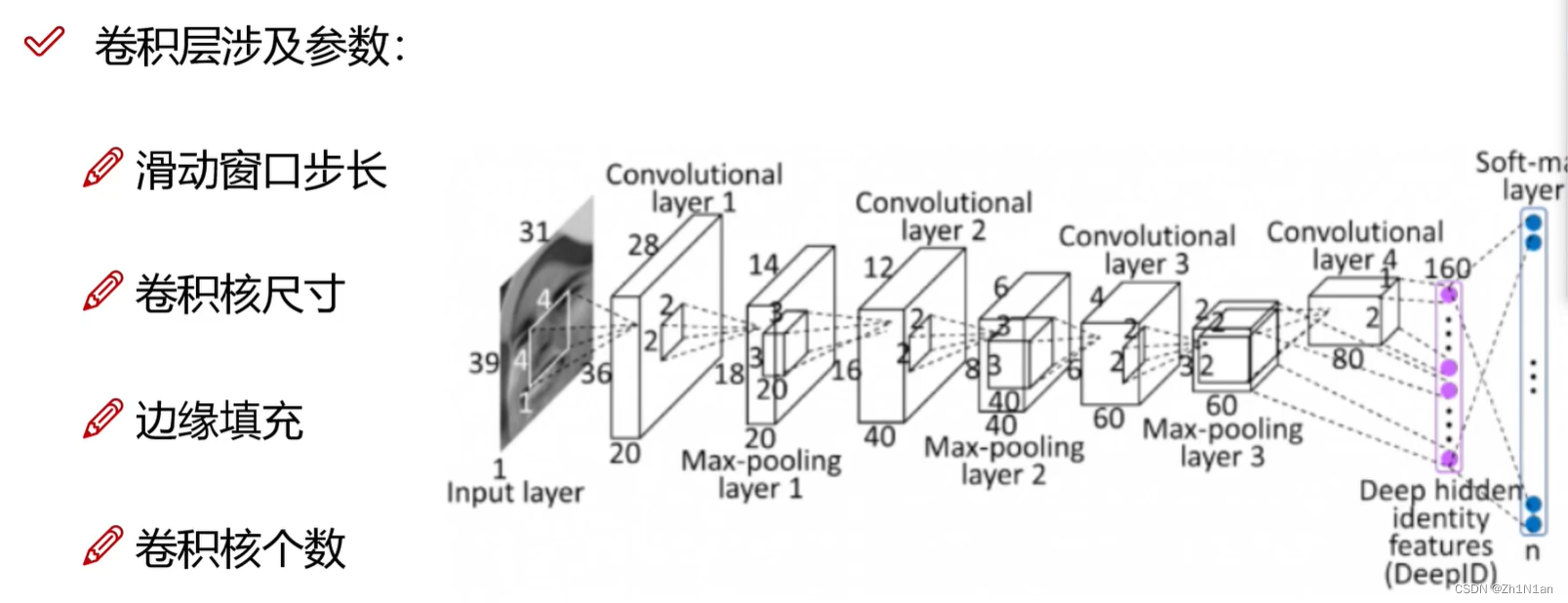
滑动窗口步长:移动大小,对结果的影响就是得到的Output Volume
当步长小,慢慢提取特征,当步长大,大刀阔斧粗略提取特征
CV用CNN一般是单步长,但是NLP有可能用大步长
NLP用CNN,可以用(类似网络滑动窗口)进行用卷积(三个词三个词或者五个字五个字提取特征)

卷积核尺寸:上述已讲
边缘填充:因为有些点对最终输出结果贡献多,而越边缘的点对最终输出结果贡献少,所以边缘填充,使得原来的边缘不再是边缘,让边缘也对之后的结果产生更大的影响
卷积核个数:上述已讲
CNN参数相对于全连接层少很多!
池化层
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YKQBNppU-1678346660088)(file:///C:/Users/fangz/Pictures/Typedown/508db33e-7ca6-4bc1-b243-d74711ae10dc.png)]](https://img-blog.csdnimg.cn/a078364ca0634ce88e16ce2ec2f13bb1.png)
池化层,做压缩,下采样的!
最大池化比平均池化好得多!
全连接层
最后一层FC:最后一个池化层的三维输出拉直成一个特征向量![外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Fn7jvL85-1678346660089)![(file:///C:/Users/fangz/Pictures/Typedown/0921a0e7-8aa3-428d-926c-a228b7cfa07e.png)]](https://img-blog.csdnimg.cn/d8bc45cf99f741e589cbeafdf856820b.png)
总结
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9MnlV25n-1678346660092)(file:///C:/Users/fangz/Pictures/Typedown/5e27eef5-ffb8-4425-ac66-b7672c609d8a.png)]](https://img-blog.csdnimg.cn/07e47ebb856e4fbd941f5b77ce997bd2.png)
经典CNN架构Alexnet
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CTcR2jZY-1678346660094)(file:///C:/Users/fangz/Pictures/Typedown/6c798c60-1d92-4646-bff9-7d3c49adb87c.png)]](https://img-blog.csdnimg.cn/80f5d67becb54a0197f7a61f85852b3e.png)
VGG
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ysU9Q9er-1678346660096)(file:///C:/Users/fangz/Pictures/Typedown/c56e9d57-4805-4983-927b-cea92f829941.png)]](https://img-blog.csdnimg.cn/6bf995a66a7f442ea2b605db68285c27.png)
所有卷积核都是3*3的,但是VGG训练时间比Alexnet长很多,以天为单位!
感受野
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eJgr1jkL-1678346660098)(file:///C:/Users/fangz/Pictures/Typedown/aac5a34a-89e2-409b-9b3f-94d8b294f16f.png)]](https://img-blog.csdnimg.cn/1fa7ee19687446e8a8bac9b6c40a746b.png)
VGG就是全用 3 ∗ 3 3*3 3∗3 的!
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LhjuC1Zz-1678346660100)(file:///C:/Users/fangz/Pictures/Typedown/4b7a912d-2986-4ff0-982f-4bd3e9a24854.png)]](https://img-blog.csdnimg.cn/da29dffc17a24a9d9377faaaea80aeec.png)
ResNet
实验中发现一个事儿:当计算机性能越来越高,理论上层数越深,效果越好。但堆叠层数越深,居然会退化!但是深度学习应该是层数越深越好嘛。
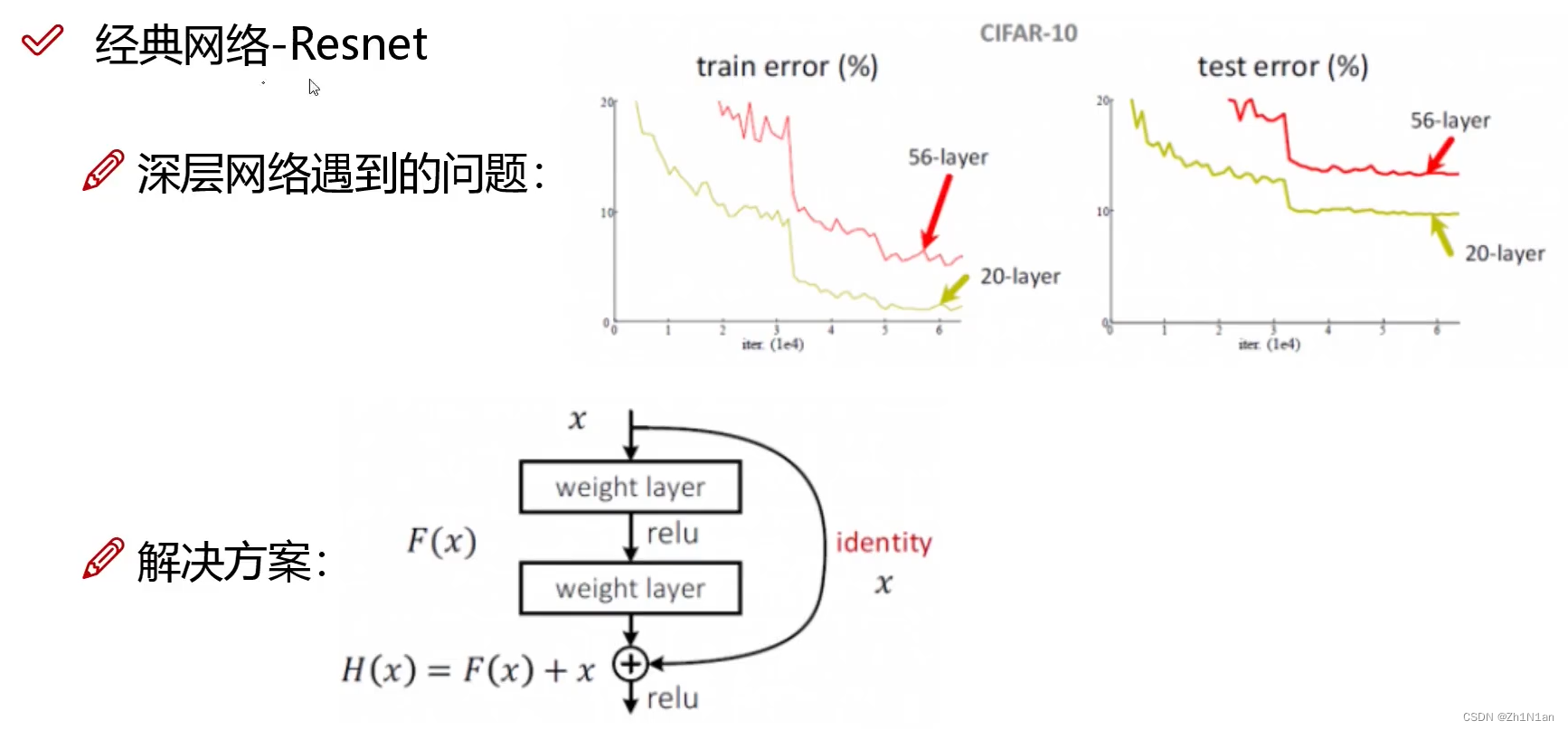
我既要把层数堆叠起来,但是不能让那些影响我模型变差的层数去影响我最终结果。
选拔那些对结果有利影响的层数。同等映射! 中间不好的层数直接跳过。
H ( x ) = F ( x ) + x H(x)=F(x)+x H(x)=F(x)+x 将 x x x 最终也直接拿下来,做一个保底,如果 F ( x ) F(x) F(x) 效果不好,那么Loss函数会将 F ( x ) F(x) F(x) 的影响优化到 0 0 0 直接同等映射!
重新盘活了深度学习!















 2616
2616











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









