







 ResNet,即深度残差网络,由何凯明于2015年提出,旨在解决深度神经网络训练中的退化问题。通过引入skip connection,ResNet实现了深层网络的高效训练,避免了梯度消失,使模型在ImageNet竞赛中获得多项冠军。
ResNet,即深度残差网络,由何凯明于2015年提出,旨在解决深度神经网络训练中的退化问题。通过引入skip connection,ResNet实现了深层网络的高效训练,避免了梯度消失,使模型在ImageNet竞赛中获得多项冠军。
简介
ResNet也就是深度残差网络,此论文《Deep Residual Learning for Image Recognition》是由何凯明大神2015年底提出的,要说它的最大特点的话,就是很深。并且一经出世,就在ImageNet中斩获图像分类、检测、定位三项的冠军。
原论文地址:https://arxiv.org/pdf/1512.03385.pdf
(-2015-)ResNet:
1、问题:
在深度神经网络训练中,从经验来看,随着网络深度的增加,模型理论上可以取得更好的结果。但是实验却发现,深度神经网络中存在着退化问题。可以看到,在下图中56层的网络比20层网络效果还要差。
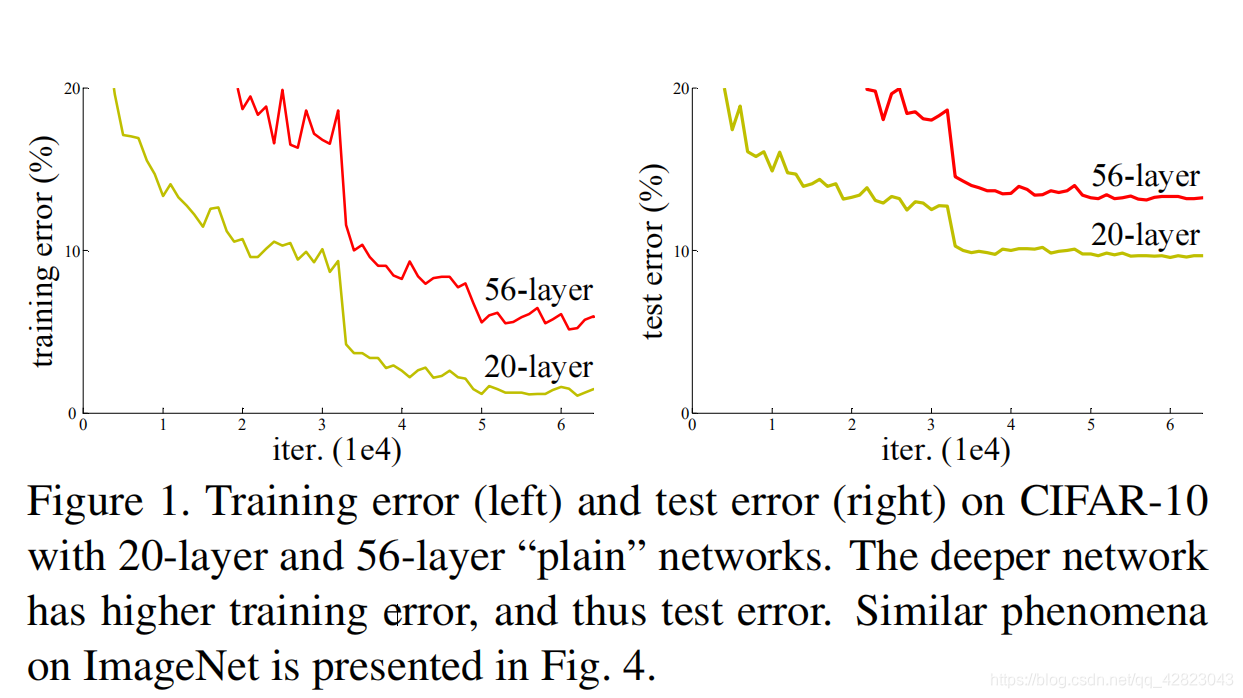
上面的现象与过拟合不同,过拟合的表现是训练误差小而测试误差大,而上面的图片显示训练误差和测试误差都是56层的网络较大。
2、ResNet思路:
我们来看看普通神经网络前向传播过程,首先x与w1相乘,得到1;1与w2相乘,得到0.1,以此类推,如下图绿色部分:
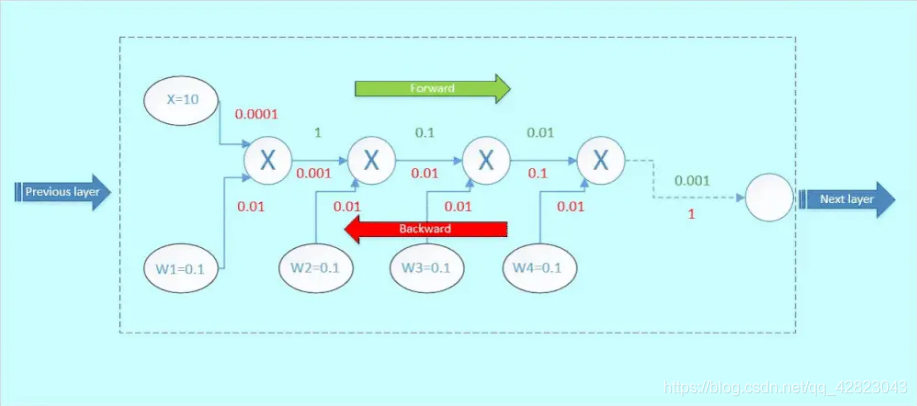
而反向传播如红色表示,假设从下一层网络传回来的梯度为1(最右边的数字)。那么这里可以看到,本来从上一层传过来的梯度为1,经过这个block之后,得到的梯度已经变成了0.0001和0.01,也就是说,梯度流过一个blcok之后,就已经下降了几个量级,传到前一层的梯度将会变得很小!
这就是梯度弥散。假如模型的层数越深,这种梯度弥散的情况就更加严重,导致浅层部分的网络权重参数得不到很好的训练,这就是为什么在Resnet出现之前,CNN网络都不超过二十几层的原因。
既然梯度经过一层层的卷积层会逐渐衰减,我们来考虑一个新的结构:
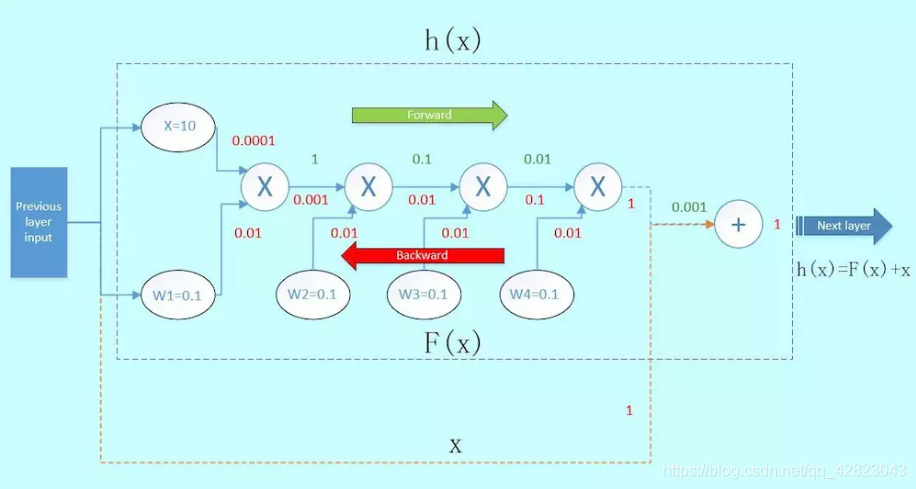
我们在这个block的旁边加了一条“捷径”(如图橙色箭头),也就是常说的“skip connection”。假设左边的上一层输入为x,虚线框的输出为f(x),上下两条路线输出的激活值相加为h(x),即h(x) = F(x) + x,得出的h(x)再输入到下一层。
当进行反向传播时,右边来自深层网络传回来的梯度为1,经过一个加法门,橙色方向的梯度为dh(x)/dF(x)=1,蓝色方向的梯度也为1。这样,经过梯度传播后,现在传到前一层的梯度就变成了[1, 0.0001, 0.01],多了一个“1”!
正是由于多了这条捷径,来自深层的梯度能直接畅通无阻地通过,去到上一层,使得浅层的网络层参数等到有效的训练!
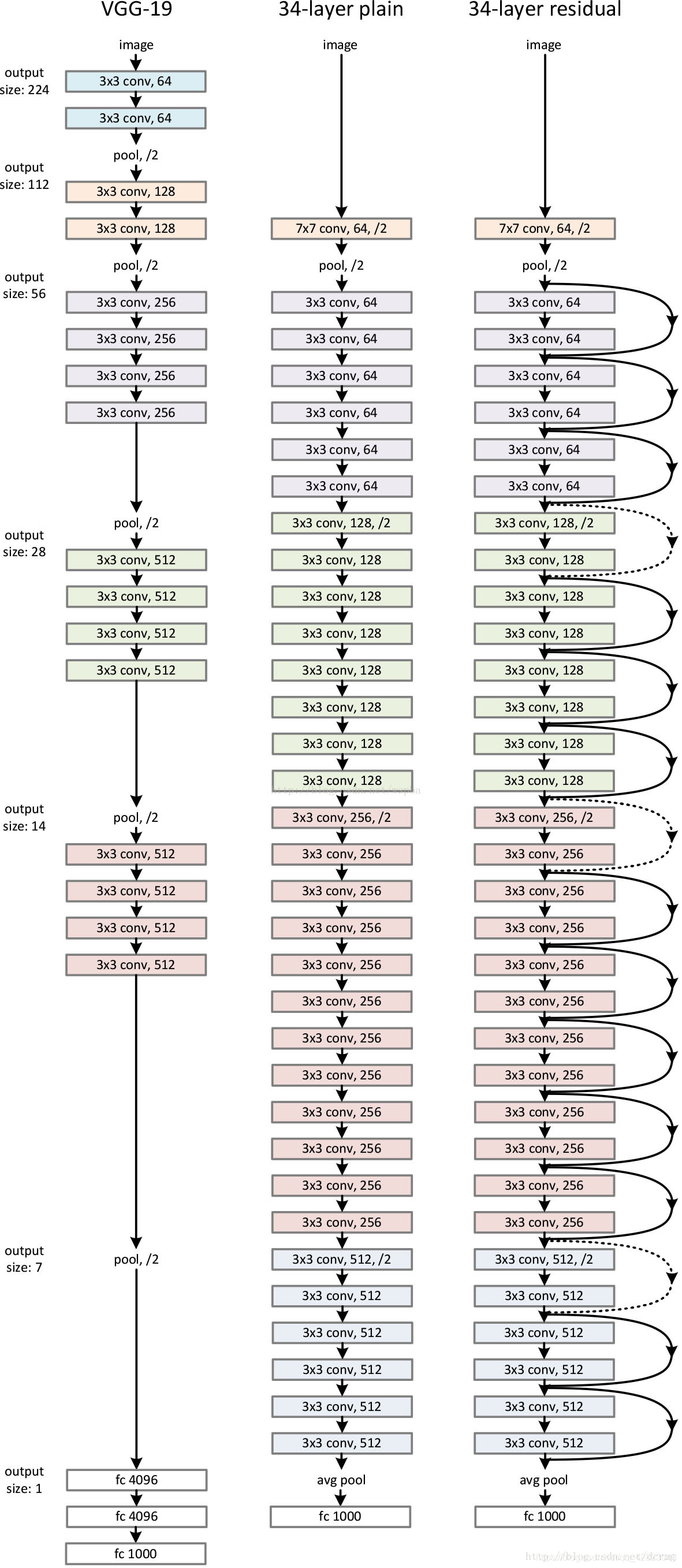
3、ResNet网络结构:
ResNet正是有了这样的Skip Connection,梯度能畅通无阻地通过各个Res blocks。
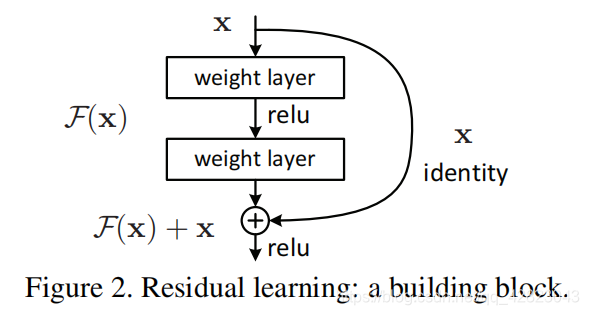
即增加一个identity mapping(恒等映射),将原始所需要学的函数H(x)转换成H(x)=F(x)+x,把当前输出直接传输给下一层网络(全部是1:1传输,不增加额外的参数),相当于走了一个捷径,跳过了本层运算,同时在反向传播过程中,也是将下一层网络的梯度直接传递给上一层网络,这样就解决了深层网络的梯度消失问题。
这一想法也是源于图像处理中的残差向量编码,通过一个reformulation,将一个问题分解成多个尺度直接的残差问题,能够很好的起到优化训练的效果。
这个Residual block通过shortcut connection实现,通过shortcut将这个block的输入和输出进行一个element-wise的加叠,这个简单的加法并不会给网络增加额外的参数和计算量,同时却可以大大增加模型的训练速度、提高训练效果。
接下来,作者就设计实验来证明自己的观点。
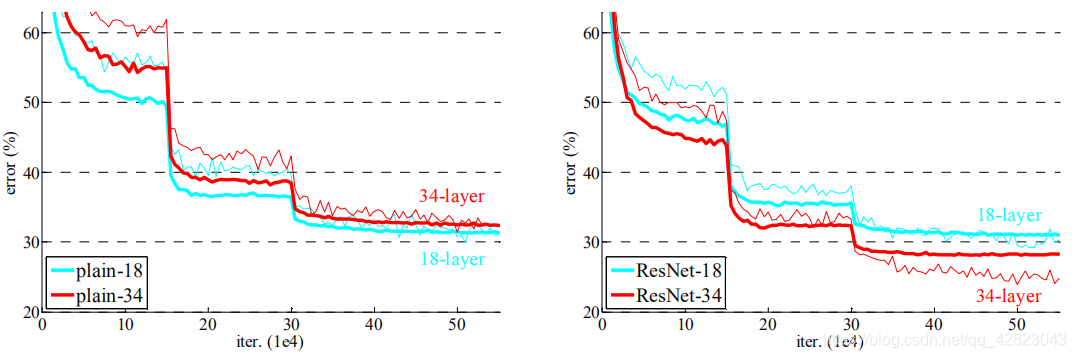
模型构建好后进行实验,在plain上观测到明显的退化现象,而且ResNet上不仅没有退化,34层网络的效果反而比18层的更好,而且不仅如此,ResNet的收敛速度比plain的要快得多。
对于shortcut的方式,作者提出了三个选项:
A. 使用恒等映射,如果residual block的输入输出维度不一致,对增加的维度用0来填充;
B. 在block输入输出维度一致时使用恒等映射,不一致时使用线性投影以保证维度一致;
C. 对于所有的block均使用线性投影。
对这三个选项都进行了实验,发现虽然C的效果好于B的效果好于A的效果,但是差距很小,因此线性投影并不是必需的,而使用0填充时,可以保证模型的复杂度最低,这对于更深的网络是更加有利的。
4、bottleneck结构:
进一步实验,作者又提出了deeper的residual block:
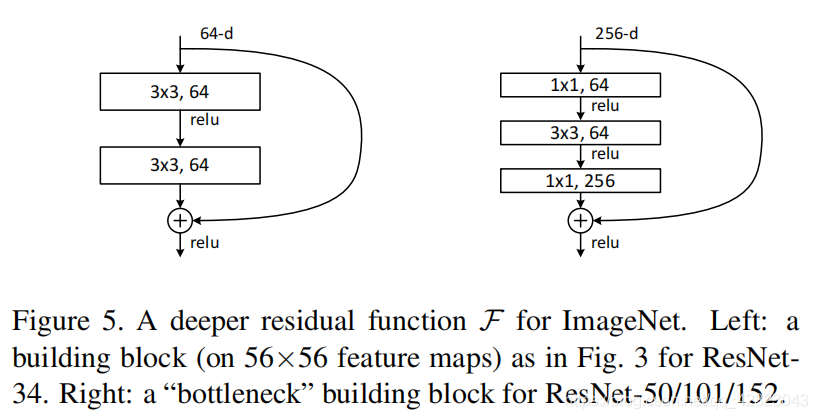
bottleneck结构先通过一个1x1的卷积减少通道数,使得中间卷积的通道数减少为1/4;中间的普通卷积做完卷积后输出通道数等于输入通道数;第三个卷积用于增加(恢复)通道数,使得bottleneck的输出通道数等于输入通道数。这两个1x1卷积有效的减少了卷积的参数个数和计算量。
ps:
使用bottleneck前:3x3x256x256+3x3x256x256=1179648
使用bottleneck后:1x1x256x64+3x3x64x64+1x1x64x256=69632
不同数量的building block和bottleneck组成了不同的ResNet。常用的由ResNet-50和ResNet-101。
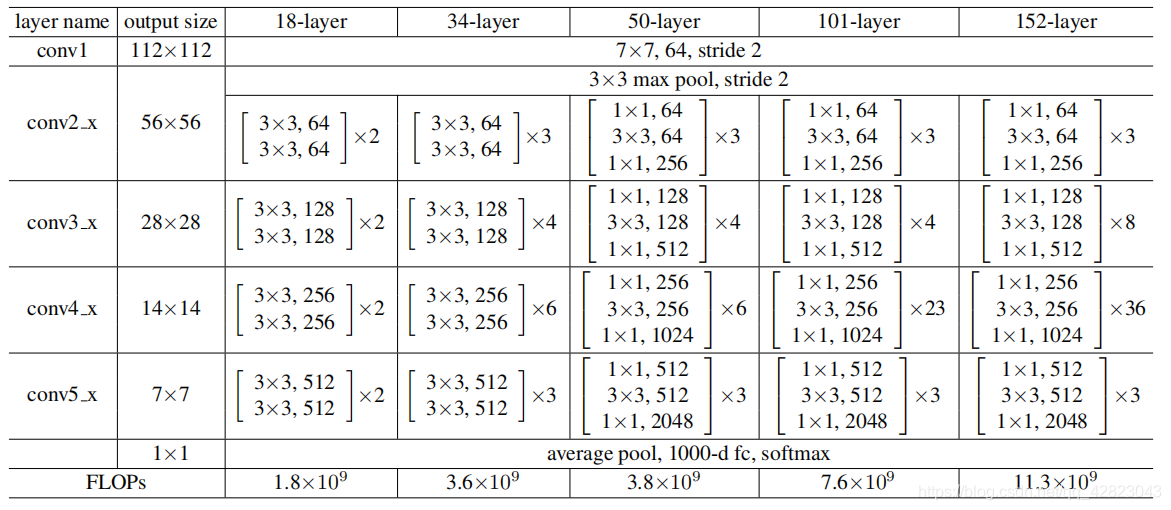
5、ResNets的特点:
- 残差网络在模型表征方面并不存在直接的优势,ResNets并不能更好的表征某一方面的特征,但是ResNets允许逐层深入地表征更多的模型。
- 残差网络使得前馈式/反向传播算法非常顺利进行,在极大程度上,残差网络使得优化较深层模型更为简单
- “shortcut”快捷连接添加既不产生额外的参数,也不会增加计算的复杂度。快捷连接简单的执行身份映射,并将它们的输出添加到叠加层的输出。通过反向传播的SGD,整个网络仍然可以被训练成终端到端的形式。
关于残差块的理解参考 https://www.jianshu.com/p/3d79e722ee56 讲的很直观。
系列传送门:
CNN发展简史——LeNet(一)
CNN发展简史——AlexNet(二)
CNN发展简史——VGG(三)
CNN发展简史——GoogLeNet(四)
CNN发展简史——DenseNet(六)

















 3106
3106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









