









文章目录
import numpy as np
import pandas as pd
from collections import defaultdict
import datatable as dt
import lightgbm as lgb
from matplotlib import pyplot as plt
import riiideducation#官方的结构,用于获取测试集
import torch#用于后面判断gpu是否可用
# `Error handling, ignore all`
np.seterr(divide = 'ignore', invalid = 'ignore')
一、defaultdict
1.认识defaultdict:
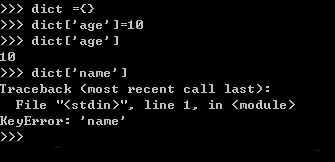
当我使用普通的字典时,用法一般是dict={},添加元素的只需要dict[element] =value即,调用的时候也是如此,dict[element] = xxx,但前提是element字典里,如果不在字典里就会报错,如:
这时defaultdict就能排上用场了,defaultdict的作用是在于,当字典里的key不存在但被查找时,返回的不是keyError而是一个默认值
2.如何使用defaultdict:
defaultdict接受一个工厂函数作为参数,如下来构造:
dict =defaultdict( factory_function)
这个factory_function可以是list、set、str等等,作用是当key不存在时,返回的是工厂函数的默认值,比如list对应[ ],str对应的是空字符串,set对应set( ),int对应0,如下举例:
from collections import defaultdict
dict1 = defaultdict(int)
dict2 = defaultdict(set)
dict3 = defaultdict(str)
dict4 = defaultdict(list)
dict1[2] ='two'
print(dict1[1])
print(dict2[1])
print(dict3[1])
print(dict4[1])
输出:
0 #int
set()#set
#str
[]#list
二、datatable包
工具包 datatable 的功能特征与 Pandas 非常类似,但更侧重于速度以及对大数据的支持。此外,datatable 还致力于实现更好的用户体验,提供有用的错误提示消息和强大的 API 功能。专注于大数据支持、高性能内存/内存不足的数据集以及多线程算法等问题

1.datatable使用
首先将数据加载到 Frame 对象中,datatable 的基本分析单位是 Frame,这与Pandas DataFrame 或 SQL table 的概念是相同的:即数据以行和列的二维数组排列展示。
datatable读取
%%time
datatable_df = dt.fread("data.csv")
__________________________________________________________
CPU times: user 30 s, sys: 3.39 s, total: 33.4 s
Wall time: 23.6 s
如上图,fread() 是一个强大又快速的函数,能够自动检测并解析文本文件中大多数的参数,所支持的文件格式包括 .zip 文件、URL 数据,Excel 文件等等。此外,datatable 解析器具有如下几大功能:
- 能够自动检测分隔符,标题,列类型,引用规则等。
- 能够读取多种文件的数据,包括文件,URL,shell,原始文本,档案和 glob 等。
- 提供多线程文件读取功能,以获得最大的速度。
- 在读取大文件时包含进度指示器。
- 可以读取 RFC4180 兼容和不兼容的文件。
pandas 读取
下面,使用 Pandas 包来读取相同的一批数据,并查看程序所运行的时间。
%%time
pandas_df= pd.read_csv("data.csv")
___________________________________________________________
CPU times: user 47.5 s, sys: 12.1 s, total: 59.6 s
Wall time: 1min 4s
由上图可以看到,结果表明在读取大型数据时 datatable 包的性能明显优于 Pandas,Pandas 需要一分多钟时间来读取这些数据,而 datatable 只需要二十多秒。
2.数据转换
对于当前存在的帧,可以将其转换为一个 Numpy 或 Pandas dataframe 的形式,如下所示:
numpy_df = datatable_df.to_numpy()
pandas_df = datatable_df.to_pandas()
三、特征构造
1.函数
1.reset_index
函数作用:重置索引或其level。重置数据帧的索引,并使用默认索引。如果数据帧具有多重索引,则此方法可以删除一个或多个level。
函数主要有以下几个参数:
reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill='')
各个参数介绍:
**level:**可以是int, str, tuple, or list, default None等类型。作用是只从索引中删除给定级别。默认情况下删除所有级别。
**drop:**bool, default False。不要尝试在数据帧列中插入索引。这会将索引重置为默认的整数索引。
**inplace:**bool, default False。修改数据帧(不要创建新对象)。
**col_level:**int or str, default=0。如果列有多个级别,则确定将标签插入到哪个级别。默认情况下,它将插入到第一层。
**col_fill:**object, default。如果列有多个级别,则确定其他级别的命名方式。如果没有,则复制索引名称。
返回:
DataFrame or None。具有新索引的数据帧,如果inplace=True,则无索引。
2.shif()函数
该函数主要的功能就是使数据框中的数据移动
shift(self, periods=1, freq=None, axis=0)
参数详解:
- period:表示移动的幅度,可以是正数,也可以是负数,默认值是1,1就表示移动一次,注意这里移动的都是数据,而索引是不移动的,移动之后没有对应值的,就赋值为NaN。
- freq: DateOffset, timedelta, or time rule string,可选参数,默认值为None,只适用于时间序列,如果这个参数存在,那么会按照参数值移动时间索引,而数据值没有发生变化。
- axis: {0, 1, ‘index’, ‘columns’},表示移动的方向,如果是0或者’index’表示上下移动,如果是1或者’columns’,则会左右移动。
假设存在一个DataFrame数据df:
index value1
`A ``0`
`B ``1`
`C ``2`
`D ``3
如果执行以下代码 df.shift() 就会变成如下:
index value1
`A NaN`
`B ``0`
`C ``1`
`D ``2
注意,shift移动的是整个数据,如果df有如下多列数据,当然也可以只对某一列进行移动,比如:
train_df['lag'] = train_df.groupby('user_id')[target].shift()
3.map函数
# 用户回答问题正确的比例,数目和次数 sum是回答正确的次数,count是回答的xx题目的总次数
user_agg = train_df.groupby('user_id')[target].agg(['sum', 'count'])
#每个content出现的次数和被回答正确的比例
content_agg = train_df.groupby('content_id')[target].agg(['sum', 'count'])
train_df['Accuracy_sum'] = train_df['user_id'].map(user_agg['sum'])#每个用户回答问题对的总数
train_df['Questions_num'] = train_df['user_id'].map(user_agg['count'])#每个用户回答问题的总数
4.tail函数
与head()函数类似,默认是取dataframe中的最后五行。
在这个比赛中,由于数据量过大,大概有1亿的数据,用户数量是40w左右,所以每个用户的数据也是比较多的,考虑到内存的问题,可以取每个用户的后多少次数据,当然这是会带来误差的。
train_df = train_df.groupby('user_id').tail(500).reset_index(drop = True)
函数源码:
1 def tail(self, n=5):
2 """
3 Returns last n rows
4 """
5 if n == 0:
6 return self.iloc[0:0]
7 return self.iloc[-n:]
5.groupby函数
该函数使用的频率很高很高,所以大家一定一定要认真学习!
groupby()的常见用法:

这是由于变量grouped是一个GroupBy对象,它实际上还没有进行任何计算,只是含有一些有关分组键df[‘key1’]的中间数据而已,然后我们可以调用配合函数(如:.mean()方法)来计算分组平均值等。` 因此,一般为方便起见可直接在聚合之后+“配合函数”,默认情况下,所有数值列都将会被聚合,虽然有时可能会被过滤为一个子集。 一般,如果对df直接聚合时, df.groupby([df[‘key1’],df[‘key2’]]).mean()(分组键为:Series)与df.groupby([‘key1’,‘key2’]).mean()(分组键为:列名)是等价的,输出结果相同。 但是,如果对df的指定列进行聚合时, df[‘data1’].groupby(df[‘key1’]).mean()(分组键为:Series),唯一方式。 此时,直接使用“列名”作分组键,提示“Error Key”。 注意:`分组键中的任何缺失值都会被排除在结果之外。
groupby()的配合函数:

(1)根据key1键对data1列数据聚合
df.groupby('key1')['data1'].mean()
#或者
df['data1'].groupby(df['key1']).mean()
(2)当对多列数据如data1和data2根据某个键入key1聚合分组时,组引入列表['data1','data2'],此处对data2外加中括号是一个意思,只是影响输出格式。
根据key1键对data1和data2列数据聚合
df.groupby('key1')[['data1','data2']].mean()
#或者
df[['data1','data2']].groupby(df['key1']).mean()
(3)根据多个键key1、key2对data2列数据聚合
df.groupby(['key1','key2'])['data2'].mean()
#或者
df['data2'].groupby([df['key1'],df['key2']]).mean()
2.特征构造
1.特征
features =['timestamp','lagtime','lagtime_mean','Accuracy_sum','Questions_num','prior_question_elapsed_time',
'prior_question_had_explanation', 'user_correctness', 'prior_question_elapsed_time_mean',
'part', 'content_count','content_id','explanation_mean','explanation_cumsum']
一共使用了14个特征,其中timestamp、prior_question_elapsed_time、prior_question_had_explanation、part和content_id是本身就存在的特征,其余的9个特征都是自己构造的。
2.特征含义
- timestamp:此用户交互与该用户完成第一个事件之间的时间(毫秒)。
- lagtime:两件事完成时间的差值,比如第一件事10s完成,第二件事12s完成,两者之间的lagtime=2s。
- lagtime_mean:两件事之间时间的平均值
- Accutacy_sum:每个用户回答问题对的总数
- Questions_num:每个用户回答问题的总数
- user_correctness:学习进步的增长率,回答问题正确增加的比例
- prior_question_elapsed_time:(如果上一个bundle有很多question,那么这个时间是这么多个题目的平均时间,如果是第一个题目,则没有这个时间)用户回答前一个问题包中的每个问题所花费的平均时间(以毫秒为单位)
- prior_question_had_explanation:用户是否看到上一个问题的答案,第一个题目为null。通常前几个都为false,因为那是测试。
- prior_question_elapsed_time_mean:用户回答所有问题的平均时间
- part: 题目所属部分(托业考试分为听力(4个)和阅读(3个),细分总共有7个部分)
- content_id:内容的id,对应 lecture_id和question_id,后来被转化为某讲座被回答正确的比例
- content_count:某讲座被回答的次数
- explanation_mean:每个用户看上一题答案的平均率,比如一共用10个题,有7个题看了答案,那就是7/10.
- explanation_cumsum:每个用户看上一题的答案个数
3.特征构造
lagtime
train_df['lagtime'] = train_df.groupby('user_id')['timestamp'].shift()#下移一次
train_df['lagtime']=train_df['timestamp']-train_df['lagtime']#此用户交互与该用户完成第一个事件之间的时间(毫秒)。
train_df['lagtime'].fillna(0, inplace=True)#用0填充空值
train_df.lagtime=train_df.lagtime.astype('int32')#数据格式转换
lagtime_mean
lagtime_agg = train_df.groupby('user_id')['lagtime'].agg(['mean'])#完成每一题的平均时间
train_df['lagtime_mean'] = train_df['user_id'].map(lagtime_agg['mean'])#map映射
train_df.lagtime_mean=train_df.lagtime_mean.astype('int32')#转换数据格式
Accutacy_sum和Questions_num
user_agg = train_df.groupby('user_id')[target].agg(['sum', 'count'])
train_df['Accuracy_sum'] = train_df['user_id'].map(user_agg['sum'])#每个用户回答问题对的总数
train_df['Questions_num'] = train_df['user_id'].map(user_agg['count'])#每个用户回答问题的总数
user_correctness
cum = train_df.groupby('user_id')['lag'].agg(['cumsum', 'cumcount']) # 列方向上求累积和 和累计个数
train_df['user_correctness'] = cum['cumsum'] / cum['cumcount']#学习进步的增长率
train_df.drop(columns = ['lag'], inplace = True)
prior_question_elapsed_time_mean
prior_question_elapsed_time_mean = train_df.prior_question_elapsed_time.dropna().values.mean()
train_df['prior_question_elapsed_time_mean'] = train_df.prior_question_elapsed_time.fillna(prior_question_elapsed_time_mean)
content_id和content_count
train_df['content_count'] = train_df['content_id'].map(content_agg['count']).astype('int32')#某讲座被回答的次数
train_df['content_id'] = train_df['content_id'].map(content_agg['sum'] / content_agg['count'])#某讲座被回答正确的比例
explanation_mean和explanation_cumsum
#train_df['lag'] = train_df.groupby('user_id')['prior_question_had_explanation'].shift()#用户是否看到上一个问题的答案,第一个题目为null。通常前几个都为false,因为那是测试。
cum = train_df.groupby('user_id')['lag'].agg(['cumsum', 'cumcount'])#看上一题解释的总数和列数
train_df['explanation_mean'] = cum['cumsum'] / cum['cumcount']#解释的平均
train_df['explanation_cumsum'] = cum['cumsum']
train_df.drop(columns=['lag'], inplace=True)
train_df['explanation_mean'].fillna(0, inplace=True)
train_df['explanation_cumsum'].fillna(0, inplace=True)
train_df.explanation_mean=train_df.explanation_mean.astype('float16')
train_df.explanation_cumsum=train_df.explanation_cumsum.astype('int16')
四、模型训练
1.参数
features = [ 'timestamp','lagtime','lagtime_mean','Accuracy_sum','Questions_num','prior_question_elapsed_time',
'prior_question_had_explanation', 'user_correctness', 'prior_question_elapsed_time_mean',
'part', 'content_count','content_id','explanation_mean','explanation_cumsum']
params = {
'loss_function': 'Logloss',
'eval_metric': 'AUC',
'task_type': 'GPU' if torch.cuda.is_available() else 'CPU',#使用gpu更快
'grow_policy': 'Lossguide',
'iterations': 5000,
'learning_rate': 4e-2,
'random_seed': 0,
'l2_leaf_reg': 1e-1,
'depth': 15,
'max_leaves': 10,
'border_count': 128,
'verbose': 50,
}
2.导入模型并加载数据
from catboost import CatBoostClassifier, Pool
# Training and validating data
train_set = Pool(train_df[features], label = train_df[target])
val_set = Pool(valid_df[features], label = valid_df[target])
Pool:https://catboost.ai/docs/concepts/python-reference_pool.html
3.模型训练
# Model definition
model = CatBoostClassifier(**params)
# Fitting
model.fit(train_set, eval_set = val_set, use_best_model = True)
五、得分与总结
1.得分
这个最终的public得分是0.762,private得分是0.763.(这个排行榜是用大约20%的测试数据计算出来的。最终结果将以其他80%为基础,因此最终排名可能会有所不同。)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ww1LxYIm-1610084691497)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20210108123500621.png)]](https://img-blog.csdnimg.cn/20210108135325345.png)
2.总结
第一次参加kaggle的正式赛,从12月13号开始参加比赛,从了解题目背景到看懂真正做什么,如何写推断花了三天左右的时间,然后才正式开始打比赛。
这个kaggle 的比赛不像国内的,国内的你直接提交结果文件,kaggle需要你提交代码文件,而且你事先看不到测试集,通过一个接口获得测试集,所以对于特征构造与特征增加这块有些头疼,而且这个比赛的性质更是加大了写推断的难度,有的时候给训练集增加特征很容易,但是往测试集加的时候不注意可能就会出错。
在这次比赛中认识了很多的朋友,有来自北京工作的强哥,比赛中也询问了他很多东西,当时提分提不上的时候,一度想放弃,后来强哥拿出来自己天池首次参数的季军奖激励了我,坚持到最后就会有好的收获,感谢强哥,后面的比赛希望多多合作。其次,感谢来自中科大苏州研究院的川弟,互相分享强特,解决bug,一起夜间上分,实属不易,希望后面的比赛有机会在一起合作一波。
虽然最后我们都只是获得了铜牌,此次kaggle的比赛收获不少,传统机器学习中的集成学习和深度学习的融合效果实在是惊人,权重比例的划分等,都有所收获,下一步,好好的研究一下前排大佬开源机器学习lgb的特征和深度学习代码sakt、saint!
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mMY1o6O7-1610084691498)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20210108125207699.png)]](https://img-blog.csdnimg.cn/20210108135400340.png)















 1443
1443











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









