







首先两个程序,证明cacheLine的存在。
public class ThreadTest {
static volatile long[] arr = new long[2];
public ThreadTest() {
}
public static void main(String[] args) throws InterruptedException {
Thread thread1 = new Thread(() -> {
for(long i = 0L; i < 100000000L; arr[0] = i++) {
}
});
Thread thread2 = new Thread(() -> {
for(long i = 0L; i < 100000000L; arr[1] = i++) {
}
});
long start = System.nanoTime();
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println(System.nanoTime() - start);
}
}
public class ThreadTest_1 {
static volatile long[] arr = new long[16];
public ThreadTest_1() {
}
public static void main(String[] args) throws InterruptedException {
Thread thread1 = new Thread(() -> {
for(long i = 0L; i < 100000000L; arr[0] = i++) {
}
});
Thread thread2 = new Thread(() -> {
for(long i = 0L; i < 100000000L; arr[8] = i++) {
}
});
long start = System.nanoTime();
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println(System.nanoTime() - start);
}
}
程序1,打印出的时间为
2278531100/ns
2330328000/ns
测试了五次,取出其中两次测试结果,不同的机器线程执行的时间肯定不一致,以自己机器为例。
程序2,打印出的时间为
556254500
344490100
显而易见,程序二的执行效率会比一的执行效率高很多,因为Intel的cpu的缓存行大小为64字节,程序二采用long数组,将两个值进行隔离,保证不再统一缓存行。
因为定义static变量的时候使用volatile,需要保证公共资源的可见性,程序1相对于程序二,每次在对变量在进行修改的时候根据缓存一致性协议(MESI),每次cpu在进行计算的时候都需要去主存中同步最新数据,所以时间耗时多。
扩展:对于缓存一致性协议,正常情况下,通过缓存锁实现一致性,对于无法缓存的数据或者是数据量过大的数据(缓存行一次无法全部加载),采用锁总线的方式保持一致性。
jdk1.7版本,其中一些源码,也是采用消除伪共享的代码方式,在jdk1.8中提供一个注解@Contended,对于高并发访问的常量,可以使用这个注解来保证变量不会跟其他变量加载在同一缓存行中,如果想要使用这个注解,需要添加JVM启动参数:-XX:-RestrictContended,解除对@Contended。
相应的测试代码:
public class ThreadTest_02 {
@Contended
static volatile long arr1;
@Contended
static volatile long arr2;
public ThreadTest_02() {
}
public static void main(String[] args) throws InterruptedException {
Thread thread1 = new Thread(() -> {
for(long i = 0L; i < 100000000L; arr1 = i++) {
}
});
Thread thread2 = new Thread(() -> {
for(long i = 0L; i < 100000000L; arr2 = i++) {
}
});
long start = System.nanoTime();
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println(System.nanoTime() - start);
}
}
之所以jdk1.8提供这个注解,是为了在不同的电脑上(因为不是所有的cpu的缓存行都是64字节),有jvm编译成为机械码,在cpu计算的时候会始终保持变量不会跟其他并发量高的变量存于同一缓存行之内,更好的跨平台。
可以比较添加注解和注释注解两次的执行时间:
933722100(添加)
2569085400(注释)
最后在说明一下缓存行:
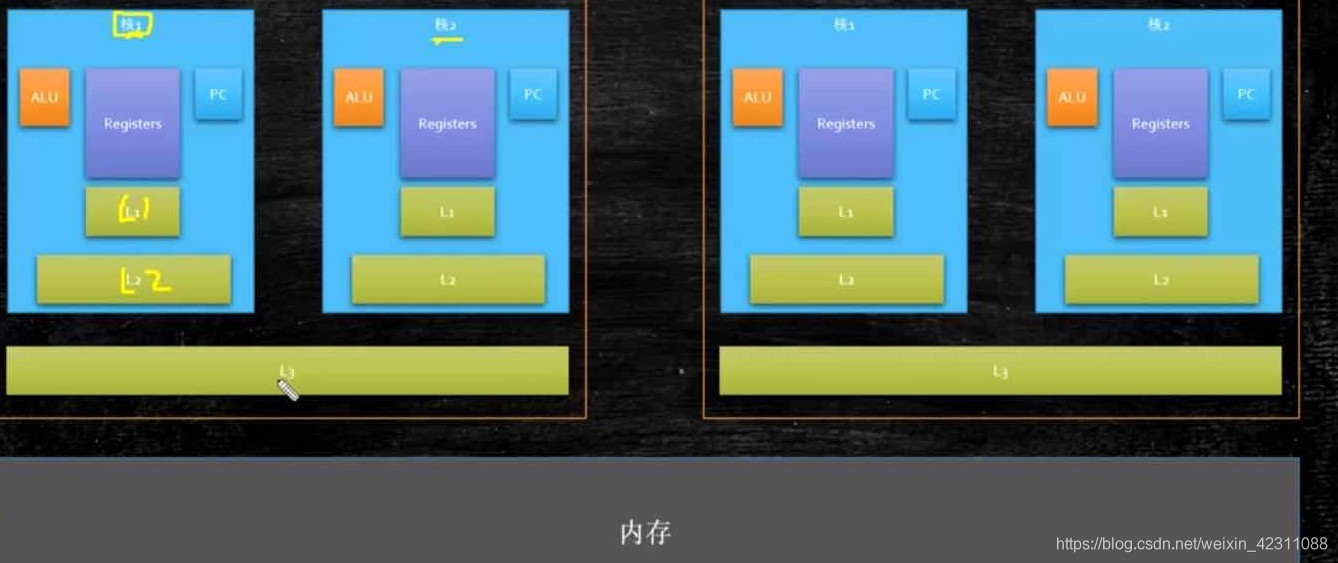
因为cpu的Registers处理速度为主存的100倍,对于想要处理的数据,不可能单次自读取这一个数字,为了使CPU的使用效率更可能高,和程序的局部性原理,cpu会将相邻的代码也会读取到内存中,interl的cpu是64字节。这就是所谓的缓存行。
cpu的缓存级别:l1,l2,l3;
个人感觉这个知识点可能会在面试的时候问的比较多,在正常业务逻辑中我们很少会使用@Contended,目前我的项目代码中是没有使用这个优化的,可能是并发并不是很高。如果本篇文章对大家有所帮助,关注一波,点赞一下,以后会将学习的内容,有意思的内容,卸载博客中,并且项目中遇到难搞的点也会卸载博客中,算是三省吾身。















 2410
2410











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









