








文章目录
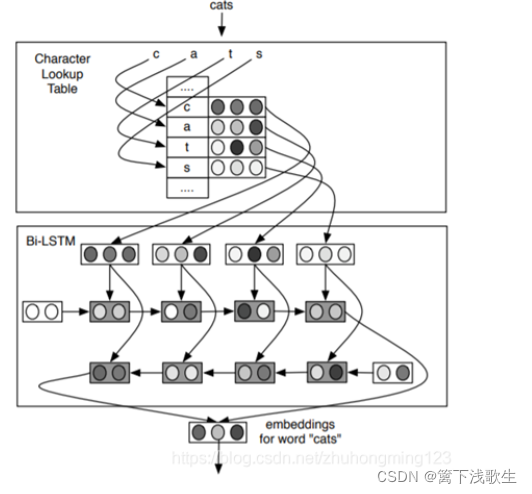
C2W模型-语言模型(双向LSTM)
一、文件目录
二、语料库(wiki_00)

三、创建训练,测试,验证集
import json
import nltk
#导入数据
datas = open("./wiki_00",encoding="utf-8").read().splitlines()
#创建训练,测试,验证集
f_train = open("train.txt","w",encoding="utf-8")
f_valid = open("valid.txt","w",encoding="utf-8")
f_test = open("test.txt","w",encoding="utf-8")
num_words = 0
for data in datas:
data = json.loads(data,strict=False) #转成json
sentences = data["text"] #提取出句子内容
sentences = sentences.replace("\n\n",".")
sentences = sentences.replace("\n",".")
sentences = nltk.sent_tokenize((sentences)) #提取句子
for sentence in sentences:
sentence = nltk.word_tokenize(sentence)
if len(sentence)<10 or len(sentence)>100:
continue
num_words = num_words +len(sentence)
sentence =" ".join(sentence)+"\n"
if num_words <=1000000:
f_train.write(sentence)
elif num_words <= 1020000:
f_valid.write(sentence)
elif num_words <=1040000:
f_test.write(sentence)
else:
exit()
四、构建word2id,char2id,特征,标签
# 加载训练集
import os.path
import pickle
import numpy as np
from collections import Counter
from torch.utils import data
class Char_LM_Dataset(data.DataLoader):
def __init__(self,mode="train",max_word_length=16,max_sentence_length=100):
self.path = os.path.abspath('.')
self.mode = mode
self.max_word_length = max_word_length
self.max_sentence_length = max_sentence_length
datas = self.read_file()
datas, char_datas, weights = self.generate_data_label(datas)
self.datas = datas.reshape([-1]) #(3592800,)
self.char_datas = char_datas.reshape([-1, self.max_word_length])#(3592800, 16)
self.weights = weights#(3592800,)
print(self.datas.shape, self.char_datas.shape, weights.shape)
def __getitem__(self, index):
return self.char_datas[index], self.datas[index],self.weights[index]
def __len__(self):
return len(self.datas)
def read_file(self):
if self.mode == "train":
datas = open(self.path+"/train.txt",encoding="utf-8").read().strip("\n").splitlines()
datas = [s.split() for s in datas]
# 构建word2id,char2id
if not os.path.exists(self.path+"/word2id"):
words = []
chars = []
for data in datas:
for word in data:
words.append(word.lower())
chars.extend(word)
# 5000个词计算出现次数,509个字母计算出现次数
words = dict(Counter(words).most_common(5000 - 2))
chars = dict(Counter(chars).most_common(512 - 3))
word2id = {"<pad>": 0, "<unk>": 1}
for word in words:
word2id[word] = len(word2id)
char2id = {"<pad>": 0, "<unk>": 1, "<start>": 2}
for char in chars:
char2id[char] = len(char2id)
self.word2id = word2id
self.char2id = char2id
pickle.dump(self.word2id,open(self.path+"/word2id","wb"))
pickle.dump(self.char2id,open(self.path+"/char2id","wb"))
else:
self.word2id = pickle.load(open(self.path+"/word2id","rb"))
self.char2id = pickle.load(open(self.path+"/char2id","rb"))
return datas
elif self.mode == "valid":
datas = open(self.path + "/valid.txt", encoding="utf-8").read().strip("\n").splitlines()
datas = [s.split() for s in datas]
self.word2id = pickle.load(open(self.path + "/word2id", "rb"))
self.char2id = pickle.load(open(self.path + "/char2id", "rb"))
return datas
elif self.mode == "test":
datas = open(self.path + "/test.txt", encoding="utf-8").read().strip("\n").splitlines()
datas = [s.split() for s in datas]
self.word2id = pickle.load(open(self.path + "/word2id", "rb"))
self.char2id = pickle.load(open(self.path + "/char2id", "rb"))
return datas
def generate_data_label(self, datas):
# 构建特征和标签
char_datas = []
weights = []
for i, data in enumerate(datas):
if i % 1000 == 0:
print(i, len(datas))
char_data = [[self.char2id["<start>"]] * self.max_word_length]
for j, word in enumerate(data):
char_word = []
for char in word:
char_word.append(self.char2id.get(char, self.char2id["<unk>"])) # 将字符转化成id
char_word = char_word[0:self.max_word_length] + \
[self.char2id["<pad>"]] * (self.max_word_length - len(char_word)) # 将所有词pad成相同长度
datas[i][j] = self.word2id.get(datas[i][j].lower(), self.word2id["<unk>"]) # 将词转化为id
char_data.append(char_word)
weights.extend([1] * len(datas[i]) + [0] * (self.max_sentence_length - len(datas[i])))
datas[i] = datas[i][0:self.max_sentence_length] + [self.word2id["<pad>"]] * (self.max_sentence_length - len(datas[i])) # 将所有句子pad成相同长度
char_datas.append(char_data)
char_datas[i] = char_datas[i][0:self.max_sentence_length] + \
[[self.char2id["<pad>"]] * self.max_word_length] * (self. max_sentence_length - len(char_datas[i])) # 将所有句子pad成相同长度
datas = np.array(datas)
char_datas = np.array(char_datas)
weights = np.array(weights)
return datas, char_datas, weights
if __name__=="__main__":
char_lm_dataset = Char_LM_Dataset()
五、C2W模型构建
import torch
import torch.nn as nn
import numpy as np
class C2W(nn.Module):
def __init__(self, config):
super(C2W, self).__init__()
self.char_hidden_size = config.char_hidden_size
self.word_embed_size = config.word_embed_size
self.lm_hidden_size = config.lm_hidden_size
self.character_embedding = nn.Embedding(config.n_chars,config.char_embed_size) # 字符嵌入层,64,50
self.sentence_length = config.max_sentence_length
self.char_lstm = nn.LSTM(input_size=config.char_embed_size,hidden_size=config.char_hidden_size,
bidirectional=True,batch_first=True) # 字符lstm,50,50,
self.lm_lstm = nn.LSTM(input_size=self.word_embed_size,hidden_size=config.lm_hidden_size,batch_first=True) # 语言模型lstm.50,150
self.fc_1 = nn.Linear(2*config.char_hidden_size,config.word_embed_size) # 线性组合生成词表示
self.fc_2 =nn.Linear(config.lm_hidden_size,config.vocab_size) # 生成类别用于预测
def forward(self, x):
input = self.character_embedding(x) #[64, 16, 50]
char_lstm_result = self.char_lstm(input) #[64, 16, 100]
word_input = torch.cat([char_lstm_result[0][:,-1,0:self.char_hidden_size],
char_lstm_result[0][:,0,self.char_hidden_size:]],dim=1) #[64,100]
word_input = self.fc_1(word_input) #[64,50]
word_input = word_input.view([-1,self.sentence_length,self.word_embed_size]) #[8,8,50]
lm_lstm_result = self.lm_lstm(word_input)[0].contiguous() #[8, 8, 150]
lm_lstm_result = lm_lstm_result.view([-1,self.lm_hidden_size]) #[64, 150]
print(lm_lstm_result.shape)
out = self.fc_2(lm_lstm_result) #[64, 1000]
return out
class config:
def __init__(self):
self.n_chars = 64 # 字符的个数
self.char_embed_size = 50 # 字符嵌入大小
self.max_sentence_length = 8 # 最大句子长度
self.char_hidden_size = 50 # 字符lstm的隐藏层神经元个数
self.lm_hidden_size = 150 # 语言模型的隐藏神经元个数
self.word_embed_size = 50 # 生成的词表示大小
config.vocab_size = 1000 # 词表大小
if __name__=="__main__":
config = config()
c2w = C2W(config)
test = np.zeros([64,16])
c2w(test)
六、训练和测试
import torch
import torch.autograd as autograd
import torch.nn as nn
import torch.optim as optim
from model import C2W
from data_load import Char_LM_Dataset
from tqdm import tqdm
import config as argumentparser
config = argumentparser.ArgumentParser()
def get_test_result(data_iter,data_set):
# 生成测试结果
model.eval()
all_ppl = 0
for data, label,weights in data_iter:
if config.cuda and torch.cuda.is_available():
data = data.cuda()
label = label.cuda()
weights = weights.cuda()
else:
data = torch.autograd.Variable(data).long()
label = torch.autograd.Variable(label).squeeze()
out = model(data)
loss_now = criterion(out, autograd.Variable(label.long()))
ppl = (loss_now * weights.float()).view([-1, config.max_sentence_length])
ppl = torch.sum(ppl, dim=1) / torch.sum((weights.view([-1, config.max_sentence_length])) != 0, dim=1).float()
ppl = torch.sum(torch.exp(ppl))
all_ppl += ppl.data.item()
return all_ppl*config.max_sentence_length/data_set.__len__()
if __name__=="__main__":
# 判断是否能用cuda
if config.cuda and torch.cuda.is_available():
torch.cuda.set_device(config.gpu)
# 导入训练集
training_set = Char_LM_Dataset(mode="train")
training_iter = torch.utils.data.DataLoader(dataset=training_set,
batch_size=config.batch_size * config.max_sentence_length,
shuffle=False,
num_workers=2)
# 导入验证集
valid_set = Char_LM_Dataset(mode="valid")
valid_iter = torch.utils.data.DataLoader(dataset=valid_set,
batch_size=config.batch_size * config.max_sentence_length,
shuffle=False,
num_workers=0)
# 导入测试集
test_set = Char_LM_Dataset(mode="test")
test_iter = torch.utils.data.DataLoader(dataset=test_set,
batch_size=32 * 100,
shuffle=False,
num_workers=0)
model = C2W(config)
if config.cuda and torch.cuda.is_available():
model.cuda()
criterion = nn.CrossEntropyLoss(reduce=False)
optimizer = optim.Adam(model.parameters(), lr=config.learning_rate)
loss = -1
for epoch in range(config.epoch):
model.train()
process_bar = tqdm(training_iter)
for data, label,weights in process_bar:
if config.cuda and torch.cuda.is_available():
data = data.cuda()
label = label.cuda()
weights = weights.cuda()
else:
data = torch.autograd.Variable(data).long()
label = torch.autograd.Variable(label).squeeze()
out = model(data)
loss_now = criterion(out, autograd.Variable(label.long()))
ppl = (loss_now*weights.float()).view([-1,config.max_sentence_length])
ppl = torch.sum(ppl,dim=1)/torch.sum((weights.view([-1,config.max_sentence_length]))!=0,dim=1).float()
ppl = torch.mean(torch.exp(ppl))
loss_now = torch.sum(loss_now*weights.float())/torch.sum(weights!=0)
if loss==-1:
loss = loss_now.data.item()
else:
loss = 0.95 * loss + 0.05 * loss_now.data.item()
process_bar.set_postfix(loss=loss,ppl=ppl.data.item())
process_bar.update()
optimizer.zero_grad()
loss_now.backward()
optimizer.step()
print ("Valid ppl is:",get_test_result(valid_iter,valid_set))
print ("Test ppl is:",get_test_result(test_iter,valid_set))
实验结果
输出语言模型的困惑度。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









