







文章目录
attention_nmt(attention+seq2seq)


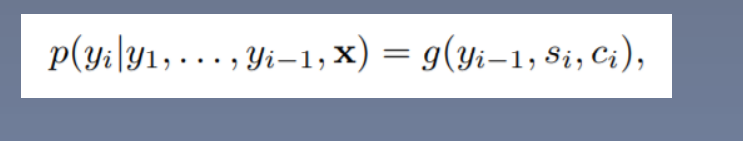
一、文件目录

二、语料集下载地址
https://wit3.fbk.eu/2014-01
三、数据处理(iwslt_Data_Loader.py)
1.数据集加载
2.读取标签和数据
3.创建word2id(源语言和目标语言)
3.1统计词频
3.2加入 pad:0,unk:1创建word2id
4.将数据转化成id(源语言和目标语言)
5.添加目标数据的输入(target_data_input)
from torch.utils import data
import os
import nltk
import numpy as np
import pickle
from collections import Counter
class iwslt_Data(data.DataLoader):
def __init__(self,source_data_name="train.tags.de-en.de",target_data_name="train.tags.de-en.en",source_vocab_size = 30000,target_vocab_size = 30000):
self.path = os.path.abspath(".")
if "data" not in self.path:
self.path += "/data"
self.source_data_name = source_data_name
self.target_data_name = target_data_name
self.source_vocab_size = source_vocab_size
self.target_vocab_size = target_vocab_size
self.source_data, self.target_data, self.target_data_input = self.load_data()
def load_data(self):
# 数据集加载
raw_source_data = open(self.path + "/iwslt14/" + self.source_data_name, encoding="utf-8").readlines()
raw_target_data = open(self.path + "/iwslt14/" + self.target_data_name, encoding="utf-8").readlines()
raw_source_data = [x[0:-1] for x in raw_source_data] # 去掉换行符
raw_target_data = [x[0:-1] for x in raw_target_data] # 去掉换行符
source_data = []
target_data = []
for i in range(len(raw_source_data)):
# 去掉空的和写着网址的源语言,目标语言
if raw_target_data[i] != "" and raw_source_data[i] != "" and raw_source_data[i][0] != "<" and \
raw_target_data[i][0] != "<":
source_sentence = nltk.word_tokenize(raw_source_data[i], language="german")
target_sentence = nltk.word_tokenize(raw_target_data[i], language="english")
if len(source_sentence) <= 100 and len(target_sentence) <= 100:
source_data.append(source_sentence)
target_data.append(target_sentence)
if not os.path.exists(self.path + "/iwslt14/source_word2id"):
source_word2id = self.get_word2id(source_data, self.source_vocab_size)
target_word2id = self.get_word2id(target_data, self.target_vocab_size)
self.source_word2id = source_word2id
self.target_word2id = target_word2id
pickle.dump(source_word2id, open(self.path + "/iwslt14/source_word2id", "wb"))
pickle.dump(target_word2id, open(self.path + "/iwslt14/target_word2id", "wb"))
else:
self.source_word2id = pickle.load(open(self.path + "/iwslt14/source_word2id", "rb"))
self.target_word2id = pickle.load(open(self.path + "/iwslt14/target_word2id", "rb"))
source_data = self.get_id_datas(source_data,self.source_word2id)
target_data = self.get_id_datas(target_data,self.target_word2id,is_source=False)
# 训练错位输入
target_data_input = [[2] + sentence[0:-1] for sentence in target_data] # 在错位输入的开始加入start,序号为2
source_data = np.array(source_data)
target_data = np.array(target_data)
target_data_input = np.array(target_data_input)
return source_data, target_data, target_data_input
# 获取word2id(源语言,目标语言)
def get_word2id(self, source_data, word_num):
words = []
for sentence in source_data:
for word in sentence:
words.append(word)
word_freq = dict(Counter(words).most_common(word_num - 4)) # 自动统计词频,取前30000个
word2id = {"<pad>": 0, "<unk>": 1, "<start>": 2, "<end>": 3}
for word in word_freq:
word2id[word] = len(word2id)
return word2id
# 源语言数据转id
def get_id_datas(self, datas, word2id,is_source = True):
for i, sentence in enumerate(datas):
for j, word in enumerate(sentence):
datas[i][j] = word2id.get(word, 1)
if is_source:
datas[i] = datas[i][0:100] + [0] * (100 - len(datas[i]))
datas[i].reverse() # 源语言逆序
else:
datas[i] = datas[i][0:99] + [3] + [0] * (99 - len(datas[i]))#在结尾加end,序号为3
return datas
def __getitem__(self, idx):
return self.source_data[idx],self.target_data_input[idx], self.target_data[idx]
def __len__(self):
return len(self.source_data)
if __name__=="__main__":
iwslt_data = iwslt_Data()
print (iwslt_data.source_data.shape)
print (iwslt_data.target_data_input.shape)
print (iwslt_data.target_data.shape)
print (iwslt_data.source_data[0])
print (iwslt_data.target_data_input[0])
print (iwslt_data.target_data[0])
四、模型(Attention_NMT_Model.py)
import torch
import torch.nn as nn
import numpy as np
from torch.nn import functional as F
from torch.autograd import Variable
class Attention_NMT(nn.Module):
def __init__(self, source_vocab_size, target_vocab_size, embedding_size,
source_length, target_length, lstm_size, batch_size=32):
super(Attention_NMT, self).__init__()
self.source_embedding = nn.Embedding(source_vocab_size, embedding_size) # source_vocab_size * embedding_size
self.target_embedding = nn.Embedding(target_vocab_size, embedding_size) # target_vocab_size * embedding_size
self.encoder = nn.LSTM(input_size=embedding_size, hidden_size=lstm_size, num_layers=1,
bidirectional=True,
batch_first=True) # if batch_first==False: input_shape=[length,batch_size,embedding_size]
self.decoder = nn.LSTM(input_size=embedding_size + 2 * lstm_size, hidden_size=lstm_size, num_layers=1,
batch_first=True)#yi-1为embedding_size,ci=hi=2*lstm_size.所以输入为yi-1+ci=embedding_size+2*lstm_size
self.attention_fc_1 = nn.Linear(3 * lstm_size, 3 * lstm_size) # 注意力机制全连接层1,eij=a(si-1,hj):si-1为lstm_size,hj为2*lstm_size。所以输入为si-1+hi=3*lstm_size
self.attention_fc_2 = nn.Linear(3 * lstm_size, 1) # 注意力机制全连接层2,应为权重为标量,所以输出为1
self.class_fc_1 = nn.Linear(embedding_size + 2 * lstm_size + lstm_size, 2 * lstm_size) # 分类全连接层1,p(yi)=g(yi-1,si,ci),yi-1为embedding_size,si为lstm_size,ci为2*lstm_size
self.class_fc_2 = nn.Linear(2 * lstm_size, target_vocab_size) # 分类全连接层2
def attention_forward(self, input_embedding, dec_prev_hidden, enc_output):
prev_dec_h = dec_prev_hidden[0].squeeze().unsqueeze(1).repeat(1, 100, 1) # batch_size*legnth*lstm_size
atten_input = torch.cat([enc_output, prev_dec_h], dim=-1) # batch_size*length*(3*lstm_size)
attention_weights = self.attention_fc_2(F.relu(self.attention_fc_1(atten_input))) # batch_size*length*1
attention_weights = F.softmax(attention_weights, dim=1) # alpha: batch_size*length*1
atten_output = torch.sum(attention_weights * enc_output, dim=1).unsqueeze(1) # bs*1*(2*lstm_size)
dec_lstm_input = torch.cat([input_embedding, atten_output], dim=2) # bs*1*(embedding_size*2*lstm_size)
dec_output, dec_hidden = self.decoder(dec_lstm_input, dec_prev_hidden)
# dec_output: bs*1*lstm_size
# dec_hidden: [bs*1*lstm_size,bs*1*lstm_size]
return atten_output, dec_output, dec_hidden
def forward(self, source_data, target_data, mode="train", is_gpu=True):
source_data_embedding = self.source_embedding(source_data) # batch_size*length*embedding_size
enc_output, enc_hidden = self.encoder(source_data_embedding)
# enc_output.shape: batch_size*length*(2*lstm_size) 只返回所有hidden, concat
# enc_hidden:[[h1,h2],[c1,c2]] 返回每个方向最后一个时间步的h和c
self.atten_outputs = Variable(torch.zeros(target_data.shape[0],
target_data.shape[1],
enc_output.shape[2])) #ci=batch_size*length*(2*lstm_size)
self.dec_outputs = Variable(torch.zeros(target_data.shape[0],
target_data.shape[1],
enc_hidden[0].shape[2])) # si=batch_size*length*lstm_size
if is_gpu:
self.atten_outputs = self.atten_outputs.cuda()
self.dec_outputs = self.dec_outputs.cuda()
# enc_output: bs*length*(2*lstm_size)
if mode == "train":
target_data_embedding = self.target_embedding(target_data) # batch_size*length*embedding_size
dec_prev_hidden = [enc_hidden[0][0].unsqueeze(0), enc_hidden[1][0].unsqueeze(0)] #取出正向的h1和c1
# dec_prev_hidden[0]: 1*bs*lstm_size, dec_prev_hidden[1]: 1*bs*lstm_size
for i in range(100):
input_embedding = target_data_embedding[:, i, :].unsqueeze(1) # bs*1*embedding_size
atten_output, dec_output, dec_hidden = self.attention_forward(input_embedding,
dec_prev_hidden,
enc_output)
# dec_output: bs*1*lstm_size
# dec_hidden: [bs*1*lstm_size,bs*1*lstm_size]
self.atten_outputs[:, i] = atten_output.squeeze()
self.dec_outputs[:, i] = dec_output.squeeze()
dec_prev_hidden = dec_hidden
class_input = torch.cat([target_data_embedding, self.atten_outputs, self.dec_outputs],
dim=2) # bs*length*(embedding_size*2*lstm_size+lstm_size)
outs = self.class_fc_2(F.relu(self.class_fc_1(class_input)))
else:
input_embedding = self.target_embedding(target_data)
dec_prev_hidden = [enc_hidden[0][0].unsqueeze(0), enc_hidden[1][0].unsqueeze(0)]
outs = []
for i in range(100):
atten_output, dec_output, dec_hidden = self.attention_forward(input_embedding,
dec_prev_hidden,
enc_output)
class_input = torch.cat([input_embedding, atten_output, dec_output], dim=2)
pred = self.class_fc_2(F.relu(self.class_fc_1(class_input)))
pred = torch.argmax(pred, dim=-1)
outs.append(pred.squeeze().cpu().numpy())
dec_prev_hidden = dec_hidden
input_embedding = self.target_embedding(pred)
return outs
五、训练和测试
import torch
import torch.autograd as autograd
import torch.nn as nn
import torch.optim as optim
from model import Attention_NMT
from data import iwslt_Data
import numpy as np
from tqdm import tqdm
import config as argumentparser
config = argumentparser.ArgumentParser()
torch.manual_seed(config.seed)
from nltk.translate.bleu_score import corpus_bleu
if config.cuda and torch.cuda.is_available():
torch.cuda.set_device(config.gpu)
def get_dev_loss(data_iter):
model.eval()
process_bar = tqdm(data_iter)
loss = 0
for source_data, target_data_input, target_data in process_bar:
if config.cuda and torch.cuda.is_available():
source_data = source_data.cuda()
target_data_input = target_data_input.cuda()
target_data = target_data.cuda()
else:
source_data = torch.autograd.Variable(source_data).long()
target_data_input = torch.autograd.Variable(target_data_input).long()
target_data = torch.autograd.Variable(target_data).squeeze()
out = model(source_data, target_data_input)
loss_now = criterion(out.view(-1, 30000), autograd.Variable(target_data.view(-1).long()))
weights = target_data.view(-1) != 0
loss_now = torch.sum((loss_now * weights.float())) / torch.sum(weights.float())
loss+=loss_now.data.item()
return loss
def get_test_bleu(data_iter):
model.eval()
process_bar = tqdm(data_iter)
refs = []
preds = []
for source_data, target_data_input, target_data in process_bar:
target_input = torch.Tensor(np.zeros([source_data.shape[0], 1])+2)#bs个2
if config.cuda and torch.cuda.is_available():
source_data = source_data.cuda()
target_input = target_input.cuda().long()
else:
source_data = torch.autograd.Variable(source_data).long()
target_input = torch.autograd.Variable(target_input).long()
target_data = target_data.numpy()
out = model(source_data, target_input,mode="test")
out = np.array(out).T
tmp_preds = []
for i in range(out.shape[0]):
tmp_preds.append([])
for i in range(out.shape[0]):#bs
for j in range(out.shape[1]):#length
if out[i][j]!=3:
tmp_preds[i].append(out[i][j])
else:
break
preds += tmp_preds
tmp_refs = []
for i in range(target_data.shape[0]):
tmp_refs.append([])
for i in range(target_data.shape[0]):
for j in range(target_data.shape[1]):
if target_data[i][j]!=3 and target_data[i][j]!=0:
tmp_refs[i].append(target_data[i][j])
tmp_refs = [[x] for x in tmp_refs]#为了调用函数,所以需要在参考的后面再加一个[]
refs+=tmp_refs
bleu = corpus_bleu(refs,preds)*100
with open("./data/result.txt","w") as f:
for i in range(len(preds)):
tmp_ref = [target_id2word[id] for id in refs[i][0]]
tmp_pred = [target_id2word[id] for id in preds[i]]
f.write("ref: "+" ".join(tmp_ref)+"\n")
f.write("pred: "+" ".join(tmp_pred)+"\n")
f.write("\n\n")
return bleu
training_set = iwslt_Data()
training_iter = torch.utils.data.DataLoader(dataset=training_set,
batch_size=config.batch_size,
shuffle=True,
num_workers=0)
valid_set = iwslt_Data(source_data_name="IWSLT14.TED.dev2010.de-en.de",target_data_name="IWSLT14.TED.dev2010.de-en.en")
valid_iter = torch.utils.data.DataLoader(dataset=valid_set,
batch_size=config.batch_size,
shuffle=True,
num_workers=0)
test_set = iwslt_Data(source_data_name="IWSLT14.TED.tst2012.de-en.de",target_data_name="IWSLT14.TED.tst2012.de-en.en")
test_iter = torch.utils.data.DataLoader(dataset=test_set,
batch_size=config.batch_size,
shuffle=True,
num_workers=0)
model = Attention_NMT(source_vocab_size=30000,target_vocab_size=30000,embedding_size=256,
source_length=100,target_length=100,lstm_size=256)
if config.cuda and torch.cuda.is_available():
model.cuda()
criterion = nn.CrossEntropyLoss(reduce=False)
optimizer = optim.Adam(model.parameters(), lr=config.learning_rate)
loss = -1
target_id2word = dict([[x[1],x[0]] for x in training_set.target_word2id.items()])
for epoch in range(config.epoch):
model.train()
process_bar = tqdm(training_iter)
for source_data, target_data_input, target_data in process_bar:
if config.cuda and torch.cuda.is_available():
source_data = source_data.cuda()
target_data_input = target_data_input.cuda()
target_data = target_data.cuda()
else:
source_data = torch.autograd.Variable(source_data).long()
target_data_input = torch.autograd.Variable(target_data_input).long()
target_data = torch.autograd.Variable(target_data).squeeze()
out = model(source_data,target_data_input)
loss_now = criterion(out.view(-1,30000), autograd.Variable(target_data.view(-1).long()))
weights = target_data.view(-1)!=0
loss_now = torch.sum((loss_now*weights.float()))/torch.sum(weights.float())
if loss == -1:
loss = loss_now.data.item()
else:
loss = 0.95*loss+0.05*loss_now.data.item()
process_bar.set_postfix(loss=loss_now.data.item())
process_bar.update()
optimizer.zero_grad()
loss_now.backward()
optimizer.step()
test_bleu = get_test_bleu(test_iter)
print("test bleu is:", test_bleu)
valid_loss = get_dev_loss(valid_iter)
print ("valid loss is:",valid_loss)
实验结果
生成测试集和验证集的blue值(翻译的评价指标),将测试集的原始数据和翻译数据都存入文件。














 2696
2696











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









