







Oracle常用函数
Oracle常用函数介绍
`Oracle常用函数有:转换函数、聚合函数、数字函数、日期函数、字符串函数、逻辑函数、分析函数、排名函数、偏移函数
例如:
一、三种转换函数TO_CHAR()、TO_DATE()、TO_NUMBER()
1.TO_CHAR(目标字段,’输出格式‘)
把日期转换成指定格式字符串。
1.select to_char(sysdate,'YYYY"年"MM"月"DD"日"') as TEST from dual; --2023年8月25日
2.select to_char(sysdate,'YYYY-MM-DD') as test from dual; --2023-08-25
3.select to_char(sysdate,'YYYY-MM') as test from dual; --2023-08
4.select to_char(sysdate,'YYYY') as yaer from dual; --2023
5.select to_char(sysdate,'MM') as MONTH from dual; --08
6.select to_char(sysdate,'DD') as Day from dual; --25
7.select to_char(sysdate,'SS') as Miao from dual; --15
8.select 123456.78,to_char(123456.78) as string from dual;
2.TO_DATE(目标对象,’输出格式’)
此处对象只能是符合实际日期的一个字符串类型;日期和数字型不能直接转换。
1.select to_date('20230809145345','YYYYMMDD HH24:MI:SS') as TIST_TIME from dual;
2.select to_date(20230809145345,'YYYYMMDD HH24:MI:SS') as TIST_TIME from dual; --隐式转换了,要避免隐式转换
3.select to_date('145345','HH24:MI:SS') as TIME from dual; --默认补全为当前月份第一天日期
4.select to_date('20230809','YYYYMMDD') as TIST_TIME from dual; --转换后日期带/
5.select to_date('20230809','YYYY-MM-DD') as TIST_TIME from dual; --转换后日期带/
3.TO_NUMBER(字符串)
把字符串转换成数字。
select '1234.56',to_number('1234.56') as numb from dual;
二、聚合函数 MAX()、MIN()、SUM()、AVG()、COUNT()
聚合函数:同时对多行进行操作,并返回一个结果 (别名 多行函数)。
聚合函数 结合 GROUP BY 一起使用。使用 GROUP BY 以后 ,聚合函数会根据分组字段,每个组返回一个计算结果。
使用了group by进行分组之后:
1、select后面(要查询的字段/列)只能接这个分组的字段和聚合函数,不能跟未分组的字段一起查询
2、分组后的过滤条件(HAVING),只能用分组字段(GROUP BY后面接的字段)或聚合函数过滤;HAVING 是对分组的结果进行过滤,放在 GROUP BY 后面。
数据说明:

empno代表员工编号,ename代表员工姓名,job代表工作岗位,mgr表示员工上级编号,hiredate表示员工入职日期,sal表示员工工资,comm表示员工奖金,deptno表示部门编号。
WHERE 和 HAVING 用法上的区别:
1、WHERE 必须放在 GROUP BY 前面,HAVING 放在 GROUP BY 后面过滤。
(WHERE是先过滤再分组,HAVING是先分组然后再过滤)
2、WHERE 后面可以跟所有的条件,除了 不能 直接使用 聚合函数 作为条件。
SELECT * FROM EMP E WHERE MAX(E.SAL)>1; --报错
3、HAVING 可以 直接使用聚合函数作为条件 , 只能跟 聚合函数 或 分组字段 作为条件。
1.MAX() 取最大值
select max(sal) from emp; --查找员工表中工资的最大值 5000
select deptno,max(sal) from emp group by deptno; --按照部门编号进行分组,找出每个部门中对应的员工工资的最大值。

2.MIN() 取最大值
select min(sal) from emp; --查找员工表中工资的最小值 800
select deptno,min(sal) from emp group by deptno; --按照部门编号进行分组,找出每个部门中对应的员工工资的最小值。

3.SUM() 取最大值
select sum(sal) from emp; --求所有员工工资的总和 29025
select deptno,sum(sal) from emp group by deptno; --按照部门编号进行分组,统计每个部门里面员工的工资总和。

4.AVG() 取最大值
select round(avg(sal),2) from emp; --求所有员工工资的平均值 2073.21
select deptno,round(avg(sal),2) from emp group by deptno; --按照部门编号进行分组,统计每个部门里面员工的工资的平均值。

注:round( x ,y )函数为四舍五入函数,指对数据 x 进行四舍五入,保留 y 位小数。
5.COUNT() 取最大值
select count(empno) from emp; --求员工表中的员工数 14
select deptno,count(empno) from emp group by deptno; --按照部门编号进行分组,统计每个部门里面员工的人数。

三、数字函数 ABS()、MOD()、POWER()、TRUNC()、ROUND()、CEIL()、FLOOR()
1.ABS() 取绝对值
SELECT ABS(-1) FROM DUAL; -- 1
SELECT ABS(-1.544) FROM DUAL; -- 1.544
SELECT ABS(0) FROM DUAL; -- 0
2.MOD() 数值求余
SELECT MOD(8,2) FROM DUAL; -- 0
SELECT MOD(8,3) FROM DUAL; -- 2
SELECT MOD(8,3.2) FROM DUAL; -- 1.6
3.POWER() 数值幂运算
SELECT POWER(2,3) FROM DUAL; --2的3次方 8
SELECT POWER(2,3.4) FROM DUAL; -- 10.556
SELECT POWER(-2,2) FROM DUAL; --4 注:当x是负数时,y必须是整数,不能是小数;
4.TRUNC() 数值截断函数 (不四舍五入)
TRUNC(X,Y) --不会进行四舍五入
SELECT TRUNC(123.456,2) FROM DUAL; --在小数点之后第二位截断 123.45
SELECT TRUNC(123.456,-1) FROM DUAL; --在小数点之前第一位截断 120
SELECT TRUNC(123.456,0) FROM DUAL; -- 123
5.ROUND() 数值截断函数(四舍五入)
ROUND(X,Y) 四舍五入函数 -- 会进行四舍五入
SELECT ROUND(123.456,2) FROM DUAL; -- 123.46
6.CEIL() 数值向上取整
SELECT CEIL(4.23) FROM DUAL; -- 5
SELECT CEIL(-4.23) FROM DUAL; -- -4
SELECT CEIL(0) FROM DUAL; -- 0
7.FLOOR() 数值向下取整
SELECT FLOOR(4.23) FROM DUAL; -- 4
SELECT FLOOR(-4.23) FROM DUAL; -- -5
四、日期函数
1.获取系统时间(当前时间)
select sysdate from dual; --获取系统时间
select current_date from dual; --获取系统时间
时间格式为:2023/8/30 8:36:57
2.对日期进行加减
select sysdate+5 from dual; --当前日期加5天 2023/9/4 8:38:25
select sysdate-5 from dual; --当前日期减5天 2023/8/25 8:38:25
3.日期减日期,算间隔天数
select sysdate-to_date('20230101','YYYYMMDD') from dual; --间隔 241.36天
select to_date('20230101','YYYYMMDD')-sysdate from dual; -- -241.36
--另一种形式
select sysdate-date'2023-01-01' from dual; --间隔241.36天
注1:to_date(‘20230101’,‘YYYYMMDD’) 可以将字符串日期转变为指定格式日期输出,'YYYYMMDD’表示为 年/月/日 输出为2023/1/1 。
注2:date’年-月-日’ :可表示一个日期
4.日期做截断函数 trunc(日期,‘输出格式’)
---返回这一年的 1月一号 2023/1/1
SELECT TRUNC(SYSDATE,'YYYY') FROM DUAL;
----返回时间所在月的 一号 2023/8/1
SELECT TRUNC(SYSDATE,'MM') FROM DUAL;
---天,不带时分秒 2023/8/30 8:50:13 2023/8/30
SELECT SYSDATE,TRUNC(SYSDATE,'DD') FROM DUAL;
---当前所在星期的第一天 2023/8/30 8:50:13 2023/8/27(周日)
SELECT SYSDATE,TRUNC(SYSDATE,'D') FROM DUAL;
---返回当前时间所在季度的第一天 2023/8/30 8:50:13 2023/7/1
SELECT SYSDATE,TRUNC(SYSDATE,'Q') FROM DUAL;
5.月份加减函数 ADD_MONTHS()
SELECT ADD_MONTHS(SYSDATE,1) FROM DUAL; --加一个月 2023/9/30 8:54:09
SELECT ADD_MONTHS(SYSDATE,-1) FROM DUAL; --减去一个月 2023/7/30 8:54:09
6.月份间隔函数 MONTHS_BETWEEN(日期1,日期2)
select MONTHS_BETWEEN(sysdate,date'2023-01-01') from dual; -- 7.94747834528076(单位 月)
7.返回指定日期当月的最后一天 LAST_DAY(日期)
SELECT LAST_DAY(SYSDATE) FROM DUAL; -- 2023/8/31 8:57:36
--TRUNC 函数返回的结果作为 LAST_DAY 函数的参数 ,函数嵌套
SELECT LAST_DAY(TRUNC(SYSDATE,'DD'))FROM DUAL; -- 2023/8/31
8.四舍五入式处理日期 ROUND(日期,‘输出格式’)
---如果为“YEAR”则舍入到某年的1月1日,即前半年舍去,后半年作为下一年
SELECT ROUND(SYSDATE,'YEAR') FROM DUAL; --下半年 2024/1/1
SELECT ROUND(date'2023-05-23','YEAR') FROM DUAL; --上半年 2023/1/1
---如果为“MONTH”则舍入到某月的1日,即前半月舍去,后半月作为下一月。
SELECT ROUND(SYSDATE,'MONTH') FROM DUAL; --2023/9/1
SELECT ROUND(SYSDATE-15,'MONTH') FROM DUAL; --2023/8/1
---默认为“DDD”,即月中的某一天,最靠近的天,前半天舍去,后半天作为第二天
SELECT ROUND(to_date('20230411092334','YYYYMMDD HH12MISS'),'DDD') FROM DUAL; --2023/4/11
SELECT ROUND(SYSDATE,'DDD') FROM DUAL; --2023/8/30
----如果为“DAY”则舍入到最近的周的周日,即上半周舍去,下半周作为下一周周日
SELECT ROUND(SYSDATE,'DAY') FROM DUAL; --2023/8/27
SELECT ROUND(SYSDATE+3,'DAY') FROM DUAL; --2023/9/3
SELECT ROUND(to_date('20230809120000','YYYYMMDD HH12MISS'),'DAY') FROM DUAL; --2023/8/13
五、字符串函数
1.字符转换函数 to_char()
select to_char(to_date('20230819','YYYYMMDD'),'Q') from dual; --返回当前时间所在季度 3
select to_char(sysdate,'day') from dual; --返回当前日期所在的星期 星期三
SELECT TO_CHAR(SYSDATE,'YYYY') FROM DUAL; --返回当前所在年份 2023
SELECT TO_CHAR(SYSDATE,'MM') FROM DUAL; --返回当前所在月份 08
SELECT TO_CHAR(SYSDATE,'DD') FROM DUAL; --返回当前所在月的日 30
SELECT TO_CHAR(SYSDATE,'YYYYMMDD') FROM DUAL; --返回当前所在日期的年月日 20230830
2.字符拼接函数 concat(x,y) 或者管道 || 拼接
select concat(concat(e.ename,e.empno),'hahaha') from emp e; --例 SMITH7369hahaha
select concat('HELLO','ORACLE') from dual; --HELLOORACLE
select 'hello' || ' world !' from dual; -- hello world !
3.ASCII() 函数,解读字符ASCII值
select ascii('1') from dual; -- 49
select ascii(1) from dual; -- 49
select ascii('A') from dual; -- 65
select ascii('abc') from dual; -- 97 --返回第一个字符所对应的ASCII编码值
4.按组拼接,列转行函数 wm_concat(x)
wm_concat(x) 跟group by 一起使用,将每一组的多行的某个字段的数据拼接到一行,并逗号隔开
select e.deptno,wm_concat(e.ename)
from emp e
group by e.deptno;
按照部门进行分组,将同组的员工姓名拼接到同一行。

按照部门编号分组,将同部门的工作岗位进行拼接。
select e.deptno,wm_concat(distinct e.job) --加distinct 去重拼接
from emp e
group by e.deptno;

5.字符长度 LENGTH()
select length('ABCF') from dual; -- 4
select length('中国') from dual; -- 2
6.字节长度 LENGTHB()
select lengthb('ABCF') from dual; --4 一个英文占一个字节
select lengthb('中国') from dual; --4 一个汉字占两个字节
7.位置查找函数 INSTR(x,str,m,n)
说明:x表示原字符串,str目标字符,m从哪个位置开始找(默认为 1 ,正数从左往右找),n表示第几次出现(默认为1)。返回值为找到的目标位置,没有找到返回为 0
select instr('hello word','o',1,1) from dual; -- 5
select instr('hello word','o',6,2) from dual; -- 0
select instr('helloword','o',-1,1) from dual; -- 7
select instr('helloword','or') from dual; -- 7
8.替换函数 REPLACE(字符串,旧的值,新的值)
select replace('helloword','or','MM') from dual; --or 替换成 MM ,得到 hellowMMd
select replace('helloword','o','S') from dual; --o 替换成 S ,得到 hellSwSrd
select replace('helloword','ord','D') from dual; --连续字符才可以替换 ord 替换成 D, 得到 hellowD
select replace(ename,'S','MM'),ename from emp;
9.大小写转换 LOWER() 转小写、UPPER() 转大写
select upper('helloword') from dual; -- HELLOWORD
select lower('HELLO ORACLE') from dual; -- hello oracle
10.截去函数 LTRIM(x,y)、RTRIM(x,y) 、TRIM(y,x)
说明:截去函数截去掉包含在后面的参数 y 中的任意一个或多个字符,要求包含在参数 y 内,并且是连续的。
- LTRIM(x,y) 从左边开始,截去 x 中包含在参数 y 中的字符,默认截去空格
- RTRIM(x,y) 从右边开始,截去 x 中包含在参数 y 中的字符,默认截去空格
- TRIM(y from x) 两边截去 x 中包含的参数 y 中的字符,缺省时去空格 --截去只能填一个字符 y
select ltrim('SASCDFVGS','S') from dual; --ASCDFVGS
select rtrim('SASCDFVGS','S') from dual; --SASCDFVG
select trim(' SASCDFVGS ') from dual; --SASCDFVGS 去除两边空格
select trim('S' from 'SASCDFVGS') from dual; --ASCDFVG
11.截取函数 SUBSTR(x,m,n)
说明:从原字符串 x 中的第 m 位开始截取,截取 n 个长度。
select substr('DDSIYYDSILOVEU',9,6) from dual; --从第九个位置开始截取,截取六个长度 ILOVEU
select substr('DDSIYYDSILOVEU',-6,6) from dual; --从第九个位置开始截取,截取六个长度 ILOVEU
select substr('DDSIYYDSILOVEU',-6) from dual; --从右往左第六个位置开始截取,默认截取到最后位 ILOVEU
六、逻辑函数 nvl()、nvl2()、decode()
1.空值处理 nvl()、nvl2()
- nvl(列名,默认值)
对空值进行默认值处理 - nvl2(列名,不为空的处理,空值的处理)
对含空值的字段的数据,进行空值和非空值这两个情况进行处理
select job,nvl(comm,0) from emp; --将奖金为空值的数据赋予默认值 0
select job,nvl2(comm,sal+comm,0) from emp; --若奖金为空,则赋予默认值0,否则返回为工资+奖金
9.decode()
decode(列名,判断值1,结果值1,判断值2,结果值2,)
说明:可以对某个字段多种情况进行精准判断
select ename,job,decode(job,'MANAGER',sal*1.3,'SALESMAN',sal*1.2,sal*1.1) from emp; --根据不同的工作岗位进行 涨薪
select ename,decode(comm,null,0,sal+comm) from emp; --若奖金为空,则赋予默认值0,否则返回为工资+奖金
可以与case when … 进行替换
case … when … 数据判断的逻辑语句
语法:
case
when 条件判断1 then 执行结果1
when 条件判断2 then 执行结果2
...
else 执行结果
end --可用 as 取个别名
--查询每个人得到工资等级,2000以下是C,2000-3000是B,3000以上是A
select ename,job,
case
when sal<2000 then 'C'
when sal between 2000 and 3000 then 'B'
else 'A'
end as 工资等级
from emp;
七、分析函数 = 聚合函数+开窗函数over()
- 开窗函数:over()
- 分析函数语法:聚合函数()或者单行函数() + over( partition by 分组 order by 排序)
- 分析函数的运用:对表格的数据进行统一的或者是分组的计算,将计算的结果当成一个新的列,直接拼接在表格的后面。
聚合函数+开窗函数
sum()over(),max()over(),min()over(),count()over,avg()over 对整个表格的数据进行计算。
1. over() 里面不填内容
select e.*,sum(sal)over() from emp e;
select e.*,max(sal)over() from emp e;
select e.*,min(sal)over() from emp e;
select e.*,count(sal)over() from emp e;
select e.*,avg(sal)over() from emp e;

聚合函数得到的结果,生成新的一列数据字段,在查询结果中展示。
2. over(partition by 字段)分组
对某个分组内的数据进行统计和计算
将每个部门的工资总和 拼接在 对应部门 每条数据 后面
select emp.*, sum(sal) over(partition by deptno)
from emp;

3. over( order by 字段) 排序
在整个表格的范围内,对数据进行 ’累计‘ 的统计。
select e.*,sum(sal)over(order by e.empno asc) from emp e; --按员工编号进行升序排序,并累计统计员工工资 如下图所示
select e.*,max(sal)over(order by e.empno asc) from emp e; --按员工编号进行升序排序,并按排序结果一步一步找对对应的最大工资
select e.*,min(sal)over(order by empno asc) from emp e; --按员工编号进行升序排序,并按排序结果一步一步找对对应的最小工资
select e.*,count(1)over(order by e.empno asc) from emp e; --按员工编号进行升序排序,并按排序结果累计统计当前员工人数
select e.*,count(sal)over(order by e.empno asc) from emp e; --按员工编号进行升序排序,并按排序结果累计统计当前员工人数
select e.*,avg(sal)over(order by e.empno asc) from emp e; --按员工编号进行升序排序,并按排序结果计算当前排序情况的平均工资

4. over(partition by 分组 order by 排序)
在整个表格的范围内,对数据进行某个字段排序的 ’累计‘ 的统计。
select emp.*,
sum(sal)over(partition by deptno order by empno asc)
from emp;

按照部门编号进行了分组,并按照员工编号进行了升序排序。最后逐步统计部门的员工工资的总和。
分析函数配合 rows between and 使用
- 语法:
CURRENT ROW:当前行
n PRECEDING:往前n行
n FOLLOWING:往后n行
UNBOUNDED PRECEDING:表示从前面的起点
UNBOUNDED FOLLOWING:表示到后面的终点 - 实例:
SELECT DEPTNO,ENAME,HIREDATE,SAL,
SUM(SAL) OVER() AS S1, --所有行相加
SUM(SAL) OVER(PARTITION BY DEPTNO) AS S2, --按DEPTNO分组,组内数据相加
SUM(SAL) OVER(PARTITION BY DEPTNO ORDER BY HIREDATE) AS S3, --按DEPTNO分组,组内数据累加
SUM(SAL) OVER(PARTITION BY DEPTNO ORDER BY HIREDATE
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS S4, --和S3效果相同,
--由起点到当前行聚合
SUM(SAL) OVER(PARTITION BY DEPTNO ORDER BY HIREDATE
ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS S5, --当前行和前面1行聚合
SUM(SAL) OVER(PARTITION BY DEPTNO ORDER BY HIREDATE
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS S6, --前1行,当前行及后1行聚合
SUM(SAL) OVER(PARTITION BY DEPTNO ORDER BY HIREDATE
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS S7 --当前行到最后一行聚合
FROM EMP;

八、排名函数
排名函数 是一定要排序才能有排名的函数。
语法:单行函数() + over(partition by 分组 order by 排序)
1. row_number()over()
按照顺序,给每一行定义一个有顺序的排序数字,依次排序。没有并列排名情况 1 2 3 4 5
select emp.*,
row_number() over(order by sal desc) r --按工资降序排序。
from emp;

2. rank()over()
按照顺序,如果有相同的值,那么会产生并列的排名,而且会跳过占用的名次 1 2 3 3 5
select emp.*,
rank() over(order by sal desc) r
from emp;

3. dense_rank()over()
按照顺序,如果有相同的值,那么会产生并列的排名,但是不会跳过占用的名次 1 2 3 3 4
select emp.*,
dense_rank() over(order by sal desc) r
from emp;

- 有partition by 分组,就在组内进行排名
select emp.*,
row_number() over(partition by deptno order by sal desc) r
from emp;

九、偏移函数 LAG()、LEAD()
LAG和LEAD函数可以在一次查询中取出同一字段的前N行的数据和后N行的值。
语法:LAG(ARG1,ARG2,ARG3)over(partition by 字段 order by 字段)
--LAG 往下面多少行找
--第一个参数是偏移哪个字段的数据
--第二个参数是偏移多少行
--第三个参数是当偏移之后找不到数据,就给的一个默认值
--ORDER BY 必须要有
--PARTITION BY 可以省略,当省略的时候就是整张表的数据做偏移,不分组
--当 PARTITION BY 存在时,就是在每一组里边进行偏移
1. lag()over() 向下偏移
SELECT T.*,LAG(T.SAL,2,0)OVER(PARTITION BY T.DEPTNO ORDER BY T.SAL DESC) LAG_SAL
FROM EMP T;

员工按部门进行分组,并按降序进行排序,之后将工资向下偏移 2 个位置,生成新列,没有数据则补充为 0 。
2. lead()over() 向上偏移
SELECT T.*,LEAD(T.SAL,2,0)OVER(PARTITION BY T.DEPTNO ORDER BY T.SAL DESC) LEAD_SAL
FROM EMP T;
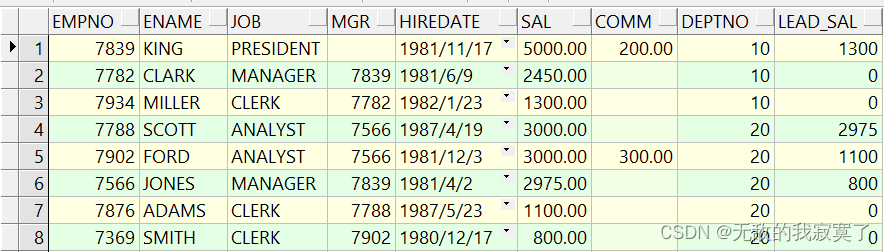
员工按部门进行分组,并按降序进行排序,之后将工资向上偏移 2 个位置,生成新列,没有数据则补充为 0 。
例题:通过偏移计算 环比情况
环比:环比的定义和计算方法:环比是指当前时间段的数据与上一个时间段的数据相比较的增长率,通常用百分数表示。环比计算方法如下:环比增长率 = (当前时间段数据 - 上一个时间段数据) / 上一个时间段数据 × 100%
数据声明:

--用lag()over()
select t.ym,t.amt-lag(t.amt,1)over(order by t.ym) 环比情况
FROM SAL t
--用lead()over()
select t.ym,t.amt-lead(t.amt,1)over(order by t.ym desc) 环比情况
FROM SAL t
order by t.ym;
















 4229
4229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









