





A Perceptual Distinguishability Predictor For JND-Noise-Contaminated Images
摘要:恰察觉失真(JND)模型被广泛用于图像和视频中的感知冗余估计。测量JND模型精度的常用方法是在基于JND模型的图像中注入随机噪声,并检查JND噪声污染的图像在感知上是否可与原始图像区分开。此外,当比较两种不同的JND模型的精度时,在相同的噪声能量水平下产生具有更好质量的JND噪声污染图像的模型是更好的模型。但是在这两种情况下,主观测试都是必要的,这是非常耗时和昂贵的。在这篇文章中,作者提出了一个全参考度量称为PDP(感知可区分性预测),它可以用来确定一个给定的JND噪声污染的图像对比参考图像是否感知可区分的。所提出的度量采用稀疏编码的概念,并从给定的图像对中提取特征向量。然后将特征向量输入多层神经网络进行分类。为了训练网络,作者建立了一个999幅自然图像的公共数据库,这些自然图像具有从大量主观实验中获得的四种不同JND模型的分辨率阈值。结果表明,PDP达到了97.1%的高分类精度。所提出的方法可用于客观地比较各种JND模型,而无需进行任何主观测试。它还可以用来获得适当的比例因子,以提高由任意JND模型估计的JND阈值。
主要工作
- 提出一个JND噪声污染图像的感知可区分预测器(PDP);
- 为四种不同的JND模型提出了一个具有图像级可区分阈值的数据库;
- 提出了一种基于图像内容为任意JND模型选择比例因子的系统方法,用于更精确地估计JND阈值,比较各种JND模型;
感知可区分预测器(PDP)
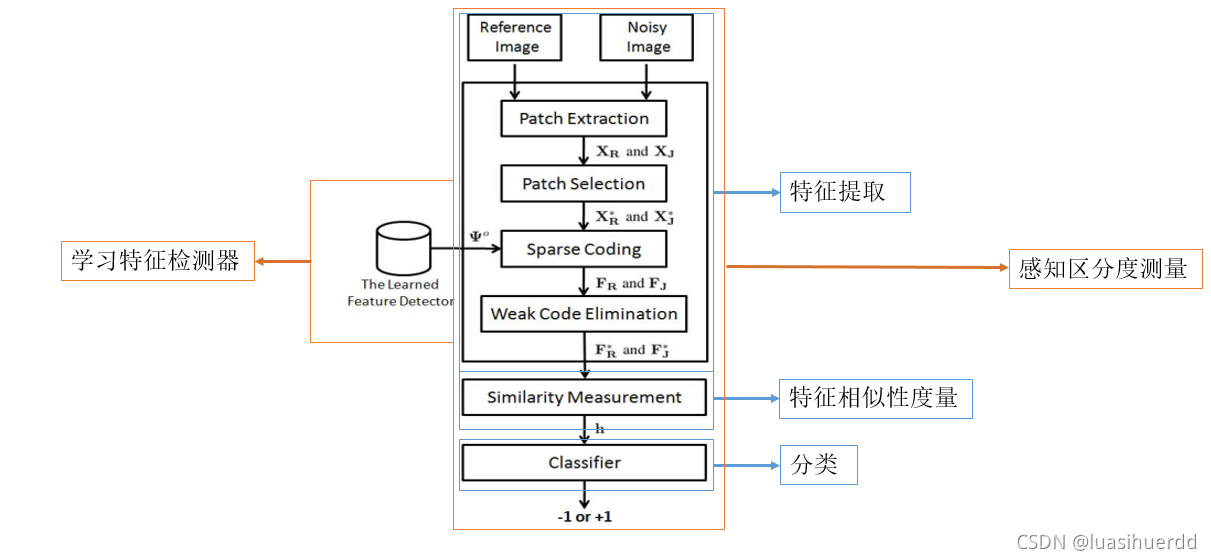
上图描述了PDP的流程图。该方法包括两个主要部分:1)学习感知特征检测器,2)感知区分度测量。第二部分本身由以下三个步骤组成:a)特征提取,b)特征相似性度量,c)分类。
学习特征检测器
使用独立成分分析(ICA)来实现,x表示矢量化的图像块,假设x可以用字典中一些基向量的线性叠加来表示,即
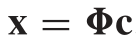
两边同时乘以字典的逆,可得稀疏特征向量
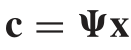
字典的逆通过对一组自然图像块应用稀疏编码方法获得
学习特征检测器的作用,就是通过将它应用于给定的图像块x,可以获得稀疏特征向量c。
x的选取
从9张图像中随机提取大小为8×8的P(20000)个块,对图像块进行矢量化,生成大小为64 × 20000的数据矩阵X

稀疏编码
应用主成分分析(PCA)来降低数据矩阵维数,实验发现K = 50时,可以获得最好的结果。然后使用pca的对角矩阵和C的k个最大特征值 得到白化矩阵w,白化数据Z。最后使用FastICA稀疏编码方法进行特征的学习

最后一步是为了将获得的特征检测器从白化空间变换到原始空间,最终得到的50个基向量

感知区分度度量
特征提取:R为参考灰度图像,J为JND噪声污染图像。使用学习特征检测器为R和J提取稀疏特征向量
1)将R和J都划分为8×8不重叠的块,将获得的块矢量化及中心化,得到两个64 × Q的矩阵
2)将使用MS-SSIM计算J中每个块的感知质量分数,保留质量差的块,矩阵大小为64 × G
3)
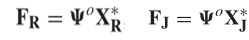
4)计算稀疏特征向量的功率,丢弃功率低的向量,矩阵大小为K × H
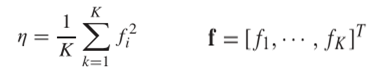
特征相似性度量
度量所计算的特征矩阵之间的相似性,就不概述
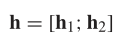
最终特征向量h的长度将为2K,因为它是通过h1和h2的连接获得的。因为,在实验中,K = 50,h的长度将是100。
分类:多层感知器
网络的输入和输出神经元的数量分别等于100和1,第一至第三隐藏层的神经元数目分别为128、64和16,Sigmoid函数作为输出层的激活函数。网络的输出是二进制值(0或1),它决定了输入的噪声图像在感知上是否可与参考图像区分开。
数据库
为了训练分类器,文章建立一个图像数据库,其中每个图像有四个与四个不同的JND模型相关的可分辨阈值
1 )采用MIT中的999张1024 × 768彩色图像
2) 采用四个JND模型:Wu2017 、Liu2010 、Wu2013 和Yang2005
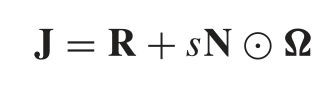
3)可区分阈值:一个合适的s值,来衡量所采用的JND模型在该参考图像的JND阈值,999 × 4 = 3996个可分辨阈值
可区分阈值测量实验
1)定义一个心理测量函数,该函数将JND噪声污染图像中的噪声能量与相应的感觉(两幅图像之间的可分辨性)联系起来
2)求取初始可区分阈值
3)使用Psi方法自适应地估计可区分阈值和函数斜率
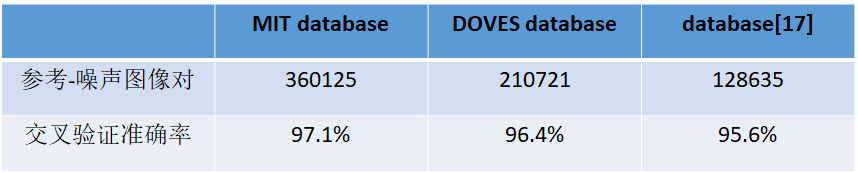
实验结果
PDP的交叉验证精度
基于PDP的多种JND模型比较
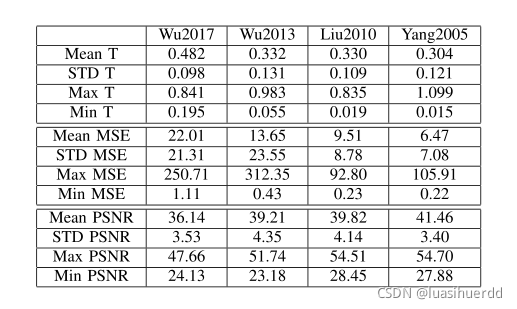
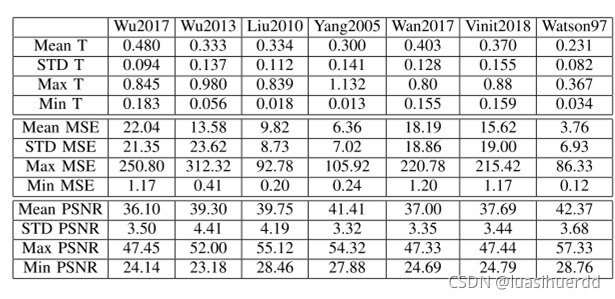
基于PDP的多种JND模型比较(非数据库模型)
比较步骤
1)将s设置为初始值s0
2)生成JND噪声污染图像
3)在R和J上应用PDP。如果它们在感知上是可区分的,用步长ζ减小S的值,然后返回步骤2。否则将可区分阈值设置为当前值s,然后退出。
总结
1)PDP适用于JND噪声污染图像,具有很高的分类精度和很好的泛化能力
2)提出的数据库可用于生成任意数量的具有可区分阈值的训练样本,能很好的解决数据样本少的问题
3)基于PDP的客观评价标准,无需主观测试便可以很好的比较各种JND模型的准确性和效率

















 4893
4893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









