






数据库环境:5.7.16 InnoDB 存储引擎下
单表数据70多万
in语句
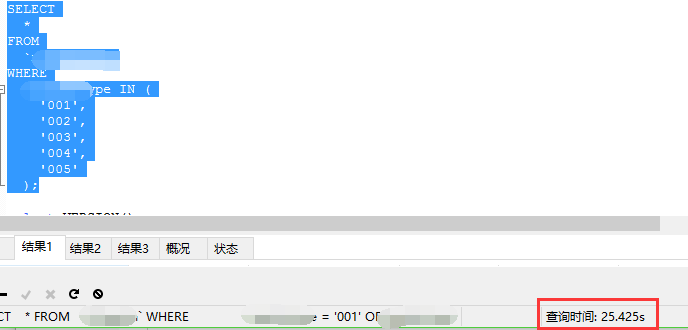
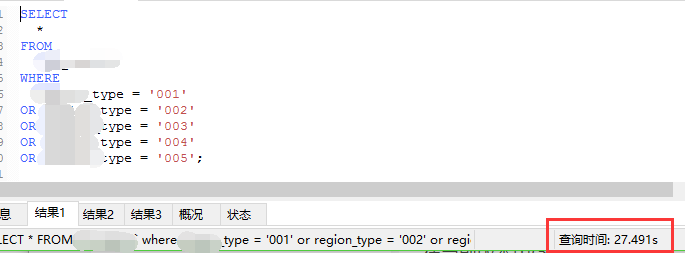
对比可以看出,数据量较小的情况下,效率相差无几
数据量较大的时候,in 效率平稳降低,or 急剧降低 (暂无大量数据测试)
in,exists执行原理介绍:
先来看个例子,下面代码1和代码2哪个的执行效率高(只是把循环次数的位置调换了一下):
代码1:
for(i=1; i<100; i++)
{
for(j=1; j<10000; j++)
{
call fun(); // 调用函数
}
}
代码2:
for(i=1; i<10000; i++)
{
for(j=1; j<100; j++)
{
call fun(); // 调用函数
}
}
都执行相同的循环次数。难道效率不是一样的吗?其实不然,代码1要优于代码2。原因如下:
虽然在函数的调用上没有区别,便在变量【i】,【j】运算上效率却是不同的。
代码1中【i】为赋值了100次,而【j】被赋值了100*10000次。
代码2中【i】为赋值了10000次,而【j】被赋值了100*10000次。
说上面的原理的目的在于引入in和exists执行机制。
我们假设i循环代表了外表也就是之前提到的A表,而j循环代表了内表,也就是之前提到的B表。
【in】相当于先选择j循环(内表,B表),后执行i循环(外表,A表);
【exist】相当于先选择i循环(外表,A表),后执行j循环(内表,B表);
结合上述的理论,推出以下结论:
1. 如果A表记录条数多于B表,则选择为in效率更高;
2. 如果A表记录条数少于B表,则选择为exists效率更高;















 1107
1107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









