








一. 数据堆叠与拆堆
在分类汇总数据中,stack()和unstack()是进行层次化索引的重要操作。层次化索引就是对索引进行层次化分类,包含行索引、列索引。
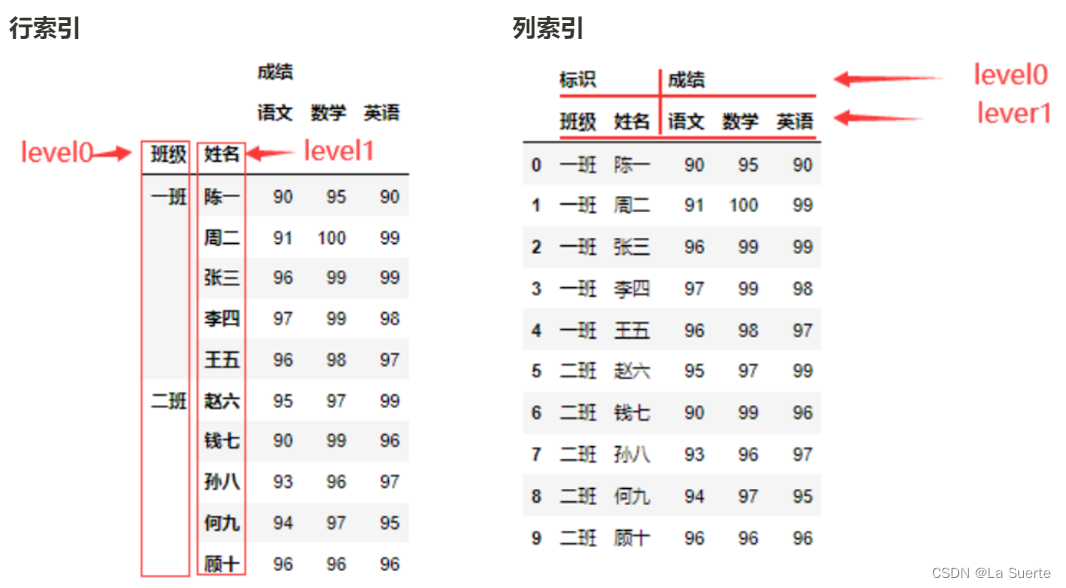
常见的数据层次化结构包括横表与纵表。横表在行列方向上均有索引,纵表只有列方向上的索引。
- stack:将数据从横表变成纵表,即将其列索引变成行索引。
- unstack:数据从纵表变成横表,即要将其中一层的行索引变成列索引。
如果是多层索引(multiindex),则以上函数是针对内层索引,利用 level参数可以选择具体哪层索引。
- stack:level等于哪一个,哪一个就消失,出现在行里。
- unstack:level等于哪一个,哪一个就消失,出现在列里。
1)数据堆叠(stack)
(a)简介
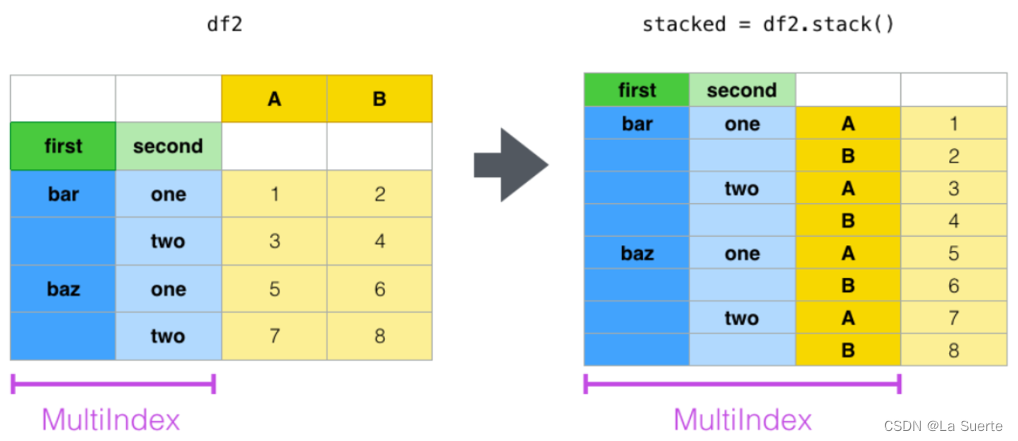
堆叠stack指将列的数据堆叠形成行。stack的计算机术语是“栈”,那么应用到DataFrame上,可以理解为将所有的列全部进行“入栈”操作(push)。
如图所示,将DataFrame的A列与B列全部入栈,就是挨着把这些列一个个的压进去,数据矩阵由4x2变成了8x1,这样的stack压缩操作带来的效果是:
- 由列变成了行:['A','B']这些列的数据,一个个堆叠形成一条记录的两行。这样列数减少了,行数增多了。
- 数据由原来的“宽格式”变成了“厚格式”:全部的列宽度都压缩到了行厚度上面,全部的列名称组成了一个新的索引列。
(b)代码
举例数据

数据堆叠
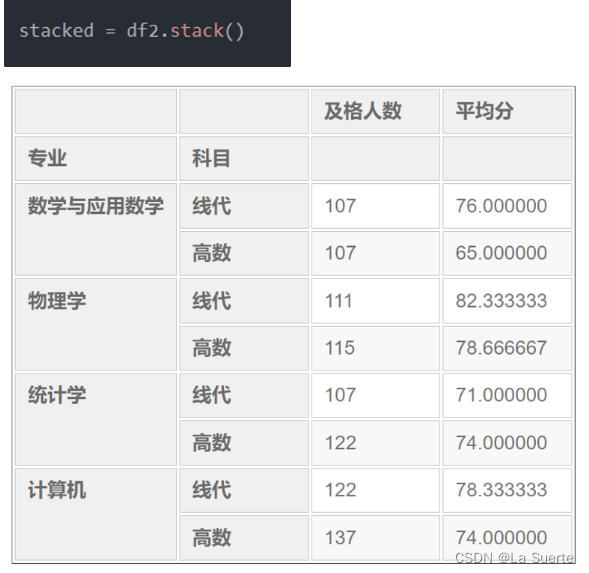
2)数据拆堆(unstack)
(a)简介
拆堆unstack是stack的逆操作,指将堆叠好了的行数据卸下来形成列。可以理解为出栈把“栈”里面的数据全部弹出来(pop)。
如图所示,将DataFrame的A行与B行拆成两列,数据矩阵由8x1变成了4x2,这样的unstack解压操作带来的效果刚好和stack相反:
- 由行变成了列:索引列里面的每行数据,全部都变成了单独的一列。这样行数减少了,列数增多了。
- 数据由原来的“厚格式”变成了“宽格式”:也即全部的行厚度都释放到了列宽度上面,索引列中的全部成员都被分解成了单独的一列。

(b)代码
对于多层索引逐层拆堆(所用举例数据同stack部分)
level 1:拆科目
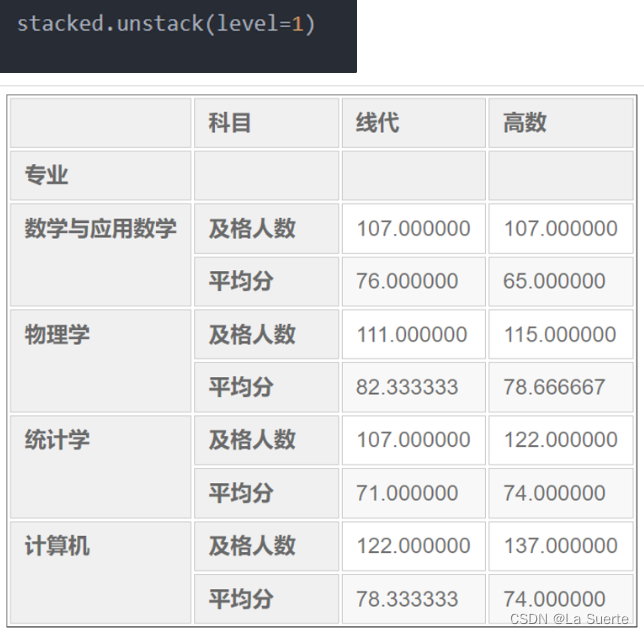
level 0:拆专业

二. 数据融合与透视
数据融合与透视是最常用的数据汇总工具,可以根据一个或者多个指定的维度来聚合数据。实际上melt和pivot分别是stack和unstack的快捷方式。stack和unstack根据索引来进行堆叠和拆堆,而pivot和melt可以根据指定的数据来进行变换操作灵活性更高。
1)数据透视(pivot)
(a)简介
pivot与unstack类似,同样是将行数据转换成列。
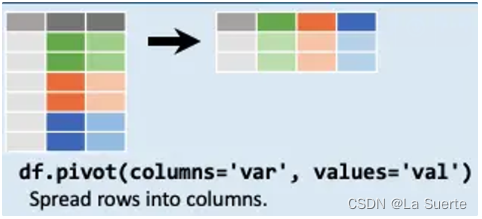
两者之间的区别在于pivot:
1.更方便的处理没有索引列的dataframe
根据前文的介绍,unstack操作的效果是:索引列中的全部成员都被分解成了单独的一列。所以unstack操作一般要求要有索引列。但是有些DataFrame是没有明显的索引列的(如下图)
因此如果使用unstack需要两个步骤:先设置索引,再将目标索引列解压。而pivot则可以更快捷的实现。pivot本质上就是Pandas设定的unstack的快捷方式,并不是一种新的重塑方法。

2.提供更多的参数可以指定相应的数据进行转换,比unstack更加灵活。参数包括索引(index)、列(column)与值(values)。三个参数作用分别是:
- index:新 df 的索引列,用于分组,如果为None,则使用现有索引
- columns:新 df 的列,如果透视后有重复值会报错
- values:用于填充 df 的列。 如果未指定,将使用所有剩余的列,并且结果将具有按层次结构索引的列

(b)代码
举例数据

使用df.pivot以姓名为index,以各科目为columns,来统计各科成绩

2)数据融合(melt)
(a)简介
melt与stack类似,同样是将列数据转换成行。

两者区别与上文pivot与unstack类似,melt可以:
1.更方便的处理没有索引列的dataframe,因此解决stack默认会把所有的列都做压缩操作的问题。melt本质上就是Pandas设定的stack的快捷方式。
2.提供了更多的参数可以指定相应的数据进行转换(指定哪些列固定,哪些列转换成行等),比stack更加灵活。简单来说,就是将指定的列铺开放到行上,名放在variable索引列,值放在value索引列。
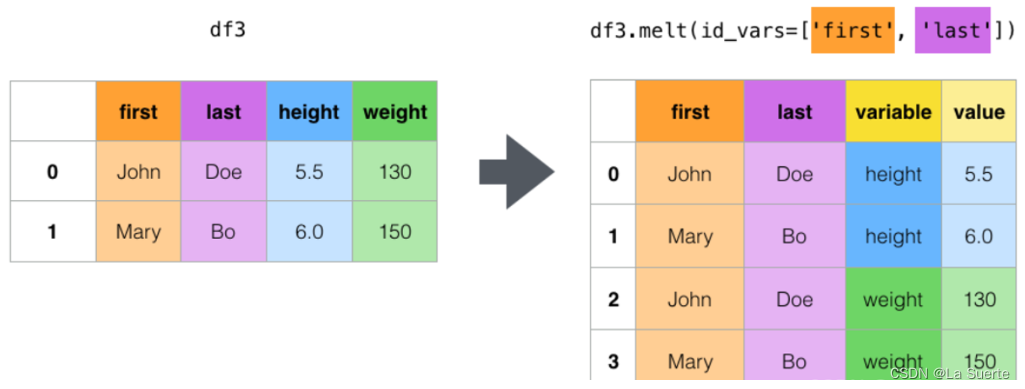
(b)代码
举例数据

使用df.melt以姓名为标识变量的列id_vars,以各科目为value_vars,来统计各科成绩

3)数据透视表(pivot_table)
(a)简介
Excel中有一个强大的功能:数据透视表。典型的数据格式是扁平的,只包含行和列,不方便总结信息。而数据透视表可以快速的进行分类汇总,自由组合字段快速计算,从而快速抽取有用的信息。在Pandas中,可以利用pivot table函数实现该功能。
pivot的重点在于reshape, 它的作用其实就是对索引列“合并同类项”分组(类似group by),所以在行与列的交叉点值的索引应该是唯一值。下图描述了这个数据合并迁移的过程,它是按目标索引列的值['item0,'item1']进行“同类项”合并的。
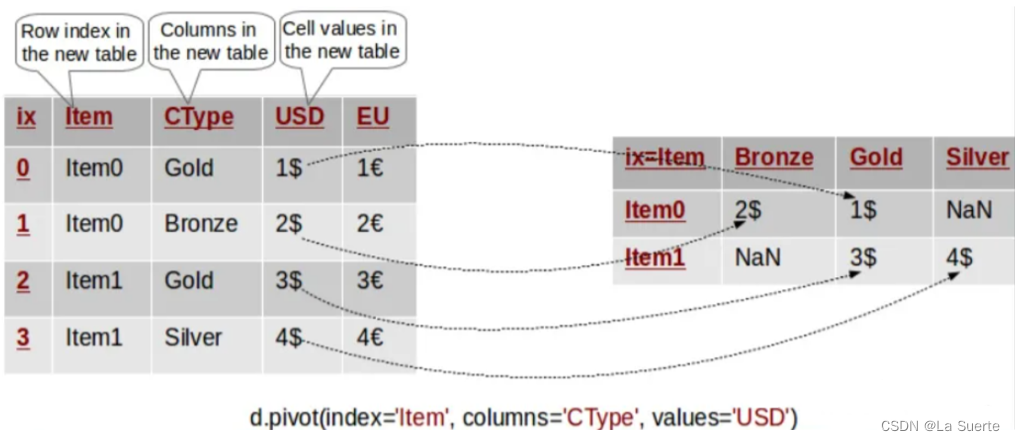
但是,这种合并方法在遇到“index+columns”组合有重复数据时,显得无能为力。如果不是唯一值,即原始数据集中存在重复条目,此时pivot函数无法确定数据透视表中的数值。如果这时要强行使用pivot会报错失败:ValueError: Index contains duplicate entries, cannot reshape。
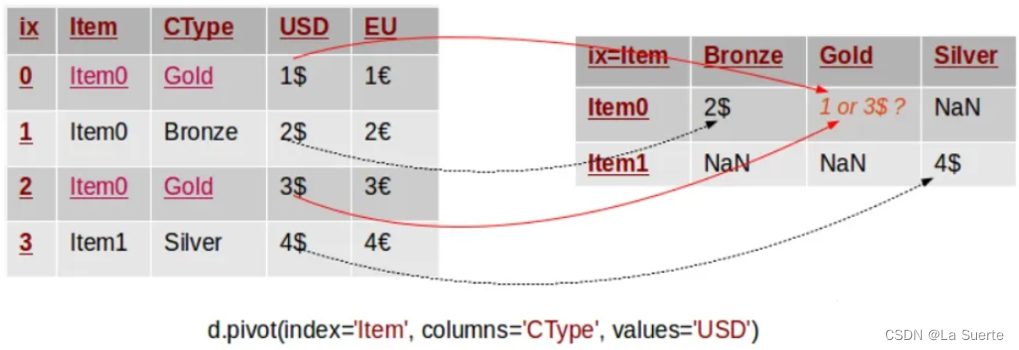
而pivot_table可以用聚合功能来解决这个问题:默认取平均数(还可以取最小值)
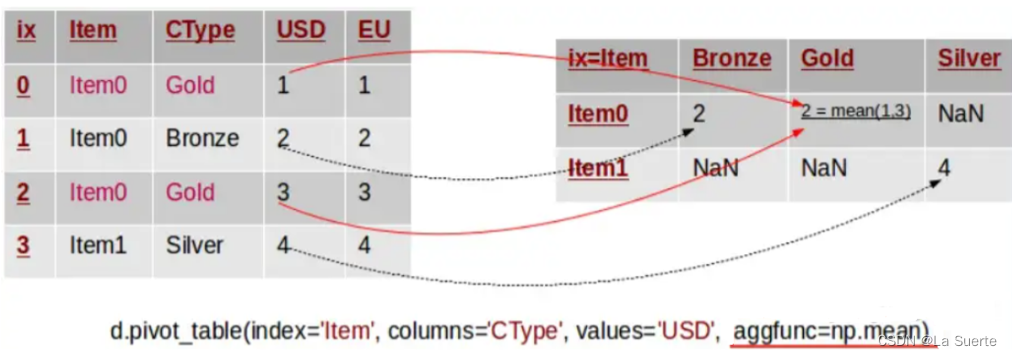
因此,pivot_table除了重塑以外,它还有一个聚合的功能,这是它和pivot最大的区别。因此,pivot_table通常用于数字类型的数据透视,而pivot通常用于非数字类型。
(b)代码
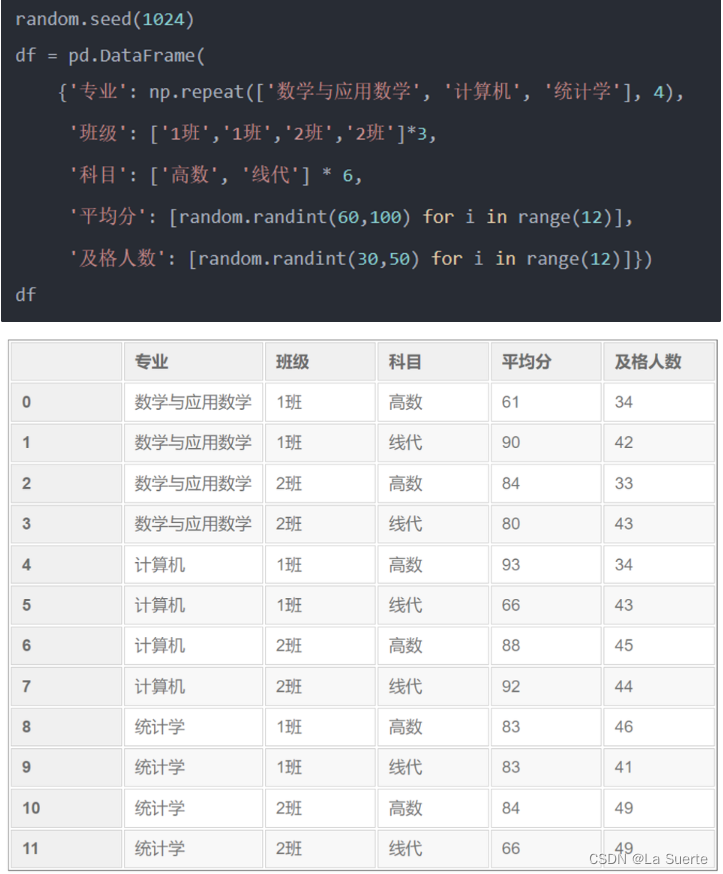
举例数据
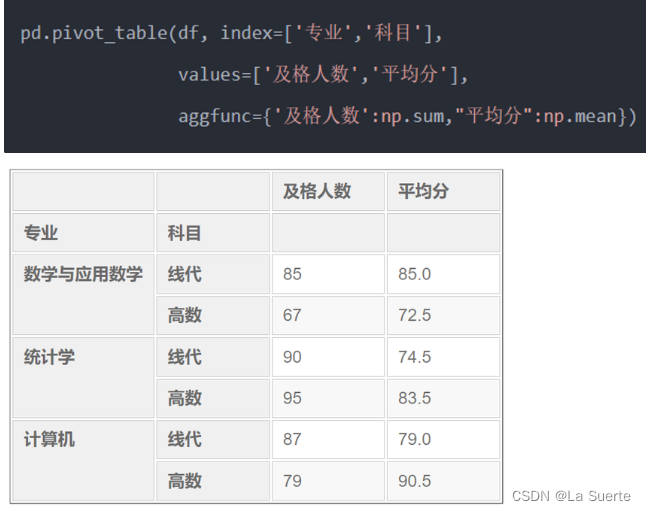
各个专业对应科目的及格人数和平均分的数据透视表:
(c)pivot与pivot table区别总结
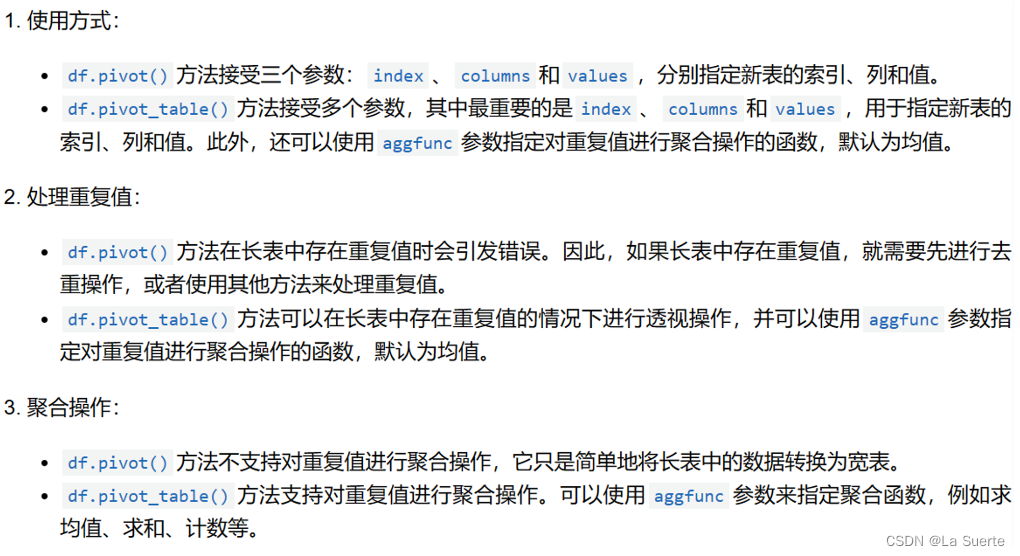
总的来说,pivot适用于长表中不存在重复值的情况,而pivot_table()适用于长表中存在重复值的情况,并且可以对重复值进行聚合操作。
再补充一个方法:
4)数据交叉表(crosstab)
(a)简介
数据交叉表显示了每个变量的不同类别组合中观察到的频率或计数。通俗地说,就是根据不同列的数据统计了频数,从而洞察数据中的模式和趋势。
它与pivot_table函数非常相似。当输入数据不是数据帧格式而是数组、列表或系列的形式时,首选使用 crosstab函数。该函数用于返回以数据帧格式交叉制表的数据。
(b)代码
i. 单层crosstab
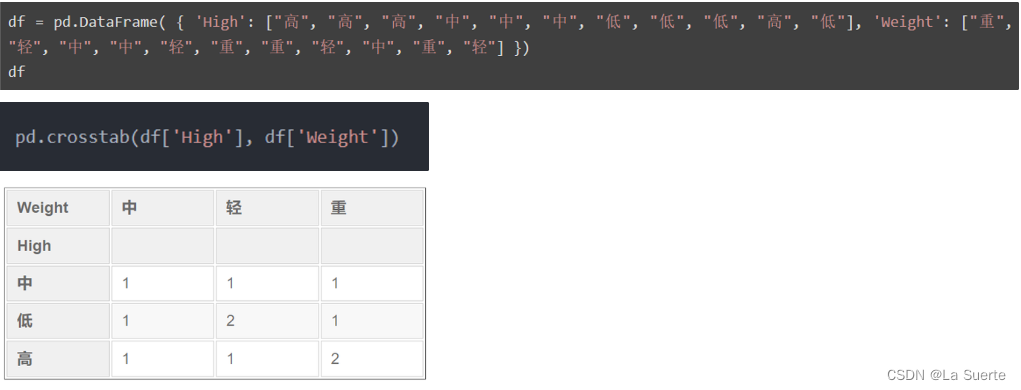
ii. 双层crosstab

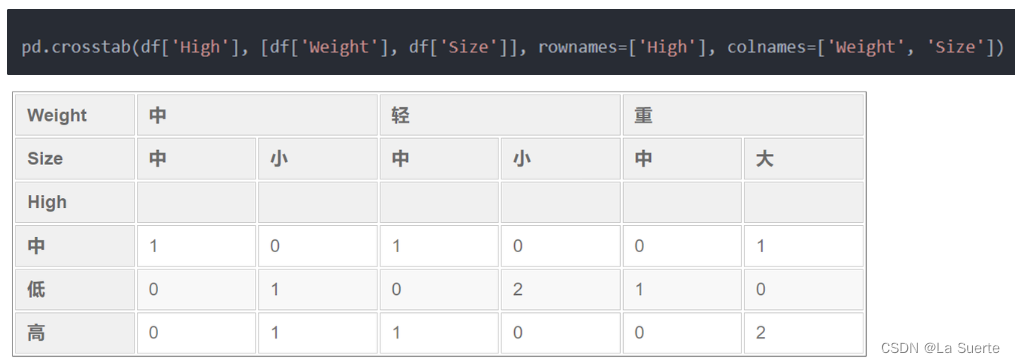
(c)crosstab与pivot table区别总结

下一期:Pandas文本与时间数据,Bye!















 1709
1709











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









