








一. 文本数据简介
1)定义
指不能参与算术运算的任何字符,也称为字符型数据。如英文字母、汉字、不作为数值使用的数字(以单引号开头)和其他可输入的字符。
文本数据虽不能参加算术运算,但其具有纬度高、量大且语义复杂等特点,因此在进行数据分析的时候需要重视这类型数据。
2)类型
Pandas用来代表文本数据类型主要有两种:string和object。object一般为NumPy的数组,string为最常规的文本数据。
最常用的还是使用string来存储文本文件,但是使用dataframe和series进行数据处理转换的时候object数据类型又用的多。
在Pandas1.0版本之前只有object类型,这会导致字符数据和非字符数据全部都以object方式存储,导致处理混乱。而后续版本优化加入了String更好的区分了处理文本数据的耦合问题。目前的object类型依旧是文本数据和数组类型的string数据,但是Pandas为了后续的兼容性依旧将object类型设为默认的文本数据存储类型。
根据MBA智库百科,string与object之间有三大区别:
- 字符存取方法(string accessor methods)string会返回相应数据的Nullable类型,object会随缺失值的存在而改变返回类型。
- 某些Series方法不能在string上使用。例如: Series.str.decode(),因为存储的是字符串而不是字节
- string类型在缺失值存储或运算时,类型会广播为pd.NA,而不是浮点型np.nan。
二. 字符操作
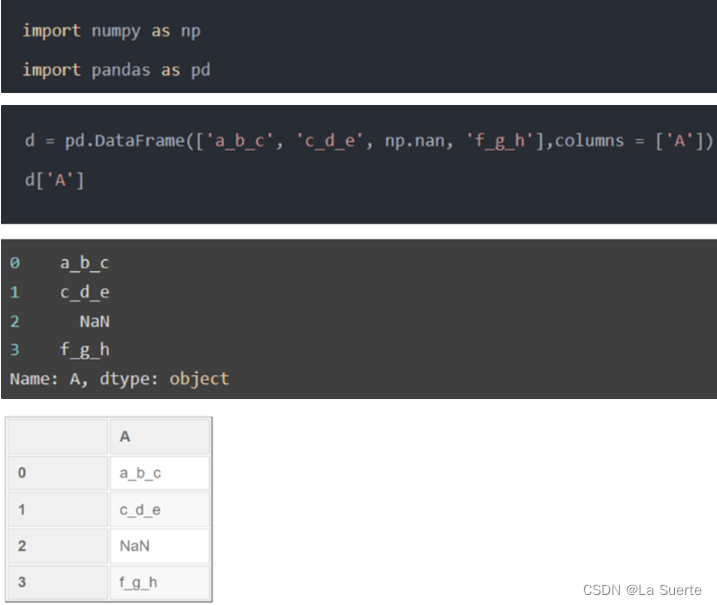
0)举例数据
1)大小写变换
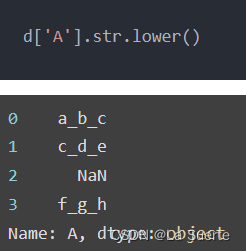
(a)lower():全部小写
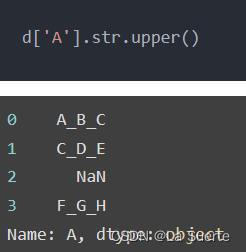
(b)upper():全部大写
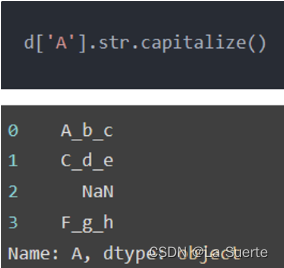
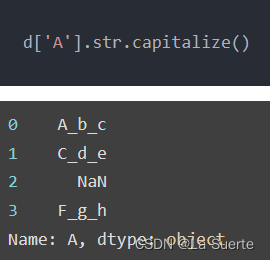
(c)capitalize():首字符大写
(d)swapcase():大小写互换
2)文本对齐
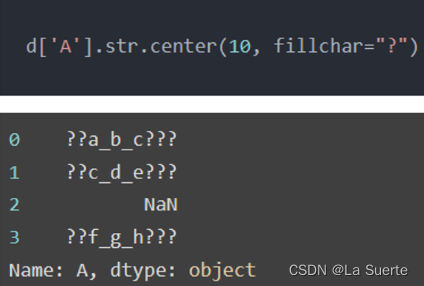
(a)center():中间补齐
#居中对齐,宽度为10,其余用’?’填充
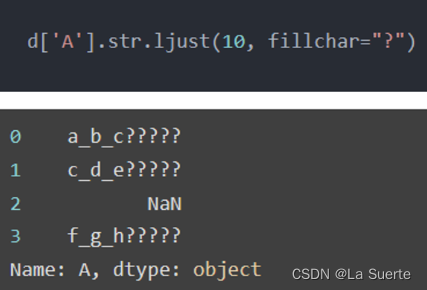
(b)ljust():右边补齐
#右对齐,宽度为10,其余用’?’填充
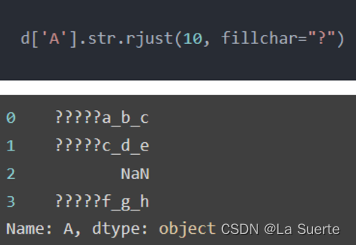
(c)rjust():左边补齐
#左对齐,宽度为10,其余用’?’填充
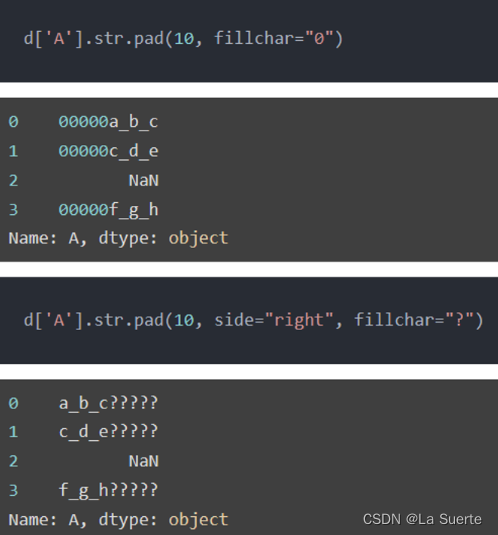
(d)pad():左右补齐
#自定义对齐方式,参数可调整宽度、对齐方向、填充字符
3)文本计数
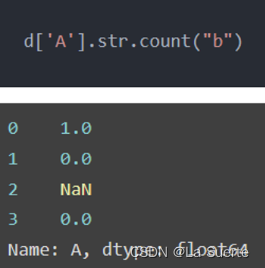
(a)count():计算给定单词出现的次数
#计算字符串内b的数量
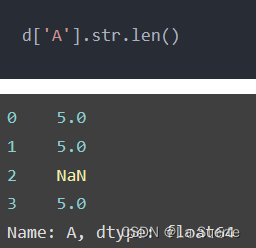
(b)len():计算字符串的长度
4)格式判断
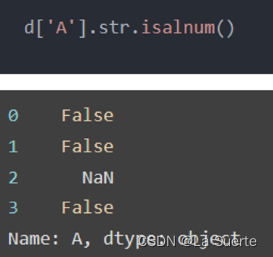
(a)isalnum():是否全部是数字和字母组成
(b)isalpha():是否全部是字母
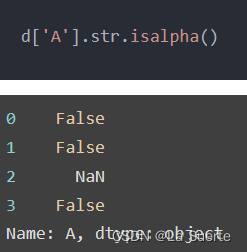
(c)isdigit():是否全部都是数字
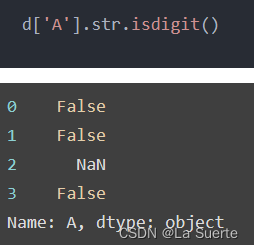
(d)isspace():是否空格
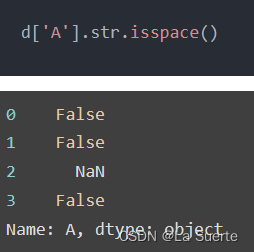
(e)islower():是否全部小写

(f)isupper():是否全部大写
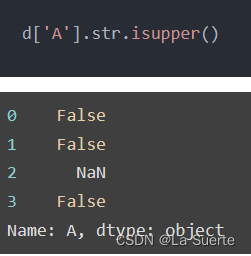
(g)istitle():是否只有首字母为大写,其他字母为小写
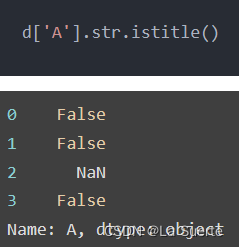
(h)isnumeric():是否是数字
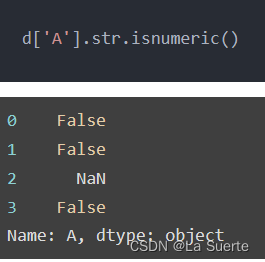
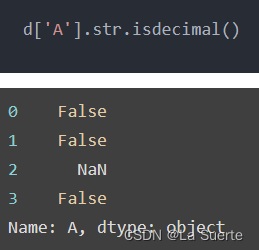
(i)isdecimal():是否全是数字
三. 文本高级处理
1)文本拆分与切片
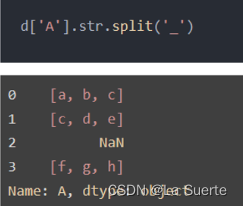
(a)split():切分字符串
按照某个指定的字符作为分割点拆分文本,对文本分隔后会生成一个列表。使用expand参数还可以将分隔内容展开,形成单独的列,n参数可以指定拆分的位置来控制形成几列。
![]()
下例以下划线对内容进行了分隔,分隔后每个内容都成为一个列表。分隔对空值不起作用。
(b)slice():按给定点的开始结束位置切割字符串
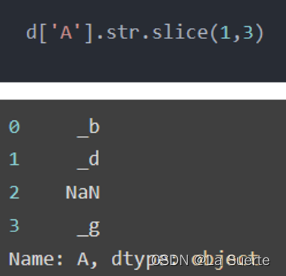
其他例子

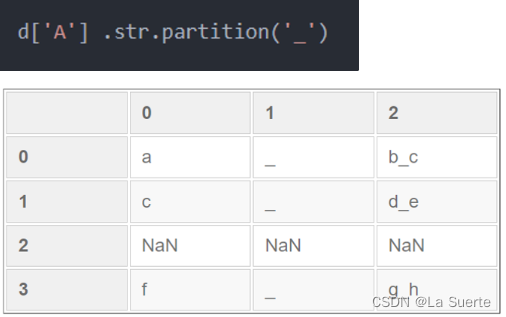
(c)partition():把字符串数组切割成为DataFrame
注意切割只是切割成三部分,分隔符前,分隔符,分隔符后
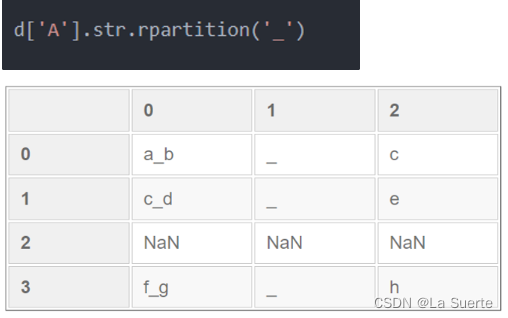
(d)rpartition():从右切起
2)文本替换
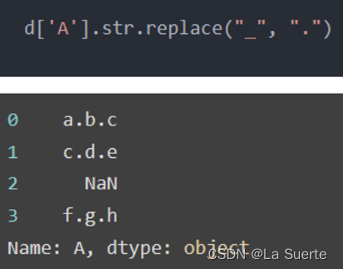
(a)replace():替换不想要的内容
replace是最常用的替换方法,参数包括:
- pal:为被替代的内容字符串,也可以为正则表达式
- repl:为新内容字符串,也可以是一个被调用的函数
- regex:用于设置是否支持正则,默认是True
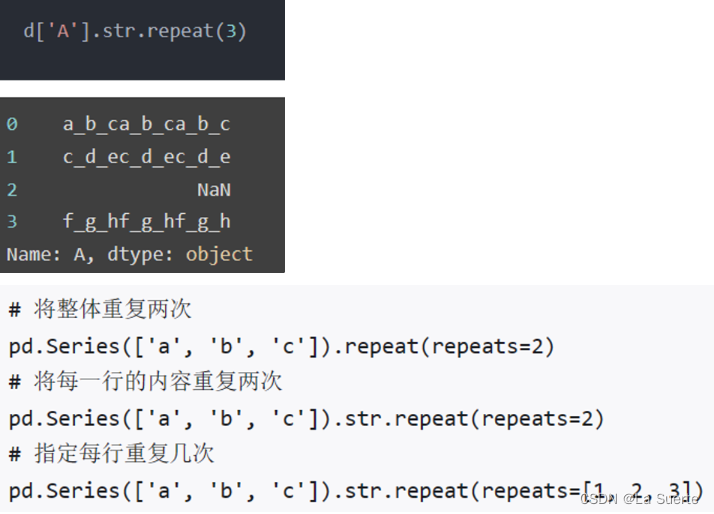
(b)repeat():让原有文本内容重复
repeat可以实现重复替换的功能,参数repeats设置重复的次数。
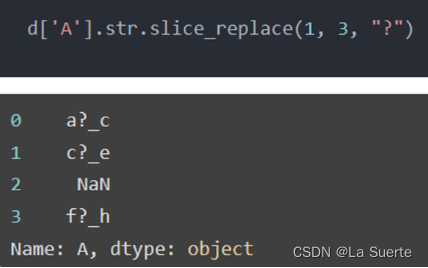
(c)slice_replace():使用给定的字符串,替换指定的位置的字符
slice_replace通过切片可以保留或者删除指定的字符,参数如下:
- start:起始位置
- stop:结束位置
- repl:要替换用的新内容
如果没有设置stop,那么start之后全部进行替换;同理如果没设置start,那么stop之前全部进行替换。
3)文本拼接
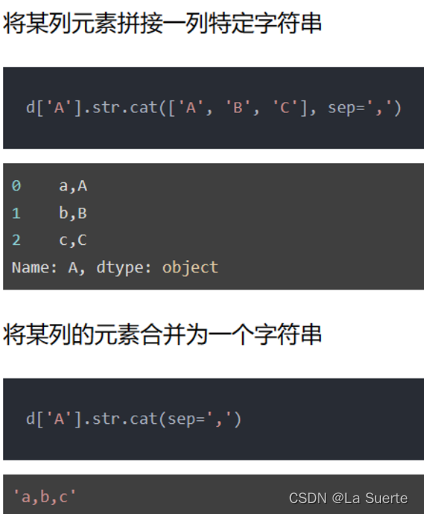
(a)cat():拼接字符串
cat可以拼接字符串,参数如下:
- others: 需要拼接的序列,如果为None不设置,就会自动把当前序列拼接为一个字符串
- sep: 拼接用的分隔符
- na_rep: 默认不对空值处理,这里设置空值的替换字符。
- join: 拼接的方向,包括left, right, outer, inner,默认为left
(b)join():对每个字符都用给定的字符串拼接起来(不常用)
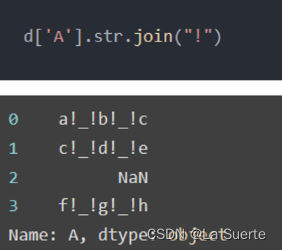
4)文本提取
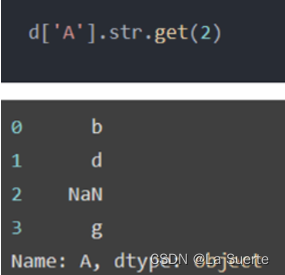
(a)get():获取指定位置的字符串
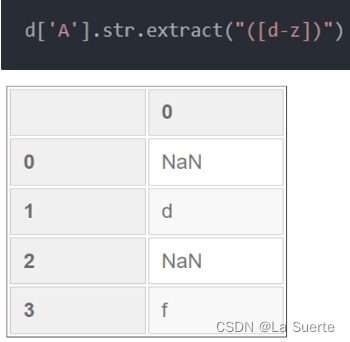
(b)extract():抽取匹配的字符串出来
extract可以利用正则表达式将文本中的数据提取出来,形成单独的列(注意要加上括号,把你需要抽取的东西标注上)参数如下:
- pat: 通过正则表达式实现一个提取的pattern
- flags: 正则库re中的标识,比如re.IGNORECASE
- expand: 当正则只提取一个内容时,如果expand=True会展开返回一个DataFrame,否则返回一个Series
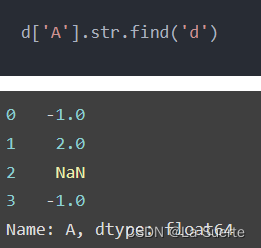
5)文本查询
(a)find():从左边开始,查找给定字符串的所在位置
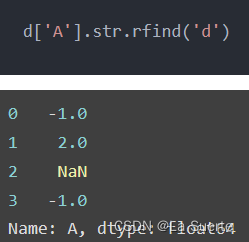
(b)rfind():从右边开始,查找给定字符串的所在位置
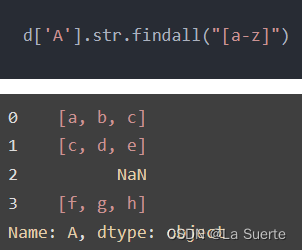
(c)findall():查找所有符合正则表达式的字符,以数组形式返回
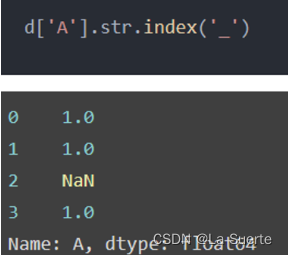
(d)index():查找给定字符串的位置
注意,如果不存在这个字符串,那么会报错!
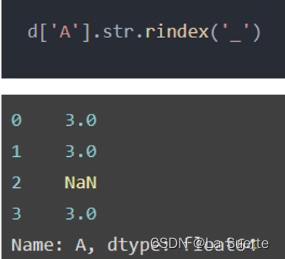
(e)rindex():从右边开始查找,给定字符串的位置
6)文本包含
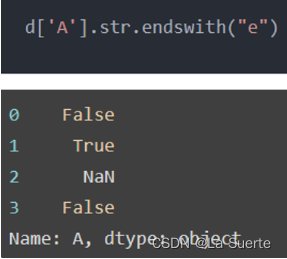
(a)contains():是否包含表达式(很常用)
文本包含通过contains方法实现,返回布尔值,一般和loc查询功能配合使用,参数如下:
- pat: 匹配字符串,支持正则表达式
- case: 是否区分大小写,True表示区别
- flags: 正则库re中的标识,比如re.IGNORECASE
- na: 对缺失值填充
- regex: 是否支持正则,默认True支持

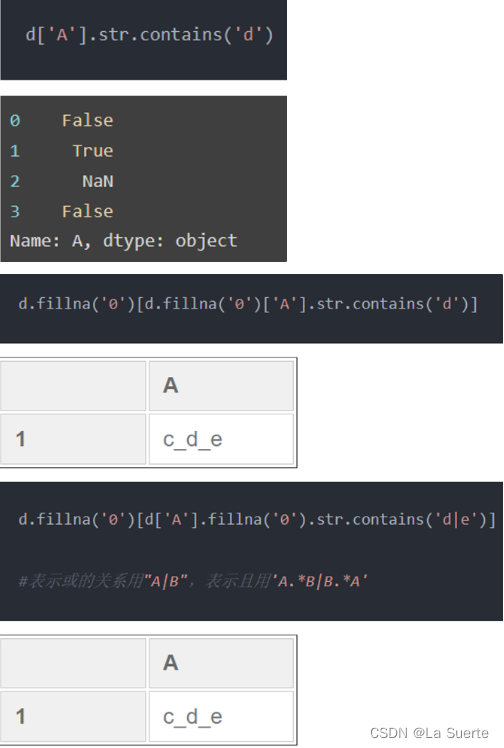
(b)match():检测是否全部匹配给点的字符串或者表达式
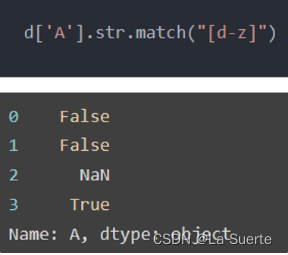
(c)startswith():判断是否以给定的字符串开头
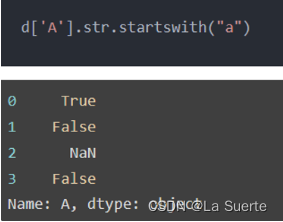
(d)endswith():判断是否以给定的字符串结束
7)去除空格
(a)strip():去除前后的空白字符
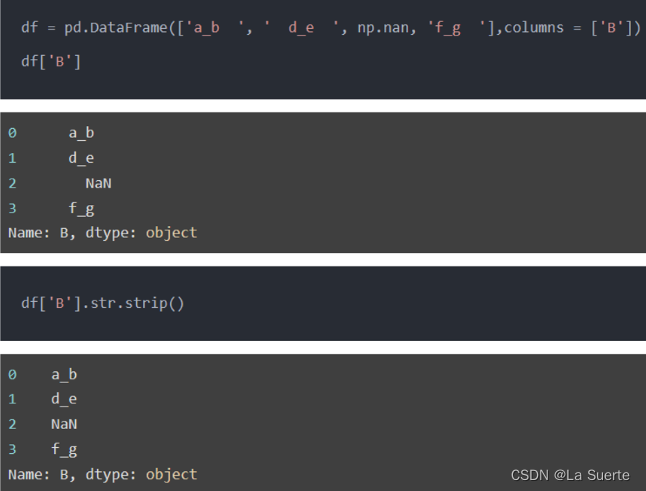
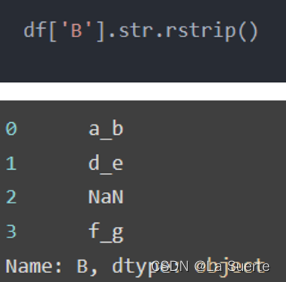
(b)rstrip():去除后面的空白字符
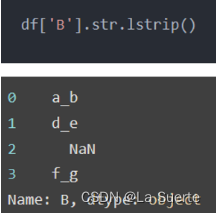
(c)Istrip():去除前面的空白字符
下一期:Pandas时间数据,Bye!















 1340
1340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









