







一、需求描述
1、自然语言来描述
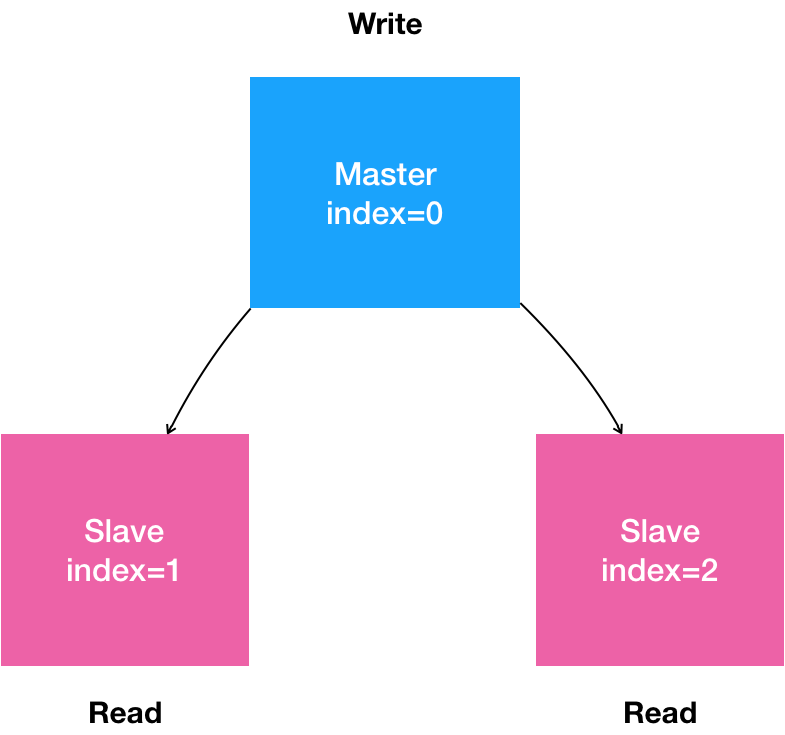
是一个“主从复制”(Maser-Slave Replication)的 MySQL 集群;
有 1 个主节点(Master);
有多个从节点(Slave);
从节点需要能水平扩展;
所有的写操作,只能在主节点上执行;
读操作可以在所有节点上执行。
2、图形描述
二、需求分析
1、通过 XtraBackup 将 Master 节点的数据备份到指定目录。
$ cat xtrabackup_binlog_info
TheMaster-bin.000001 481

2、配置 Slave 节点
Slave 节点在第一次启动前,需要先把 Master 节点的备份数据,连同备份信息文件,一起拷贝到自己的数据目录(/var/lib/mysql)下。然后,我们执行这样一句 SQL:
TheSlave|mysql> CHANGE MASTER TO
MASTER_HOST='$masterip',
MASTER_USER='xxx',
MASTER_PASSWORD='xxx',
MASTER_LOG_FILE='TheMaster-bin.000001',
MASTER_LOG_POS=481;

3、启动 Slave 节点
TheSlave|mysql> START SLAVE;
这样,Slave 节点就启动了。它会使用备份信息文件中的二进制日志文件和偏移量,与主节点进行数据同步。
4、在这个集群中添加更多的 Slave 节点
需要注意的是,新添加的 Slave 节点的备份数据,来自于已经存在的 Slave 节点

通过上面的叙述,我们不难看到,将部署 MySQL 集群的流程迁移到 Kubernetes 项目上,需要能够“容器化”地解决下面的“三座大山”:
Master 节点和 Slave 节点需要有不同的配置文件(即:不同的 my.cnf);
Master 节点和 Salve 节点需要能够传输备份信息文件;
在 Slave 节点第一次启动之前,需要执行一些初始化 SQL 操作;
三、第一座大山:Master 节点和 Slave 节点需要有不同的配置文件
1、思路

2、MySQL 的配置文件
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql
labels:
app: mysql
data:
master.cnf: |
# 主节点MySQL的配置文件
[mysqld]
log-bin
slave.cnf: |
# 从节点MySQL的配置文件
[mysqld]
super-read-only
在这里,我们定义了 master.cnf 和 slave.cnf 两个 MySQL 的配置文件。

3、ConfigMap

4、两个 Service 定义
接下来,我们需要创建两个 Service 来供 StatefulSet 以及用户使用。这两个 Service 的定义如下所示:
apiVersion: v1
kind: Service
metadata:
name: mysql
labels:
app: mysql
spec:
ports:
- name: mysql
port: 3306
clusterIP: None
selector:
app: mysql
---
apiVersion: v1
kind: Service
metadata:
name: mysql-read
labels:
app: mysql
spec:
ports:
- name: mysql
port: 3306
selector:
app: mysql
1、可以看到

2、不同点

3、读写分离
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1226
1226











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









