







介绍
参考资料:
KNeighborsClassifiers
https://wenku.baidu.com/view/94aea4e8d15abe23482f4d5b.html
https://www.jianshu.com/p/871884bb4a75
泰坦尼克号生存预测 (Logistic and KNN)
数据集介绍

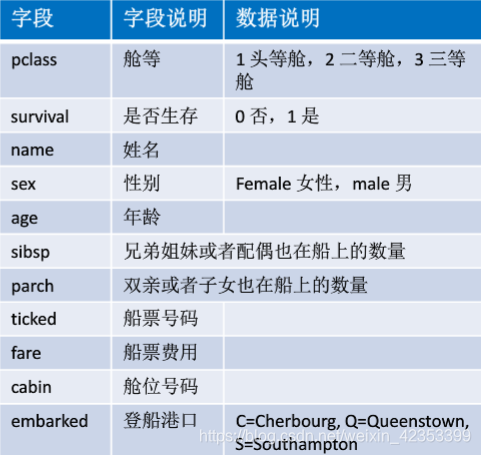
boat(船),body(身体),home(家庭地址)看起来没什么用,删去。
算法
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
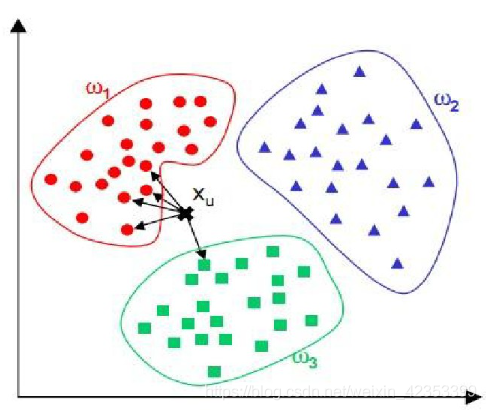
图中判定xu属于w1类。

学习器
假设x是训练样本,共有n个训练样本,每个样本有m维特征,y为训练样本的对应的类别(假设是二分类,只有w0和w1),a是一个未知样本。
d
i
s
t
i
表
示
a
到
训
练
样
本
x
i
的
距
离
;
dist_i表示a到训练样本x_i的距离;
disti表示a到训练样本xi的距离;
1、初始化
d
i
s
t
i
=
+
∞
,
i
=
1
,
2
,
3
,
.
.
.
n
dist_i = +\infty, i=1,2,3,...n
disti=+∞,i=1,2,3,...n
2、计算 a到各个样本的距离
d
i
s
t
i
=
f
(
a
,
x
i
)
,
i
=
1
,
.
.
.
n
;
f
(
a
,
b
)
为
计
算
a
,
b
的
距
离
函
数
。
dist_i = f(a,x_i), i=1,...n; f(a,b)为计算a,b的距离函数。
disti=f(a,xi),i=1,...n;f(a,b)为计算a,b的距离函数。
3、找到前k个离a最近的x,
x
j
,
j
为
使
d
i
s
t
i
由
小
到
大
排
序
的
前
k
个
i
x_j, j为使dist_i由小到大排序的前k个i
xj,j为使disti由小到大排序的前k个i
分类器
分为两类:w0和w1。
y
预
测
=
{
w
0
,
i
f
x
j
属
于
w
0
的
个
数
多
于
x
j
属
于
w
1
的
个
数
w
1
,
o
t
h
e
r
w
i
s
e
y_{预测}=\begin{cases} w_0, & {if\ \ x_j属于w_0的个数多于x_j属于w_1的个数} \\ w_1, & {otherwise} \end{cases}
y预测={w0,w1,if xj属于w0的个数多于xj属于w1的个数otherwise
实现
数据下载与导入
#获取数据
data_url="http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic3.xls"#下载网址
data_file_path="data/titanic3.xls"
if not os.path.isfile(data_file_path):
result=urllib.request.urlretrieve(data_url,data_file_path)
print('downloaded',result)
else:
print(data_file_path,'data file already exists.')
df_data=pd.read_excel(data_file_path)#读excel
selected_cols=['survived','name','pclass','sex','age','sibsp','parch','fare','embarked']#挑出需要的列
selected_df_data=df_data[selected_cols]
预处理
数据有缺失,需要估计填补(目前以平均值填补)。
文字数据需要转化为数字。
所有变量都要归一化处理。
#数据处理
def prepare_data(df_data):
df=df_data.drop(['name'],axis=1)#名字训练时不需要,去掉
age_mean=df['age'].mean()
df['age']=df['age'].fillna(age_mean)#缺失的年龄以平均值填充
fare_mean=df['fare'].mean()
df['fare']=df['fare'].fillna(fare_mean)#缺失的票价以平均值填充
df['sex']=df['sex'].map({'female':0,'male':1}).astype(int)#文字转化为数字表示
df['embarked']=df['embarked'].fillna('S')#缺失值用最多的值取代
df['embarked']=df['embarked'].map({'C':0,'Q':1,'S':2}).astype(int)#文字转化为数字表示
ndarray_data=df.values
features=ndarray_data[:,1:]#没有生存情况
label=ndarray_data[:,0]#生存情况
minmax_scale=preprocessing.MinMaxScaler(feature_range=(0,1))
norm_features=minmax_scale.fit_transform(features)#归一化
return norm_features,label
shuffled_df_data=selected_df_data.sample(frac=1)#打乱顺序
x_data,y_data=prepare_data(shuffled_df_data)
train_size=int(len(x_data)*0.8)#80%的数据训练,20%的数据测试
x_train=x_data[:train_size]#训练数集
y_train=y_data[:train_size]
x_test=x_data[train_size:]#测试数集
y_test=y_data[train_size:]
建立模型
KNeighborsClassifier基于k个查询点的最近邻居,其中k是用户指定的整数值。 RadiusNeighborsClassifier根据固定半径内的邻居数量实现学习r每个训练点的位置r是用户指定的浮点值。
class sklearn.neighbors.KNeighborsClassifier(
n_neighbors=5(选取最近的点的个数),
weights=’uniform’(预测使用的权重函数,uniform 所有的点具有相同的权重),
algorithm=’auto’(计算最临近点的距离,‘auto’ 根据传递给fit的数据自动决定使用最合适的算法),
leaf_size=30(会影响构建和查询的速度以及保存树的内存,最优值取决于问题),
p=2(闵科夫斯基距离的指数,p=2,等价于欧式距离),
metric=’minkowski’(这个距离用于树),
metric_params=None(为度量增加的关键字参数),
n_jobs=1(临近点搜索的线程数),
**kwargs)
fit(x,y):使用x作为训练数据,y作为目标值(类似于标签)来拟合模型。
#创建KNN模型(K邻近回归器)
Classifier3 = KNeighborsClassifier(n_neighbors=5)
Classifier3.fit(x_train,y_train)
评估,预测
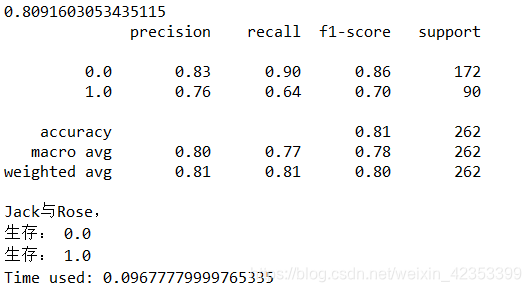
评估:
#模型评估
score_Knn = Classifier3.score(x_test,y_test)
print(score_Knn)
from sklearn.metrics import classification_report
y_pre=Classifier3.predict(x_test)
print(classification_report(y_test,y_pre))
预测:
#加入Jack和Rose
Jack_infor=[0,'Jack',3,'male',23,1,0,5.000,'S']
Rose_infor=[1,'Rose',1,'female',20,1,0,100.000,'S']
new_passenger_pd=pd.DataFrame([Jack_infor,Rose_infor],columns=selected_cols)#创建新旅客的表单
all_passenger_pd=selected_df_data.append(new_passenger_pd)#与旧的合成
x,y=prepare_data(all_passenger_pd)
y_pre=Classifier3.predict(x[-2:,:])
print("Jack与Rose,")
for i in range(len(y_pre)):
print("生存:",y_pre[i])
结果

代码
import numpy as np
import pandas as pd
import re
import os
import matplotlib.pyplot as plt
from sklearn import preprocessing
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from itertools import product
import seaborn as sns
import time
start = time.clock()
#获取数据
data_url="http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic3.xls"#下载网址
data_file_path="data/titanic3.xls"
if not os.path.isfile(data_file_path):
result=urllib.request.urlretrieve(data_url,data_file_path)
print('downloaded',result)
else:
print(data_file_path,'data file already exists.')
df_data=pd.read_excel(data_file_path)#读excel
selected_cols=['survived','name','pclass','sex','age','sibsp','parch','fare','embarked']#挑出需要的列
selected_df_data=df_data[selected_cols]
#数据处理
def prepare_data(df_data):
df=df_data.drop(['name'],axis=1)#名字训练时不需要,去掉
age_mean=df['age'].mean()
df['age']=df['age'].fillna(age_mean)#缺失的年龄以平均值填充
fare_mean=df['fare'].mean()
df['fare']=df['fare'].fillna(fare_mean)#缺失的票价以平均值填充
df['sex']=df['sex'].map({'female':0,'male':1}).astype(int)#文字转化为数字表示
df['embarked']=df['embarked'].fillna('S')#缺失值用最多的值取代
df['embarked']=df['embarked'].map({'C':0,'Q':1,'S':2}).astype(int)#文字转化为数字表示
ndarray_data=df.values
features=ndarray_data[:,1:]#没有生存情况
label=ndarray_data[:,0]#生存情况
minmax_scale=preprocessing.MinMaxScaler(feature_range=(0,1))
norm_features=minmax_scale.fit_transform(features)#归一化
return norm_features,label
shuffled_df_data=selected_df_data.sample(frac=1)#打乱顺序
x_data,y_data=prepare_data(shuffled_df_data)
train_size=int(len(x_data)*0.8)#80%的数据训练,20%的数据测试
x_train=x_data[:train_size]#训练数集
y_train=y_data[:train_size]
x_test=x_data[train_size:]#测试数集
y_test=y_data[train_size:]
'''
Classifier1 = LogisticRegression()
#训练模型
Classifier1.fit(x_train,y_train)
#预测
Y1_prediction = Classifier1.predict(x_test)
#模型评估
score_Logit = Classifier1.score(x_train,y_train)
score_Logit
Classifier1.coef_
'''
#创建KNN模型(K邻近回归器)
Classifier3 = KNeighborsClassifier(n_neighbors=5)
Classifier3.fit(x_train,y_train)
Y3_prediction = Classifier3.predict(x_test)
#模型评估
score_Knn = Classifier3.score(x_test,y_test)
print("自带模型评估:",score_Knn)
from sklearn.metrics import classification_report
y_pre=Classifier3.predict(x_test)
print(classification_report(y_test,y_pre))
#加入Jack和Rose
Jack_infor=[0,'Jack',3,'male',23,1,0,5.000,'S']
Rose_infor=[1,'Rose',1,'female',20,1,0,100.000,'S']
new_passenger_pd=pd.DataFrame([Jack_infor,Rose_infor],columns=selected_cols)#创建新旅客的表单
all_passenger_pd=selected_df_data.append(new_passenger_pd)#与旧的合成
x,y=prepare_data(all_passenger_pd)
y_pre=Classifier3.predict(x[-2:,:])
print("Jack与Rose,")
for i in range(len(y_pre)):
print("生存:",y_pre[i])
elapsed = (time.clock() - start)
print("Time used:",elapsed)














 865
865











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









