






 本文介绍如何在Elasticsearch中新增字段并实现批量更新记录的方法。内容涵盖使用REST API添加日期类型字段的过程,以及通过编写脚本进行数据批量更新的具体步骤。特别针对更新操作中的脚本语法进行了说明,并举例展示了更新请求体的构造方式。
本文介绍如何在Elasticsearch中新增字段并实现批量更新记录的方法。内容涵盖使用REST API添加日期类型字段的过程,以及通过编写脚本进行数据批量更新的具体步骤。特别针对更新操作中的脚本语法进行了说明,并举例展示了更新请求体的构造方式。
新增字段
PUT http://host/index名字/_mapping
{
"properties":{
"last_time_used":{"type" : "date"}
}
}
全部更新
参考:http://t.zoukankan.com/itBlogToYpl-p-13367859.html
https://www.zhihu.com/question/400814362/answer/1284775773
###
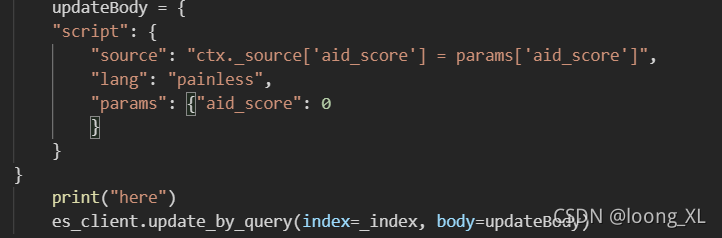
try:
updateBody = {
"script": {
"source": "ctx._source['字段名'] = params['字段名']",
## "source": "ctx._source.'字段名'= params.'字段名'",
"lang": "painless",
"params": {"字段名": 0
}
}
}
print("here")
es_client.update_by_query(index=_index, body=updateBody)
except:pass
批量更新
{
'_op_type': 'update',
'_index': 'index-name',
'_type': 'document',
'_id': 42,
'doc': {'question': 'The life, universe and everything.'}
}
ACTIONS = []
_index = "*8st_"
k = 0
for i in final:
response = es_client.search(body={"query": {"bool": {"must": [{"term": {"aid": i[0]}}], }},
# "_source": ["_id"]
}, index=_index)
# print(response)
for j in response["hits"]["hits"]:
_id = j["_id"]
# print(_id)
ACTIONS.append({
"_index": _index,
'_op_type': 'update',
"_id": _id,
"_source": {"doc": {"aid_score": float(i[1])}}
})
k+=1
print(k)
elasticsearch.helpers.bulk(es_client, ACTIONS, index=_index, raise_on_error=False)


















 2871
2871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











