






 本文介绍了福昕高级PDF编辑器如何处理可编辑和不可编辑的PDF,包括文本编辑、字数统计、OCR识别及批量更正疑似错误的功能,帮助用户在翻译项目中高效操作。
本文介绍了福昕高级PDF编辑器如何处理可编辑和不可编辑的PDF,包括文本编辑、字数统计、OCR识别及批量更正疑似错误的功能,帮助用户在翻译项目中高效操作。
学习笔记
想必大家也遇到过——有的PDF的文本可以直接复制出来、整个文档可以转换成很常规的DOC文件,但是有的PDF却不可以,里面的文字无法选中,转换成DOC之后还很可能是图片式的,文字依然无法选中……
为便于表达,我们把前者称为“可编辑的PDF”,后者称为“不可编辑的PDF”,不讨论PDF设置了“保护密码”的情况。“可编辑的PDF”的文字可以被选中和复制,与其他格式互转之后差异很小,由DOC文档转换成的PDF就是这样。“不可编辑的PDF”则很可能来自于图片或扫描件,有的是清晰的,看起来与“可编辑的PDF”没有差别,但数据记录的形式有根本区别;还有的是模糊的或者歪的,非常难处理,不利于获取要翻译的文本。
本篇推送,继续以福昕为例,分别展示上述两类PDF的文本处理,涉及文本编辑、字数统计、文本提取与OCR功能,希望大家藉此机会,举一反三,以后充分运用到翻译项目中去~
一、对于“可编辑的PDF”
可编辑PDF的文本可以直接复制出来,整个文档可以转换成很常规的DOC文件。
01
文本编辑
点击“编辑”工具栏,选择“编辑文本”工具。文件页面显示出文本框,可以编辑其中的文本。
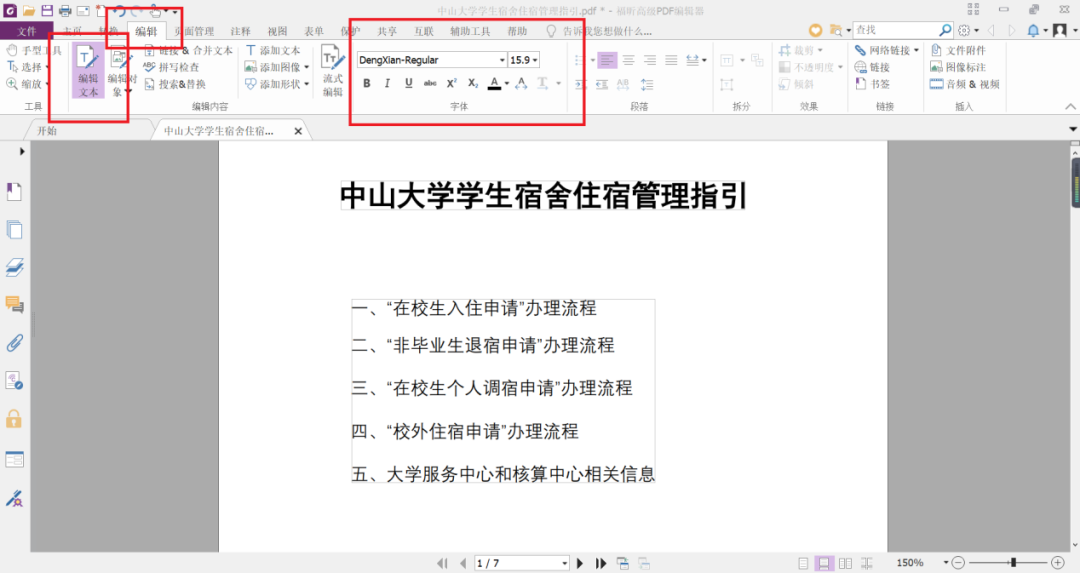
02
对象编辑
点击“编辑”工具栏,选择“对象编辑”工具。选择要编辑的对象,可对其进行移动、缩放、旋转等操作。对于文本对象还可以改变字体和颜色,或者拆分对象。
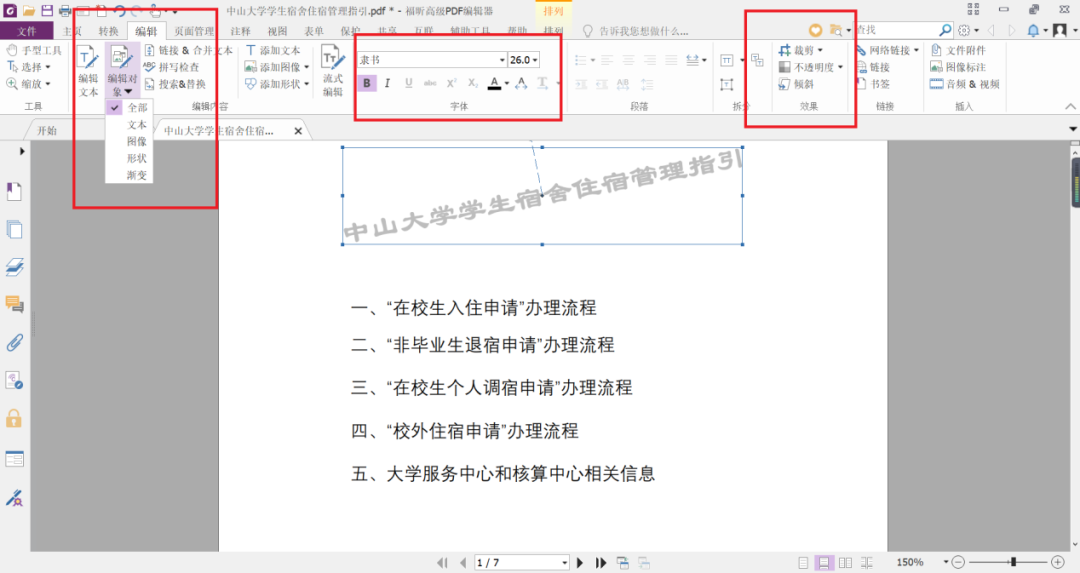
03
流式编辑
点击“编辑”工具栏,选择“流式编辑”工具。进入流式编辑页面,此时可以像在word里面一样对整个文本进行编辑。
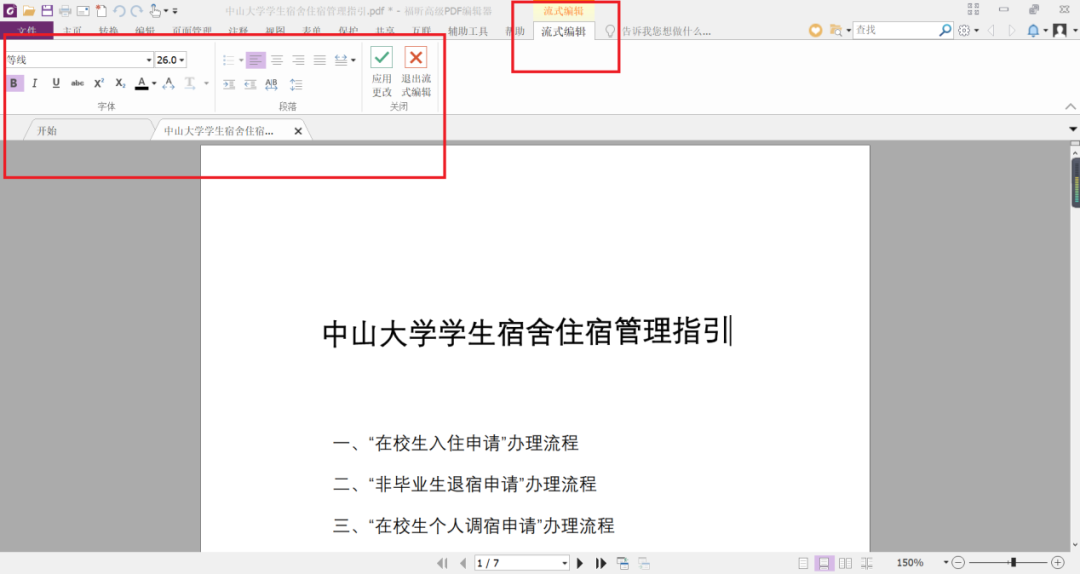
04
字数统计
点击工具栏的“告诉我您想做什么”框,输入“字数统计”,即可得到字数统计信息。
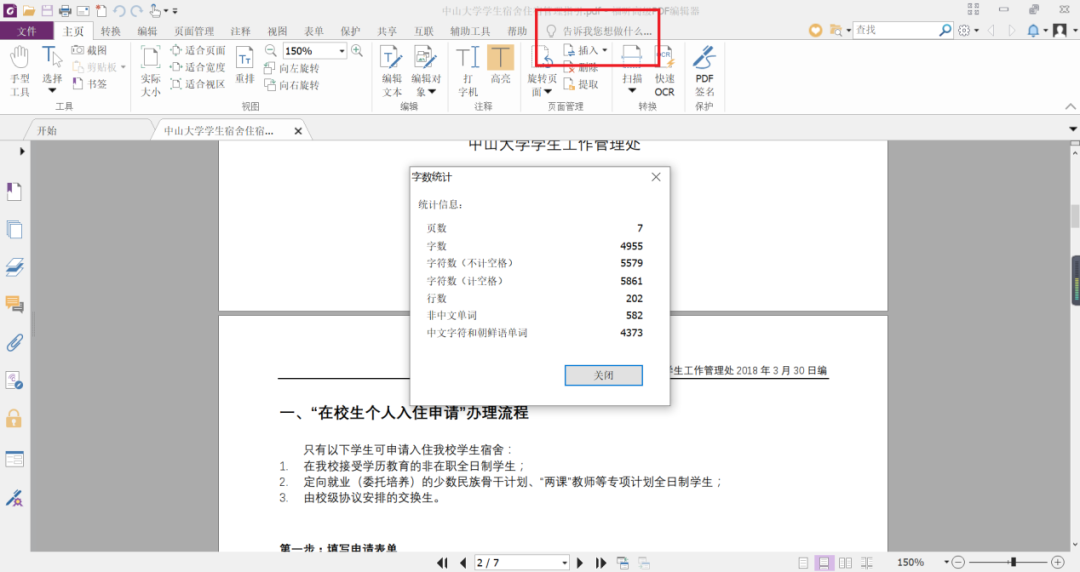
二、对于“不可编辑的PDF”
这类PDF文档里的文字不能用光标选中,甚至直接在图片里,福昕高级PDF编辑器的OCR(光学字符识别)就是为了解决这个问题的,下面将讲解:如何使用OCR识别文本,以及如何对疑似错误的识别结果进行批量更正。
01
使用OCR识别文本
首先,用福昕PDF编辑器打开某个扫描文档,在菜单栏里找到“OCR”一项,如图
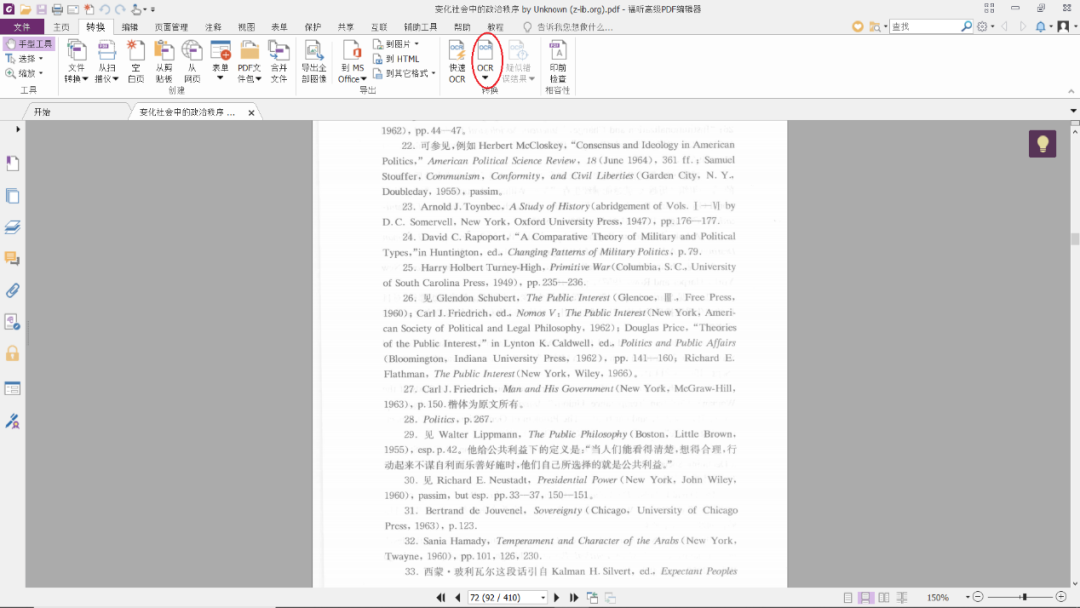
点击“OCR”,如果只需要识别当前文档,请点击“当前文件”;如果是需要识别多个文档,请点击“多个文件”
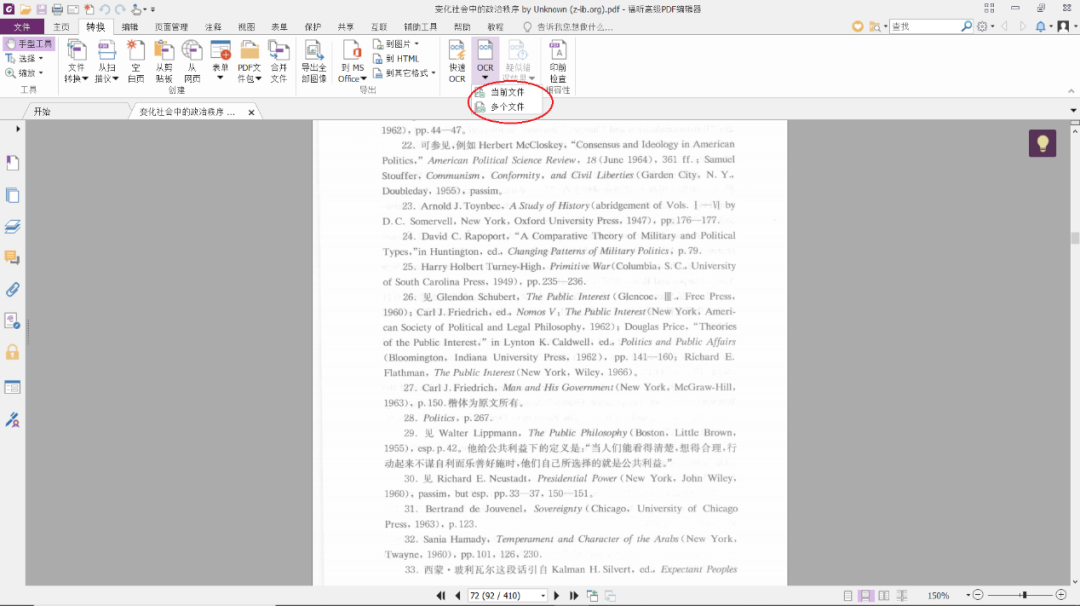
点击之后,会弹出对话框,如图所示,对话框里的内容分为三个部分:页面范围、语言设置、输出结果
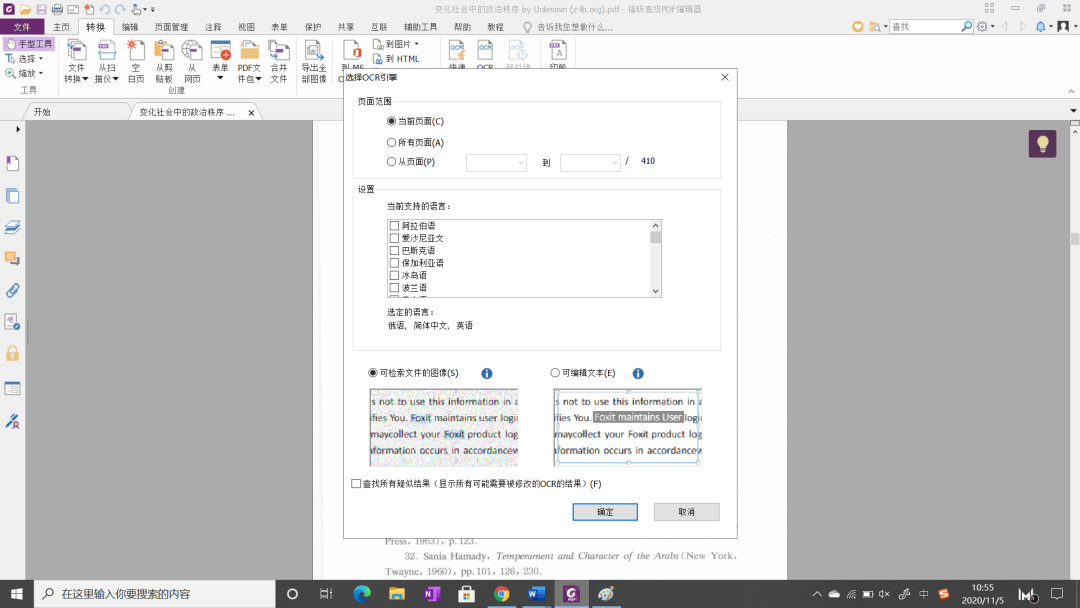
根据自己的需要进行设置后,点击右下角的“确定”,就可以开始识别了,识别过程如图所示:
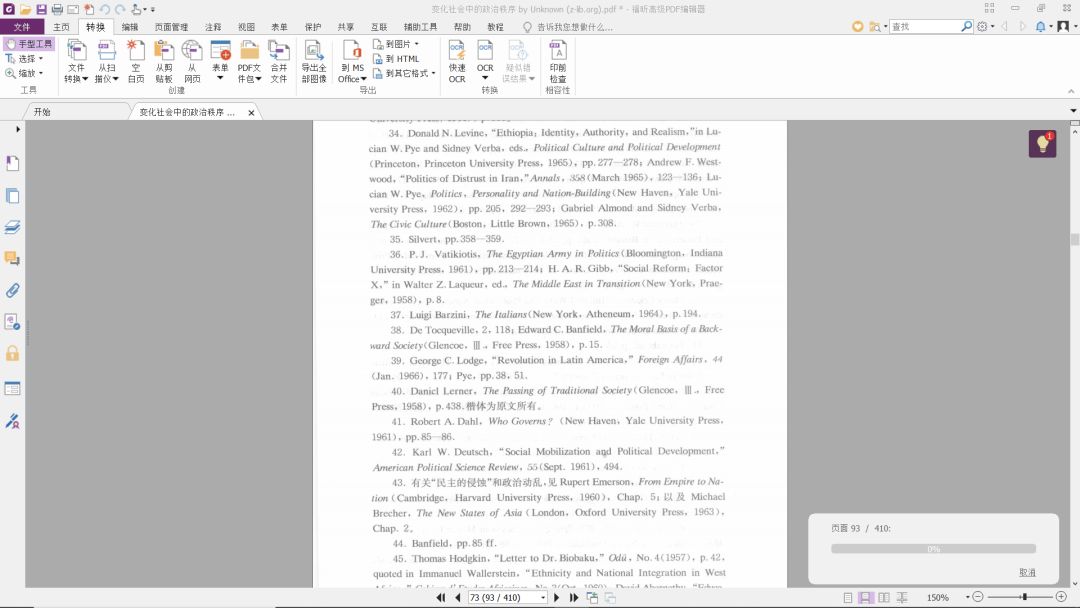
识别完成后,我们可以发现,现在文档里的文字可以被选中了。
02
批量更正疑似错误的识别结果
然而,有时我们会发现,识别结果与实际情况有很大出入,为了更正这些错误,我们可以使用OCR疑似结果批量更正这一功能,以下是有关示范:
文档识别完成后,点击菜单栏中“疑似错误结果”,如图:
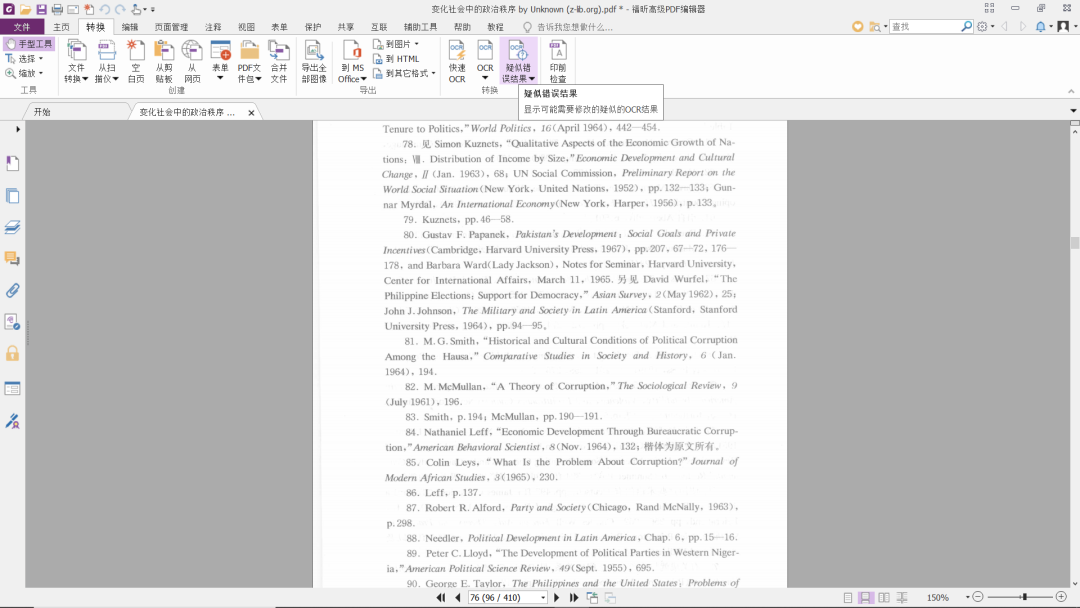
点击“疑似错误结果”后,会弹出子菜单,显示“第一个疑似错误”和“所有疑似错误”,如果要查找可能需要修改的第一次OCR结果,就点击“第一个疑似错误”;如果要查找可能需要修改的所有OCR结果,就点击“所有疑似错误”,如图:
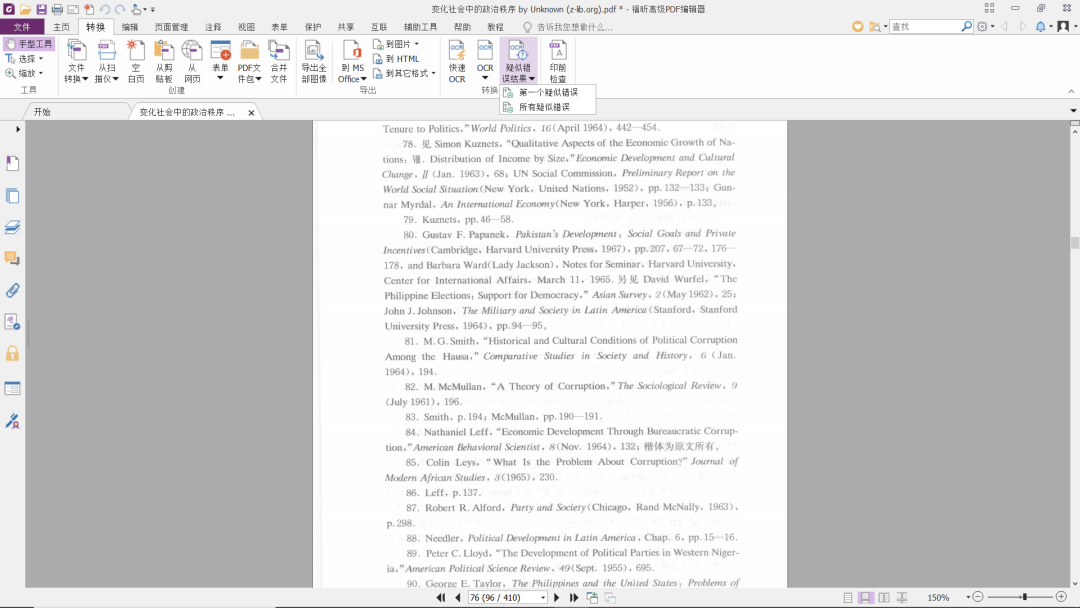
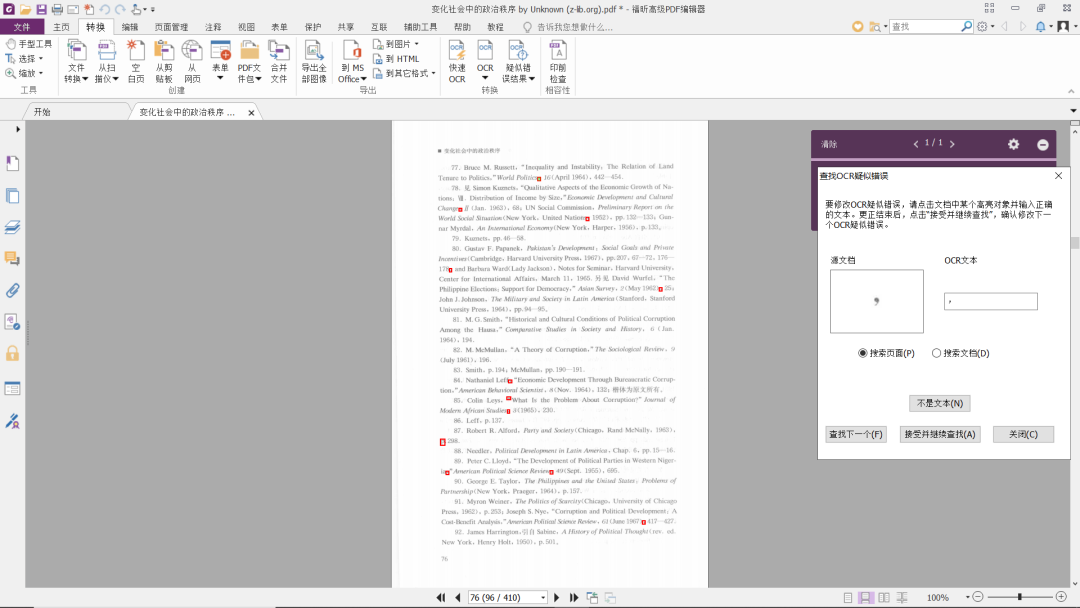
假设我们要查找可能需要修改的所有OCR结果,点击“所有疑似错误”后,会弹出对话框,同时也会显示所有可疑结果(红框标记的部分),将正确的结果输入对话框,确认无误后,点击“接受并继续查找”,即可完成对所有可疑结果的批量修改,如图:
关于OCR,还有哪些好用的工具或平台?
对比起来,哪个又更胜一筹?
这将作为一个独立的主题出推送,
和大家共同探讨学习~
同样,
对PDF文档的处理也远不止这两篇推送,
我们一起积极探索和实践吧 :)
图文来源丨彭逸铵 赵梓彤 郭见田
编辑丨陈俊嘉

















 768
768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









