







 这篇博客详细介绍了2023年合肥市信息学市赛初中组的比赛题目,包括文本修改、逛花店、密码箱等题目,涉及字符串处理、组合数学、图论等算法。文章提供了样例、输入输出格式和解题思路,如使用数组标记法优化字符串替换,以及利用差分思想解决花店购物问题,还探讨了处理有向无环图中环的问题,以及密码箱加密方式的计数方法。
这篇博客详细介绍了2023年合肥市信息学市赛初中组的比赛题目,包括文本修改、逛花店、密码箱等题目,涉及字符串处理、组合数学、图论等算法。文章提供了样例、输入输出格式和解题思路,如使用数组标记法优化字符串替换,以及利用差分思想解决花店购物问题,还探讨了处理有向无环图中环的问题,以及密码箱加密方式的计数方法。
2023年合肥市信息学市赛初中组-T1-文本修改(replace)
题目描述
小 C 在写一个程序。这个程序类似“文本文档”,但仅需要支持对某个文本串 T 的替换。由于小 C 还是个萌新,所以替换的功能也十分简单:将文本串中所有 字符 为 char1 替换成 字符 char2 即可。
小 C 还规定了文本串 T、字符char1 和char2 仅仅包含大写字母 A∼Z 和小写字母a∼z(不含空格等其他字符)。现在,小 C 希望你来帮忙实现这个功能。
另外小 C 为你准备了测试数据:文本串 T,以及 n 次替换操作,每次操作都会给你两个 字符 char1 和 char2。你只需要告诉小 C 对文本串 T 次进行替换操作后的结果即可。
输入格式
从文件 replace.in 中读取数据。
第一行为一个字符串 T,表示文本串;
第二行为一个正整数 n,表示替换操作次数;
接下来 n 行,每行有两个字符char1 和 char2,中间用空格隔开,表示一次替换操作。
输出格式
输出到文件 replace.out 中。
仅一行,输出一个字符串,表示依次进行n 次替换操作后的文本串。
样例
输入数据#1
IAmAStudent
1
A a
输出数据#1
IamaStudent
解释#1
文本串 T=IAmAStudent,将 A 替换成 a 后得到的文本串为 IamaStudent。
输入数据#2
aAKhgoB
3
a B
g f
B i
输出数据#2
iAKhfoi
解释#2
依次进行三次替换:

数据范围
记字符串 T 的长度为m。
对于 30% 的数据:m≤200,n=1;
对于 60%60% 的数据:m≤10^3,n≤103;
对于 100%的数据:m≤10^5,n≤10^5,char1 和char2 均为 单个字符。
耗时限制1000ms 内存限制512MB
解析
考点:字符串,数组标记
思路解析:
给定一个由大小写字母字符串 T,进行 n 次字符替换操作,每次将T 中所有的 c1 替换为 c2,求最后的字符串。
数据范围:∣T∣,n≤10^5。
60 分:暴力模拟
暴力求解的方法比较简单,模拟 n 次替换操作即可,时间复杂度 O(nm),其中m=∣T∣。预计官方可以拿 60分。(数据对第三段数据范围有一个测试点没有完全卡死,可得 70 分)
代码略。
100 分:数组标记
由上面的暴力模拟思路可知,如果想要不超时地通过本题,不能进行模拟,而应该在每次替换操作时,进行某种优化,容易想到的就是用数组标记法了。
由于字符串中仅有大小写字母,我们可以对每种字符进行标记,用 fa[a]=b 表示原字符串中所有的字符 a 最终被替换为了 b。接下来分析,如果用这种数组去避免模拟。
初始地,对于所有的字母 a,都有最终它们都要“替换为”本身,也即fa[a]=a。
当我们要进行一次将 a 替换为 b 的操作 a→b 时,意味着所有原本要替换为 a 的字符,都已经在之前的替换操作中,被替换为了 a,并且,在当前替换操作中,被替换为b。因此,我们应将所有 fa[..]=a 的字符,将其标记数组 fa[..] 的值修改为 b。值得注意的是,由于在这之前,原本字符 a 可能已经被替换为其他字符了,因此,不可令a[a]=b,这会导致结果错误。示例数据如下:
abcde
3
a b
c a
a e扩展思考:
本题这种标记的思想有一点像并查集,将每个字母看作一个结点,初始每个结点的出边都指向自己。不同的是,并查集里连边会令所有 a 的所有子孙结点的 fa[..] 都指向 b 的祖先。而这里的替换操作 a→b 在进行时,只是将所有 a 的子结点都指向 b 本身。
参考代码:
int m, fa[128], ex[128];
char a, b;
string s;
int main(){
cin >> s >> m;
for(int i = 65; i <= 122; i++) fa[i] = i;
for(int i = 1; i <= m; i++) {
cin >> a >> b;
if(ex[a] || a==b) continue; // 时间常数优化(可删):当前替换操作没有意义
ex[a] = 1; // 时间常数优化(可删):a 字符一定不存在了
// 所有之前被替换为字符 a 的字母,现在接着被替换成了 b
for(int j=65; j <= 90; j++) if(fa[j]==a) fa[j] = b;
for(int j=97; j <= 122; j++) if(fa[j]==a) fa[j] = b;
ex[b] = 0; // 时间常数优化(可删):b 字符是可能存在的
}
for(auto c : s) {
if(fa[c]) cout << char(fa[c]);
}
return 0;
}
2023年合肥市信息学市赛初中组-T2-逛花店(flower)
题目描述
小 C 今天去逛花店。花店里有三种花:月季花、牡丹花和菊花,每朵价格依次为 x、y、z 元。
小 C 带了 n 元现金,他决定每种花最多买m 朵。现在小 C 想知道,对于t 从 1 枚举到n,假如小 C 花费恰好 t 元,购买这三种花有多少种不同的组合?两种组合只要有一种花购买的朵数不一样即视为不同的组合。
输入格式
从文件 flower.in 中读取数据。
共两行,第一行共两个数 n 和 m,表示小 C 带的现金数、每种花的限制数;
第二行共三个数,依次表示每种花每朵的价钱为 x、y 和 z 元。
输出格式
输出到文件 flower.out 中。
仅一行,共 n 个数,第 t 个数表示小 C 花费恰好 t 元购花的不同的组合数。
样例
输入数据#1
5 1
1 2 3
输出数据#1
1 1 2 1 1
解释#1
设 (p,q,r) 表示一组方案,代表购买了 p 朵月季花、q 朵牡丹花和 r 朵菊花。
- 花费 1 元的方案:(1,0,0);
- 花费 2 元的方案:(0,1,0);
- 花费 3 元的方案:(0,0,1) 和 (1,1,0);
- 花费 4 元的方案:(1,0,1);
- 花费 5 元的方案:(0,1,1)。
注意到方案 (1,1,1) 的花费为 6 元,但是小 C 只带了 5 元现金,所以并不会被记入任何答案中。
输入数据#2
99 49
6 8 9
输出数据#2
见选手目录下的 flower/flower2.ans。
该组数据满足 20% 数据的条件。
输入数据#3
99993 994
89 55 1
输出数据#3
见选手目录下的 flower/flower3.ans。
该组数据满足:z = 1。
输入数据#4
999992 199
9917 1377 2919
输出数据#4
见选手目录下的 flower/flower4.ans。
该组数据满足 40% 数据的条件。
【样例2~4】数据参考选手目录
数据范围
对于 20% 的数据:n≤100,m≤50,1≤x,y,z≤10;
对于 40% 的数据:n≤10^6,m≤200,1≤x,y,z≤10^4;
对于另外 40% 的数据:n≤10^6,m≤5000,1≤x,y≤10^4,z=1;
对于 100%的数据:n≤10^6,m≤5000,11≤x,y,z≤10^4。
耗时限制1000ms 内存限制512MB
解析
考点:枚举,差分
题目大意: 题面意思比较明确,这里给出一个数学视角的题意:
给出方程
ax+by+cz=t
上式中 x,y,z 已知,a,b,c 为未知数。求对于每个非负整数 t∈[1,n],该方程的满足a,b,c 均在 [0,m] 范围内的非负整数解的数量。
数据范围:n≤10^6,m≤5000,1≤x,y,z≤10^4
40 分:暴力枚举+break优化
考虑到有三个未知数,且其范围已经限定在[0,m] 之间,于是我们三重循环暴力枚举每种(a,b,c) 的组合方案,然后用数组统计其中值落在 [1,n] 之间的组合数量即可。核心代码如下:
for(int i = 0; i <= m; i++) {
if(x * i > n) break; // 优化
for(int j = 0; j <= m; j++) {
if(x*i+y*j > n) break; // 优化
for(int k = 0; k <= m; k++) {
int t = x*i+y*j+k*z; // 总花费
if(t <= n) f[t]++; // 只统计在 [1,n] 之间的花费
}
}
}
for(int i = 1; i <= n; i++) cout << f[i] << ' ';
此思路的时间复杂度 O(m^3+n),可稳过 40% 的数据,考虑到 break 优化,常数比较低,实际官方得分可能大于 40 分。
另外 40 分:z=1
如果 z=1,那么意味着,当我们在前两重循环中计算出 x∗i+y∗j≤n 之后,每多买一朵菊花,对应的价格都要加一,方案数也增加一。而最多买 m 朵菊花,最多花 n 元,因此,x∗i+y∗j+0∼min(x∗i+y∗j+m,n) 之间的所有价格都可以组合出来。
我们令 l=x∗i+y∗j,令 r=min(x∗i+y∗j+m,n)。那么,这也就意味着 f[l]∼f[r] 都要增加一。
这是什么操作?区间加操作啊,怎么快速进行区间加减操作?差分啊。于是,我们构造一个 d[i]=f[i]−f[i−1]。将原本的维护 f 数组转到对应的差分数组d 上,如此,可以将上面的第三重循环去掉,时间复杂度降到O(m2+n)。可拿到另外的 40 分。核心代码如下:
for(int i = 0; i <= m; i++) {
if(x * i > n) break;
for(int j = 0; j <= m; j++) {
int l = x*i+y*j;
int r = min(l+m, n);
if(l > n) break;
d[r+1]--;
d[l]++;
}
}
for(int i = 1; i <= n; i++) d[i] += d[i-1];
for(int i = 1; i <= n; i++) cout << d[i] << ' ';
将该代码和上面的暴力枚举的代码组合一下,理论上可以拿到至少 80 分:
int n, m, x, y, z, f[N], d[N];
int main(){
cin >> n >> m >> x >> y >> z;
if(z != 1) { // 暴力枚举+break优化
for(int i = 0; i <= m; i++) {
if(x * i > n) break;
for(int j = 0; j <= m; j++) {
if(x*i+y*j > n) break;
for(int k = 0; k <= m; k++) {
int t = x*i+y*j+k*z;
if(t <= n) f[t]++;
}
}
}
for(int i = 1; i <= n; i++) cout << f[i] << ' ';
} else { // z=1,差分
for(int i = 0; i <= m; i++) {
if(x * i > n) break;
for(int j = 0; j <= m; j++) {
int l = x*i+y*j;
int r = min(l+m, n);
if(l > n) break;
d[r+1]--;
d[l]++;
}
}
for(int i = 1; i <= n; i++) d[i] += d[i-1]; // i-1=i-z
for(int i = 1; i <= n; i++) cout << d[i] << ' ';
}
return 0;
}
100 分:差分变形
很多时候,题目的部分分的设置是为了引导我们想出正解的。
延续上面的思路,那么如果 z≠1,差分的思想还可以使用吗?
稍微思考后,我们发现,现在还是区间加操作,但是并不是区间全体加一,而是以 z 为步长进行 +1。
直接原封不动地使用差分是不行的,我们需要对差分稍微进行一下变形处理。
虽然每一次枚举的起点 p=x∗i+y∗j 可能都不一样,但是每次的区间修改的步长都是z,这意味着我们可以把上面的操作看作是 z 个不同的区间加差分操作。
具体代码实现时,当l=x∗i+y∗j 通过双循环枚举确定后,我们再计算出对应 z 步长下的 r 的上界。正常的差分数组在区间加一修改 [[l,r] 时进行的是 d[l] 自加和 d[r+1] 自减操作。这里由于步长为 z,因此我们要修改为 d[r+z] 自减即可。
参考代码
const int N = 1.1e6+5; // 注意要多开至少 z
int n, m, x, y, z, d[N];
int main(){
cin >> n >> m >> x >> y >> z;
for(int i = 0; i <= m; i++) {
if(x * i > n) break;
for(int j = 0; j <= m; j++) {
if(x*i+y*j > n) break;
int r = x*i+y*j + min((n-l)/z, m)*z;
d[x*i+y*j]++;
d[r+z]--;
}
}
// 注意,现在是 z 个差分数组,转原数组要从下标 z 开始
for(int i = z; i <= n; i++) d[i] += d[i-z];
for(int i = 1; i <= n; i++) cout << d[i] << ' ';
return 0;
}
2023年合肥市信息学市赛初中组-T3-逛花店(flower)
题目描述
众所周知,现在的软件基本都有开屏广告。最近小 C 发现手机里软件的广告功能又升级了,只需轻轻“摇一摇”,就会跳转到另一个软件。这让小 C 很是苦恼,哪怕他没有摇动手机,广告都会自动打开另一个软件。
现在,小 C 的手机上装有 n 个软件,其中的 m 个软件有“摇一摇”广告。具体来说,只要打开这些软件,就会弹出来“摇一摇”广告。假设第 i 个软件有“摇一摇”广告,在广告播放结束后,便会自动跳转到第 pi 个软件。接下来,如果这个软件也有“摇一摇”广告,无论先前是否打开过,它都会播放广告,并在广告结束后打开其它对应的软件;否则将会无事发生。
这些软件上疯狂的广告甚至可能停不下来。小 C 的忍耐值为 k,也就是说,当他打开一个具有“摇一摇”广告的软件,接下来连续跳转达到 k 次后,小 C 就会非常愤怒。为了能有愉快的一天,小 C 决定删除一些软件,使得他点开任何一个软件,“摇一摇”广告不会连续跳转达到 k 次。
请你告诉小 C 至少要删除几个软件。保证每个软件要么没有“摇一摇”广告,要么其“摇一摇”广告播放完后会跳转到某一个其它的软件。
输入格式
从文件 ad.in 中读取数据。
第一行共三个整数 n、m 和 k,依次表示总软件数、拥有“摇一摇”广告的软件数以及小 C 的忍耐值;
接下来 m 行,每行两个整数i 和 pi,表示第 i 个软件拥有“摇一摇”广告,在其播放完后会自动跳转到第 pi 个软件。
输出格式
输出到文件 ad.out 中。
仅一行一个数,表示最少需要删除的软件数。
样例
输入数据#1
6 4 2
1 2
3 2
4 5
5 6
输出数据#1
1
解释#1
这 6 个软件中“摇一摇”广告的跳转关系如下图。
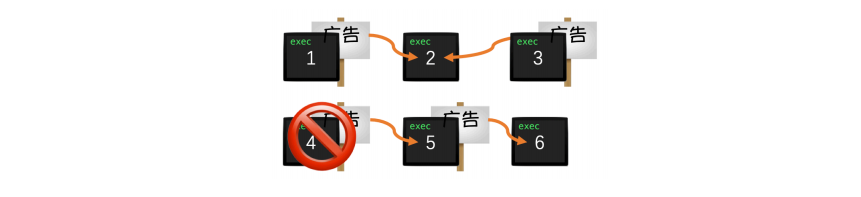
由于小 C 的忍耐值为 2,而打开第 4 个软件后,软件打开顺序为 4→5→6,广告跳转次数为 2,达到了小 C 的忍耐值。所以删除第 4 个软件即可。
输入数据#2
6 6 2
1 4
2 1
4 2
3 2
5 4
6 5
输出数据#2
2
解释#2
这 6 个软件中“摇一摇”广告的跳转关系如下图。

图中即为符合答案的一种删除方案。可以证明最少需要删除的软件数一定为 2。
数据范围
特殊性质 A:保证 m=n−1,且“摇一摇”广告的跳转关系构成一条链,并且一定满足 pi=i+1。
特殊性质 B:保证 m=n−1,且存在一个正整数x,满足当 i<x 时 pi=i+1,当 �>�i>x 时,pi=i−1。
特殊性质 C:保证“摇一摇”广告的跳转关系不存在环,即一定不存在从某个“摇一摇”广告开始,一直跳转下去,再次跳回到自身。
对于所有数据:11≤m≤n≤3×10^5,1≤k≤100,11≤i,pi≤n 且 i≠pi。
时间限制 3.0s 内存限制 512MB
解析
考点:图论,拓扑排序
题目大意:
给你一个有 n 个结点,m 条有向边的简单图,每个结点最多有一条出边,可能有环。问最少需要删除几个结点,可以使得剩下的图中不存在长度大于等于 k 的链路。
数据范围:1≤m≤n≤3×10^5,1≤k≤100
测试点 1∼3(5 分):n<=5
暴搜即可,每个点删或者不删,决策完后,判断剩下的图中是否存在长度大于等于 k 的链路,如果满足条件,记录最小的删除数量即可。代码略。
测试点 4(5 分):图是一条链
特殊性质 A 上 m=n−1 且pi=i+1,这意味着图是一条单向的链树。如此,我们只需简单地每 k+1 个结点删除最后一个结点即可。
也即,输出 n/(k+1) 即可得此 5 分。
测试点 4(5 分):图是一棵二叉树
特殊性质 B 上m=n−1,且存在一个正整数 x,满足当 i<x 时 pi=i+1,当i>x 时,pi=i−1。这意味着依赖关系类似下图,构成一棵二叉树的形式:
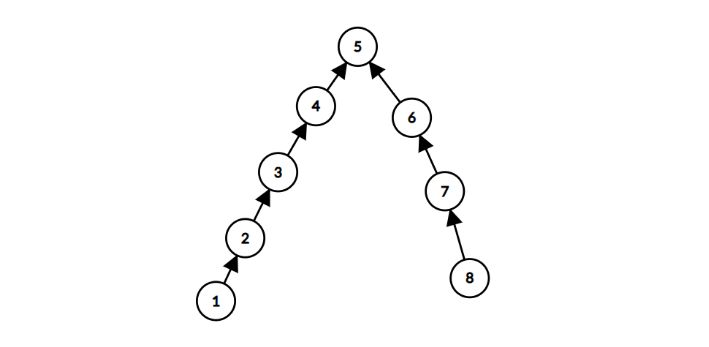
那么贪心地,我们把结点 x 删除,然后依次往两条子树的链上,按照特殊性质 A 的逻辑,每 k+1 个结点删除最后一个结点即可。
也即,输出 (n+1)/(k+1)−1 即可得此 5 分。
测试点 6∼10 + 测试点1∼3(40 分):图是有向无环图,且是多棵多叉树
特殊性质 C 保证图中跳转关系不存在环,也就意味着图是有向无环图。同时,由于每个结点都只有一条出边,这意味着这个有向无环图不会出现从一个点出发有多条出边的路径,然后这些路径最终又走到同一个点的情况。
所以此时,整个图可以看作是若干棵多叉树,每个树上的边都是从叶子开始指向其父结点,最终走到根结点,类似下图:
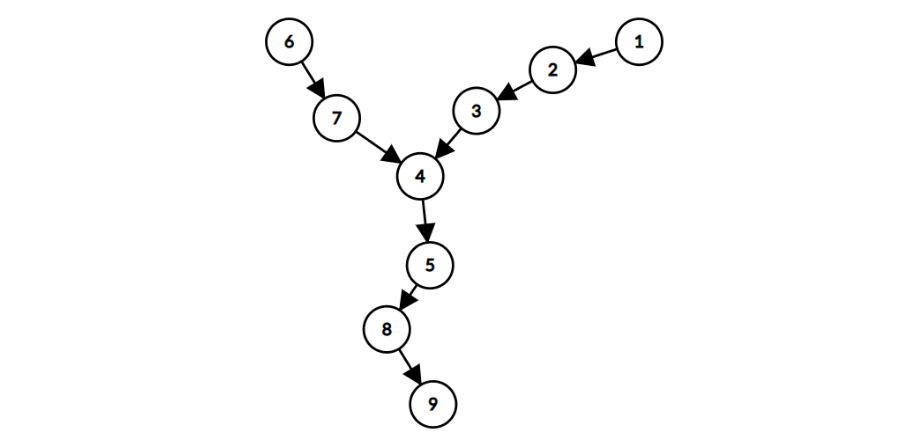
结构分析清楚后,我们发现,我们仍可以贪心地对每条链都每隔 k+1 个结点删除一个,也就是每到第 k+1 个结点,就删除。
具体地,由于是有向无环图,因此,我们可以用类似拓扑排序求图上最长路的方式,记录一下每个结点的 dis[i],表示到达结点 i 时的路径长度。然后先将所有入度是零的结点入队,然后用拓扑排序的方式遍历整个图。当同时当有多条链路走到同一个结点时,[]dis[] 取每条链路过来的最大值即可。
当出现 dis[x]=k 时,就意味着存在一条链路在到达结点 x 时长度已经大于等于 k 了,答案加一。然后其出边对应的结点的 dis 不做更新,这样就相当于删除该结点了。
如此可以通过满足性质 C 的测试点。实际上,由于性质 A,B 也满足性质 C,因此,此思路可以通过前 10 个测试点,理论上至少有 50 分。
参考代码:
int n, m, k, p[N], in[N], dis[N], ans;
void topo() {
queue<int> q;
for(int i = 1; i <= n; i++) {
if(!in[i]) q.push(i);
}
while(!q.empty()) {
int u = q.front(); q.pop();
in[p[u]]--;
if(dis[u] == k) ans++; // 删除该结点,dis[p[u]] = 0
else dis[p[u]] = max(dis[p[u]], dis[u] + 1);
if(!in[p[u]]) q.push(p[u]);
}
}
int main(){
cin >> n >> m >> k;
for(int i = 1, u, v; i <= m; i++) {
cin >> u >> v;
in[v] ++;
p[u] = v;
}
topo();
cout << ans;
return 0;
}
100 分做法:拓扑+处理环
现在图上面可能有环了。经过上面性质 C 的做法,我们可以发现,经过拓扑遍历处理后,图上就只剩下环上的结点可能会出现连续的长度达到 k 的链路。而且由于每个结点只有一条出边,因此这些环也一定是独立的,不会出现交叉形成环的情况。因此,我们只需遍历每个环,看这些环上需要删除几个结点。
需要注意,在上面拓扑处理后,环上有的结点的 dis[]≠0。我们就得分析一下该如何处理这些结点:
- 如果dis[u]=k,那么意味着 u 这个结点必须删掉。
- 如果 dis[u]<k,那么意味着该结点往后 k−dis[u] 个结点内必须至少有一个结点要删除。
这么去分类想可能有些复杂,且没法用上面的贪心删除的策略。 考虑到每连续k+1 个结点至少要删除一个,于是我们可以在环上枚举任意连续 k+1 个结点中的每个结点作为删除的起始点,然后去计算对应的环上的总的删除的结点数量,求出其中的最小值。最坏情况下,每个环上的结点都都循环遍历 k+1 次,假设所有结点都在环上,那么最坏情况下的时间复杂度为O(n×(k+1))。也不会超时。
这部分思路也验证了上面我们说的:“很多时候,题目的部分分的设置是为了引导我们想出正解的”这句话。
参考代码:
const int N = 3e5+5;
int n, m, k, p[N], in[N], dis[N], ans;
void topo() {
queue<int> q;
for(int i = 1; i <= n; i++) {
if(!in[i]) q.push(i);
}
while(!q.empty()) {
int u = q.front(); q.pop();
in[p[u]]--;
if(dis[u] == k) ans++; // 删除该结点,dis[p[u]] = 0
else dis[p[u]] = max(dis[p[u]], dis[u] + 1);
if(!in[p[u]]) q.push(p[u]);
}
}
int calc(int u){ // 计算从 u 开始删除,环上需要删除几个结点
int v = p[u], res = 1, d = -1;
while(v != u){
d = max(d+1, dis[v]);
if(d == k){
res++;
d = -1;
}
v = p[v];
}
return res;
}
int deal(int u) {
int s = u, cnt = n+1; // cnt: 当前环上需要删除的最少结点数量
for(int i = 1; i <= k+1; i++) {
cnt = min(cnt, calc(s));
s = p[s];
}
u = s;
do { // 将当前结点所在的环全部标记掉
in[u] = 0;
u = p[u];
} while(u != s);
return cnt;
}
int main(){
cin >> n >> m >> k;
for(int i = 1, u, v; i <= m; i++) {
cin >> u >> v;
in[v] ++;
p[u] = v;
}
topo();
for(int i = 1; i <= n; i++) {
if(in[i]) ans += deal(i); // 未处理的环上结点
}
cout << ans;
return 0;
}
2023年合肥市信息学市赛初中组-T4-密码箱(code)
题目描述
小 C 手上有 n 个密码箱,每个密码箱具有原码和密码,密码是由原码通过加密得到,二者均为长度为 m 的字符串,每一位由小写字母a∼z 组成。
这 n 个密码箱是同一个生产商制作的,所以采用的加密方式是一样的:首先生产商制定一个长度为 m 的排列 P=(p1,p2,...,pm),其中 pi 两两不同且都为 1 到 m 之间的整数。然后,假设原码对应的字符串为 S[1...m],密码对应的字符串为T[1...m],那么对于 i=1,2,...,m,均满足:T[i]=S[pi]。
小 C 知道所有 n 个密码箱的原码和密码,他想知道有多少种加密方式能满足要求,即:有多少种合法的排列 P,使得所有的原码按照 P 对应的加密方式,均能得到对应的密码。由于方案数很大,你只需要告诉小 C 方案数对 998244353 取模的结果即可。
当然,有可能生产商骗了小 C,并偷偷采用了其他的加密方式。所以最终合法的方案数可能为 0。
输入格式
从文件 code.in 中读取数据。
单个测试点中包含多组数据。
第一行有一个正整数 K,表示数据组数。
接下来依次描述每组数据。对于每组数据:
- 第一行有两个正整数n 和 m,依次表示密码箱的个数、原码密码的长度;
- 第 2∼2n+1 行描述了 n 个密码箱的原码和密码,其中第2i 行表示第 i 个密码箱的原码,第 2i+1 行表示第 i 个密码箱的密码,也就是每两行描述一个密码箱的信息。保证每行为一个长度为 m 的字符串。
输出格式
输出到文件 code.out 中。
共 K 行,每行输出一个正整数,依次表示每组数据中合法的排列数对 998244353 取模的结果。
样例
输入数据#1
3
1 2
ab
ba
1 3
aab
aba
1 3
aba
abc
输出数据#1
1
2
0
解释#1
第一组数据中,合法的排列只有 (2,1)(2,1);
第二组数据中,合法的排列有两种:(1,3,2)(1,3,2) 或 (2,3,1)(2,3,1);
第三组数据中,由于原码不含有 c 但是密码含有 c,故一定不存在合法排列。
输入数据#2
2
2 4
pass
saps
seek
kese
2 3
aba
aab
bcb
cbb
输出数据#2
1
0
解释#2
第一组数据中,对于第一组原码 pass 和密码 saps,其合法的排列为 (3,2,1,4) 或者 (4,2,1,3)(4,2,1,3);对于第二组原码seek 和密码 kese,其合法的排列为(4,2,1,3) 或者(4,3,1,2)。
由于两个密码箱加密所用的排列相同,所以最终合法的排列只能是 (4,2,1,3)。
第二组数据中,对于第一组原码aba 和密码aab,其合法的排列为(1,3,2) 或者(3,1,2);
对于第二组原码 bcb 和密码cbb,其合法的排列为(2,1,3) 或者 (2,3,1)。二者并不存在公共的合法排列,故最终答案为 0。
数据范围
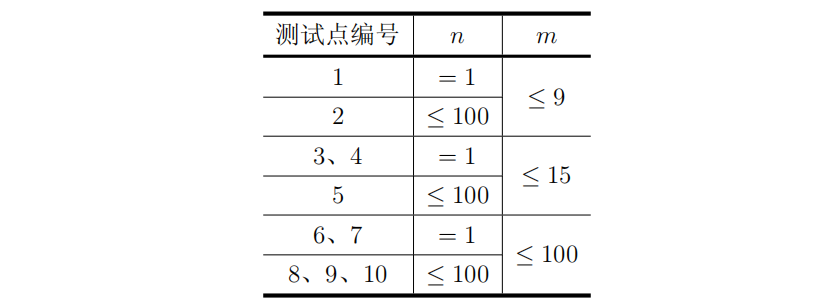
对于所有数据:1≤K≤10,1≤n,m≤100。
耗时限制1000ms 内存限制512MB
解析
考点:哈希,组合数学,计数原理,排列
题目大意:
给定 n 对长度相同的由小写字母构成的字符串 S1∼Sn 和 T1∼Tn,其长度均为 m,问存在多少种 ∼m 的排列 P=(p1,p2,...,pm),可以使得对于所有的 Sj[1..m] 和Tj[1..m],都有 Tj[i]=Sj[pi]。
数据范围:有 K 组测试数据,1≤K≤10,1≤n,m≤100
50 分:n=1,排列组合与乘法原理
测试点 1,3,4,6,71,3,4,6,7 满足 n=1。
这里我们要找的排列 P 其实只是一个映射。以字符串 S=abbd 和 T=bbda 为例,其对应的 P 有两种排列:
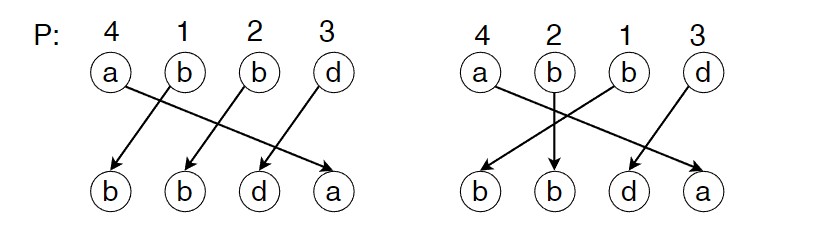
观察后我们可以发现:对于字符 s[i] 和 s[j],如果 s[i] 和 s[j] 相同,那么其对应的映射关系 pi 和 pj 在交换后仍为合法的排列(映射)。更通俗地说,那么对于S 中的每一种字母,如果它出现在了多个位置上,且存在合法的排列,使得其映射后可以成为T,那么将这些位置上的映射关系p 任意交换,排列仍旧合法。
那么怎么判断是否存在合法的序列呢?很简单,只要每种字母出现的次数一样多,那么 S 一定可以通过至少一种排列的加密方式变成 T,如果出现的次数不一样多,那么一定无法成功加密。
所以,在存在合法排列时,我们可以对于 26个字母,统计每个字母出现的次数。对于出现了 x 次的字母,其 x 个位置上做任意映射均是合法的,根据排列组合原理,易知,其方案数为 x! 种。由于不同字母之间的映射互相独立,因此总方案数就为各个字母的映射方案数累乘。写成数学表达式为:

时间复杂度:O(Kmlogm)
参考代码:
const int N = 1e2+5, mod=998244353;
int k, n, m;
long long fac[N]; // fac[i] = i!
string s, t;
int main(){
cin >> k;
fac[0] = 1;
for(int i = 1; i <= 100; i++) fac[i] = fac[i-1]*i % mod;
while(k--) {
long long ans = 1;
cin >> n >> m >> s >> t; // n = 1
sort(s.begin(), s.end());
sort(t.begin(), t.end());
if(s == t) { // 每种字符出现的次数一样多
int cnt = 1;
for(int i = 1; i < m; i++) {
if(s[i] == s[i-1]) cnt++;
else ans = ans*fac[cnt]%mod, cnt = 1;
}
ans = ans*fac[cnt]%mod;
} else ans = 0;
cout << ans << '\n';
}
return 0;
}
100 分:哈希随机化
当 n>1 时,有多对原码和密码。要求此时的合法排列对于每一对原码和密码都能成功将原码转成密码。我们仍可以沿用上面的思路:对于每一对原码和密码,如果每种字母出现的次数不一样多,那么一定不存在合法的排列。我们也可以独立地求出对于每一对原码和密码其合法的排列。整体满足每一对原码和密码的排列一定是这些排列集合的交集。但是如何求出这个交集呢?
注意到,对于一个合法的排列,我们将所有的原码的每一位打包到一起,组成一个“超级字符”,将所有的密码的每一位打包到一起,也组成一个对应位的“超级字符”,这样构造出一个“超级原码”和“超级密码”后。用这个排列去加密它们,结果仍会是合法的(因为一个排列对每一对原码和密码的映射关系是相同的)。反之,用一个非法的排列去加密,结果一定仍是非法的。
这样,我们就能用生成的一对“超级原码”和“超级密码”去按照上面 50 分做法中的方法计算原本的密码对的合法排列数量。这样“的“超级字符”的生成规则必须满足以下条件:
- 与原码密码对的出现顺序无关,也就是调换输入n 对原码密码的顺序,结果不能改变
- “超级原码”和“超级密码”上的合法的排列就是原本的合法排列,其上的非法的排列就是原本的非法排列
那么,考虑如何构造这样的一个“超级字符”——使用哈希。我们将每个排列的每个字母随机映射到某个数字上,然后将每一位上的这些数字相加(或者异或等),就可以构造出对应位上的“超级字符”。然后我们沿用 50 分中的判断准则:每种“超级字符”出现的次数一样多,那么就说明存在合法的排列。合法排列的方案数是各种“超级字符”出现次数的阶乘的累积。
时间复杂度:O(Knmlogm)
这里如果不哈希(随机化),然后直接相加或者异或的话,由于原本的小写字母在数值上是接近的,可能会存在误判排列合法的情况,所以要用哈希。举个反例:
2 4
abxy
yxba
efgd
fedg
这里,如果不用哈希随机化,我们也可以直接把字母拼成字符串,作为一个“超级字符”,也是可以的,这样处理也能满足“超级字符”的条件。
参考代码
const int mod=998244353;
int k, n, m;
long long fac[105], p[26];
string s, t;
int main(){
cin >> k;
fac[0] = 1;
for(int i = 1; i <= 100; i++) fac[i] = fac[i-1]*i % mod;
while(k--) {
long long ans = 1;
cin >> n >> m;
vector<int> a(m, 0), b(m, 0);
for(int i = 1; i <= n; i++) {
cin >> s >> t;
for(int j = 0; j < 26; j++) p[j] = (rand()+1)*(rand()+1); // 哈希进行随机化处理
for(int j = 0; j < m; j++) { // 构造一个超级字符串
a[j] ^= p[s[j]-'a'];
b[j] ^= p[t[j]-'a'];
}
sort(s.begin(), s.end());
sort(t.begin(), t.end());
if(s != t) {
ans = 0;
break;
}
}
sort(a.begin(), a.end());
sort(b.begin(), b.end());
if(ans && a == b) {
int cnt = 1;
for(int i = 1; i < m; i++) {
if(a[i] == a[i-1]) cnt++;
else ans = ans*fac[cnt]%mod, cnt = 1;
}
ans = ans*fac[cnt]%mod;
} else ans = 0;
cout << ans << '\n';
}
return 0;
}

















 1820
1820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









