







简介:《汇编语言 第3版》由王爽老师编写,旨在帮助读者深入理解和掌握汇编语言,这门计算机科学的基础语言。书中从汇编语言的基本概念讲起,逐步深入到x86架构下的指令集,同时讲解子程序设计、堆栈操作等编程方法,并探讨了汇编语言与高级语言的交互和调试技术。本书配以大量实例和习题,强调实践能力的培养,并鼓励读者支持正版图书。 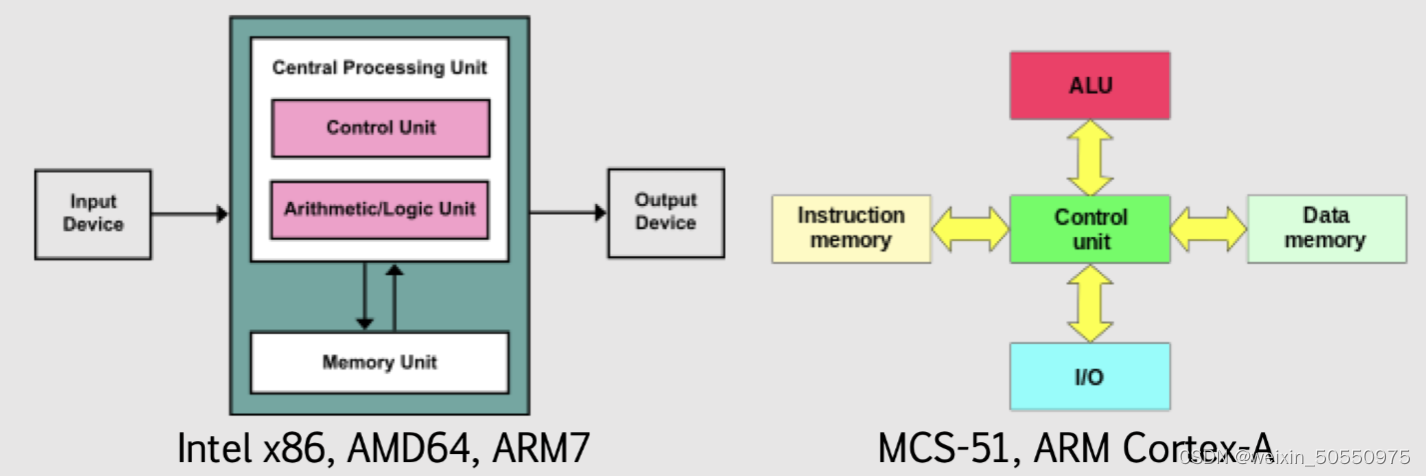
1. 汇编语言基础知识介绍
1.1 汇编语言的概念与发展历程
汇编语言是一种低级编程语言,它与计算机的机器语言紧密相关,但使用了人类可读的符号和指令代替了复杂的二进制代码。其发展始于20世纪50年代,随着计算机硬件的普及和软件需求的增加,汇编语言逐渐成为早期计算机编程的重要工具。随着计算机体系结构的演进,汇编语言也发生了相应的变化,以适应不同硬件平台的需求。
1.2 汇编语言的特性与应用领域
汇编语言具有高度的硬件依赖性,使得它在系统底层开发中具有不可替代的作用。其主要特性包括直接控制硬件资源、执行速度快以及代码体积小等。应用领域主要包括操作系统开发、嵌入式系统、驱动程序编写以及性能敏感型应用,如游戏开发和实时系统。
1.3 汇编语言程序的开发环境搭建
开发汇编语言程序需要特定的工具和环境,如编译器、汇编器、链接器和调试器。对于x86架构,常见的工具包括MASM、NASM和GAS等。搭建环境的第一步是在操作系统上安装这些工具,并配置好环境变量。然后,可以创建简单的汇编程序,通过编译、链接并最终运行来验证环境配置的正确性。
2. x86架构指令集详细讲解
2.1 x86架构概述与寄存器组
2.1.1 CPU内部结构与寄存器功能
x86架构是一种广泛应用于个人计算机的CPU设计风格,由Intel公司于1978年推出。其特点在于提供一套复杂的指令集,同时保持向后兼容性。这使得x86架构的处理器可以运行大量自那时起开发的软件。
在x86架构中,寄存器是CPU内部用来存储数据和指令地址的快速访问存储单元。每个寄存器都有特定的用途和大小。主要的寄存器包括通用寄存器、指令指针、标志寄存器等。
- 通用寄存器(EAX, EBX, ECX, EDX):用于运算和数据传输。
- 指令指针(EIP):存储下一条要执行的指令地址。
- 标志寄存器(EFLAGS):保存运算结果的状态信息,如零标志、符号标志、溢出标志等。
2.1.2 操作模式与寻址方式
x86架构支持多种操作模式,如实模式、保护模式和长模式。这些模式允许CPU根据需要执行不同的任务和运行不同的操作系统。
- 实模式是x86架构最初的操作模式,用于启动系统和运行早期的DOS程序。
- 保护模式提供了内存管理和硬件保护功能,支持多任务处理。
- 长模式则是在x86-64架构中引入的,支持超过4GB的内存寻址。
寻址方式决定了CPU如何定位和访问数据。x86架构提供了多种寻址方式,包括:
- 直接寻址:直接提供数据所在内存地址。
- 间接寻址:使用寄存器间接提供地址。
- 基址寻址:结合基址寄存器和偏移量计算地址。
- 索引寻址:通过索引寄存器和偏移量计算地址。
代码块示例:
; 示例:使用基址寻址方式加载数据到EAX寄存器
mov eax, [ebx+12h] ; EBX寄存器的值加上偏移量12h作为地址,将该地址处的数据加载到EAX寄存器
执行逻辑说明:
- 上述汇编指令
mov用于数据传输。 -
eax是目标寄存器,我们想要把数据放入这个寄存器。 -
[ebx+12h]表示基址寻址方式,ebx是基址寄存器,12h是偏移量,两者相加形成最终的内存地址,然后将该地址的数据移动到eax寄存器中。
2.2 常用指令的分类与功能
2.2.1 数据传输指令
数据传输指令主要用于在寄存器、内存和I/O端口之间移动数据。它们是汇编语言中最基础也是使用最频繁的指令之一。
常见的数据传输指令包括 MOV 、 PUSH 、 POP 、 IN 和 OUT 等。
-
MOV:将数据从一个位置移动到另一个位置,是最常用的传输指令。 -
PUSH和POP:用于在栈操作中压入和弹出数据。 -
IN和OUT:分别用于从I/O端口读取数据和向I/O端口写入数据。
2.2.2 算术逻辑指令
算术逻辑指令执行算术运算(如加法、减法)和逻辑运算(如与、或、非、异或)。这些指令用于执行程序中的数学和逻辑运算。
例如:
-
ADD、SUB:执行加法和减法运算。 -
AND、OR、XOR、NOT:执行逻辑运算。
2.2.3 控制转移指令
控制转移指令用于改变程序执行的顺序,使得程序可以进行循环、跳转和分支处理。
例如:
-
JMP:无条件跳转到指定位置。 -
CALL、RET:用于函数调用和返回。 -
CMP、JE、JNE等:基于比较结果跳转。
2.3 指令的编码与格式
2.3.1 指令的二进制表示
每条x86指令都可以转换成一系列的二进制代码,也就是机器码。这些二进制代码会直接被CPU执行。指令的二进制表示包含了操作码(opcode)和操作数(operands)。
例如,指令 MOV AX, BX 的二进制表示可能看起来像这样:
B8h 20h
这里 B8h 是 MOV 指令的操作码, 20h 是 BX 寄存器在内存中的表示。
2.3.2 指令前缀的作用与编码
某些指令前缀可用于修改指令的行为。例如,前缀 REP 可以用于字符串操作指令中,表示重复执行该操作。
指令前缀同样有其二进制编码,如 REP 前缀的编码是 F3h 。
rep movsb ; 重复移动字符串字节
通过指令前缀,程序员可以更精确地控制指令的执行流程,使得程序运行更加高效。
3. 子程序设计与堆栈操作
3.1 子程序的设计原则与实现
子程序(Subroutine)是一种可以被重复调用的程序段,用于实现特定的功能。在汇编语言中,通过调用指令CALL和返回指令RET来实现子程序的调用和返回。
3.1.1 调用约定与参数传递
调用约定是指程序设计语言中,函数调用和参数传递时遵循的一组规则。这些规则定义了参数如何在寄存器和堆栈中传递,以及如何清理这些参数。在x86架构中常见的调用约定有以下几种:
- C调用约定:在C语言和许多其他语言中使用,由调用者清理堆栈,参数从右到左传递,使用寄存器传递前几个参数。
- stdcall调用约定:在Windows API中广泛使用,由被调用者清理堆栈,参数同样从右到左传递。
3.1.2 子程序的局部变量与返回
子程序通常需要局部变量来保存临时数据。这些变量可能保存在寄存器中,也可能保存在堆栈上。使用堆栈保存局部变量时,可以在子程序开始时使用 SUB ESP,xxx 指令预留空间,并在子程序结束前使用 ADD ESP,xxx 来释放空间。
子程序完成后,通常使用 RET 指令返回到调用者。 RET 指令可以带有一个立即数参数,该参数指示需要从堆栈中弹出并丢弃的额外字节数,用于平衡堆栈。
3.2 堆栈的作用与操作细节
堆栈是一种后进先出(LIFO)的数据结构,它允许程序临时存储数据、保存返回地址以及保护和恢复寄存器值。
3.2.1 堆栈的基本操作原理
堆栈通过两个主要操作进行管理:PUSH和POP。PUSH操作将数据压入堆栈,而POP操作从堆栈中弹出数据。堆栈指针寄存器ESP(或x86-64中的RSP)指向当前堆栈的顶部。
当PUSH一个值时,ESP减少该值所占字节数,然后在ESP指向的位置写入数据;当POP一个值时,从ESP指向的位置读取数据,然后ESP增加相应的字节数。
3.2.2 堆栈在子程序中的应用实例
子程序调用时,通常需要将返回地址和调用者的上下文信息(如寄存器)保存到堆栈中。以下是一个使用汇编语言编写的子程序调用示例:
; 假设子程序名为SubroutineExample
; 参数通过寄存器EAX传递
push ebp ; 保存基指针
mov ebp, esp ; 设置新的基指针
sub esp, 10h ; 为局部变量预留空间
; 做一些处理...
mov eax, [ebp+8] ; 从参数中获取数据
; 更多处理代码...
add esp, 10h ; 清理局部变量空间
pop ebp ; 恢复基指针
ret ; 返回到调用者
在这个例子中,基指针寄存器EBP被用来保存堆栈帧的起始地址,ESP用来管理动态的堆栈空间。通过这样的方式,即使在子程序执行期间堆栈发生改变,也能够确保数据的正确存取和恢复。
3.3 中断与异常处理机制
中断和异常是操作系统处理硬件事件和程序错误的主要机制。当中断或异常发生时,处理器会立即暂停当前任务,转向执行相应的处理程序。
3.3.1 中断向量表与中断处理程序
中断向量表(Interrupt Vector Table, IVT)是x86架构中的一个数据结构,其中包含了指向中断处理程序(Interrupt Service Routines, ISRs)的指针。当中断发生时,处理器会使用中断向量号来查找IVT,并跳转到相应的ISR执行。
中断处理程序应该快速响应,处理完事件后,使用 IRET 指令返回到被中断的程序。 IRET 指令不仅恢复程序计数器,还恢复标志寄存器和堆栈指针。
3.3.2 异常处理机制与故障恢复
异常是程序执行过程中发生的错误,比如除零错误、访问违规等。异常的处理通常由操作系统内核来完成,异常处理程序通常位于特定的内存区域。
异常处理过程涉及保存被中断程序的状态,执行必要的错误处理,然后将控制权返回给被中断的程序。如果错误是可恢复的,程序可以尝试修正错误并继续执行;如果错误不可恢复,程序通常会被终止。
异常处理代码示例:
divide_by_zero_handler:
; 处理除零异常
pushad ; 保存所有通用寄存器
mov eax, esp ; 获取当前堆栈指针
; 调用异常处理函数,参数为异常编号和堆栈指针
call handle_exception
; 如果需要返回被中断的程序
popad ; 恢复所有通用寄存器
iretd ; 返回到被中断的程序
在异常处理程序中,使用 pushad 指令保存通用寄存器状态,并在处理完异常后使用 popad 来恢复。最后, iretd 指令用于从中断或异常返回。
4. 汇编与高级语言的交互
4.1 汇编语言与C语言的互操作基础
4.1.1 调用约定的匹配
为了在汇编语言和C语言之间实现有效的交互,必须确保它们之间的调用约定相匹配。调用约定是一套规则,它定义了如何在函数调用过程中传递参数、使用寄存器以及清理堆栈。例如,在x86架构上,典型的C语言调用约定包括使用栈来传递参数,并由调用方负责清理栈帧。
// 一个简单的C函数示例,展示了调用约定
int add(int a, int b) {
return a + b;
}
在汇编中实现上述C函数,并确保按照C语言的调用约定传递参数,其汇编代码可能如下:
; 假设使用的是x86架构和C调用约定
section .text
global _add
_add:
push ebp ; 保存旧的基指针
mov ebp, esp ; 设置新的基指针
mov eax, [ebp+8] ; 获取第一个参数
add eax, [ebp+12]; 获取第二个参数并相加
pop ebp ; 恢复基指针
ret ; 返回结果
在上面的汇编代码中,我们使用了栈来传递参数,并在函数结束时恢复了基指针。这样,无论是从C语言中调用汇编函数还是从汇编中调用C函数,都能保证参数和堆栈状态的一致性。
4.1.2 数据类型与参数转换
在C语言和汇编语言之间进行交互时,数据类型的一致性非常重要。由于汇编语言对数据类型的处理比高级语言更底层,因此需要在汇编代码中明确地对数据类型进行转换。例如,32位整数和64位整数在汇编中操作时会有不同的指令集。
// C语言中的一个函数,接受一个64位整数参数
int64_t multiply(int64_t a, int64_t b) {
return a * b;
}
相应的汇编代码实现:
; 假设使用的是x86-64架构
section .text
global _multiply
_multiply:
mov rax, rdi ; 将第一个参数放入rax寄存器
imul rax, rsi ; 与第二个参数相乘
ret ; 返回结果
上述汇编代码使用了 rax 和 rsi 寄存器来处理64位整数。这展示了数据类型转换和寄存器使用的匹配。
4.2 汇编语言在高级语言中的应用实例
4.2.1 性能关键部分的汇编优化
在性能敏感的应用中,使用汇编语言对关键部分进行优化是常见的做法。这包括循环优化、数学计算加速等。下面是一个使用汇编进行循环优化的例子。
假设我们有一个C语言函数,它包含了一个计算数组元素平方和的循环:
int sumOfSquares(int *arr, int len) {
int sum = 0;
for (int i = 0; i < len; i++) {
sum += arr[i] * arr[i];
}
return sum;
}
通过将循环中的乘法操作改用汇编语言实现,我们可以获得性能提升:
; 汇编语言优化循环中的乘法操作
section .text
global _sumOfSquares
_sumOfSquares:
xor ecx, ecx ; 清零计数器
xor edx, edx ; 清零累加器
mov esi, [esp+4] ; 获取数组指针
mov edi, [esp+8] ; 获取数组长度
cld ; 清除方向标志,确保向前操作
repetae:
mul dword [esi + ecx*4] ; 用汇编指令乘法替代C中的乘法
add edx, eax
inc ecx
cmp ecx, edi
jne repetae
mov eax, edx ; 将结果放入eax寄存器返回
ret
4.2.2 高级语言中的内联汇编技术
内联汇编是在高级语言代码中直接嵌入汇编指令的能力。这允许开发者在不离开高级语言上下文的情况下,直接使用汇编指令。下面是在C语言中使用GCC内联汇编的一个示例。
假设我们需要在C代码中实现一个原子操作,以便在多线程环境中安全地增加一个变量的值。这在性能要求较高的场合是非常有用的。
// 使用内联汇编在C语言中实现原子加操作
int atomic_add(int *ptr, int value) {
int result;
__asm__ __volatile__(
"lock xaddl %0, %1"
: "=r" (result), "=m" (*ptr)
: "0" (value), "m" (*ptr)
: "memory", "cc"
);
return result + value;
}
在上述代码中,我们使用了 lock xaddl 指令来原子地执行增加操作。这个指令确保了即使在多线程环境中,变量的增加也是线程安全的。
4.3 混合编程的调试与性能分析
4.3.1 调试工具的使用与技巧
混合编程的调试往往比单一语言更为复杂,因为涉及到两种不同层次的语言。调试工具如GDB、OllyDbg或Visual Studio等提供了一系列调试功能,可以帮助我们在这类复杂情况下进行调试。
调试的基本步骤包括:
- 使用断点,设置在汇编代码和高级代码中的关键点。
- 单步执行,观察寄存器和内存状态的变化。
- 观察变量值和表达式的结果。
调试技巧包括:
- 使用调试器的反汇编功能来查看高级语言对应的汇编代码。
- 利用条件断点减少调试过程中的重复步骤。
- 在复杂的嵌套调用中使用调用栈跟踪功能。
4.3.2 性能瓶颈分析与优化策略
性能瓶颈分析和优化是混合编程中的重要环节。开发者必须了解哪些部分是性能瓶颈,并选择合适的策略进行优化。
性能瓶颈分析的常见步骤包括:
- 使用性能分析工具(如gprof、Valgrind、Intel VTune)来检测程序中的热点。
- 确定耗时的函数和循环。
- 评估函数调用开销。
优化策略可能包括:
- 减少不必要的函数调用。
- 在热点循环中使用内联汇编来替代高级语言代码。
- 使用寄存器变量来减少内存访问。
至此,我们已经详细探讨了汇编语言与高级语言交互的多个方面,包括基础的互操作原理、应用实例以及混合编程时调试和性能分析的策略。这些内容为IT行业的专业人员提供了一个深入理解混合编程复杂性的窗口,并提供了实用的工具和技巧。
5. 汇编程序调试技术指导
5.1 调试环境的配置与使用
调试是汇编程序开发中不可或缺的一环,其目的是找到程序中的错误(bugs)并修正它们。要开始调试,首先要配置一个合适的调试环境。这一小节将详细介绍如何选择合适的调试器,配置调试环境,并介绍如何使用断点和单步执行等常见的调试技术。
5.1.1 调试器的选择与配置
调试器是用于检测程序错误的工具,它可以让我们在程序运行时逐步执行代码,观察程序状态,从而定位问题所在。选择合适的调试器对于有效的调试至关重要。常用的汇编语言调试器包括GDB、WinDbg以及集成开发环境(IDE)自带的调试器,如Visual Studio中的调试器。
在配置调试器之前,需要确认调试器是否与你的汇编环境兼容。例如,如果你使用的是Windows操作系统并且编写的是x86架构的程序,WinDbg将是一个不错的选择。而如果你使用的是Linux系统,GDB则可能是更合适的选择。
配置调试器时,需要考虑以下几个方面:
- 符号表 :确保调试器能够加载与程序相对应的符号表,这样才能正确显示函数名和变量名。
- 源代码映射 :如果你有源代码,应该配置调试器以便它知道如何将程序的执行位置映射到源代码的行号上。
- 内存检查 :配置调试器来检测内存访问违规,如越界读写等。
配置完调试器之后,通常需要加载目标程序,这可以通过命令行或是调试器的图形界面完成。
5.1.2 断点设置与单步执行
在配置好调试环境之后,接下来是设置断点并执行单步操作。断点是一个标记,它告诉调试器在执行到程序的特定位置时暂停执行,允许开发者检查程序状态。
在GDB中,可以使用 break 命令设置断点。例如,要在 main 函数处设置断点,可以输入 break main 。在WinDbg中,可以使用 bp 命令来实现相同的功能。
单步执行允许程序员一次执行程序的一行或是一条指令,观察程序的执行流程和变量的变化。在GDB中,可以使用 step 命令进行单步执行,它会进入函数内部;而 next 命令则执行当前行,但不会进入函数内部。在WinDbg中, t 命令用于单步跟踪,而 p 命令则进行单步执行。
示例代码块与逻辑分析
下面是一个简单的汇编语言程序段,和如何使用GDB进行调试的示例:
section .text
global _start
_start:
; 程序逻辑开始
mov eax, 1
mov ebx, 0
int 0x80
要使用GDB调试这个程序,首先编译并运行GDB:
gcc -m32 -g -o example example.s
gdb ./example
在GDB中,我们可以设置断点并开始单步执行:
(gdb) break _start
(gdb) run
(gdb) step
(gdb) info registers
这些命令分别用于设置断点、运行程序、执行单步操作和查看寄存器的状态。通过逐步执行和观察寄存器及内存的变化,开发者能够逐步理解程序的行为,从而找出和修复bug。
5.2 调试过程中的常见问题与解决
汇编语言编程比高级语言编程更容易出现底层错误,如内存访问违规、寄存器状态混乱等。本小节将探讨这些问题的识别和解决方法。
5.2.1 内存访问违规与处理
内存访问违规可能是由数组越界、非法指针访问或错误的内存释放引起的。当发生内存访问违规时,调试器通常会立即停止程序执行,显示错误信息。
例如,下面的汇编代码中有一个试图读取越界内存的操作:
section .data
array db 10, 20, 30
section .text
global _start
_start:
mov esi, 3
mov al, [array + esi] ; 这里访问了越界内存
; 程序其他部分...
在GDB中,当这个操作发生时,可以获取违规的详细信息:
(gdb) run
Starting program: /path/to/example
Access violation reading location 0x12345678.
Program received signal SIGSEGV, Segmentation fault.
0x08048082 in _start ()
通过分析寄存器和栈信息,可以找到违规发生的确切位置。通常,这需要对汇编指令和寄存器状态有深入的理解。
5.2.2 寄存器状态分析与问题定位
寄存器状态分析是调试汇编程序时的核心环节之一。在不同的程序执行点,寄存器会存储不同的值。通过检查和分析这些值,我们可以判断程序在运行时的某些操作是否正确。
以x86架构为例,常见的寄存器包括EAX、EBX、ECX、EDX等,它们有各自特定的用途。在进行寄存器状态分析时,应该特别注意这些寄存器的状态变化:
(gdb) info registers
eax 0x1 1
ecx 0x2 2
edx 0x3 3
ebx 0x0 0
esp 0xbffff7e0 -1073744752
ebp 0xbffff7f8 -1073744736
esi 0x3 3
edi 0x0 0
eip 0x8048082 0x8048082 <_start+14>
eflags 0x202 [ IF ]
cs 0x73 115
ss 0x7b 123
ds 0x7b 123
es 0x7b 123
fs 0x0 0
gs 0x33 51
在这个例子中, eip 寄存器显示当前执行的指令地址,通过这个地址我们可以分析程序当前正在执行的指令。而其他寄存器则显示了它们的值,可以帮助我们理解程序的状态。
5.3 调试技巧的进阶应用
随着调试经验的积累,开发者会发现有许多高级调试技巧能够帮助更深入地理解程序的行为和定位更隐蔽的错误。
5.3.1 条件调试与日志记录
条件调试是一种仅当满足特定条件时才停止执行的调试方法,这在程序的某个特定条件下出现问题时非常有用。GDB和WinDbg都支持设置条件断点。
例如,若只想在 array 数组的第一个元素为0时停止执行,可以设置如下断点:
(gdb) break _start if array[0] == 0
在复杂程序的调试过程中,日志记录可以作为一种重要的调试手段。通过在关键代码位置添加日志输出语句,可以追踪程序执行流程,记录关键变量的状态变化。这在发布版本中不希望出现调试语句影响性能时尤其有用。
5.3.2 复杂程序的调试策略
调试复杂的汇编程序需要一个明确的策略。对于大型项目,一种策略是逐步细化,从程序的高层逻辑开始,逐步深入到底层的函数和指令。
在进入复杂的函数或循环时,可以先不设置断点,而是使用 continue 命令让程序运行,直到遇到下一个断点。这样做可以快速地定位到问题发生的区域。
同时,理解程序的结构和逻辑流程对于高效调试至关重要。因此,开发者应当在编写代码的同时保持代码的可读性和可调试性,这将大大减少调试时遇到的困难。
表格与Mermaid流程图
调试工具的比较:
| 工具名称 | 支持的平台 | 主要特点 | 用户界面 | 常见用途 | |-----------|------------|------------------------------|----------------|--------------------------| | GDB | Linux | 命令行工具、支持多语言调试 | 命令行 | 高级调试功能、底层问题定位 | | WinDbg | Windows | 图形界面、内核模式调试 | 图形界面 | 系统级调试、驱动开发调试 | | Visual Studio | 多平台 | 集成开发环境、高级调试功能 | 图形界面 | 跨平台应用开发、代码调试 |
Mermaid流程图表示如何使用GDB进行调试:
flowchart LR
A[编写汇编代码] --> B[编译代码]
B --> C[运行GDB调试]
C --> D[设置断点]
D --> E[运行程序]
E --> F[单步执行]
F --> G[查看寄存器和内存状态]
G -->|发现问题| H[问题定位与修复]
H --> I[重复上述步骤直到程序正确运行]
这个流程图描述了使用GDB进行汇编程序调试的一般步骤。
通过本小节的讲解,读者应该能够掌握使用GDB、WinDbg等调试工具进行汇编程序调试的基本技巧,并能应用这些技巧来识别和解决程序中出现的常见问题。在实践中,需要通过不断的尝试和应用,才能提高调试效率和技能水平。
6. 实例和习题的实践应用
6.1 汇编语言编程实例分析
6.1.1 实例的选题与需求分析
选择汇编语言编程实例时,通常需要考虑以下几点:
- 可理解性 :实例应包含基础与高级的概念,以便读者能够从基础开始学习,逐步深入。
- 实用性 :最好选择在实际工作中可能会遇到的问题或场景,使学习者能够将所学知识应用于实践。
- 多样性 :应覆盖不同类型的编程任务,包括数据处理、算法实现、系统功能调用等。
例如,我们可以选择一个简单的实例,如实现一个程序,它能够将用户输入的一系列数字进行排序。通过这个实例,可以探讨汇编语言在数组处理和基本算法实现方面的应用。
6.1.2 编码实现与功能测试
以x86汇编语言为例,对上述实例的实现步骤可能会包括以下关键代码:
section .data
array db 5, 2, 8, 3, 1, 4, 9, 7, 6 ; 待排序数组
size equ $ - array ; 数组大小
section .text
global _start
_start:
; 这里假设已经调用了排序子程序 sort_array
call sort_array
; 程序完成后的退出
mov eax, 1 ; 系统调用号(sys_exit)
xor ebx, ebx ; 返回值 0
int 0x80 ; 触发中断
sort_array:
; 排序算法实现代码(例如冒泡排序)
; ...
ret
上述代码展示了如何在汇编语言中声明数据、编写一个主程序入口以及一个排序子程序的框架。之后,开发者需要完成 sort_array 函数的实现,这里可以使用冒泡排序等基础算法来完成。
在功能测试阶段,需要验证程序是否能够正确排序。这可以通过在屏幕上打印排序后的数组或使用调试器单步执行并观察寄存器和内存状态来完成。
6.2 经典习题的解析与拓展
6.2.1 基础题目的解题思路
基础题目的解题思路通常需要遵循以下步骤:
- 理解题意 :仔细阅读题目要求,明确要解决的问题。
- 分析算法 :根据题目的复杂度选择合适的算法,如线性搜索、二分查找、堆排序等。
- 编写伪代码 :初步构思程序的流程和结构。
- 实现代码 :根据伪代码,使用汇编语言编写程序。
- 测试调试 :检查程序中的逻辑错误,确保程序的正确性。
以冒泡排序为例,解题思路是在一个数组中重复比较相邻元素,然后交换顺序不对的元素。重复这个过程,直到整个数组排序完成。
6.2.2 高级题目的深入探讨
高级题目的解题思路则更强调对复杂概念的理解和应用,例如:
- 动态内存分配 :如何在汇编语言中管理内存,实现动态数据结构的创建和释放。
- 中断和异常处理 :在程序执行过程中,如何处理各种中断和异常情况。
- 系统级别的交互 :如何通过汇编语言调用操作系统提供的服务。
这些问题的探讨将涉及汇编语言中更深层次的系统调用和高级数据结构的操作。
6.3 实际问题的解决方法与思路
6.3.1 实际工作中遇到的问题实例
在实际工作中,可能会遇到需要优化程序性能的情况。例如,一个程序在处理大量数据时出现响应缓慢,此时可以考虑使用汇编语言对关键算法进行优化。
6.3.2 解决方案的评估与选择
评估和选择解决方案时,应该考虑以下因素:
- 性能瓶颈 :首先确定程序中的性能瓶颈是否在算法部分。
- 优化空间 :分析算法的复杂度,并探索是否有可能简化或者改进。
- 可维护性 :考虑优化后的代码是否会影响程序的可维护性。
- 兼容性 :确保优化后的代码在目标硬件和操作系统上能够正常工作。
解决方案可能包括使用更高效的算法、改进数据结构的使用或者直接用汇编语言重写关键代码段。最终目的是通过这些方法,提高程序的执行效率,减少资源消耗。
简介:《汇编语言 第3版》由王爽老师编写,旨在帮助读者深入理解和掌握汇编语言,这门计算机科学的基础语言。书中从汇编语言的基本概念讲起,逐步深入到x86架构下的指令集,同时讲解子程序设计、堆栈操作等编程方法,并探讨了汇编语言与高级语言的交互和调试技术。本书配以大量实例和习题,强调实践能力的培养,并鼓励读者支持正版图书。

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









