







作者:Redflashing
本文梳理举例总结深度学习中所遇到的各种卷积,帮助大家更为深刻理解和构建卷积神经网络。
本文将详细介绍以下卷积概念:
- 2D卷积(2D Convolution)
- 3D卷积(3D Convolution)
- 1 ∗ 1 1*1 1∗1卷积( 1 ∗ 1 1*1 1∗1 Convolution)
- 反卷积(转置卷积)(Transposed Convolution)
- 扩张卷积(Dilated Convolution / Atrous Convolution)
- 空间可分卷积(Spatially Separable Convolution)
- 深度可分卷积(Depthwise Separable Convolution)
- 平展卷积(Flattened Convolution)
- 分组卷积(Grouped Convolution)
- 混洗分组卷积(Shuffled Grouped Convolution)
- 逐点分组卷积(Pointwise Grouped Convolution)
5. 反卷积(转置卷积)
对于很多生成模型(如GAN中的生成器、自动编码器(Autoencoder)、语义分割等模型)。我们通常希望进行与正常卷积相反的装换,即我们希望执行上采样,比如自动编码器或者语义分割。(对于语义分割,首先用编码器提取特征图,然后用解码器回复原始图像大小,这样来分类原始图像的每个像素。)
实现上采样的传统方法是应用插值方案或人工创建规则。而神经网络等现代架构则倾向于让网络自己自动学习合适的变换,无需人类干预。为了做到这一点,我们可以使用转置卷积。
转置卷积在文献中也被称为去卷积(Deconvolution)或微步幅卷积(Fractionally strided convolution)。但是,需要指出去卷积这个名称并不是很合适,因为转置卷积并非信号/图像处理领域定义的那种真正的去卷积。从技术上讲,信号处理中的去卷积是卷积运算的逆运算。但这里却不是这种运算。后面我们会介绍为什么将这种运算称为转置卷积更自然且更合适。
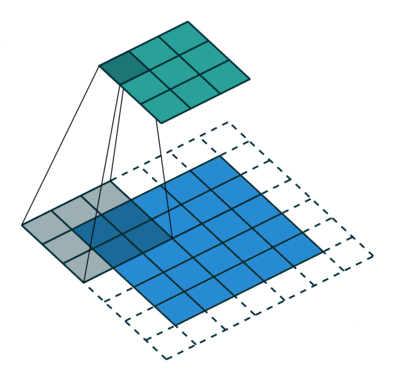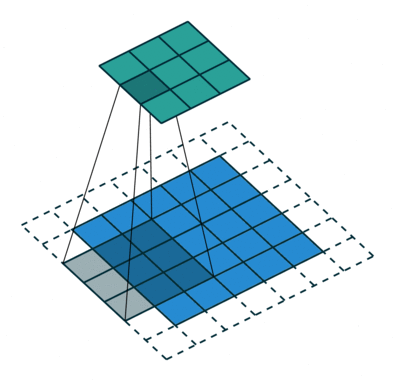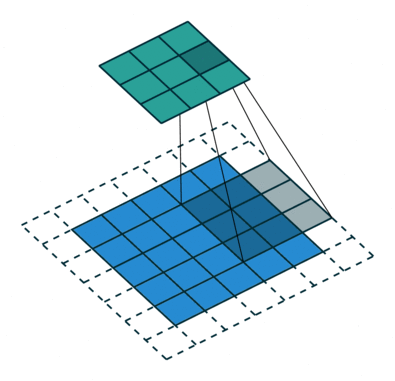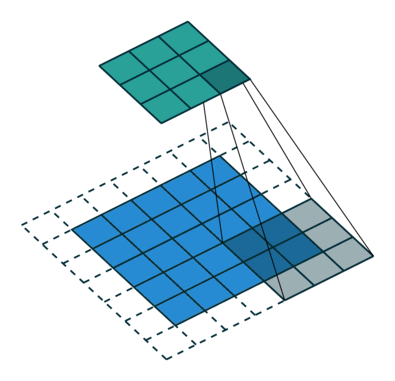
我们可以使用常见卷积实现转置卷积。这里我们用一个简单的例子来说明,输入层为 2 ∗ 2 2*2 2∗2,先进行填充值Padding为 2 ∗ 2 2*2 2∗2单位步长的零填充,再使用步长Stride为1的 3 ∗ 3 3*3 3∗3卷积核进行卷积操作则实现了上采样,上采样输出的大小为 4 ∗ 4 4*4 4∗4。
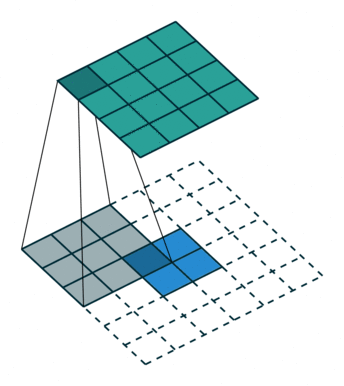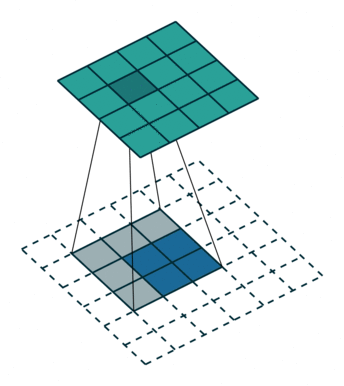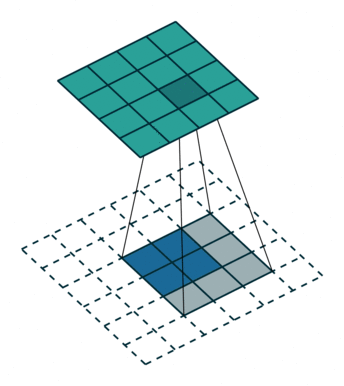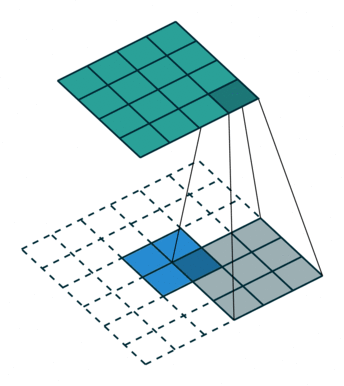
值得一提的是,可以通过各种填充和步长,我们可以将同样的 2 ∗ 2 2*2 2∗2输入映射到不同的图像尺寸。下图,转置卷积被应用在同一张 2 ∗ 2 2*2 2∗2的输入上(输入之间插入了一个零,并且周围加了 2 ∗ 2 2*2 2∗2的单位步长的零填充)上应用 3 ∗ 3 3*3 3∗3的卷积核,得到的结果(即上采样结果)大小为 5 ∗ 5 5*5 5∗5。
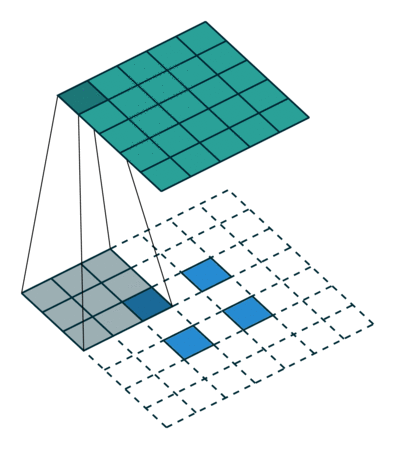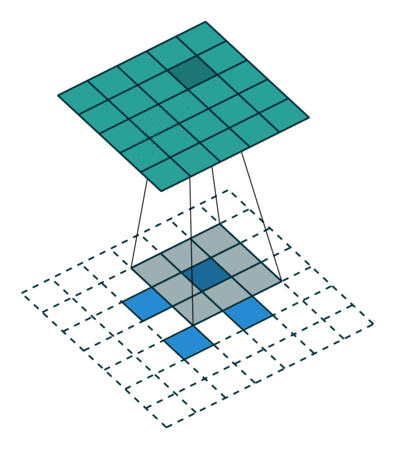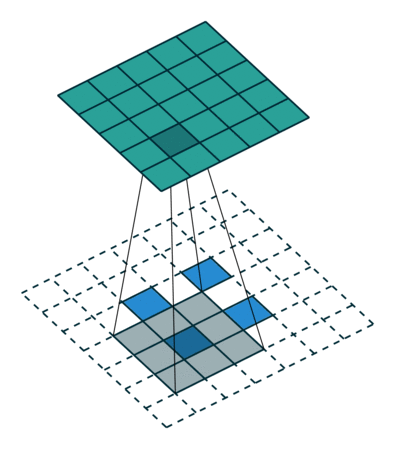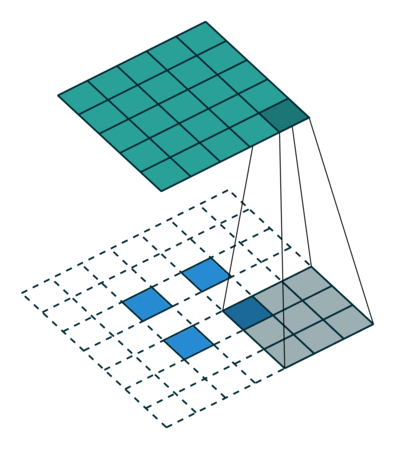
通过观察上述例子中的转置卷积能够帮助我们构建起一些直观的认识。但为了进一步应用转置卷积,我们还需要了解计算机的矩阵乘法是如何实现的。从实现过程的角度我们可以理解为何转置卷积才是最合适的名称。
在卷积中,我们这样定义:用 C C C代表卷积核, i n p u t input input为输入图像, o u t p u t output output为输出图像。经过卷积(矩阵乘法)后,我们将 i n p u t input input从大图像下采样为小图像 o u t p u t output output。这种矩阵乘法实现遵循 C ∗ i n p u t = o u t p u t C*input=output C∗input=output。
下面的例子展示了这种运算在计算机内的工作方式。它将输入平展( 16 ∗ 1 16*1 16∗1)矩阵,并将卷积核转换为一个稀疏矩阵( 4 ∗ 16 4*16 4∗16)。然后,在稀疏矩阵和平展的输入之间使用矩阵乘法。之后,再将所得到的矩阵( 4 ∗ 1 4*1 4∗1)转为 2 ∗ 2 2*2 2∗2输出。
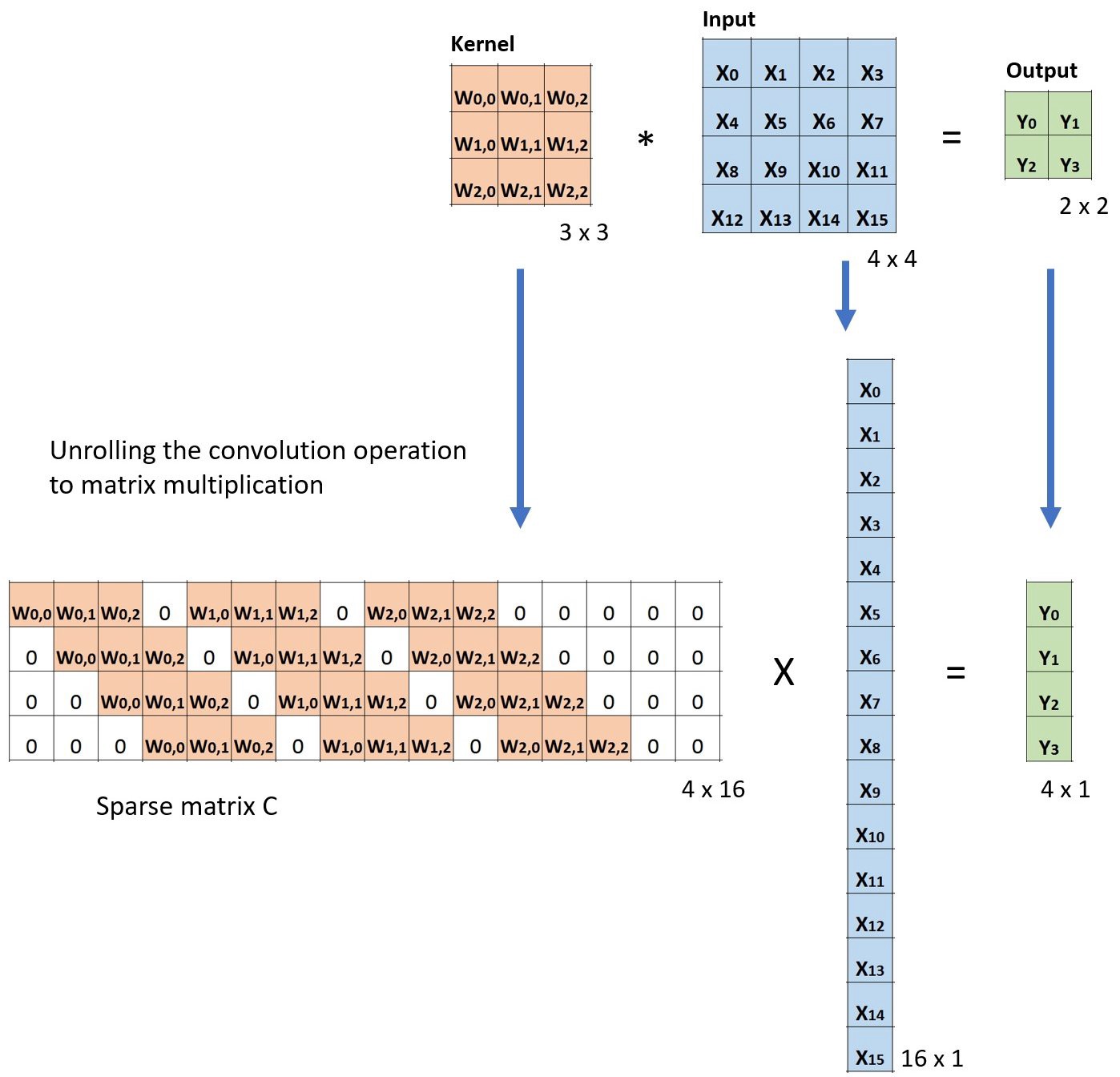
此时,若用卷积核对应稀疏矩阵的转置 C T C^T CT( 16 ∗ 4 16*4 16∗4)乘以输出的平展( 4 ∗ 1 4*1 4∗1)所得到的结果( 16 ∗ 1 16*1 16∗1)的形状和输入的形状( 16 ∗ 1 16*1 16∗1)相同。
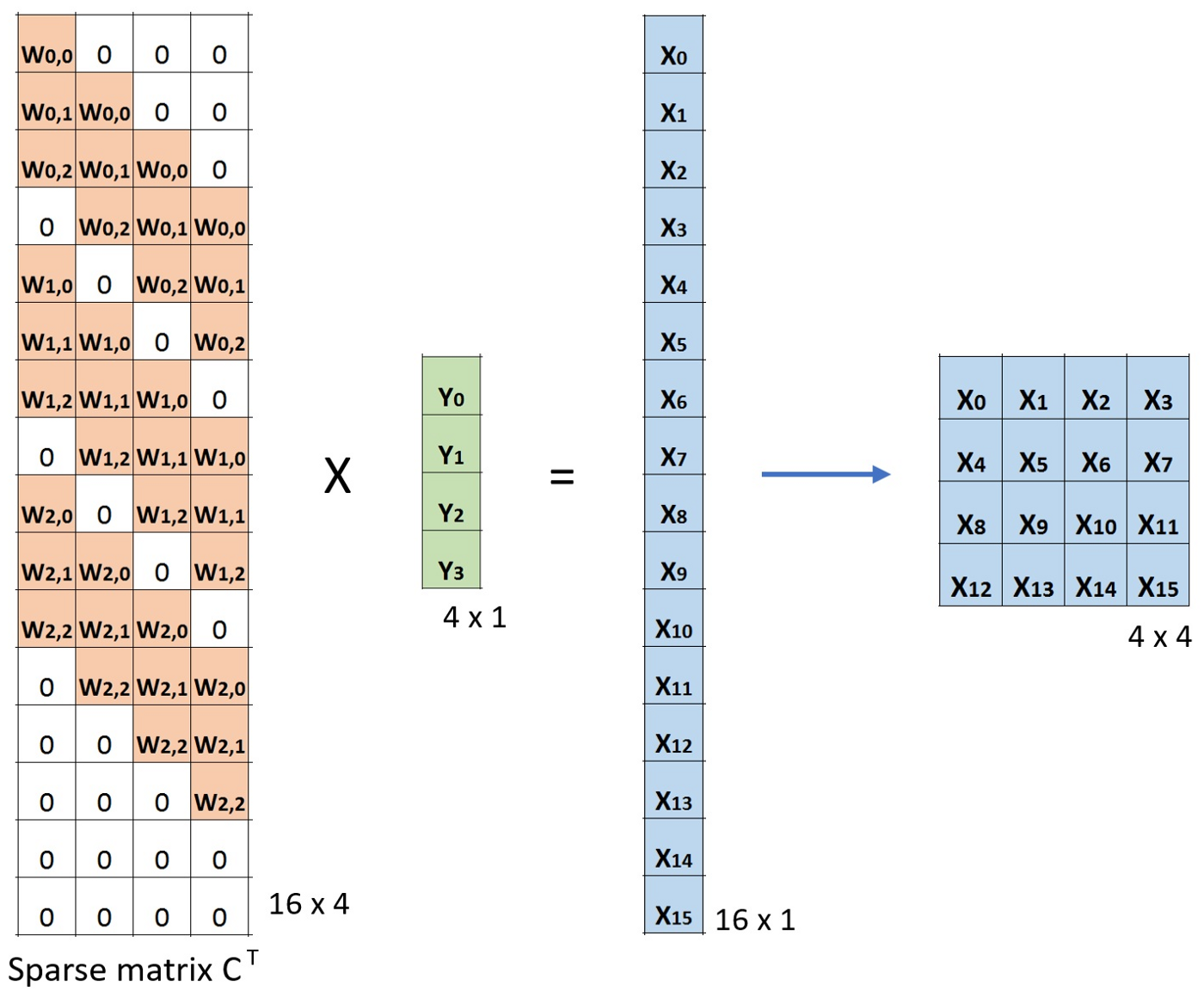
但值得注意的是,上述两次操作并不是可逆关系,对于同一个卷积核(因非其稀疏矩阵不是正交矩阵),结果转置操作之后并不能恢复到原始的数值,而仅仅保留原始的形状,所以转置卷积的名字由此而来。并回答了上面提到的疑问,相比于“逆卷积”而言转置卷积更加准确。
转置矩阵的算术解释可参考:https://arxiv.org/abs/1603.07285
5.1. 棋盘效应(Checkboard artifacts)
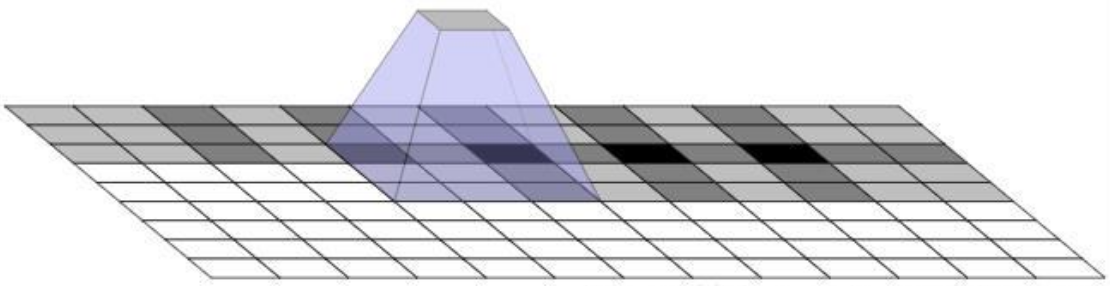
在使用转置卷积时观察到一个棘手的现象(尤其是深色部分常出现)就是"棋盘格子状伪影",被命名为棋盘效应(Checkboard artifacts)。下图直观地展示了棋盘效应(来源:https://distill.pub/2016/deconv-checkerboard/)

本文仅做简要介绍,详细部分请参考论文:Deconvolution and Checkerboard Artifacts
棋盘效应是由于转置卷积的“不均匀重叠”(Uneven overlap)的结果。使图像中某个部位的颜色比其他部位更深。尤其是当卷积核(Kernel)的大小不能被步长(Stride)整除时,反卷积就会不均匀重叠。虽然原则上网络可以通过训练调整权重来避免这种情况,但在实践中神经网络很难完全避免这种不均匀重叠。
下面通过一个详细的例子,更为直观展示棋盘效应。下图的顶部部分是输入层,底部部分为转置卷积输出结果。结果转置卷积操作,小尺寸的输入映射到较大尺寸的输出(体现在长和宽维度)。
在(a)中,步长为1,卷积核为 2 ∗ 2 2*2 2∗2。如红色部分所展示,输入第一个像素映射到输出上第一个和第二个像素。而正如绿色部分,输入的第二个像素映射到输出上的第二个和第三个像素。则输出上的第二个像素从输入上的第一个和第二个像素接收信息。总而言之,输出中间部分的像素从输入中接收的信息存在重叠区域。在示例(b)中的卷积核大小增加到3时,输出所接收到的大多数信息的中心部分将收缩。但这并不是最大的问题,因为重叠仍然是均匀的。
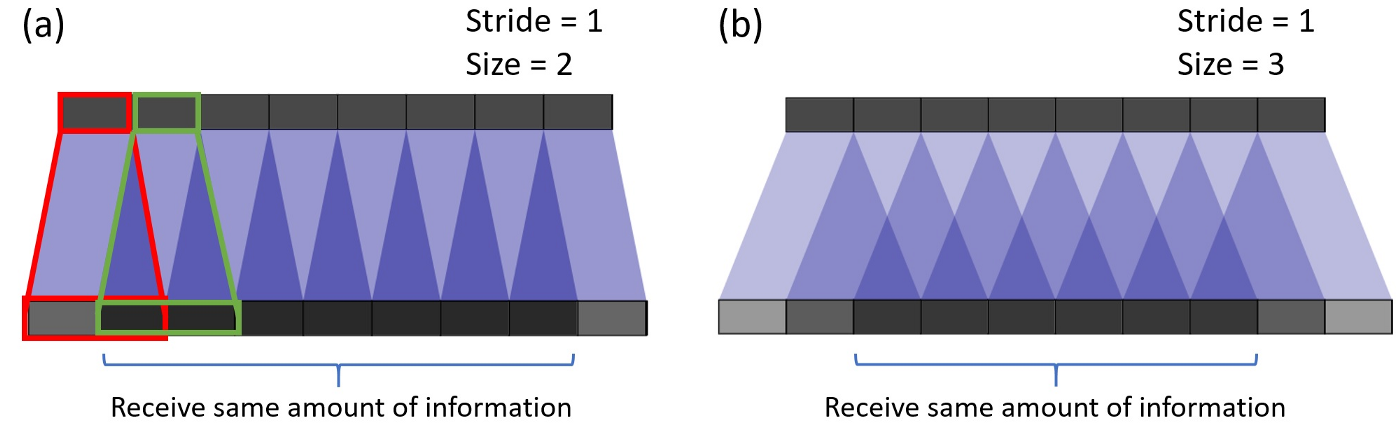
如果将步幅改为2,在卷积核大小为2的示例中,输出上的所有像素从输入中接收相同数量的信息。由下图(a)可见,此时描以转置卷积的重叠。若将卷积核大小改为4(下图(b)),则均匀重叠区域将收缩,与此同时因为重叠是均匀的,故仍然为有效输出。但如果将卷积核大小改为3,步长为2(下图(c)),以及将卷积核大小改为5,步长为2(下图(d)),问题就出现了,对于这两种情况输出上的每个像素接收的信息量与相邻像素不同。在输出上找不到连续且均匀重叠区域。
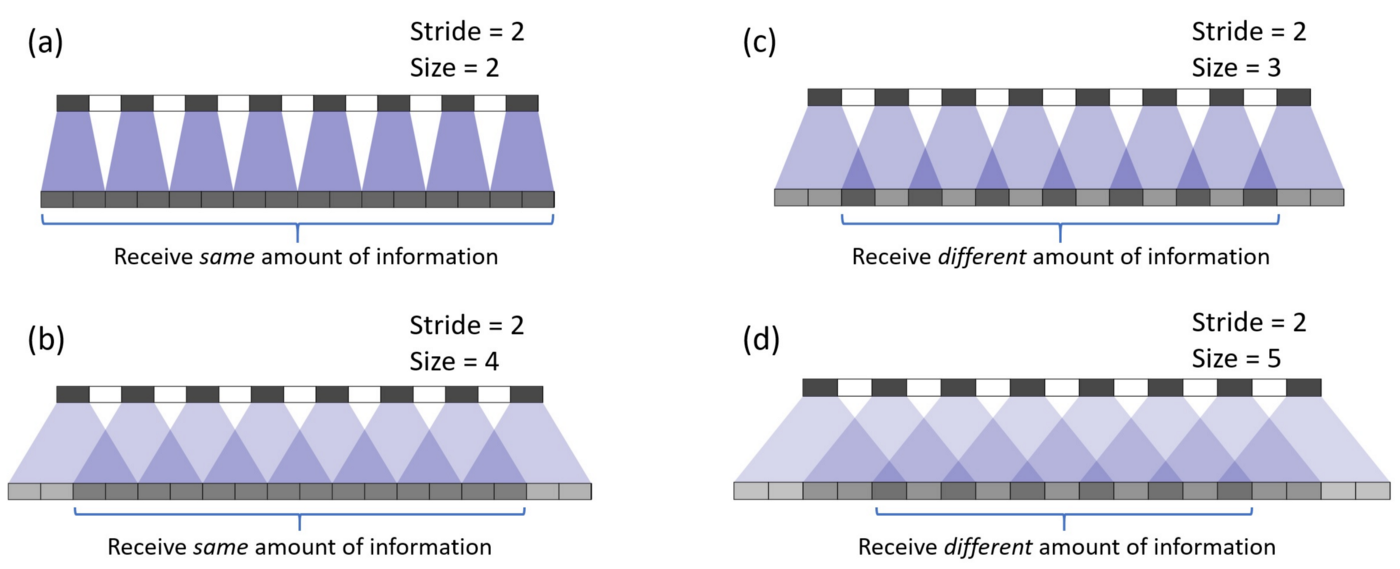
在二维情况下棋盘效应更为严重,下图直观地展示了在二维空间内的棋盘效应。
5.1.1 如何避免棋盘效应
-
采取可以被步长整除的卷积核长度
该方法较好地应对了棋盘效应问题,但仍然不够圆满,因为一旦我们的卷积核学习不均匀,依旧会产生棋盘效应(如下图所示)

-
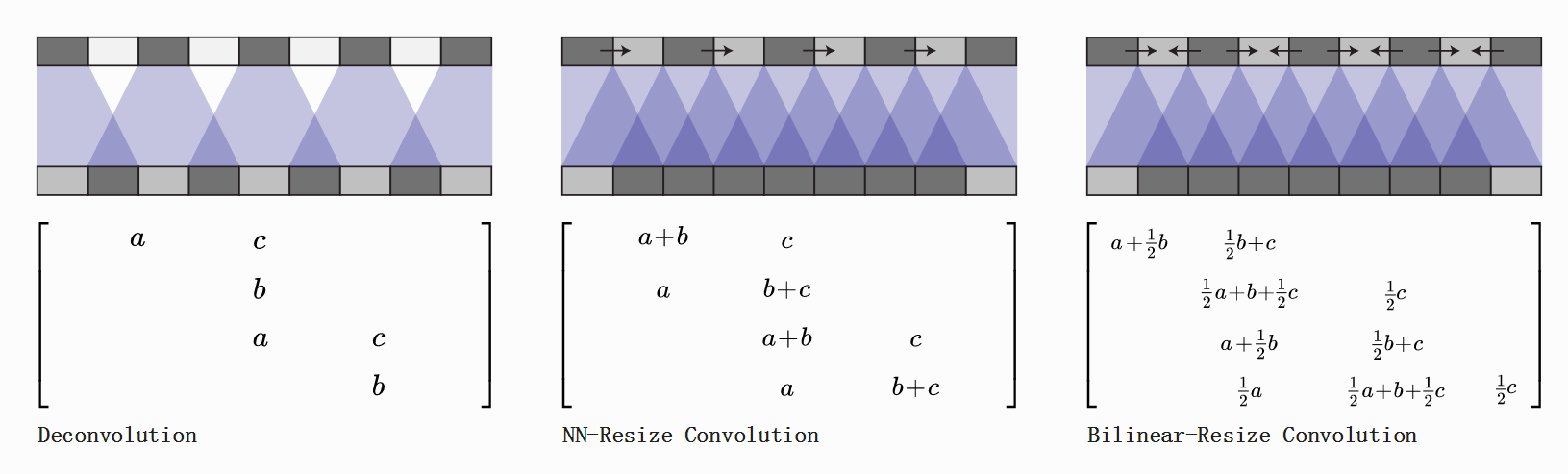
插值
可以直接进行插值Resize操作,然后再进行卷积操作。该方式在超分辨率的相关论文中比较常见。例如我们可以用常见的图形学中常用的双线性插值和近邻插值以及样条插值来进行上采样。
5.2. 转置卷积的计算
输入层: W i n ∗ H i n ∗ D i n W_{in}*H_{in}*D_{in} Win∗Hin∗Din
超参数:
- 过滤器个数: k k k
- 过滤器中卷积核维度: w ∗ h w*h w∗h
- 滑动步长(Stride): s s s
- 填充值(Padding): p p p
输出层: W o u t ∗ H o u t ∗ D o u t W_{out}*H_{out}*D_{out} Wout∗Hout∗Dout
(为简化计算,设 W i n = H i n = i n W_{in}=H_{in}=in Win=Hin=in,则记 W o u t = H o u t = o u t W_{out}=H_{out}=out Wout=Hout=out)
其中输出层和输入层之间的参数关系分为两种情况:
情况一: ( i n − 1 ) ∗ s − 2 p + k = o u t (in-1)*s-2p+k=out (in−1)∗s−2p+k=out
{ o u t = s ∗ ( i n − 1 ) − 2 p + k , D o u t = k \begin{cases} out=s*(in-1)-2p+k, \\ D_{out} = k \end{cases} {out=s∗(in−1)−2p+k,Dout=k
情况二: ( i n − 1 ) ∗ s − 2 p + k ≠ o u t (in-1)*s-2p+k\not=out (in−1)∗s−2p+k=out
{ o u t = s ( i n − 1 ) − 2 p + k + ( o u t + 2 p − k ) % s , D o u t = k \begin{cases} out=s(in-1)-2p+k+(out+2p-k)\%s, \\ D_{out} = k \end{cases} {out=s(in−1)−2p+k+(out+2p−k)%s,Dout=k
这里以经典图像语义分割模型全卷积网络FCN-32s为例,上采样转置卷积的输入为 7 ∗ 7 7*7 7∗7,我们希望进行一次上采样后恢复成原始图像尺寸 224 ∗ 224 224*224 224∗224,代入公式 { o u t = s ∗ ( i n − 1 ) − 2 p + k , o u t = 224 , i n = 7 \begin{cases} out=s*(in-1)-2p+k, \\ out=224,in=7\end{cases} {out=s∗(in−1)−2p+k,out=224,in=7得到一个关于 s , k , p s,k,p s,k,p三者之间的关系等式: 6 s + k − 2 p = 224 6s+k-2p=224 6s+k−2p=224。最后通过实验,得到最合适的一组数据: s = 16 , k = 64 , p = 32 s=16,k=64,p=32 s=16,k=64,p=32。
6. 扩张卷积(空洞卷积)
扩张卷积由这两篇引入:
- https://arxiv.org/abs/1412.7062;
- https://arxiv.org/abs/1511.07122
这是一个标准的离散卷积:
( F ∗ k ) ( p ) = ∑ s + t = p F ( s ) k ( t ) (F*k)(p)=\sum_{s+t=p}F(s)k(t) (F∗k)(p)=∑s+t=pF(s)k(t)
扩张卷积如下:
( F ∗ l k ) ( p ) = ∑ s + l t = p F ( s ) k ( t ) (F*_{l}k)(p) = \sum_{s+lt=p}F(s)k(t) (F∗lk)(p)=∑s+lt=pF(s)k(t)
当 l = 1 l=1 l=1时,扩张卷积变为标准卷积。
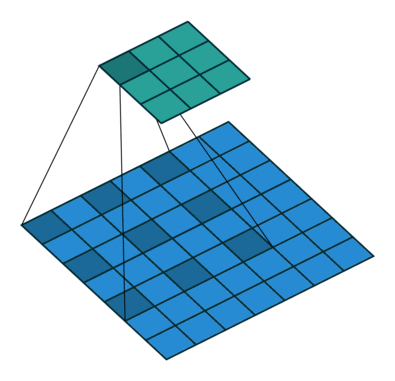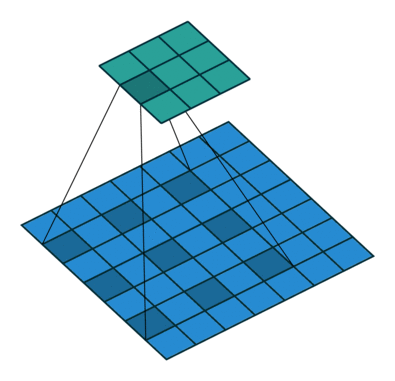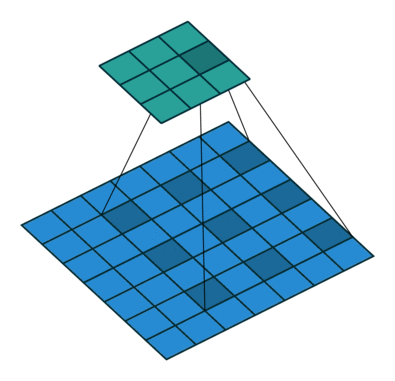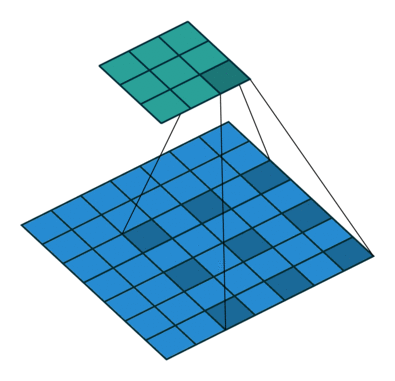
直观地来说,扩张卷积通过在卷积核元素之间插入空格来使得卷积核膨胀。新增加的参数
l
l
l表示扩张率,表示我们希望将卷积核“膨胀”的程度。具体的实现会不同,通常情况下在卷积核元素之间插入
l
−
1
l-1
l−1个空格。下面分别展示了
l
=
1
,
2
,
4
l=1,2,4
l=1,2,4时的卷积核膨胀后的大小。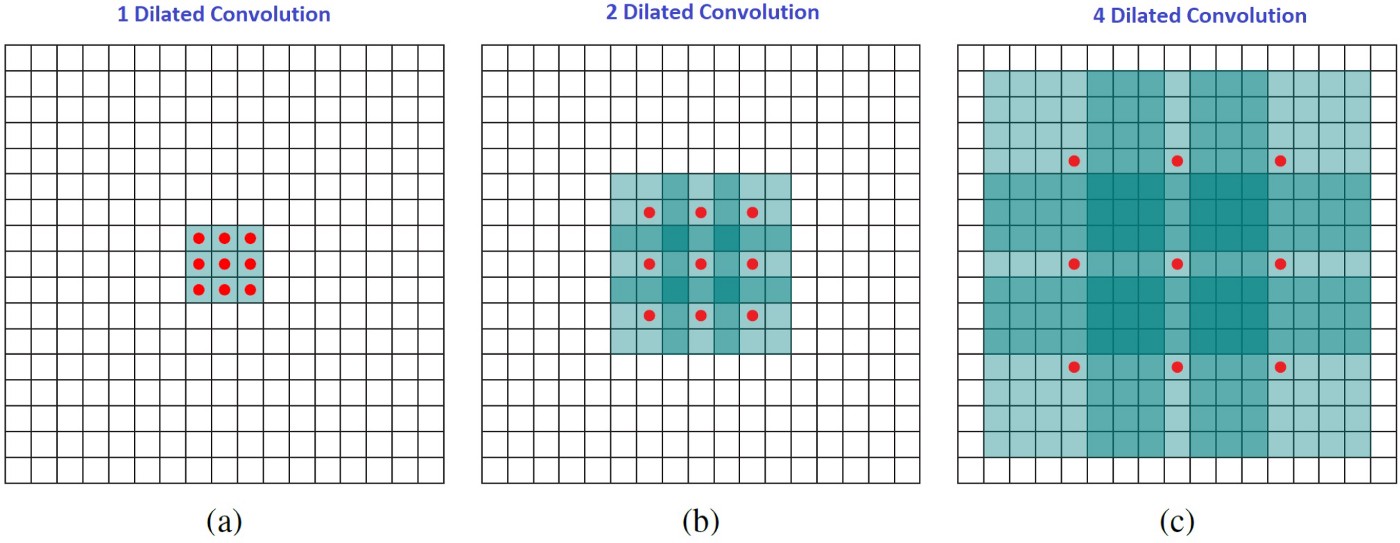 图像中,
3
∗
3
3*3
3∗3个红点表示卷积核原本大小为
3
∗
3
3*3
3∗3。尽管所有这三个扩张卷积的卷积核都是同一尺寸,但模型的感受野却有很大的不同。
l
=
1
l=1
l=1时感受野为
3
∗
3
3*3
3∗3,
l
=
2
l=2
l=2时感受野为
7
∗
7
7*7
7∗7。
l
=
3
l=3
l=3时感受野为
15
∗
15
15*15
15∗15。值得注意的是,上述操作的参数量都是相同的。扩张卷积在不增加计算成本的情况下,能让模型有更大的感受野(因为卷积核尺寸不变),这在多个扩张卷积彼此堆叠时尤其有效。
图像中,
3
∗
3
3*3
3∗3个红点表示卷积核原本大小为
3
∗
3
3*3
3∗3。尽管所有这三个扩张卷积的卷积核都是同一尺寸,但模型的感受野却有很大的不同。
l
=
1
l=1
l=1时感受野为
3
∗
3
3*3
3∗3,
l
=
2
l=2
l=2时感受野为
7
∗
7
7*7
7∗7。
l
=
3
l=3
l=3时感受野为
15
∗
15
15*15
15∗15。值得注意的是,上述操作的参数量都是相同的。扩张卷积在不增加计算成本的情况下,能让模型有更大的感受野(因为卷积核尺寸不变),这在多个扩张卷积彼此堆叠时尤其有效。
论文《Multi-scale context aggregation by dilated convolutions》的作者用多个扩张卷积层构建了一个网络,其中扩张率 l 每层都按指数增大。由此,**有效的感受野大小随层而指数增长,而参数的数量仅线性增长。**这篇论文中扩张卷积的作用是系统性地聚合多个比例的形境信息,而不丢失分辨率。这篇论文表明其提出的模块能够提升那时候(2016 年)的当前最佳形义分割系统的准确度。请参阅那篇论文了解更多信息。
6.1. 扩张卷积的应用
主要讨论扩张卷积在语义分割(Semantic Segmentation)的应用
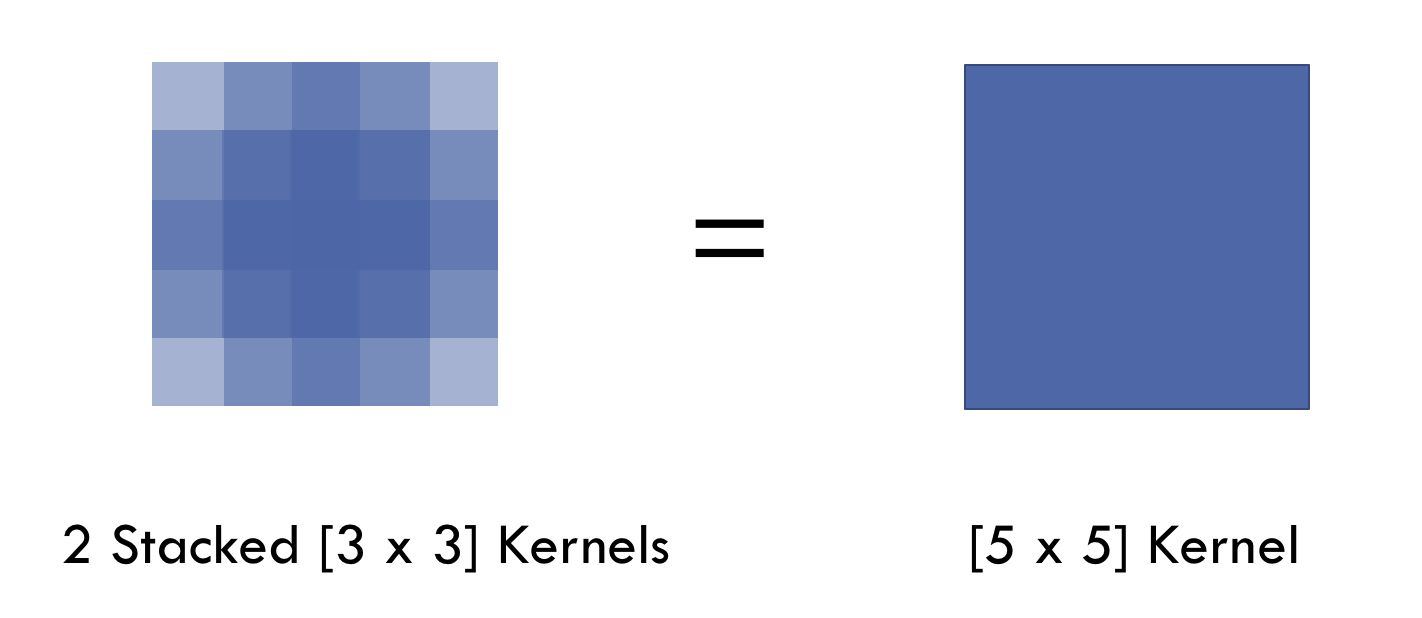
一个 7 ∗ 7 7*7 7∗7的卷积层的正则等效于3个 3 ∗ 3 3*3 3∗3的卷积层的叠加。而这样的设计不仅可以大幅度减少参数量,其本身带有正则性质的卷积核能够更容易学一个可生成和表达的特征空间。这些特点也是现在绝大部分基于卷积的深层网络都在使用小卷积核的原因。
但深层的卷积神经网络对于一些任务仍然存在致命的缺陷。较为突出的是(由上采样和池化层引起):
- 上采样核和池化层是不可逆的
- 内部数据结构丢失;空间层级化信息丢失
- 细节丢失(假设有四个池化层,则任何小于 2 4 = 16 2^4=16 24=16像素的细节将被舍弃,并无法重建。)
在这样的问题存在的情况下,语义分割问题一直处在瓶颈无法再明显提高精度,而扩张卷积的概念就很好避免了上述问题
6.3. 扩张卷积存在的问题
-
**问题一:**网格效应
假设我们仅仅简单地多次叠加扩张卷积 3 ∗ 3 3*3 3∗3卷积核的话,则会出现下图的问题:
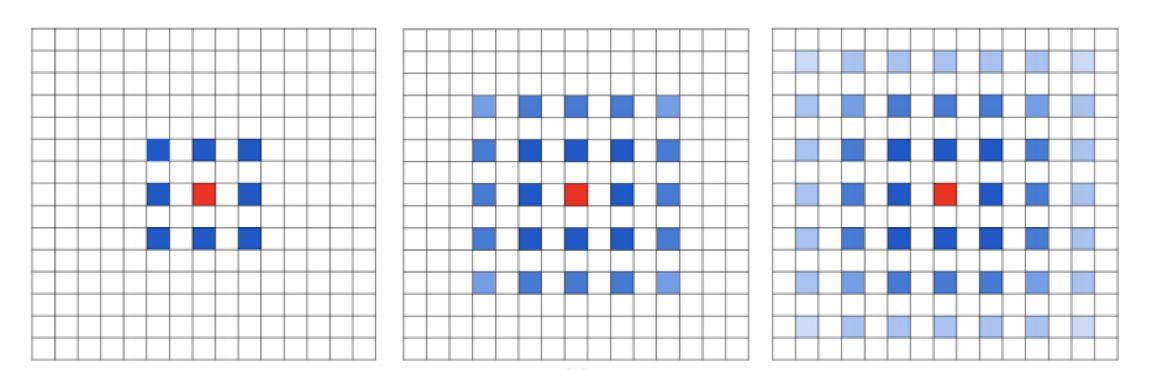 我们发现卷积核并不连续,也就是并不是所有的像素用来计算了,由于图像等信息具有连续性质,这对pixel-level dense prediction 的任务来说是致命的。
我们发现卷积核并不连续,也就是并不是所有的像素用来计算了,由于图像等信息具有连续性质,这对pixel-level dense prediction 的任务来说是致命的。 -
**问题二:****Long-ranged information might be not relevant.
从扩张卷积的设计背景来看就能推测出这样的设计是用来获取 long-ranged information。然而光采用较大扩张率的信息或许只对一些大物体分割有效果,而对小物体来说可能有消极的作用。如何同时处理不同大小的物体的关系(感受野粒度),则是设计好 扩张卷积网络的关键。
对于扩张卷积问题的处理,这里就不详述了。
6.4. 扩张卷积的计算
以卷积核元素之间插入 l − 1 l-1 l−1个空格为例子
输入层: W i n ∗ H i n ∗ D i n W_{in}*H_{in}*D_{in} Win∗Hin∗Din
超参数:
- 扩张率: l l l
- 过滤器个数: k k k
- 过滤器中卷积核维度: w ∗ h w*h w∗h
- 滑动步长(Stride): s s s
- 填充值(Padding): p p p
输出层: W o u t ∗ H o u t ∗ D o u t W_{out}*H_{out}*D_{out} Wout∗Hout∗Dout
其中输出层和输入层之间的参数关系为,
{ w 0 = ( w − 1 ) ∗ ( l − 1 ) + w , h 0 = ( h − 1 ) ∗ ( l − 1 ) + h , W o u t = ( W i n + 2 p − w 0 ) / s + 1 , H o u t = ( H i n + 2 p − h 0 ) / s + 1 , D o u t = k \begin{cases} w_0 = (w-1)*(l-1) + w,\\h_0 = (h-1)*(l-1) + h,\\W_{out} = (W_{in} +2p - w_0)/s + 1 ,\\ H_{out} = (H_{in} +2p - h_0)/s + 1, \\ D_{out} = k \end{cases} ⎩⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎧w0=(w−1)∗(l−1)+w,h0=(h−1)∗(l−1)+h,Wout=(Win+2p−w0)/s+1,Hout=(Hin+2p−h0)/s+1,Dout=k
参数量为: ( w ∗ h ∗ D i n + 1 ) ∗ k (w*h*D_{in} + 1)*k (w∗h∗Din+1)∗k
参考资料
- A Comprehensive Introduction to Different Types of Convolutions in Deep Learning | by Kunlun Bai | Towards Data Science
- Convolutional neural network - Wikipedia
- Convolution - Wikipedia
- 一文读懂卷积神经网络中的1x1卷积核 - 知乎 (zhihu.com)
- [1312.4400] Network In Network (arxiv.org)
- Inception网络模型 - 啊顺 - 博客园 (cnblogs.com)
- ResNet解析_lanran2的博客-CSDN博客
- 一文带你了解深度学习中的各种卷积(上) | 机器之心 (jiqizhixin.com)
- 一文带你了解深度学习中的各种卷积(下)
- 计算机视觉|棋盘效应
- https://www.zhihu.com/question/54149221/answer/323880412
- Intuitively Understanding Convolutions for Deep Learning | by Irhum Shafkat | Towards Data Science
- An Introduction to different Types of Convolutions in Deep Learning
- Review: DilatedNet — Dilated Convolution (Semantic Segmentation)
- ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
- Separable convolutions “A Basic Introduction to Separable Convolutions
- Inception network “A Simple Guide to the Versions of the Inception Network”
- A Tutorial on Filter Groups (Grouped Convolution)
- Convolution arithmetic animation
- Up-sampling with Transposed Convolution
- Intuitively Understanding Convolutions for Deep Learning















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









