






周志华《机器学习》第五章(神经网络)的学习笔记上篇连接在这里:《上篇》。上篇讲到了神经网络、常用的激活函数、感知机和多层前馈神经网络、局部极小和全局最小,今天继续补上昨天落下得部分,也是就是我们的其他神经网络(RBF、ART、SOM等网络)、递归神经网络(如Boltzmann机、Elman网络)的部分。
一、其他神经网络
本小节讲到的其他神经网络为RBF网络、ART网络、SOM网络。 在正式介绍这三种网络时,首先引入竞争型学习概念,竞争型学习讲究的原则为”胜者通吃、肉弱强食“。每一个时刻只有一个”胜出者“,这个”胜出者“的神经元被激活,其他的被抑制。竞争型学习是一种常用的无监督学学习策略。
(1) RBF网络(Radial Basis Function,又称为径向基函数网络),它是一种单隐层前馈神经网络。它使用径向基函数(文末有解释)作为隐层神经元激活函数,输出层是对隐层神经元输出的线性组合。通常的训练RBF网络的步骤: 第一步,确定神经元中心位置,可采取的方法有随机采样和聚类;第二步,利用BP算法确定参数(权重和阈值)。
(2)ART网络(Adaptive Resonance Theory)全名叫做自适应谐振理论网络。(一种竞争型学习)
(3)SOM网络(Self-Organizing Map)叫做自组织映射网路,它也是一种竞争学习型无监督神经网络。
注意,一般的神经网络,它的网络结构是实现固定的,它优化的是权重、阈值等参数。而结构自适应网络可以将网络结构列为了学习的目标之一,它能找着最符合数据结构特点的网络结构。
(4)级联相关网络就是一种结构自适应网络。包含“级联”和“相关”,“级联”是建立层次连接的层级结构。相关知识通过最大化新神经元的输出与网络误差之间的相关性来训练相关的参数。级联相关网络不用设置网络层数、隐层神经元数目,训练速度较快,但是当数据较小容易陷入过拟合。
二、递归神经网络(RNN)
递归神经网络我相信任何一个学习神经网络的都知道。递归神经网络和前馈神经网络很大的一个差异点就是。RNN允许出现环形结构,即输出可以返回来做输入,继续参与到下面的算法中 。常见的递归神经网络如下,
(1)Elman网络:一种常见的递归神经网络,网络结构和多层前馈网络结构类似,只不过隐层神经元的输出返回来了作为下一时刻的输入。而且这个隐层神经元采用的是Sigmoid函数(不知道什么是Sigmoid函数,就点介里),网络的训练通常采用的是推广的BP算法。图1、图2分别是Elman网络结构和多层前馈网络结构。
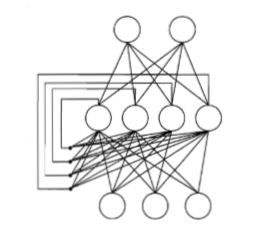

(2)Boltzmann机:一种基于能量的模型,也是一种递归神经网络。什么是基于能量的模型呢?我们都知道在神经网络中有一种模型的状态是用“能量”来定义的,所以能量最小化就是基于能量的模型的理想状态,这个神经网络也是在训练,为了最小化我们的能量。
理论上的Boltzmann机是一个全连接图,这个网络结构的复杂度很高,所以现实生活中我们常常采用受限的Boltzmann机(RBM)进行实操。受限的Boltzmann机受限在哪里呢?RBM只显示显层和隐层,所以这就极大的简化了原先的结构。除此之外RBM采用CD(Contrastive Divergence,对比散度)算法训练。
三、相关定义解释
1、什么是径向基函数?
径向基函数是关于空间中点的函数,且函数值只和距离原点的距离有关(一般使用欧式距离)。
径向基函数的表达式为:ϕ(x)=ϕ(||x||) 。














 298
298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









