







一、问题描述与评价标准
刻画节点的相似性有很多种方法,最简单直接的就是利用节点的属性。近年来,基于网络结构信息的节点相似性刻画得到了越来越多的重视。
节点相似性分析的一个典型应用就是链路预测,它是指如何通过已知的各种信息预测给定网络中尚不存在连边的两个节点之间产生连接的可能性。这种预测包含了对未知连接,也称丢失连接的预测,也包含了对未来连接的预测。基于节点相似性进行链路预测的基本假设就是如果两个节点之间的相似性越大,它们之间存在连接的可能性就越大。链路预测还可以用于预测演化网络中未来可能出现的连接。
给定一个具有N个节点和M条边的无向网络G(V,E)。链路预测的基本思想是为网络中每一对没有连边的节点对(x,y)赋予一个分数S
x
y
_{xy}
xy,然后将所有未连接的节点对按照该值从大到小排序,排在最前面的节点对出现连边的概率最大。
为了测试链路预测算法的准确性,通常将网络中已知的连边集E分为训练集E
T
^T
T和测试集E
P
^P
P两部分:

在计算时只使用测试集的信息,并把不属于现有边集E的任意一对节点之间的可能连边称为不存在的边。衡量链路预测算法精准度的两种常用指标为AUC和Precision。
(1)AUC:AUC是从整体上衡量算法的精准度。它可以理解为,测试集中的边的分数值比随机选择的一个不存在的边的分数值高的概率。也就是说,每次随机从测试集中选取一条边与随机选择的不存在的边进行比较:如果测试集中的边的分数值大于不存在的边的分数值,那么就加1分,如果两个分数值相等就加0.5分。这样独立比较n次,如果有n
′
^{'}
′次测试集中的边的分数值大于不存在的边的分数值,有n
′
′
^{''}
′′次两个分数值相等,那么AUC定义为
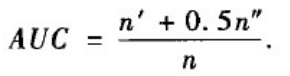
显然,如果所有分数都是随机产生的,那么AUC=0.5。因此AUC大于0.5的程度衡量了算法在多大程度上比随机选择的方法精确。
(2)Precision只考虑排在前L位的边是否预测准确,即前L个预测边中预测准确的比例。如果排在前L位的边中有m个在测试集中,那么Precision定义为:
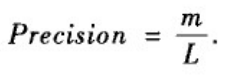
显然,Precision越大预测越准确。如果两个算法AUC相同,而算法1的Precision大于算法2,那么说明算法1更好,因为它倾向于把真正连边的节点对排在前面。
二、基于局部信息的节点相似性指标
两个节点的共同邻居的数量越多,这两个节点就越相似,从而更倾向于相互连接。最简单的基于共同邻居的节点相似性指标定义如下:
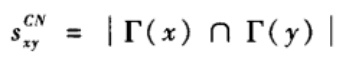
其中,
Γ
\Gamma
Γ(x)为节点x的邻居节点的集合。
在相似性指标的基础上,还可以考虑两个节点的共同邻居的相对数量。
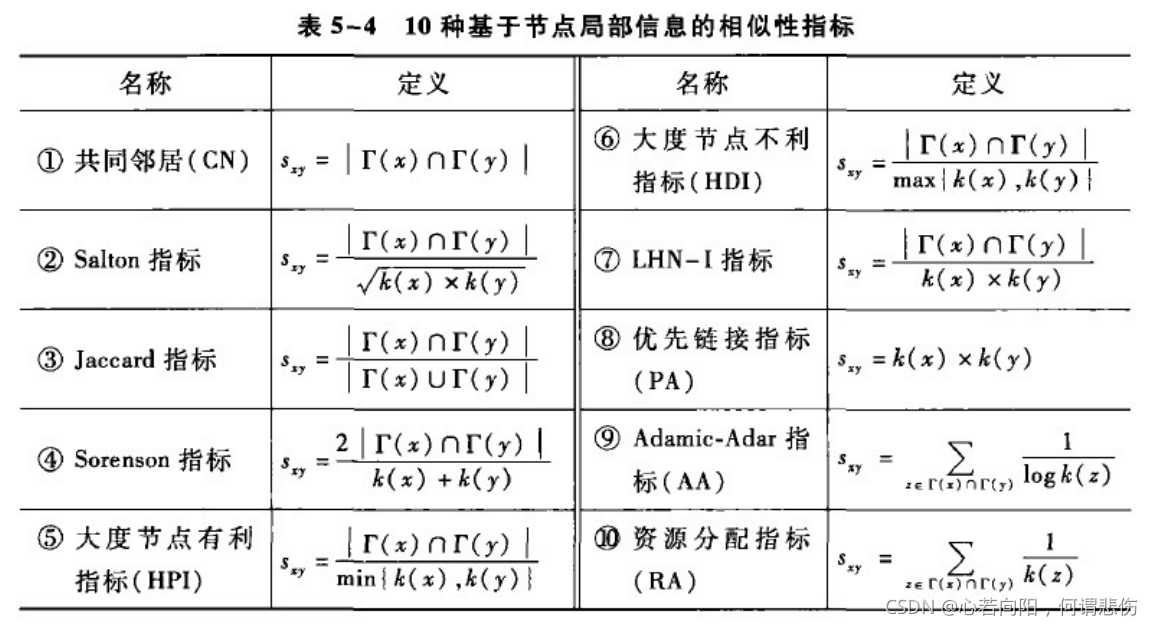
上图列出了10种基于节点局部信息的相似性指标。其中第2到7种相似性指标是直接基于共同邻居指标的不同的规范化而得到的,表中的k(x)=|
Γ
\Gamma
Γ(x)|为节点x的度。第8种指标PA是基于BA无标度网络模型中新加入节点倾向于和度大的节点相连的有限连接机制而提出的。第9种指标AA的基本思想是度小的共同邻居节点的贡献大于度大的共同邻居节点,因此根据共同邻居节点的度为每个节点赋予一个权重值。第10种指标RA是从网络资源分配的角度提出的。RA和AA指标最大的区别就是在于赋予共同邻居节点的权重分别是以1/k,1/logk的形式递减的。
三、基于全局信息的节点相似性指标
基于全局信息的节点相似性指标有以下3种:
(1)局部路径指标。它在共同邻居指标的基础上考虑了三阶邻居的贡献,定义如下:
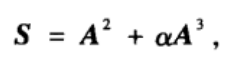
其中
α
\alpha
α为可调节参数,A为网络的邻接矩阵,(A
n
^n
n)
x
y
_{xy}
xy给出了节点x和y之间长度为n的路径数。当
α
\alpha
α=0时,LP指标就等于共同邻居指标。
(2)Katz指标。它考虑的是所有路径数,且对越短的路径赋予越大的权重,定义为:
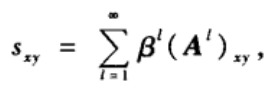
其中
β
\beta
β为权重衰减因子。对应的相似性矩阵如下:
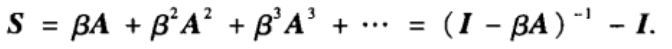
为了保证数列的收敛性,
β
\beta
β的取值必须小于邻接矩阵A最大特征值的倒数。
(3)LHN-II指标。它和Katz指标类似,也是考虑所有的路径,其基本想法是如果两个节点的邻居节点之间是相似的,那么这两个节点之间也是相似的。注意到(A
l
^l
l)
x
y
_{xy}
xy的期望值为:
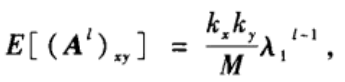
其中
λ
1
\lambda_1
λ1为矩阵A的最大特征值。LHN-II和Katz指标的主要区别是把Katz指标中的(A
n
^n
n)
x
y
_{xy}
xy变为(A
n
^n
n)
x
y
_{xy}
xy/E[(A
n
^n
n)
x
y
_{xy}
xy]。
LHN-II指标的表达式如下:
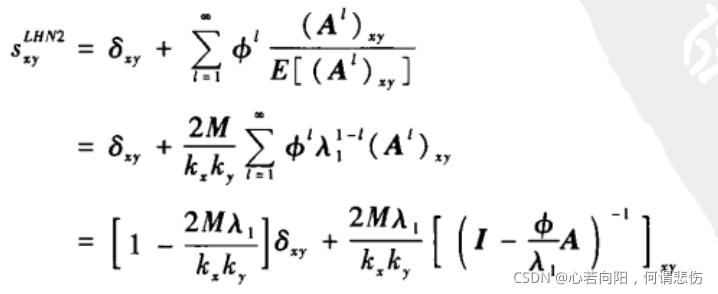
其中
δ
x
y
\delta_{xy}
δxy为Kronecker
δ
\delta
δ函数,
Φ
\Phi
Φ为取值小于1的参数。上式最后一个等式的第一项是可以去掉的对角阵,从而相似性矩阵可以写为:
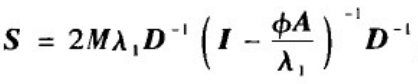
其中D为度值矩阵,D
x
y
_{xy}
xy=
δ
x
y
\delta_{xy}
δxyk
x
_x
x。
四、基于随机游走的相似性指标
基于随机游走的相似性指标有以下6种:
(1)平均通勤时间:设m(x,y)为一个随机粒子从节点x到节点y平均需要走的步数,那么节点x和y的平均通勤时间定义为:
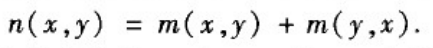
其数值解可通过求该网络拉普拉斯矩阵L的伪逆L
+
^+
+获得,即
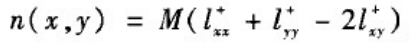
其中l
x
y
+
_{xy}^+
xy+表示矩阵L
+
^+
+中相应位置的元素。如果两个节点的平均通勤时间越小,那么两个节点越接近。由此,定义基于ACT的相似性为:
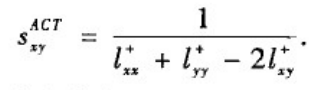
(2)基于随机游走的余弦相似性(Cos+ )。在由向量
ν
x
\nu_x
νx=
Λ
1
/
2
\Lambda^{1/2}
Λ1/2U
T
^T
Te展开的欧式空间内,L
+
^+
+中的元素l
x
y
+
_{xy}^+
xy+可表示为两向量
ν
x
\nu_x
νx和
ν
y
\nu_y
νy的内积,即l
x
y
+
_{xy}^+
xy+=
ν
x
T
ν
y
\nu_x^T\nu_y
νxTνy,其中U是一个标准正交矩阵,由L
+
^+
+特征向量按照对应的特征根从大到小排列,
Λ
\Lambda
Λ为以特征根为对角元素的对角矩阵,e
x
_x
x表示一个一维向量且只有第x个元素为1,其他都为0。由此定义余弦相似性如下:
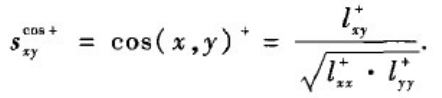
(3)重启的随机游走(RWR)。这个指标可以看成是PageRank算法的拓展应用。它假设随机游走粒子在每走一步的时候都以一定概率返回初始位置。设粒子返回概率为1-c,P为网络的马尔可夫概率转移矩阵,其元素P
x
y
_{xy}
xy=a
x
y
_{xy}
xy/k
x
_x
x表示节点x处的粒子下一步走到节点y的概率。某一粒子初始时刻在节点x处,那么t +1时刻该粒子到达网络各个节点的概率向量为:
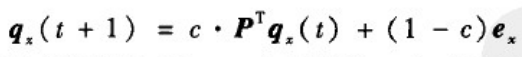
其中e
x
_x
x表示初始状态。上式的稳定解为:
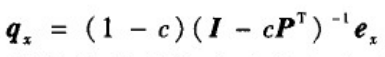
其中元素q
x
y
_{xy}
xy为从节点x出发的粒子最终有多少概率走到节点y。由此定义RWR相似性如下:
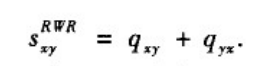
(4)SimRank指标。它的基本假设是,如果两节点所连接的节点相似,那么这两个节点就相似。其定义如下:
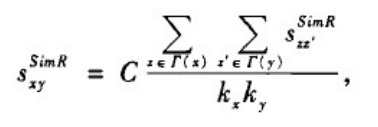
其中假定s
x
x
_{xx}
xx=1,C
∈
\in
∈[0,1]为相似性传递时的衰减参数。SimR可以用来描述两个分别从节点x和y出发的粒子多久会相遇。
(5)局部随机游走指标(LRW)。 该指标与上述4种基于随机游走的相似性不同,它只考虑有限步数的随机游走过程。一个粒子t时刻从节点x出发,定义π
x
y
_{xy}
xy(t)为t+1时刻这个粒子正好走到节点y的概率,那么可得到系统演化方程
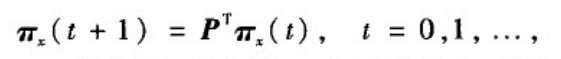
其中π
x
_x
x(0)为一个Nx1的向量,只有第x个元素为1,其他为0,即π
x
_x
x(0)=e
x
_x
x。设定各个节点的初始资源分布为q
x
_x
x,那么基于t步随机游走的相似性为
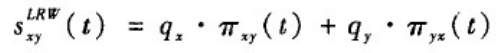
(6)叠加的局部随机游定指标(SRW)。这个指标的想法就是与目标节点更近的节点更有可能与目标节点相连。在LRW的基础上将t步及其以前的结果求和便得到SRW值。即
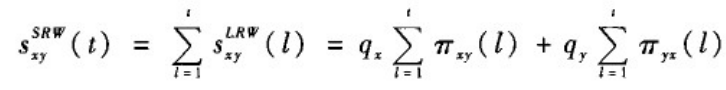

















 283
283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









