









1. 数据分析
什么是数据分析
用适当的统计分析方法对收集的大量数据进行分析,提取有用信息,对数据加以分析和概括的过程。
数据分析师需要具备的能力
- 数理知识
- 数据获取、加工能力
- 行业知识
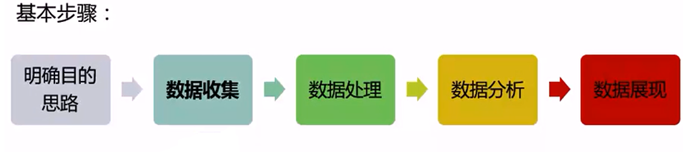
数据分析步骤
2. 数据加载
我们需要将收集的数据加载到内存中,进行下一步的分析。pandas提供丰富读取数据的函数,读取位于不同数据源中的数据
2.1. 常用函数为:
-
read_csv:逗号分隔;返回DataFrame对象,默认将第一行作为DataFrame的列标签;设置header=None,csv文件第一行就不会作为我们的列标签 -
read_table:一般是制表符分隔 -
read_sql
常用参数:
sep/delimiterheadernames:设置列索引index_col:设置行索引usecols:设置从文件中读取我们所需要的列
import numpy as np
import pandas as pd
# read_csv方法读取csv文件,返回DataFrame对象,默认将第一行作为DataFrame的列标签
# df = pd.read_csv('data.csv')
# display(df)
# # 设置header=None,csv文件第一行就不会作为我们的列标签
# df = pd.read_csv('data.csv',header=None)
# display(df)
# sep/delimiter,设置读取分隔符
# df = pd.read_csv('data.csv',header=None,sep='-')
# df = pd.read_csv('data.csv',header=None,delimiter='-')
# display(df)
# names设置列索引
# df = pd.read_csv('data.csv',header=None,names=['姓名','年龄','身高','体重'])
# display(df)
# index_col设置行索引
# df = pd.read_csv('data.csv',header=None,index_col=0)
# display(df)
# usecols设置从文件中读取我们所需要的列
# df = pd.read_csv('data.csv',header=None,usecols=[1,2])
# display(df)
# 如果数据中某列充当行索引,此列的列标签也必须在usecols中设置
df = pd.read_csv('data.csv',header=None,index_col=0,usecols=[0,1,2])
display(df)
2.2. 从 web/数据库/excel/json 中获取数据:
# 1.web中获取数据
# read_table和read_csv都可以获取网络上数据,已经本地文本数据,区别仅仅在于数据的分隔符
# read_table 分隔符 '\t' read_csv 分隔符 ','
# df = pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt')
# display(df.head())
# 2.从数据库中获取数据
# import pymysql
# # 得到数据库连接
# conn = pymysql.connect('localhost','root','root','sxt001')
# # 将sql,conn传入read_sql,读取数据库中数据
# df = pd.read_sql('select * from tb_user',conn)
# display(df.head())
# 3.从excel中读取数据
# df = pd.read_excel('data/Eueo2012_excel.xlsx',sheetname='Eueo2011')
# display(df.head())
# 4.从json中获取数据
df = pd.read_json('data/data.json')
display(df.head())
3. 写入文件
DataFrame与Sereis的 to_csv 方法能将数据写入到文件中
常用参数
index:是否写入行索引,默认为Trueindex_lable:索引字段名称header:是否写入列索引,默认为Truena_rep:空值表示columns:写入的字段,默认为全部写入sep:分隔符
df = pd.DataFrame(np.arange(1,10).reshape(3,3))
display(df)
# to_csv将DataFrame对象写入到文件中
df.to_csv('data.csv')
# df=pd.read_csv('data.csv')
# display(df)
# index,默认为True。使用index设置是否写入行索引,True写入,False不写入
# df.to_csv('data.csv',index=False)
# index_label:设置行索引对象的name信息
# df.to_csv('data.csv',index=True,index_label='index_name')
# header设置DataFrame对象列索引写入,True写入(默认),False不写入
# df.to_csv('data.csv',header=False)
# df[0]=np.nan
# display(df)
# # 空值默认写入到文件中不显示,na_rep指定文件中空值的显示效果
# df.to_csv('data.csv',header=False,na_rep='空')
# columns设置DataFrame对象哪些列写入到文件,默认写入所有的列
# df.to_csv('data.csv',header=False,columns=[1,2])
# sep,默认写入文件以逗号为分隔符,sep可以自定义分隔符
df.to_csv('data.csv',header=False,sep='-')
4. 数据清洗
收集到的数据,无法保证数据一定准确、有效的,需要对其进行清洗。数据清洗包含以下几个方面。
-
处理缺失值
-
处理异常值
-
处理重复值
4.1. 缺失值处理
4.1.1. 发现缺失值
pandas中,将float类型的nan与None视为缺失值,如下方法可检测缺失值:
-
info -
isnull -
notnull
isnull 和 any 或者 all 可以结合使用
4.1.2. 丢弃缺失值
对于缺失值,可通过 dropna 方法进行丢弃处理。
参数:
how:指定 dropna 丢弃缺失值行为,默认为 any,只要存在缺失值,直接丢弃行。axis:指定丢弃行或者丢弃列,默认丢弃行。thresh:当非空数值达到该值时,保留数据,否则删除。inplace:指定是否就地修改,默认为 Flase。
# 读取泰坦尼克号数据-titanic_train.csv
df = pd.read_csv('data/titanic_train.csv',header=None)
display(df)
# 检查缺失值,使用info对整体数据进行查看,显示DataFrame对象每列相关信息
# display(df.info())
# isnull发现缺失值
# display(df.isnull())
# display(df[10].isnull())
# any返回True,说明这一列存在至少一个缺失值
# display(df[10].isnull().any())
# # all返回True,说明这一列都是空值
# display(df[10].isnull().all())
- 处理缺失值:
# 默认情况下,how=any,只要存在缺失值,直接丢弃行
# display(df.dropna())
# how=all,全为缺失值,才丢弃
# display(df.dropna(how='all'))
# 存在空值,默认删除行,设置axis=1,丢弃列
# display(df.dropna(axis=1))
# how设置any和all都不合适,any条件太宽松,all太严格,自定义非空数据少于某个阈值才删除,thresh
# thresh=11,当非空的数据个数少于11个,删除数据
display(df.dropna(thresh=11))
4.1.3. 填充缺失值
对于缺失值,可通过 fillna 方法进行填充
参数:
value:填充所用的值,可以是一个字典,这样为DataFrame不同列指定不同填充值。method:指定上一个有效值填充 (pad / ffill),还是下一个有效值填充 (backfill / bfill)。limit:如果指定 method,表示最大连续 NaN 的填充数量,如果没有指定method,表示最大的 NaN 填充数量。inplace:指定是否就地修改,默认为 False。
# 读取泰坦尼克号数据-titanic_train.csv
df = pd.read_csv('data/titanic_train.csv',header=None)
# display(df)
# 1.使用固定值(均值或中位数)填充所有列缺失值
# display(df.fillna(1000))
# 2.提供字典,为不同列填充不同值。key指定填充对应的索引,value指定填充值
# display(df.fillna({5:500,10:1000}))
# 3.method,指定前后的有效数据填充
# display(df.fillna(method='ffill'))
# display(df.fillna(method='bfill'))
# 4.limit,单独使用,表示每列总共填充缺失值个数
# display(df.fillna(value=1000,limit=1))
# 5.limit参数结合使用,表示最多连续填充个数
display(df.fillna(method='bfill',limit=2))
4.2. 无效值处理
4.2.1. 检测无效值
通过 DataFrame 的 describe 方法查看数据统计,不同类型统计信息不同。基于统计信息,再结合业务来检查无效值。
# df = pd.read_csv('data.csv',header=None)
# display(df)
# display(df.describe())
df = pd.read_csv('data/titanic_train.csv')
# display(df)
# display(df.describe())
display(df[['Name','Sex','Ticket']].describe())
4.3. 重复值处理
对于数据中的重复数据,通常将重复数据删除。
4.3.1. 发现重复值
- 通过
duplicated方法发现重复值。该方法返回Series类型对象,值为布尔类型,表示是否与上一行重复。
-
参数说明:
-
subset:指定重复规则,默认为所有列。
-
keep:指定数据标记为重复 (True) 的规则,默认为 first。重复N条数据,first–后面重复的的数据标记为True,last–前面重复的的数据比较为True;False–所有重复的数据都标记为True4.3.2. 删除重复值
-
- 通过
drop_duplicates删除重复值。
-
参数说明:
-
subset:指定重复规则,默认为所有列。 -
keep:指定记录删除(或保留)的规则,默认为first(第一个出现的数据不删除)。 -
inplace:指定会否就地删除,默认为False(不会就地删除重复值)。
-
df = pd.read_csv('data/duplicate.csv',header=None)
display(df)
# 1.duplicate检查重复值,返回的Sereis对象,True表示重复,False表示不重复
# display(df.duplicated())
# 结合any,判断整个数据是否有重复的数据
# display(df.duplicated().any())
# 2.keep参数:重复N条数据,first-后面重复的的数据标记为True,last--前面重复的的数据比较为True;False,所有的数据都标记为True
# display(df.duplicated(keep='last'))
# display(df.duplicated(keep=False))
# 3.subset 指定重复规则,默认所有列重复才重复
# display(df.duplicated(subset=[0,1]))
# 4.删除重复数据
df.drop_duplicates(keep='first')
5. 数据过滤 query
方法:
- 使用布尔数组或者索引数组来过滤数据。
- 另外也可以使用 DataFrame 的
query方法来进行数据过滤;如果query方法中使用外面定义的变量需要在变量前加上@。
df = pd.read_csv('data/titanic_train.csv')
# display(df)
# 1.给定一个条件,根据条件生成布尔数组
# display(df['Survived']==1)
# 将得到的布尔数组传回给DataFrame对象进行过滤
# display(df[df['Survived']==1])
# 注意点,返回的是一个新的DataFrame对象
# df = df[df['Survived']==1]
# display(df)
# 2.多个条件
# bArray=(df['Survived']==1)&(df['Pclass']==1)
# display(df[bArray])
# 3.使用query方法进行过滤
# 1个条件
# display(df.query('Survived==1'))
# 多个条件
# display(df.query('(Survived==1)&(Pclass==1)'))
# 条件值为变量
val = 1
display(df.query('Survived==@val'))
6. 数据转换
6.1. 应用与映射 apply()/map()/applymap()
Sereis和DataFrame都有对元素的映射转换操作;DataFrame作为二维数据还具有行和列对应转换操作。
对于Sereis,可以调用apply或者map方法。对于DataFrame,可以调用 apply 或 applymap 方法。
-
apply():- 可以处理的对象:对 Sereis,DataFrame 进行应用和映射的数据转换。
- 参数:向apply方法传递函数,需要定义一个参数。对于Sereis,依次传递每一个元素给参数。对于DataFrame,依次传递每一行或者每一列(取决于axis参数),DataFrame传递行和列对象。
- 函数返回值表示参数处理后的结果。
- 参数axis和之前一直谈到的有区别,axis=0列的数据,axis=1 行的数据(新版的改过来了 链接)。参数axis决定了返回的是行还是列。
-
map():-
可以处理的对象:map函数适用于Series对象。
-
参数:对当前Series的值进行映射转换。参数可以是 Series,字典或者函数。传入函数,和apply方法没有区别
-
映射规则(参见下面代码):取s中一个值,和map_series索引进行匹配,匹配上,找到对应map_series中值映射给s。如果指定参数index值,可以替代s的值。
-
在字典中(参见下面的代码):取s中一个值,和map_dict的key值进行匹配,匹配上,找到key对应value值映射给s。
-
-
applymap():-
可作用的参数:DataFrame的元素转换映射操作。
-
参数:传入函数实现元素的映射转换。
-
函数作为参数,DataFrame的每一个元素都会调用一次该函数,将元素传递给该函数。处理后通过函数返回值返回映射结果。
-
- apply() 处理 Series:
# apply可以对Sereis,DataFrame进行应用和映射的数据转换
# 向apply方法传递函数,需要定义一个参数。对于Sereis,依次传递每一个元素给参数。对于DataFrame,依次传递每一行或者每一列(取决于axis参数)
# 函数返回值表示参数处理后的结果
# 1.apply方法,依次将s的元素传递给handle方法参数,handle方法对元素进行处理,将处理的结果返回
def handle(x):
return x**2,x**3
# s = pd.Series([1,2,3,4])
# s = s.apply(handle)
# display(s)
# 2.函数特别简单时候,只有一行语句,lambda表达式,给apply传入匿名方法
# s = pd.Series([1,2,3,4])
# s = s.apply(lambda x:x**3)
# display(s)
# 3.返回多个值
s = pd.Series([1,2,3,4])
s = s.apply(handle)
display(s)
- apply() 处理 DataFrame:
# 1.apply处理DataFrame
# 每行的female-->女,male-->男
def handle(row):
if row.loc['Sex']=='female':
row.loc['Sex']='女'
else:
row.loc['Sex']='男'
return row
df = pd.read_csv('data/titanic_train.csv')
display(df.head())
# 2.axis和之前一直谈到的有区别,axis=0-->列的数据,axis=1-->行的数据
df = df.apply(handle,axis=1)
display(df.head())
- map():
# map函数适用于Series对象
# 1. 传入函数,和apply方法没有区别
# s = pd.Series([1,2,3,4])
# # s = s.map(lambda x:x**2) # 结果和apply()一样
# s = s.apply(lambda x:x**2)
# display(s)
# 2. 传入Series
# s = pd.Series([1,2,3,4])
# map_series = pd.Series([11,12,13,14]) # 注意和下面的区别!
# map_series = pd.Series([11,12,13,14],index=[1,2,3,4])
# display(s,map_series)
# # 取s中一个值,和map_series索引进行匹配,匹配上,找到对应map_series中值映射给s
# display(s.map(map_series))
# 3. 传入字典
s = pd.Series([1,2,3,4])
map_dict={1:11,2:12,3:13,4:14}
# 取s中一个值,和map_dict的key值进行匹配,匹配上,找到key对应value值映射给s
display(s.map(map_dict))
- applymap():
# applymap对DataFrame的元素转换映射操作
# 函数作为参数,DataFrame的每一个元素都会调用一次该函数,将元素传递给该函数。处理后通过函数返回值返回映射结果
df = pd.read_csv('data/titanic_train.csv')
# display(df.head(),df.info())
display(df[['Age','Fare']])
df = df[['Age','Fare']].applymap(lambda x:x+10000)
display(df)
# 报错!对所有列的数据进行操作
# df = df.applymap(lambda x:x+10000)
# display(df.head())
6.2. 替换 replace
Sereis 和 DataFrame 可以通过 replace 方法实现元素值的替换。
-
to_replace:被替换值,支持单一值、列表、字典和正则表达式。 -
regex:是否使用正则表达式,默认为False。
##### replace 元素替换 #####
df = pd.read_csv('data/bikes.csv')
# display(df.head(),df.info())
# 1.replace单一值的替换 对DataFrame
# df = df.replace('4/16/2010','2010-4-16')
# display(df.head())
# 2.replace单一值的替换 对Series
# s = df['THEFT_DATE'].replace('4/16/2010','2010-4-16')
# display(s.head())
# 3.replace支持列表 将列表元素替换value指定的值
# s = df['THEFT_DATE'].replace(['4/16/2010','4/24/2010'],'2010-4-16')
# display(s.head())
# 4.replace支持列表多个值,每个替换为不同的值。列表执行对应位置替换
# s = df['THEFT_DATE'].replace(['4/16/2010','4/24/2010'],['2010-4-16','2010-4-24'])
# display(s.head())
# 5.replace支持字典方式将多个值替换为不同的值,key指定要替换的值,value指定要替换什么值
# s = df['THEFT_DATE'].replace({'4/16/2010':'2010-4-16','4/24/2010':'2010-4-24'})
# display(s.head())
# 6.支持正则表达式:把含有4/16的日期代替为2010
s = df['THEFT_DATE'].replace('4/16/[0-9]{4}','2010',regex=True)
display(s.head())
- replace 同样可以使用
map或者applymap来实现
def m(item):
if item=='4/16/2010':
return '2010-4-16'
return item
# replace同样可以使用map或者applymap来实现
df = pd.read_csv('data/bikes.csv')
s = df['THEFT_DATE'].map(m)
display(s.head())
6.3. 字符串向量化运算 (str)
Series含有 str 属性;通过 str 能对字符串进行向量级运算,从而对数据进行转换(str 属性中有很多方法)。
replace同样可以使用map或者applymap来实现
# 1.Series 的str属性,支持向量化操作,实现数据转换
# s= pd.Series([1,2,3])
# display(s,s.dtype)
# 错误!!使用Sereis的str属性时,需要Series元素值是str(字符串)类型
# display(s.str)
# s= pd.Series(['a','b','c'])
# # display(s,s.dtype)
# 2.pandas.core.strings.StringMethods提供了很多方法(和python中str类型提供方法类似的),进行字符串向量化操作
# display(s.str)
# display(s.str.upper())
# display(s.str.contains('b'))
# 3.对数据做过滤
# df = pd.read_csv('data/earthquake_week.csv')
# # display(df.head())
# # 留下CA,其他的去掉
# barray = df['place'].str.endswith('CA')
# df = df[barray]
# display(df)
# 4.split 方法对数据进行拆分
df = pd.read_csv('data/earthquake_week.csv')
display(df.head())
# expand=False,用一个列表存放拆分后的数据,expand=True,拆分为多列
# display(df['place'].str.split(',',expand=True))
7. 数据合并
7.1. concat
通过pandas的 concat 方法,对DataFrame或者Series类型的进行连接操作。连接时,默认根据索引对齐,如果不对齐,产生空值。
axis:指定连接轴,默认为0join:指定连接方式,默认为外连接。参数值outer:并集;inner:交集keys:用来区分不同的数据组join_axes:指定连接结果集中保留的索引ignore_index:忽略原来连接索引,创建新的整数序列索引,默认为False
# df1 = pd.DataFrame(np.arange(1,10).reshape(3,3))
# df2 = pd.DataFrame(np.arange(10,19).reshape(3,3),columns=[1,2,3])
# display(df1,df2)
# 1.进行concat连接时候,根据索引(默认索引)对齐合并,如果不对齐,产生空值
# display(pd.concat((df1,df2)))
# 2.axis指定数据连接方向,axis=0 竖直,列索引对齐;axis=1水平方向,行索引对齐
# df1 = pd.DataFrame(np.arange(1,10).reshape(3,3))
# df2 = pd.DataFrame(np.arange(10,19).reshape(3,3),index=[1,2,3])
# display(df1,df2)
# display(pd.concat((df1,df2),axis=1))
# 3.join参数指定连接方式:inner显示公共内容,outer显示所有的内容
# df1 = pd.DataFrame(np.arange(1,10).reshape(3,3))
# df2 = pd.DataFrame(np.arange(10,19).reshape(3,3),columns=[1,2,3])
# display(df1,df2)
# display(pd.concat((df1,df2),join='outer'))
# 4.keys:观察新的DataFrame中数据的来源
# df1 = pd.DataFrame(np.arange(1,10).reshape(3,3))
# df2 = pd.DataFrame(np.arange(10,19).reshape(3,3),columns=[1,2,3])
# display(pd.concat((df1,df2),keys=['df1','df2']))
# 5.通过join_axes指定要保留的索引
# df1 = pd.DataFrame(np.arange(1,10).reshape(3,3))
# df2 = pd.DataFrame(np.arange(10,19).reshape(3,3),columns=[1,2,3])
# display(pd.concat((df1,df2),join_axes=[df2.columns]))
# 6.ignore_index=True 忽略之前的索引,重新创建连续的索引
df1 = pd.DataFrame(np.arange(1,10).reshape(3,3))
df2 = pd.DataFrame(np.arange(10,19).reshape(3,3),columns=[1,2,3])
display(pd.concat((df1,df2),ignore_index=True))
7.2. append
(上一个小节的前面内容)Series或DataFrame的append方法可以对行进行连接操作
7.3. merge
通过pandas或者DataFrame的 merge 方法,可以进行两个DataFrame的连接,这种连接类似于SQL中对两张表进行join连接。
步骤:(默认情况下inner)
- 数据组合(像SQL中的join一样挨个连接数据)
- 根据所有的同名列进行等值显示(同名列中的当前行的数据相同!)

参数:
how:指定连接方式,可以是inner,outer,left,right,默认为inneron:指定连接使用的列(该列必须同时出现在两个DataFrame中),默认使用使用两个DataFrame所有同名列连接。left_on / right_on:指定左右DataFrame连接所使用的列。left_index / right_index:是否将左边(右边)DataFrame的行索引作为连接列,默认为False。- 可以通过left_index,right_index指定是否用行索引来充当连接条件。True,是;False,否。
- 使用行索引作为等值连接条件,就能指定列索引作为等值连接条件 --> left_index(right_index)与left_on(right_on)不能同时指定
suffixes:当两个DataFrame列名相同时,指定每个列名的后缀(用来区分),默认为_ x与_ y。
# 数据库内连接步骤: 1.数据组合 2.根据等值条件显示
# DataFrame merge连接步骤:1 数据组合 2 根据等值条件显示
# 列名都相同,且列值也相同
df1 = pd.DataFrame(np.array([[1,2],[3,4]]))
df2 = pd.DataFrame(np.array([[1,2],[3,4]]))
display(df1,df2)
display(df1.merge(df2))
# 列名都相同,同名列存一个一个不相等值
# df1 = pd.DataFrame(np.array([[1,2,3],[3,4,5]]))
# df2 = pd.DataFrame(np.array([[1,2,4],[3,4,6]]))
# display(df1,df2)
# display(df1.merge(df2))
# 列名存在不同
df1 = pd.DataFrame(np.array([[1,2,3],[3,4,5]]))
df2 = pd.DataFrame(np.array([[1,2,4],[3,4,6]]),columns=[0,1,3])
display(df1,df2)
display(df1.merge(df2))
- how
# how设置连接方式
df1 = pd.DataFrame(np.array([[1,2,3],[3,4,5]]))
df2 = pd.DataFrame(np.array([[1,2,4],[3,4,6]]))
display(df1,df2)
# # 默认内连接,连接不上时候,不会在结果中显示
# display(df1.merge(df2,how='inner'))
# # 外连接,连接不上,2个DataFrame都会在结果中显示
# # display(df1.merge(df2,how='outer'))
# # 左连接,左边的DataFrame数据显示
# display(df1.merge(df2,how='left'))
# # 右连接,右边的DataFrame数据显示
display(df1.merge(df2,how='right'))
- on
# 2个DataFrame连接时候,默认将所有的同名列索引作为连接条件
# on指定列作为连接条件,必须同时在两个DataFrame中出现
df1 = pd.DataFrame(np.array([[1,2,3],[3,4,5]]))
df2 = pd.DataFrame(np.array([[1,2,4],[3,4,6]]))
display(df1,df2)
# # 默认将所有的同名列索引作为连接条件
# display(df1.merge(df2))
# 设置Df1和Df2中0列作为连接条件
# display(df1.merge(df2,on=0))
# 设置Df1和Df2中0、1列作为连接条件
display(df1.merge(df2,on=[0,1]))
- left_on / right_on
# 默认根据2个Df的相同的列名等值连接
# left_on right_on 指定2个DF的等值连接列名
df1 = pd.DataFrame(np.array([[1,2,3],[3,1,5]]))
df2 = pd.DataFrame(np.array([[2,1,4],[3,3,6]]))
display(df1,df2)
display(df1.merge(df2,left_on=0,right_on=1))
- left_index / right_index
# 可以通过left_index,right_index指定是否用行索引来充当连接条件。True,是;False,否
# 使用行索引作为等值连接条件,就能指定列索引作为等值连接条件--》left_index(right_index)与left_on(right_on)不能同时指定
df1 = pd.DataFrame(np.array([[1,2,3],[3,4,5]]))
df2 = pd.DataFrame(np.array([[1,2,4],[3,4,6]]))
display(df1,df2)
# Df1的行索引为0 1,df2行索引为0 1,值相等,数据可以连接
display(df1.merge(df2,left_index=True,right_index=True))
- suffixes
# suffixes自定义同名列后缀
# 2个Df连接后,存在同名列,默认同名列后缀_x _y,通过suffixes自定义后缀
df1 = pd.DataFrame(np.array([[1,2,3],[3,4,5]]))
df2 = pd.DataFrame(np.array([[1,2,4],[3,4,6]]))
display(df1,df2)
# Df1的行索引为0 1,df2行索引为0 1,值相等,数据可以连接
display(df1.merge(df2,left_index=True,right_index=True,suffixes=['_df1','_df2']))
7.4. join
与merge方法类似,但是默认使用行索引进行连接。
how:指定连接方式。可以使用Inner、outer、left、right,默认是left。on:设置当前DataFrame使用哪个列与参数DataFrame对象的行索引进行连接。isuffix / rsuffix:当两个DataFrame列名相同时,指定每个列名的后缀(用来区分),如果不指定,列名相同会产生错误。
步骤:
- 数据组合
- 数据等值连接显示
join 和merge的区别:
-
merge测试根据列来等值连接显示,join侧重于根据行索引来做等值连接显示
-
出现同名列索引,merge会自动补后缀(_x,_y);但是join不会自动补后缀,产生错误,lsuffix和rsuffix指定后缀。
-
merge默认进行内连接,join默认进行左外连接how参数设置连接方式。
-
merge中on参数,指定2个DataFrame的同名列;join的on参数,仅仅指定左边(第一个)DataFrame中列,右边(第二个)DataFrame依旧是行索引。
# join和merge类似,都是进行两个DataFrame的连接,理解为2个步骤:1 数据组合 2 数据等值连接显示
# merge测试根据列来等值连接显示,join侧重于根据行索引来做等值连接显示
# df1 = pd.DataFrame(np.array([[1,2,3],[3,4,5]]))
# df2 = pd.DataFrame(np.array([[1,2,4],[3,4,6]]))
# display(df1,df2)
# 1.出现同名列索引,merge会自动补后缀(_x,_y);但是join不会自动补后缀,产生错误,lsuffix和rsuffix指定后缀
# display(df1.join(df2,lsuffix='_df1',rsuffix='_df2'))
# df1 = pd.DataFrame(np.array([[1,2,3],[3,4,5]]))
# df2 = pd.DataFrame(np.array([[1,2,4],[3,4,6]]),columns=[3,4,5],index=[1,2])
# display(df1,df2)
# 2.merge默认进行内连接,join默认进行左外连接
# how参数设置连接方式
# display(df1.join(df2,lsuffix='_df1',rsuffix='_df2',how='inner'))
df1 = pd.DataFrame(np.array([[1,2,3],[3,4,5]]))
df2 = pd.DataFrame(np.array([[1,2,4],[3,4,6]]),columns=[3,4,5],index=[1,2])
display(df1,df2)
# 3.merge中on参数,指定2个DataFrame的同名列;join的on参数,仅仅指定左边(第一个)DataFrame中列,右边(第二个)DataFrame依旧是行索引
# df1中列索引为0的值是1、3,df2中行索引的值1、2,存在相同值1
# 将df1中[1,2,3]和df2中行索引为1对应的[1,2,4]连接显示
# display(df1.join(df2,lsuffix='_df1',rsuffix='_df2',how='inner',on=0))
display(df1.join(df2,lsuffix='_df1',rsuffix='_df2',how='inner',on=2)) # 没有一条数据可以连接在一起
7.6. concat / merge / join 比较:
- concat 数据连接时候,默认根据列索引来对齐,数据纵向连接;使用concat时,axis=1根据行索引对齐,进行数据水平连接。
- merge 和 join:都理解为2步:1.数据水平组合在一起;2.据等值连接条件显示。 第1步,merge 和 join相同。
- merge:默认根据所用的同名列的值,作等值连接条件。
- join:默认根据行索引索引值作为等值连接条件,且左连接显示。注意同名列后缀名(suffix)的指定。
# concat merge join比较
df1 = pd.DataFrame(np.arange(1,5).reshape(2,2))
df2 = pd.DataFrame(np.arange(5,9).reshape(2,2))
display(df1,df2)
# 1.concat数据连接时候,默认根据列索引来对齐,数据纵向连接
display(pd.concat((df1,df2)))
# concat axis=1 根据行索引对齐,进行数据水平连接
display(pd.concat((df1,df2),axis=1))
# 2.merge和join, 都理解为2步: 1 数据水平组合在一起 2 根据等值连接条件显示。 第1步,merge和join相同
# merge默认根据所用的同名列的值,作为等值连接条件
display(df1.merge(df2))
# join默认根据行索引索引值作为等值连接条件,且左连接显示
display(df1.join(df2,how='inner',lsuffix='_df1',rsuffix='_df2'))
8. 本节使用的数据库的样式
- titantic_train.csv

- data.csv

- bike.csv

- earthquake_week.csv
















 2120
2120











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









