







AutoRec是在2015年由澳大利亚国立大学提出的,它将自编码器的思想和协同过滤结合,提出了一种单隐层神经网络推荐模型。因其简单易懂,特别时候作为深度学习推荐系统的入门。
AutoRec模型的基本原理
AutoRec模型是一个标准的自编码器,它的基本原理是利用协同过滤中的共现矩阵,完成物品向量或者用户向量的自编码。再利用自编码的结果得到用户对物品的预估评分,进而进行推荐排序。
自编码器
自编码器顾名思义,是指能后完成数据“自编码”的模型。假设数据向量为r,自编码器的作用是将向量r作为输入,通过自编码器的重建函数后,得到一个新的输出向量,并且使新的输出向量尽量接近输入向量。
换句话说,自编码器就是要构建一个重建函数h(r;θ),使所有该重建函数生成的评分向量与原评分向量的损失函数最小。自编码器的损失函数如下图所示:
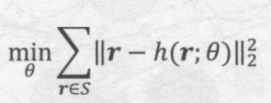
在完成自编码器的训练后,就相当于在重建函数h(r;θ)中存储了所有数据向量的“精华”。一般来说,重建函数的参数数量远小于输入向量的维度数量, 因此自编码器相当于完成了数据压缩和降维的工作。经过自编码器生成的输出向量,由于经过了自编码器的“泛化”过程,不会完全等同于输入向量,也因此具备了一定的缺失维度的预测能力,这也是自编码器能用于推荐系统的原因。
AutoRec模型的结构
AutoRec使用单隐层神经网络的结构来解决构建重建函数的问题。从模型的结构图中可以看出,网络的输入层是物品的评分向量r,输出层是一个多分类层。图中蓝色的神经元代表模型的K维单隐层,


AutoRec的推荐过程
基于AutoRec模型的推荐过程并不复杂。当输入物品i的评分向量为r(i)时, 模型的输出向量h(r(i);θ)就是所有用户对物品i的评分预测。那么,其中的第w维就是用户u对物品i的预测R,如下图所示。
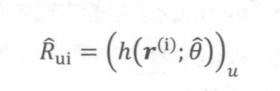
通过遍历输入物品向量就可以得到用户u对所有物品的评分预测,进而根据评分预测排序得到推荐列表。
与协同过滤算法一样,AutoRec也分为基于物品的AutoRec和 基于用户的AutoRec。以上介绍的AutoRec输入向量是物品的评分向量,因此可称为I-AutoRec,如果换做把用户的评分向量作为输入向量, 则得到U-AutoRec 。在进行推荐列表生成的过程中, U-AutoRec相比I-AutoRec的优势在于仅需输入一次目标用户的用户向量,就可以重建用户对所有物品的评分向量。也就是说,得到用户的推荐列表仅需一次模型推断过程;其劣势是用户向量的稀疏性可能会影响模型效果。
AutoRec模型的特点和局限性
由于AutoRec模型的结构比较简单,使其存在一定的表达能力不足的问题。 在模型结构上,AutoRec模型和后来的词向量模型(Word2vec)完全一致, 但优化目标和训练方法有所不同。















 7179
7179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









