







动辄TB乃至PB级別的训练数据,让推荐系统的数据流必须和大数据处理与存储的基础设施紧密结合,才能完成推荐系统的高效训练和在线预估。 大数据平台的发展经历了从批处理到流计算再到全面融合进化的阶段。架构模式的不断发展带来的是数据处理实时性和灵活性的大幅提升。按照发展的先后顺序,大数据平台主要有批处理、流计算、Lambda. Kappa 4种架构模式。
批处理架构
在大数据平台诞生之前,传统数据库很难处理海量数据的存储和计算问题。 针对这一难题,以Google GFS和Apache HDFS为代表的分布式存储系统诞生, 解决了海量数据的存储问题;为了进一步解决数据的计算问题,Map Reduce框架被提出,采用分布式数据处理再逐步Reduce的方法并行处理海量数据。“分布式存储+Map Reduce”的架构只能批量处理已经落盘的静态数据,无法在数据采集、传输等数据流动的过程中处理数据,因此被称为批处理大数据架构。
相比之前以数据库为核心的数据处理过程,批处理大数据架构用分布式文件系统和Map Reduce替换了原来的依托传统文件系统和数据库的数据存储和处理方法,批处理大数据架构示意图如下图所示。
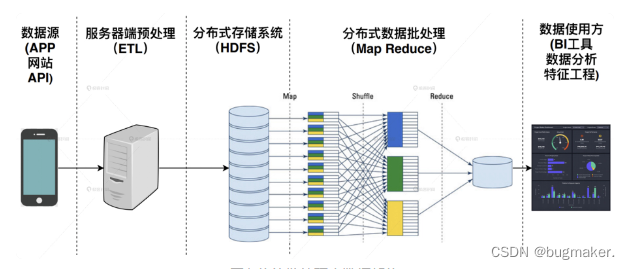
但该架构只能批量处理分布式文件系统中的数据,因此数据处理的延迟较大,严重影响相关应用的实时性,“流计算”的方案应运而生。
流计算架构
流计算大数据架构在数据流产生及传递的过程中流式地消费并处理数据。流计算架构中“滑动窗口”的概念非常重要,在每个“窗口”内部,数据被短暂缓存并消费,在完成一个窗口的数据处理后,流计算平台滑动到下一时间窗口进行新一轮的数据处理。因此理论上,流计算平台的延迟仅与滑动窗口的大小有关。在实际应用中,滑动窗口的大小基本以分钟级别居多,这大大提升了原“批处理”架构下动辄几小时的数据延迟。
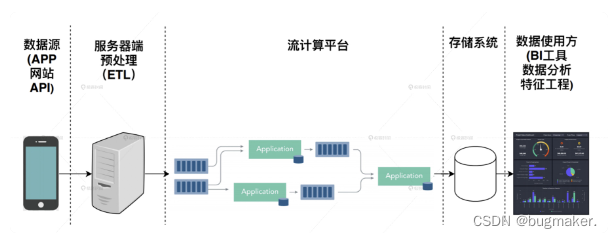
知名开源流计算平台包括Storm、Spark Streaming、Flink等,特别是近年来崛起的Flink,它将所有数据均看作“流”,把批处理当作流计算的一种特殊情况,可以说是“原生”的流处理平台。
在流计算的过程中,流计算平台不仅可以进行单个数据流的处理,还可以对多个不同数据流进行join操作,并在同一个时间窗口内做整合处理。除此之外, 一个流计算环节的输出还可以成为下游应用的输入,整个流计算架构是灵活可重构的。因此,流计算大数据架构的优点非常明显,就是数据处理的延迟小,数据 流的灵活性非常强。这对于数据监控、推荐系统特征实时更新,以及推荐模型实 时训练有很大的帮助。但是,纯流计算的大数据架构摒弃了批处理的过程,这使得平台在数据合法性检查、数据回放、全量数据分析等应用场景下显得捉襟见肘;特别是在时间窗口较短的情况下,日志乱序、join操作造成的数据遗漏会使数据的误差累计,纯流计算的架构并不是完美的。这就要求新的大数据架构能对流计算和批处理架构做一定程度的融合,取长补短。
批流一体处理架构
Lambda
Lambda架构是大数据领域内举足轻重的架构,大多数一线互联网公司的数据平台基本都是基于Lambda架构或其后续变种架构构建的。
Lambda架构的数据通道从最开始的数据收集阶段裂变为两条分支:实时流和离线处理。实时流部分保持了流计算架构,保障了数据的实时性,而离线处理部分则以批处理的方式为主,保障了数据的最终一致性,为系统提供了更多数据处理的选择。Lambda架构示意图如图所示。
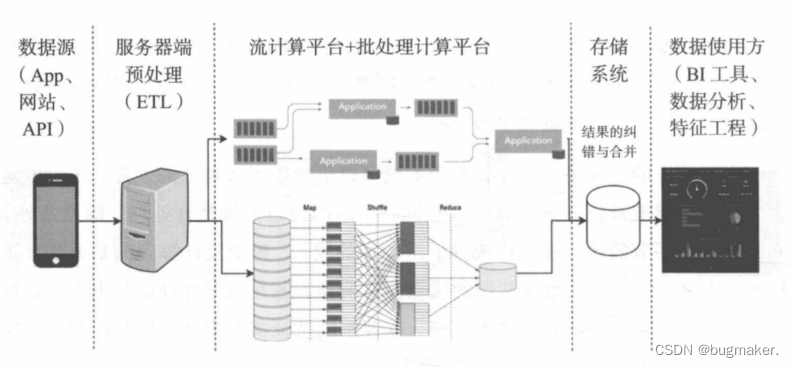
流计算部分为保障数据实时性更多是以增量计算为主,而批处理部分则对数据进行全量运算,保障其最终的一致性及最终推荐系统特征的丰富性。在将统计数据存入最终的数据库之前,Lambda架构往往会对实时流数据和离线层数据进行合并,并会利用离线层数据对实时流数据进行校检和纠错,这是Lambda架构的重要步骤。
Lambda架构通过保留流处理和批处理两条数据处理流程,使系统兼具实时性和全面性,是目前大部分公司采用的主流框架。但由于实时流和离线处理部分存在大量逻辑冗余,需要重复地进行编码工作,浪费了大量计算资源,那么有没有可能对实时流和离线部分做进一步的融合呢?
Kappa
Kappa架构是为了解决Lambda架构的代码冗余问题而产生的。Kappa架构秉持着 Everything is streaming ( 一切皆是流)”的原则,在这个原则之下, 无论是真正的实时流,还是离线批处理,都被以流计算的形式执行。也就是说, 离线批处理仅是“流处理”的一种特殊形式。从某种意义讲,Kappa架构也可以看作流计算架构的“升级”版本。
那么具体来讲,Kappa架构是如何通过同样的流计算框架实现批处理的呢?
事实上,“批处理”处理的也是一个时间窗口的数据,只不过与流处理相比,这个时间窗口比较大,流处理的时间窗口可能是5分钟,而批处理可能需要1天。 除此之外,批处理完全可以共享流处理的计算逻辑。 由于批处理的时间窗口过长,不可能在在线环境下通过流处理的方式实现, 那么问题的关键就在于如何在离线环境下利用同样的流处理框架进行数据批处理。为了解决这个问题,需要在原有流处理的框架上加上两个新的通路“原始数据存储”和“数据重播”。“原始数据存储”将未经流处理的数据或者日志原封不 动地保存到分布式文件系统中,“数据重播”将这些原始数据按时间顺序进行重 播,并用同样的流处理框架进行处理,从而完成离线状态下的数据批处理。这就是Kappa架构的主要思路。
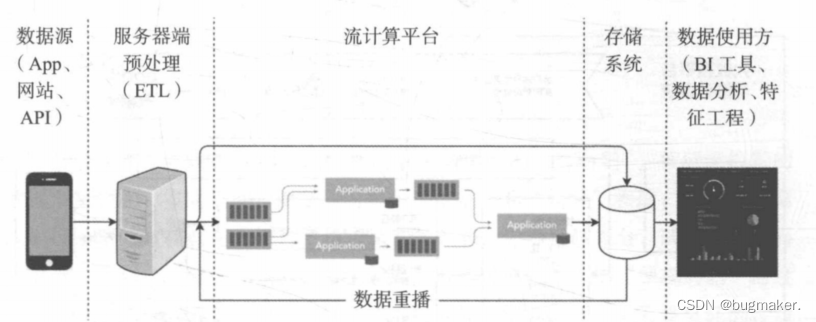
Kappa架构从根本上完成了 Lambda架构流处理部分和离线部分的融合,是非常优美和简洁的大数据架构。但在工程实现过程中,Kappa架构仍存在一些难 点,例如数据回放过程的效率问题、批处理和流处理操作能否完全共享的问题。 因此,当前业界的趋势仍以Lambda架构为主流,但逐渐向Kappa架构靠拢。
















 1131
1131











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









