







一.介绍:小样本学习,属于元学习的一种。目的是让机器具有自我判别的先验知识。
比如说,我们想要训练对3类图片分别是 猪,牛,羊的模型,传统的监督学习是拿这3类的大量数据进行训练,然后得到一个模型。
而小样本学习是想要通过其他大量的图片样本(不包括猪,牛,羊)训练出一个模型(比如相似度函数),这个模型具有先验知识(判别两类相同或者不相同的能力),所以使用这个模型,可以用来分类猪,牛,羊这三类,因为此时我们的模型已经具有分类两种类别异同的先验知识了。这是元学习的其中一种思想,可以参考下https://www.bilibili.com/video/BV1aT4y1u7e6?p=3。
二.方法:预训练+fine tuning
先验知识:cos函数可以用来评判两个向量之间的相似度,cosx=(a*b)/(|a|*|b|) ,当a和b为单位向量时,cosx=a*b (向量a和b的内积)
这里主要是想讲一种做小样本学习的有效简单的方法,方法的思路如下:
- 使用一个大数据集来训练一个提取特征的预训练模型,可以使用连体网络训练,也可以使用传统的监督学习进行训练。(提取特征好坏的指标可以用该预训练模型进行分类的准确率评判)
例如: 使用CNN训练,训练完成后将最后一层去掉。

- 得到预训练模型后,选择support_set(从要分类的样本中选),然后将support_set的样本用预训练模型转换成特征向量,如:

- 将其转换成特征向量后,就可以对query做分类,如下,给一个松鼠query,将其转化为特征向量,然后归一化得到向量q,分别跟上面support_set得到的三个特征向量做对比(相乘运算,然后softmax激活)


到这里,few-shot问题已经做完了,但是里面有一些细节可以提高,下面fine-tuning就是做这样的工作。
fine-tuning:可以大幅提升准确率!
回顾一下上面的few-shot实现问题,主要是:
- 使用预训练的神经网络,记作f(x),可以把图片xi,映射成特征向量f(xi)
- 把n个特征向量xj输入f(x),通过softmax分类器,输出概率分布pj
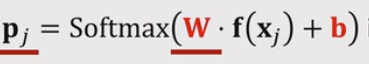 ,假如support_set有三个类别,w就有三行,pj就有三个概率值,表示每类对应的概率。
,假如support_set有三个类别,w就有三行,pj就有三个概率值,表示每类对应的概率。
这里我们设W=M b=0, W表示support_set中每类对应的均值归一化特征向量,如果support_set有三个类别,这样表示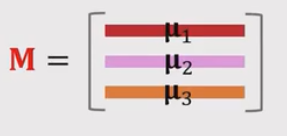 ,这里并没有学习w和b
,这里并没有学习w和b
fine-tuning:思想是使用support_set的样本学习w和b。
学习的三个技巧:
- 使用
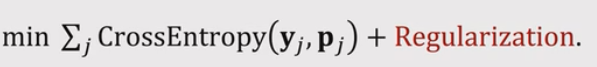 作为损失函数 ,衡量yj和pj的损失。
作为损失函数 ,衡量yj和pj的损失。 - 合理的初始化选择,初始化 W=M,b=0和用Entropy Regularization防止过拟合
- 结合Cosine Similarity + Softmax Classifier, 标准的softmax 分类器:
 ,将W和q的内积替换成sim(w,q) (CosineSimilarity),
,将W和q的内积替换成sim(w,q) (CosineSimilarity),
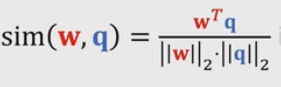 (实际上就是把w和q在求内积之前,把w和q做归一化),得到:
(实际上就是把w和q在求内积之前,把w和q做归一化),得到: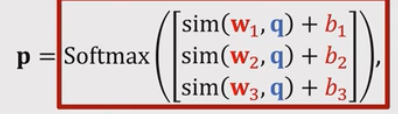














 9911
9911











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









