







NLP LLM(Pretraining + Finetuning)——理论篇
NLP LLM(Pretraining + Finetuning)——HuggingFace Transformer代码篇
NLP 基础
建议看 [CS224N 2023]打基础
- Language Model:语言模型的马尔可夫假设(每个词出现的概率仅依赖前面出现的词),是一个
自回归模型(同decoder-only)。①根据前文预测下一个词是 w n w_n wn的条件概率 P ( w n ∣ w 1 , w 2 , . . . , w n − 1 ) P(w_n | w_1, w_2, ..., w_{n-1}) P(wn∣w1,w2,...,wn−1),语言建模的能力,②预测一个word序列组成一句话的联合概率 P ( w 1 , w 2 , . . . , w n ) P(w_1, w_2, ..., w_n) P(w1,w2,...,wn),语言理解能力。 - N-gram Model:将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段序列,对文本中长度为n序列进行统计。每一个字节片段称为gram,对所有gram的出现频度进行统计,并且按照事先设定好的阈值进行过滤,形成关键gram列表,也就是这个文本的向量特征空间,列表中的每一种gram就是一个特征向量维度。该模型基于这样一种假设,第N个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。但n-gram背后是one-hot思想,不同词的相似度为零,没有考虑同义词的文本相似度。
- Vocabulary:word embedding时,根据词表,对见过的词进行编码映射为vector,未见过的词映射为UNK,为解决
word-level的稀疏问题和词表无限问题(out of vocabulary),转而使用char-level但粒度太细,所以可以使用subword-level的编码(单词前后缀等)。但vocabulary embedding没有考虑句子中词间关系。 - Word2Vec:word embedding时,将word映射到向量vector空间的预训练神经网络,文本相似度的word在特征空间中距离近。后面还要接LM做下游任务。
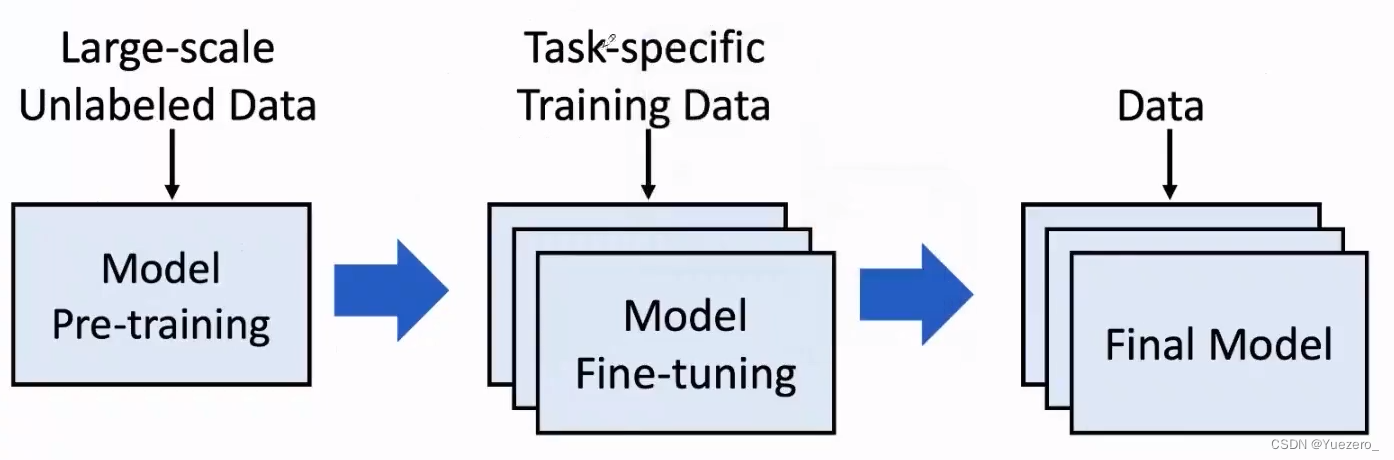
- Pre-train Whole Model:预训练整个模型是一种将大型神经网络模型与大规模文本数据集一起进行训练的技术,直接统一了word embedding和down stream。
- BigModel:大模型work的机理,Transfer Learning(无监督预训练+有监督微调)。

Tokenizer
Tokenizer计算得到的input_ids 是输入Transformer模型最直接的内容,而input_ids到embeddings的转换由Transformer模型中的Embedding Layer完成。
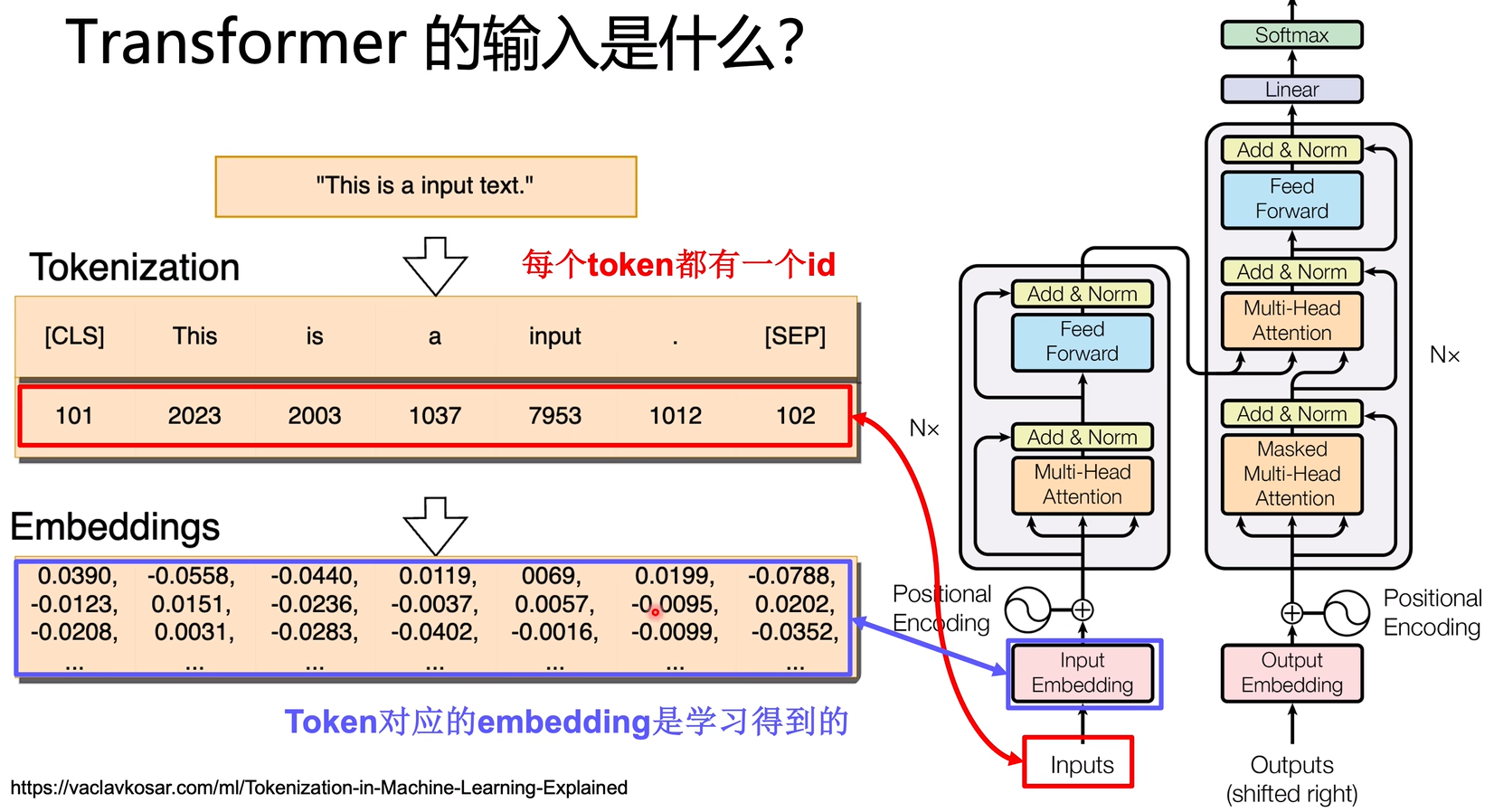
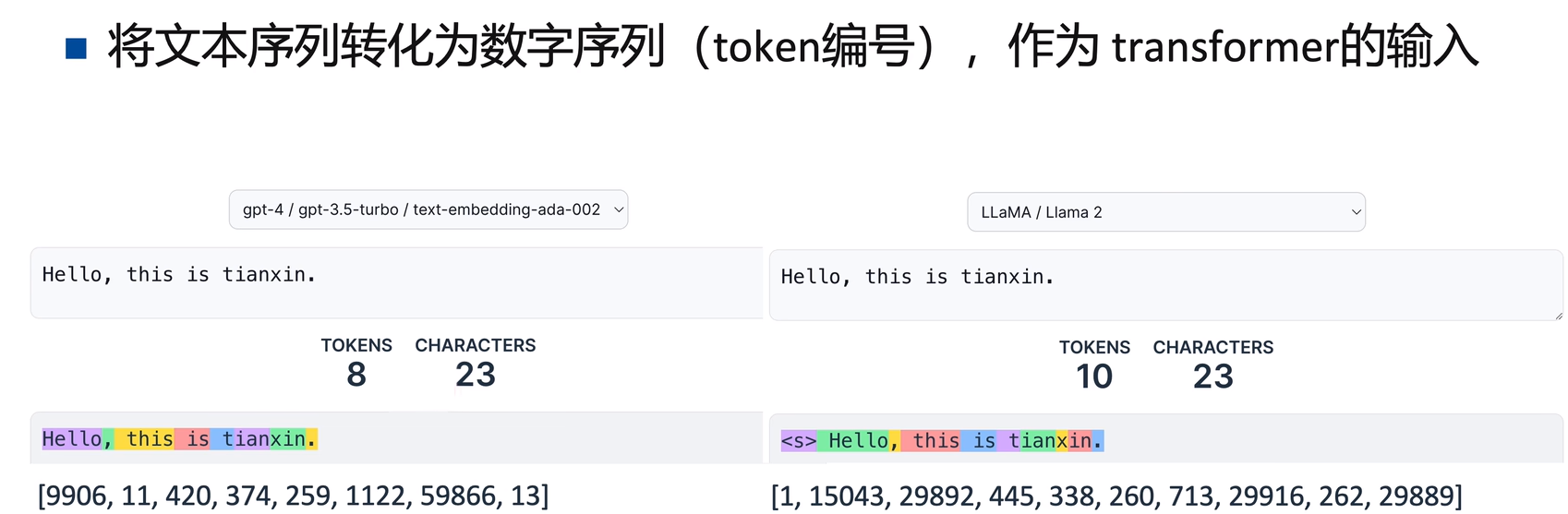
Tokenizer是根据一个巨大的词表vocab,将 word_sequence 转换位 number_sequence(id)。

Embedding Layer是Transformer模型的一部分可学习参
W
E
W_E
WE:把input_ids中每个word对应的一个id数字,映射到一个embeddings向量,

不同模型的tokenizer的划分能力和划分结果是不一样的,按照分词粒度可以分为3种:word-based、character-based、subword-based。
Word-based Tokenizer
按单词划分,需要引入规则,词表vocab会非常的大,虽然可以限制词表的大小,把词表外的词设为unkonw,但这也会导致模型性能的丢失,使得性能大打折扣。



Character-based Tokenizer
按字母/字符划分,词表vocab非常的小,但对于单词来说,按字符划分信息量非常低(单个token没有表达语义的能力),因为划分的粒度太细,会产生很长的token序列。


Subword-based Tokenizer
常用词不再被切分为更小的token,不常用的词用subword组合表示为多个token(词根词缀拆分法),这样可以更加合理的表示单词的语义。词表vocab大小固定,能保证每个tokne的语义信息。
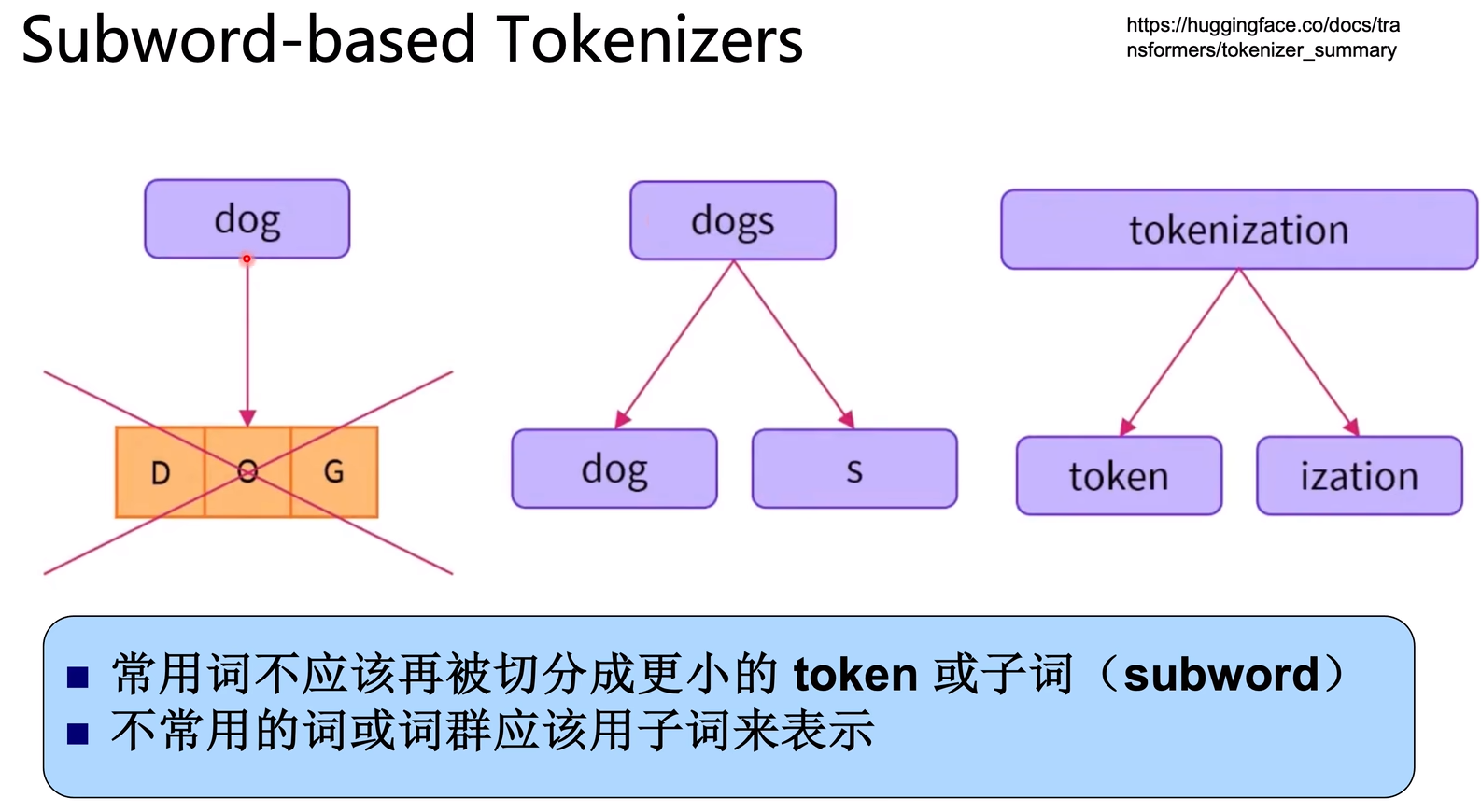
Subword-based Tokenizer主要有4种形式:BPE(Byte-Pair-Encoding)、WordPiece、SentencePiece、Unigram。

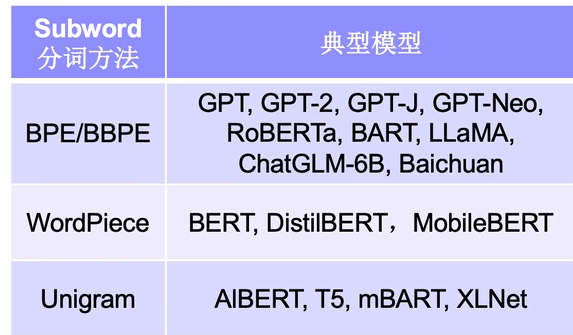
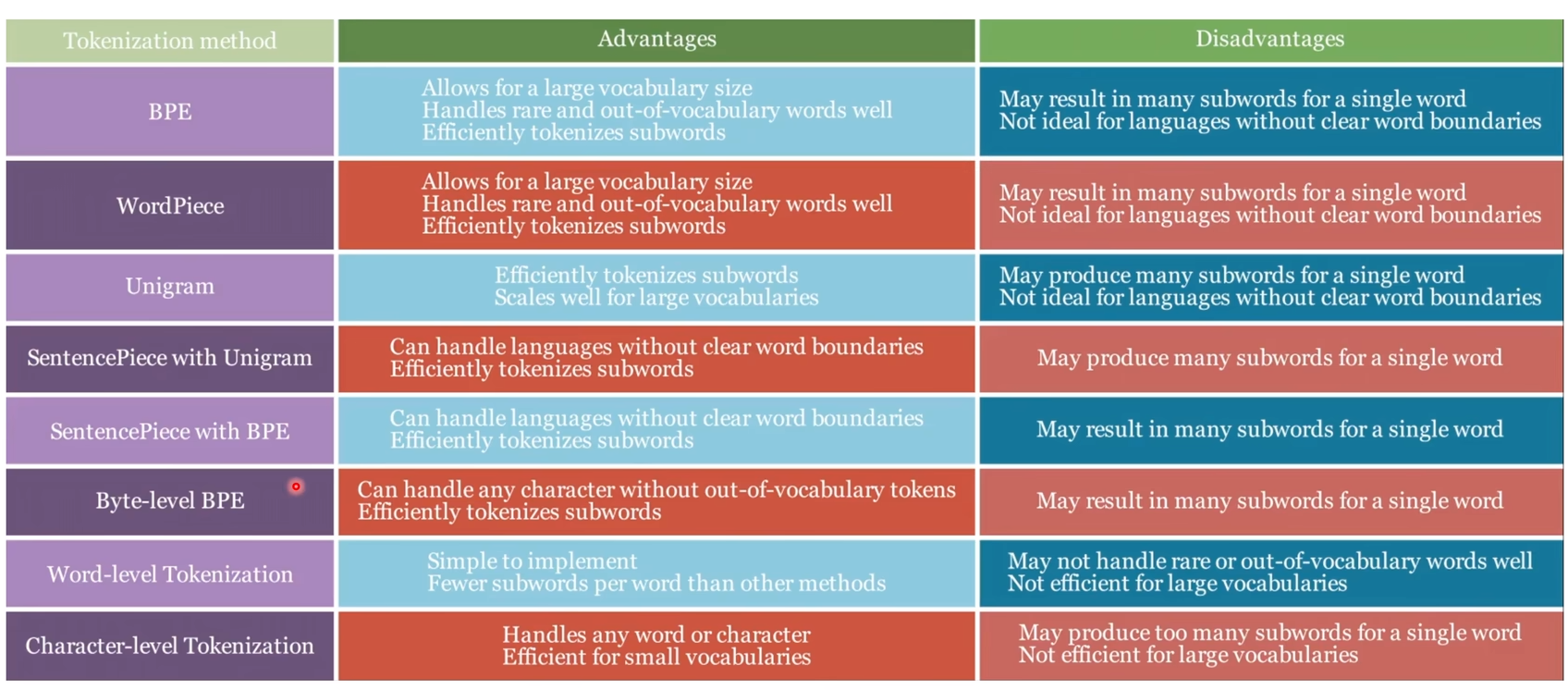
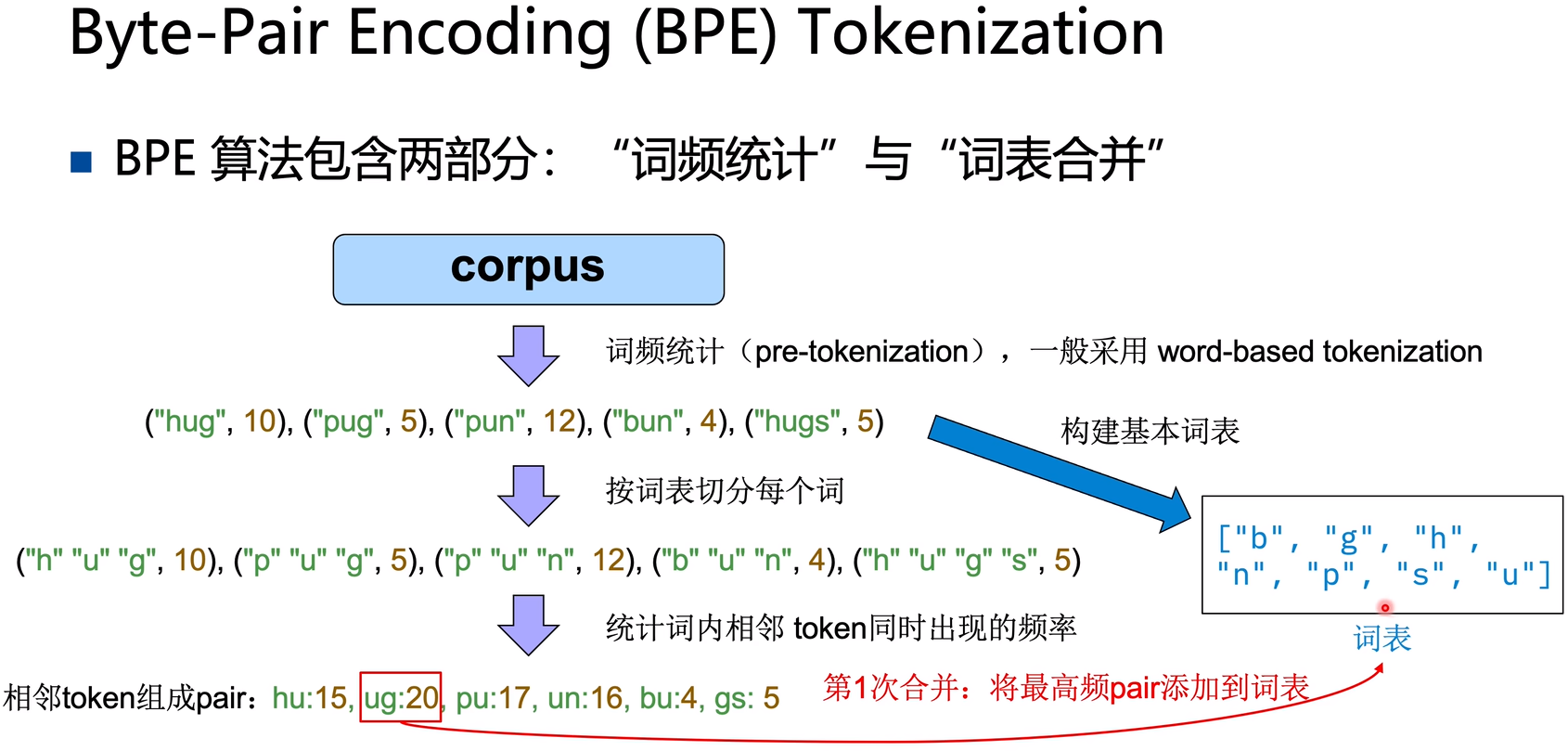
BPE(Byte-Pair-Encoding)
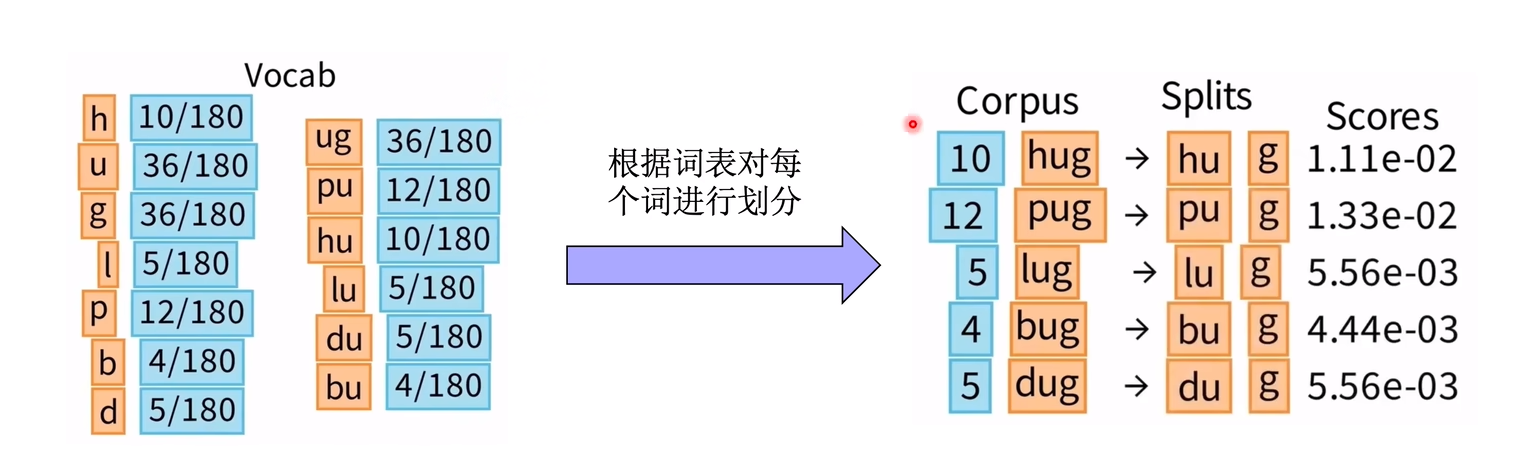
设置BPE的词表合并次数,然后不断的统计词频,进行词表合并(每合并1次,词表会增加1个subword),扩充Tokenizer的词表vocab:




WordPiece
和BPE很像,除了第一个字母,会添加##作为词表vocab中单词前缀。设置合并的次数,然后不断进行相邻token合并后的pair的联合概率统计,进行词表合并。

用联合概率给pair打分的好处是:优先考虑单个token在词表中单独出现不多,但两个token组合成的pair出现频率很高的pair。

Unigram
初始化一个巨大的词表vocab(包含字符和各种subword等),然后不断删减词表,得到最终一个比较合适的词表。
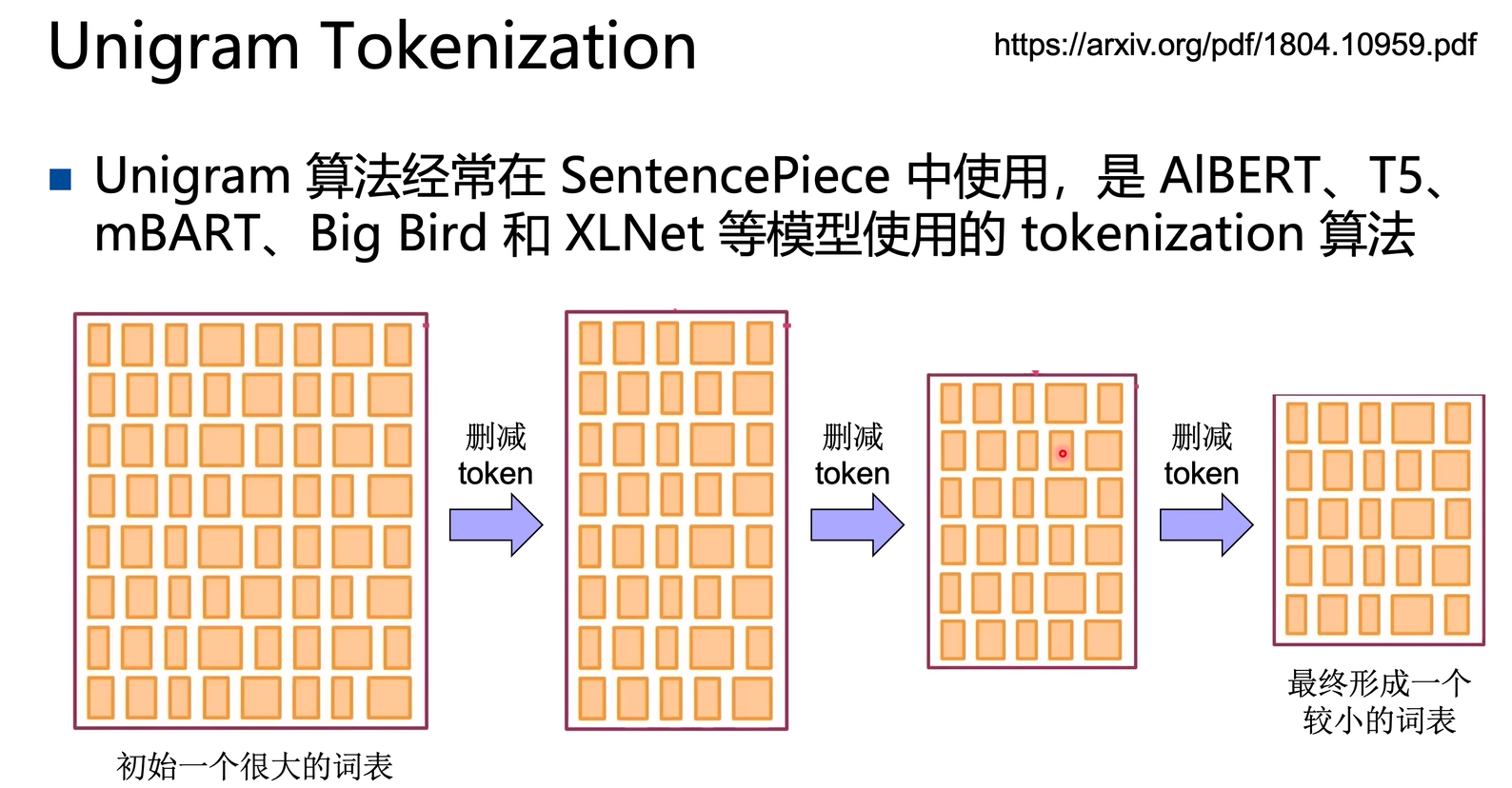
每次删减一个token,计算一次Unigram loss评价当前词表好坏,我们需要每次删除的是词表中最不重要的token:
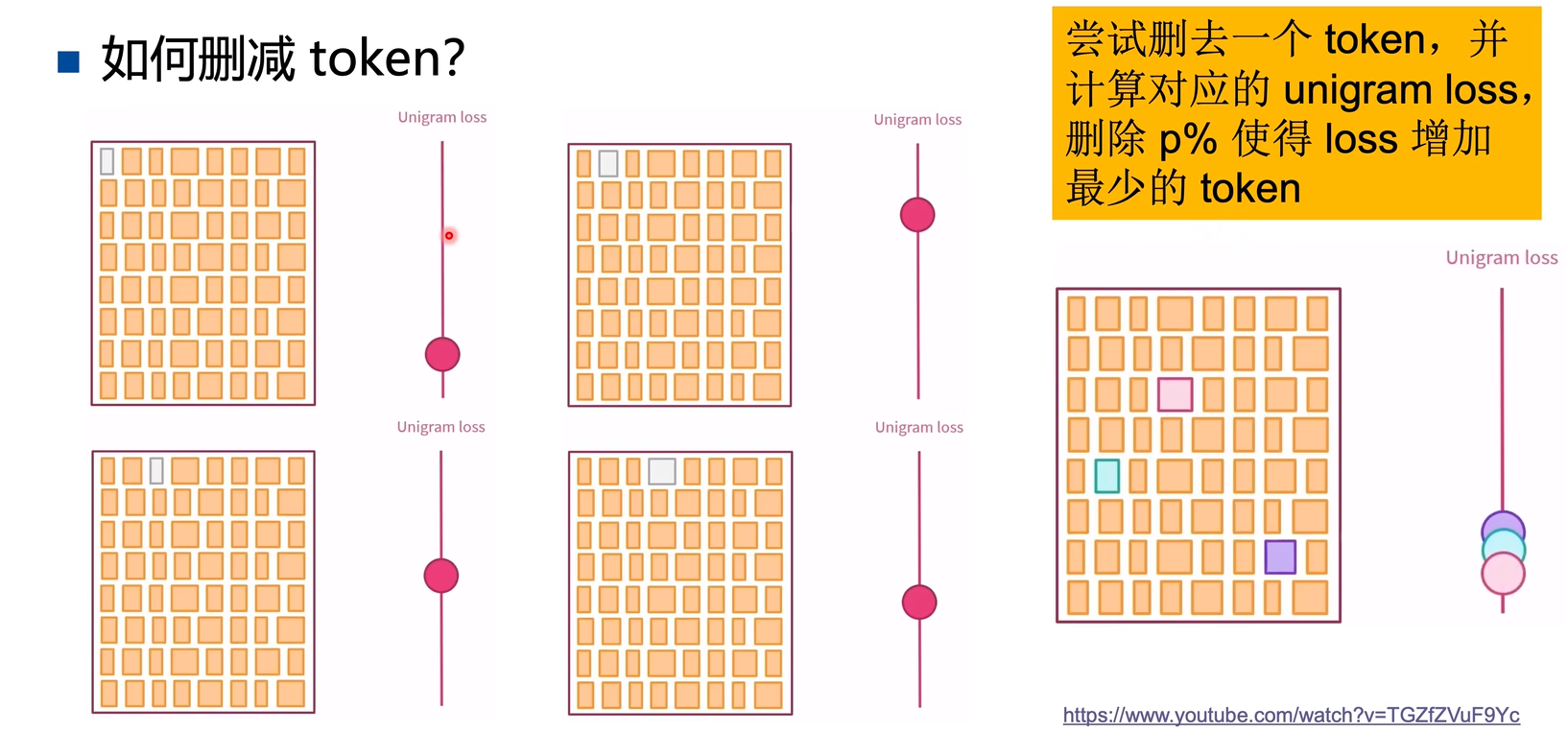
Unigram假设每个token都是独立出现的,那么求一个word的联合概率 = 每个字符出现概率的连乘:
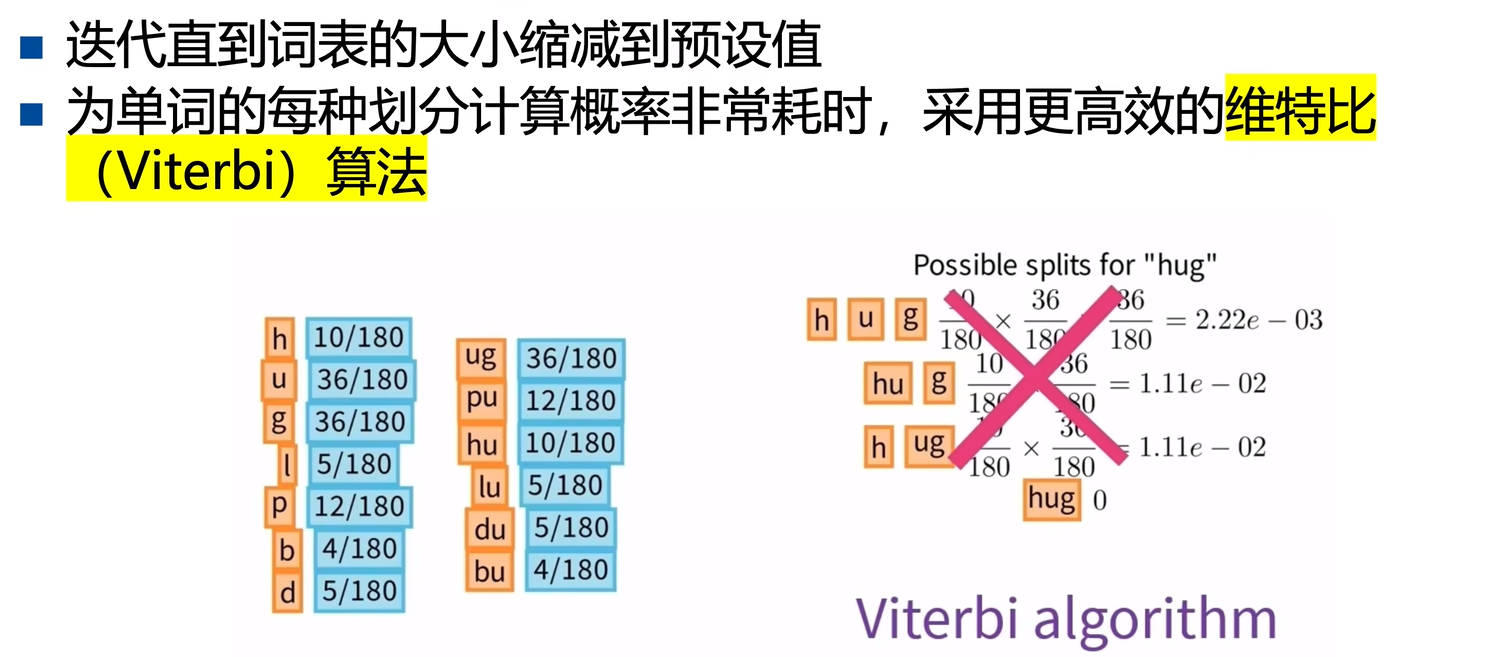
构建初始词表后,如何优化计算loss呢?
就是根据初始词表每个token的词频,计算一个pair的不同组合方式下的联合概率。

然后选择联合概率最大的切分方式。

得到每个pair的得分。
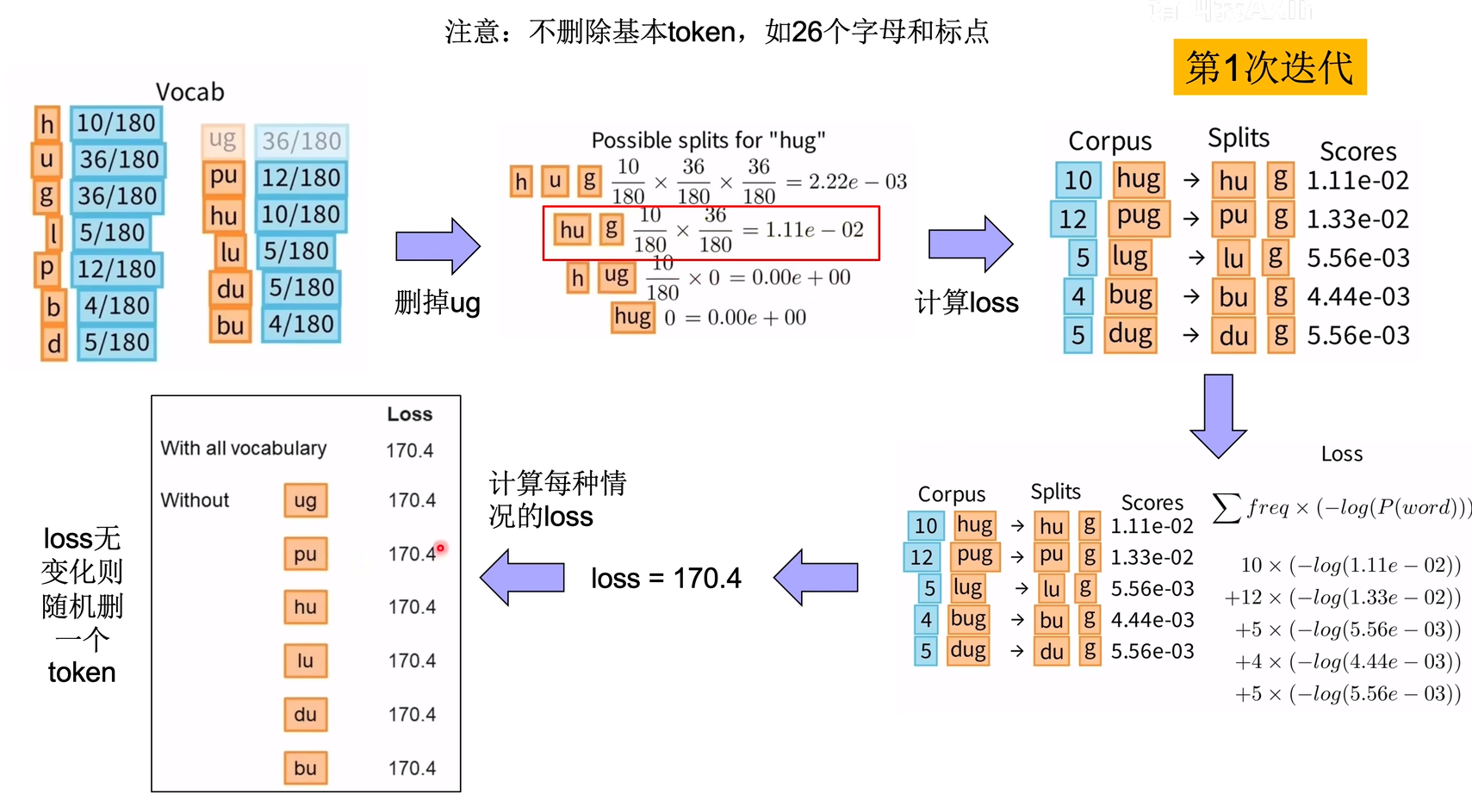
计算每个pair的负似然对数,求和即为loss。

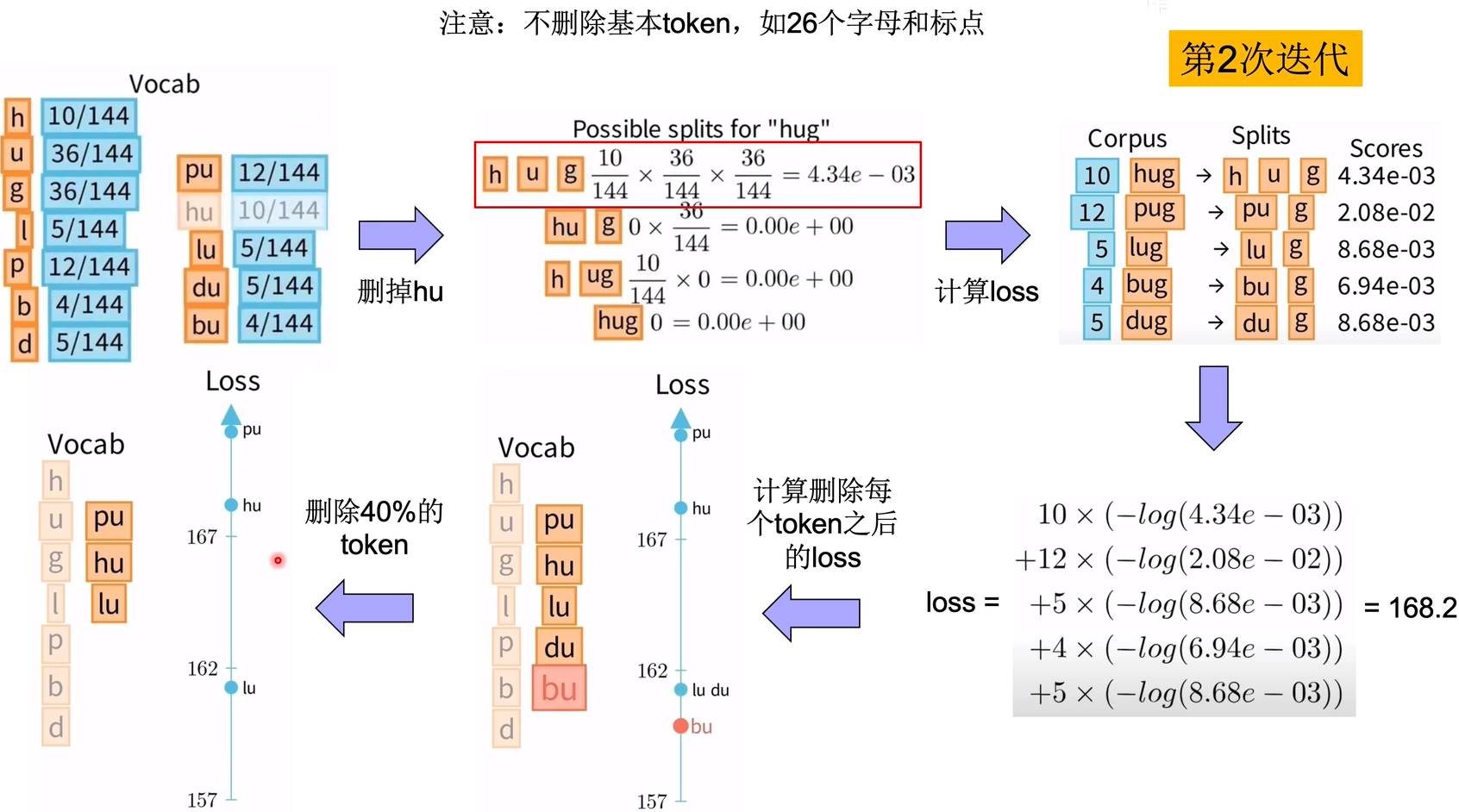
学会了计算loss,我们就可以对词表中每个token计算删除后的loss,选择一个token删除
SentencePiece
每种语言的分词方式不同(不一定都是像英文一样用空格分词),虽然可以对每种语言学习一个Pre-tokenizer用于分词,但这种方法不太通用。因此SentencePiece将输入视为字节流,再用BBPE和Unigram构建词表vocab。


Pretraining
Pretraining Language Model (PLM)主要分为两类:
- Feature based 模型:预训练模型的输出作为下游任务的输入,如Word2Vec是第一个PLM。
- Fine-tune based 模型:预训练模型权重作为下游任务模型的初始化权重,根据下游任务微调时,模型参数也会更新,就是Pre-train Whole Model,如BERT、GPT、T5等。
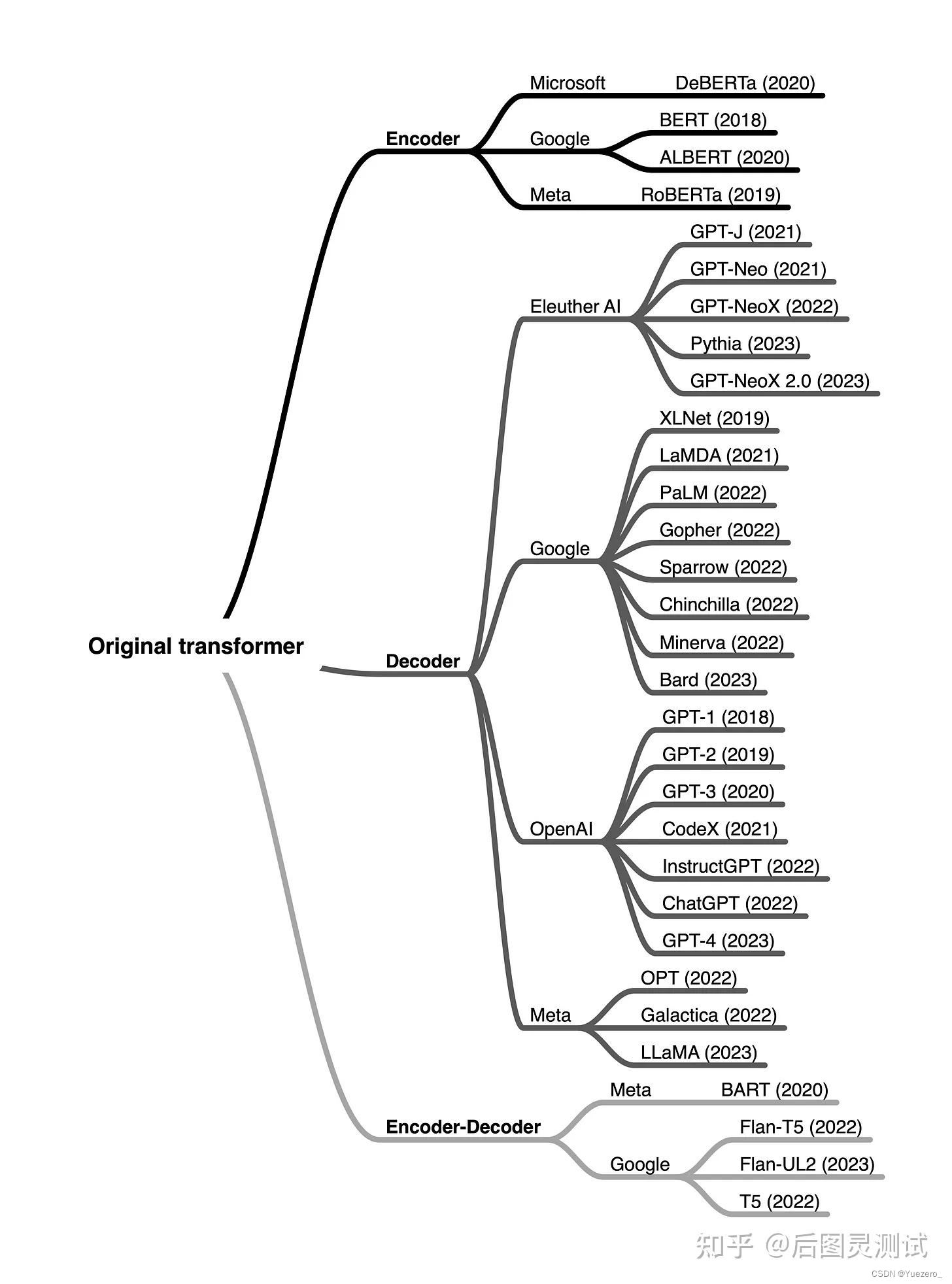
语言预训练模型梳理: BERT & GPT & T5 & BART
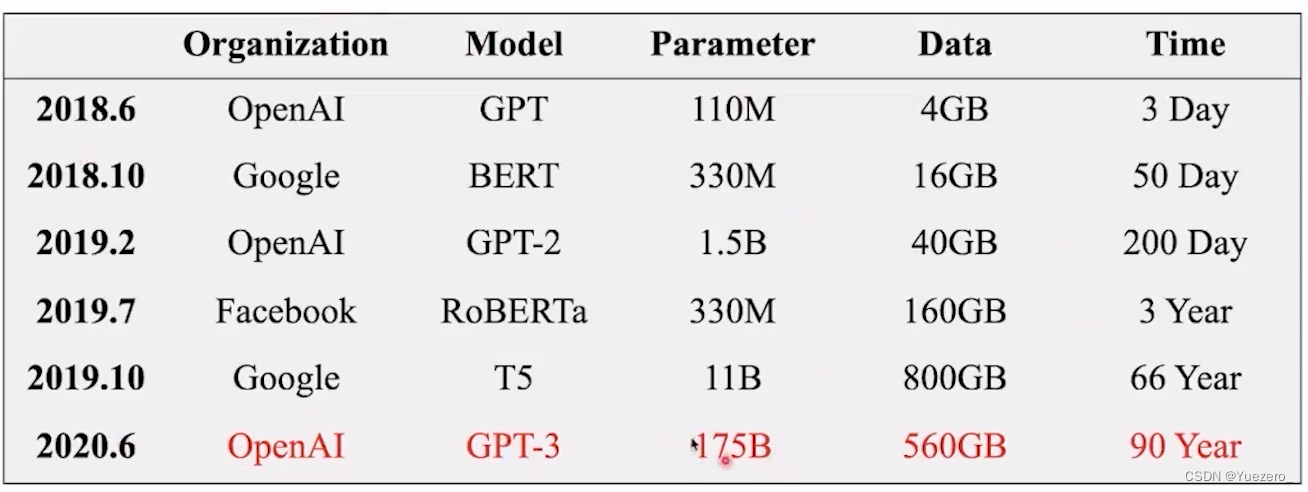
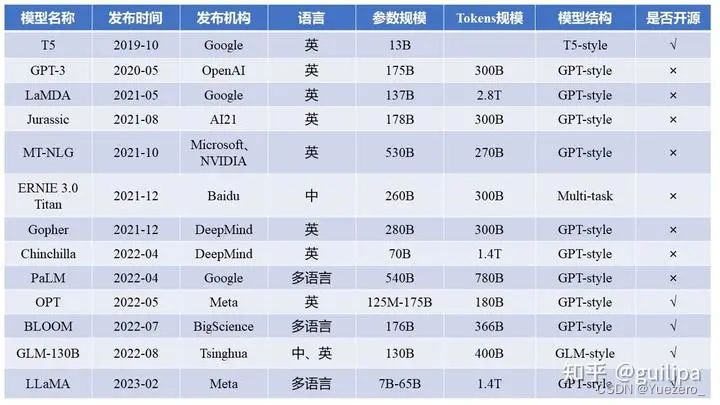
总结从T5、GPT-3、Chinchilla、PaLM、LLaMA、Alpaca等近30个最新模型
[Transformer 101系列] 初探LLM基座模型-——encoder-only,encoder-decoder和decoder-only
[Transformer 101系列] ChatGPT是怎么炼成的?
[Transformer 101系列] 多模态的大一统之路
Fine-tune based 模型
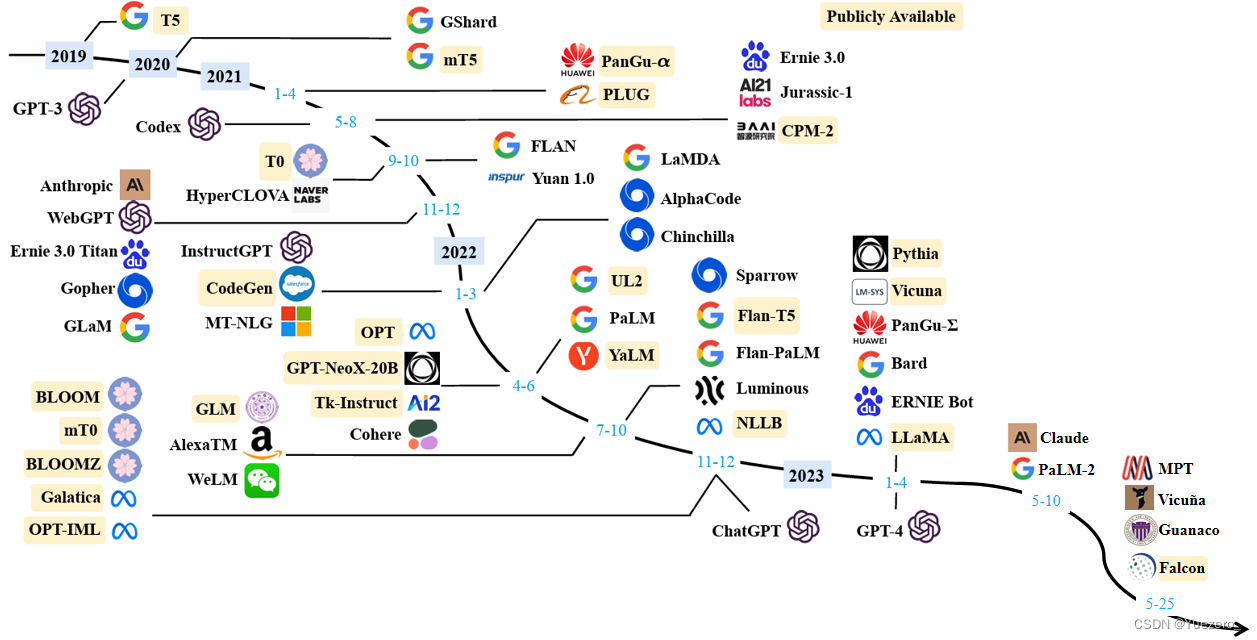
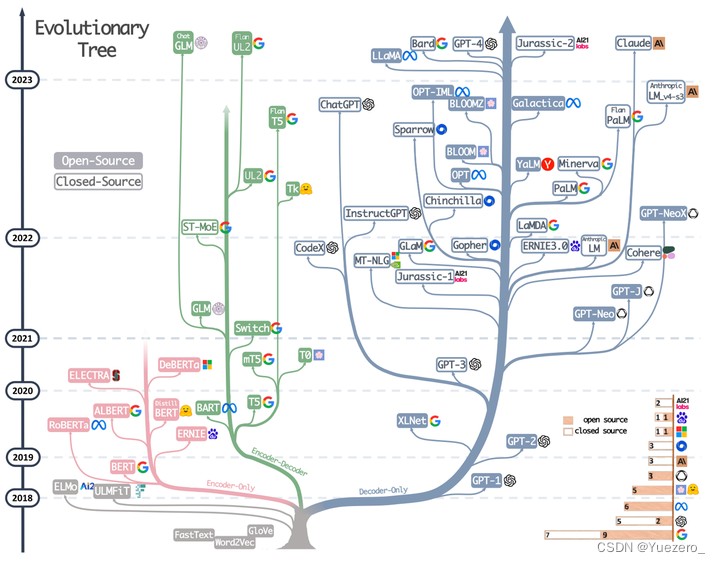
对于 Fine-tune based 模型 代表性的主要是:
Encoder-only(Mask LM模型/双向理解,也叫 Auto-Encoder):粉色分支,输出token都能看到所有输入token,采用MLM掩码-预测和NSP下句预测任务进行预训练,如BERT,RoBERTa等。针对不同的下游任务,需要单独微调。Decoder-only(LM模型/生成任务,也叫 Auto-Regressive):蓝色分支,输出token只能看到当前token前面的所有输入token,采用自回归生成式预训练, 如GPT系列,LLaMA,PaLM,OPT,LaMDA,BLOOM等。针对不同的下游任务,使用prompt不需要单独微调。Encoder-Decoder(Text2Text模型): 绿色分支,输出token都能看到所有输入token,如T5, BART,GLM等。针对不同的下游任务,使用prompt不需要单独微调。

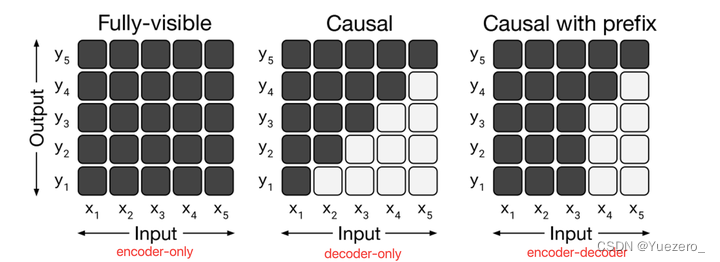
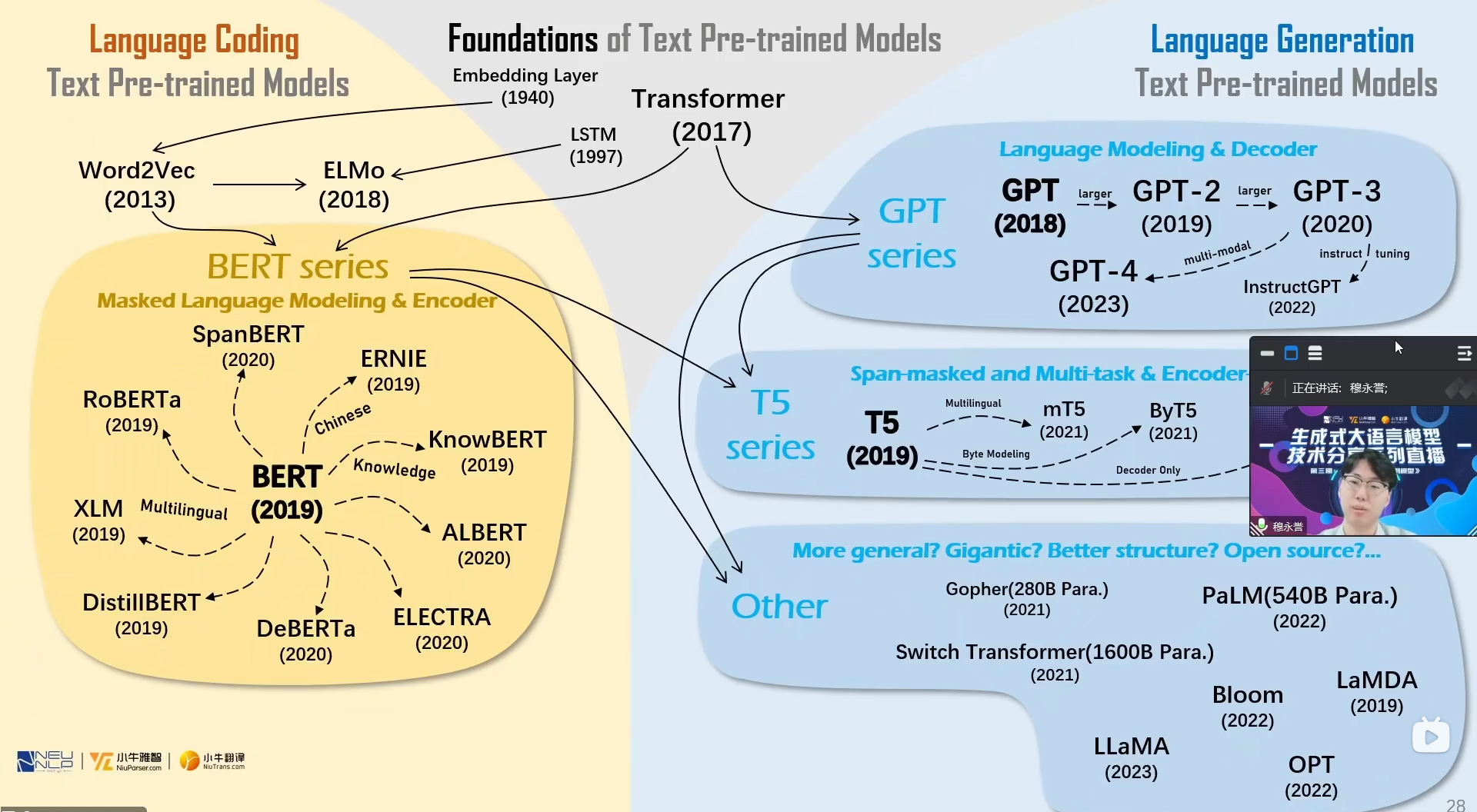
BERT:transformer encoder 双向mask 完形填空预训练Mask LM,增加CLS token用于下游任务。
GPT:12层的transformer decoder 自回归从左到右 做生成预训练,作为生成式模型。
GPT-2:增大了GPT模型参数量和预训练数据量,展现出zero-shot(只需要prompt就可处理未见过的数据)和in-context learning(给出示例就可照猫画虎)能力。
T5:transformer encoder-decoder架构,完成text2text完成MLM预训练。
BART:encoder-decoder架构,相比与T5采用了多种给文本加噪声预训练。
Encoder-Only
Encoder-only架构的LLMs更擅长对文本内容进行理解、分类,包括情感分析,命名实体识别等NLU类型任务。主要代表是Bert系列的模型,先经过预训练得到一个强大的Encoder(12层transformer),在微调时接上一个Decoder(Linear layer),使用具体的下游任务数据进行全模型微调。再例如,roBerta是基于Bert进行了升级,比如扩大了batch size,在更大的数据上训练,消除了Bert的next-sentence prediction task训练方式。

Encoder-only架构的2种预训练任务:next-sentence prediction task(NSP)和mask language modeling(MLM):
-
乱序还原式(理解):
next-sentence prediction task是将原句子打乱成不同顺序的句子,让bert找出正确语序的原句。 -
掩码-预测MLM式(理解):
mask language modeling则是在大量的文本语料库中将数据中的15%随机遮住mask,让Bert根据上下文内容来预测mask的内容。(80%时间用[MASK] token取代,10%时间用随机token,10%时间不变)

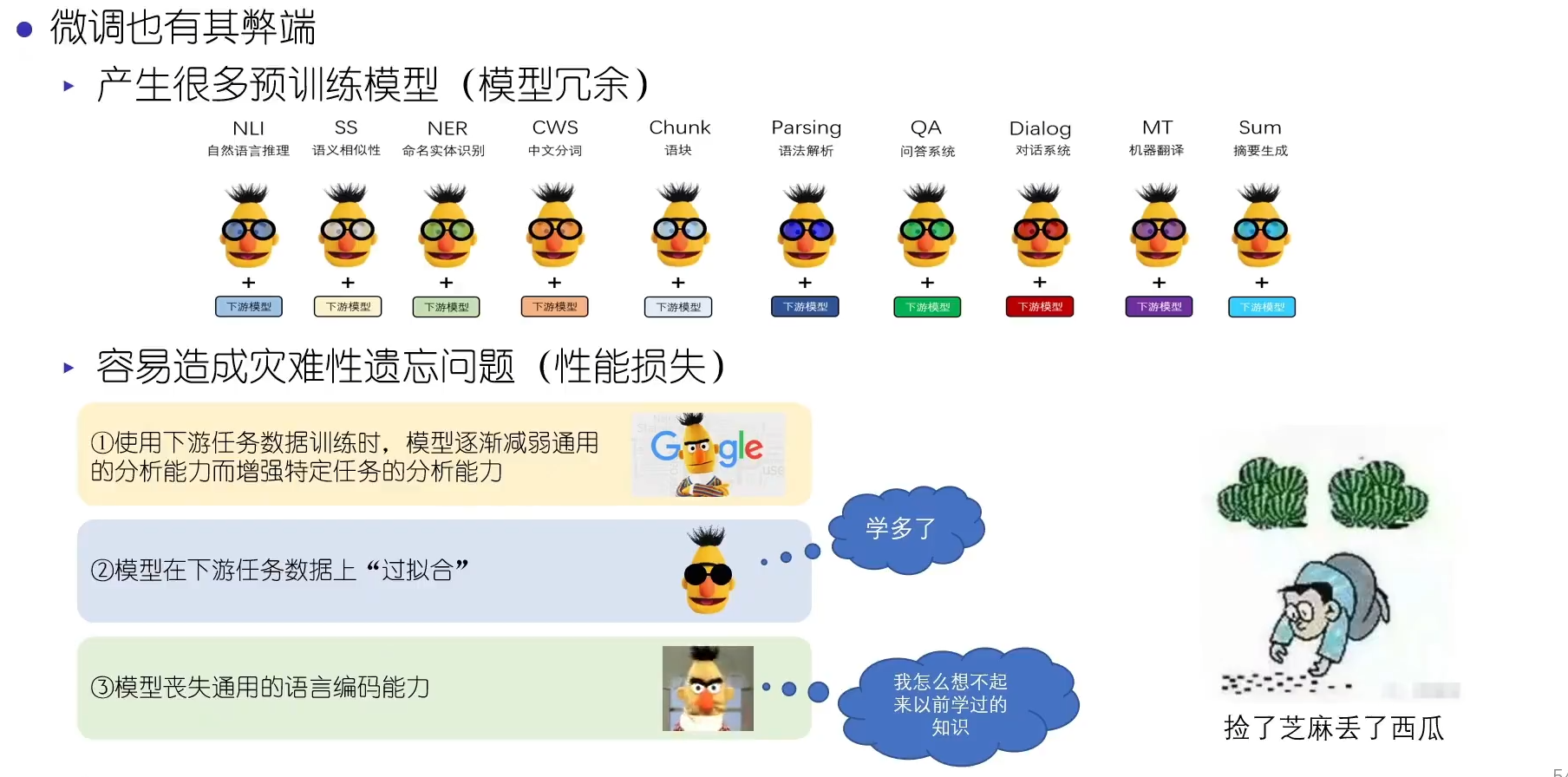
Bert根据下游任务微调时,预训练的Encoder用于提取语义知识,需要加上具体的 Task head (Linear Layer) ,整个预训练BERT模型(12层transformer) + 额外的未训练的分类层 将会一起被微调训练。
BERT微调的弊端:
Decoder-Only
Decoder-only主要是是为了预测下一个输出的内容/token是什么,并把之前输出的内容/token作为上下文学习。实际上,decoder-only模型在分析分类上也和encoder only的LLM一样有效。主要代表就是GPT系列,直接对单词token进行embedding后,送入Transformer的Decoder进行生成。Decoder-only和Encoder-Decoder模式一样,使用prompt,将所有下游任务转化为文本生成的任务(Text2Text),这样以来,预训练生成模型就可以完成各种下游任务,不需要进行微调。

只是输入Decoder的token不同:
- Decoder-only架构是每个token都是独立的语义token。
- Encoder-Decoder架构每个token都经过了双向的Encoder蕴含了所有token的信息。
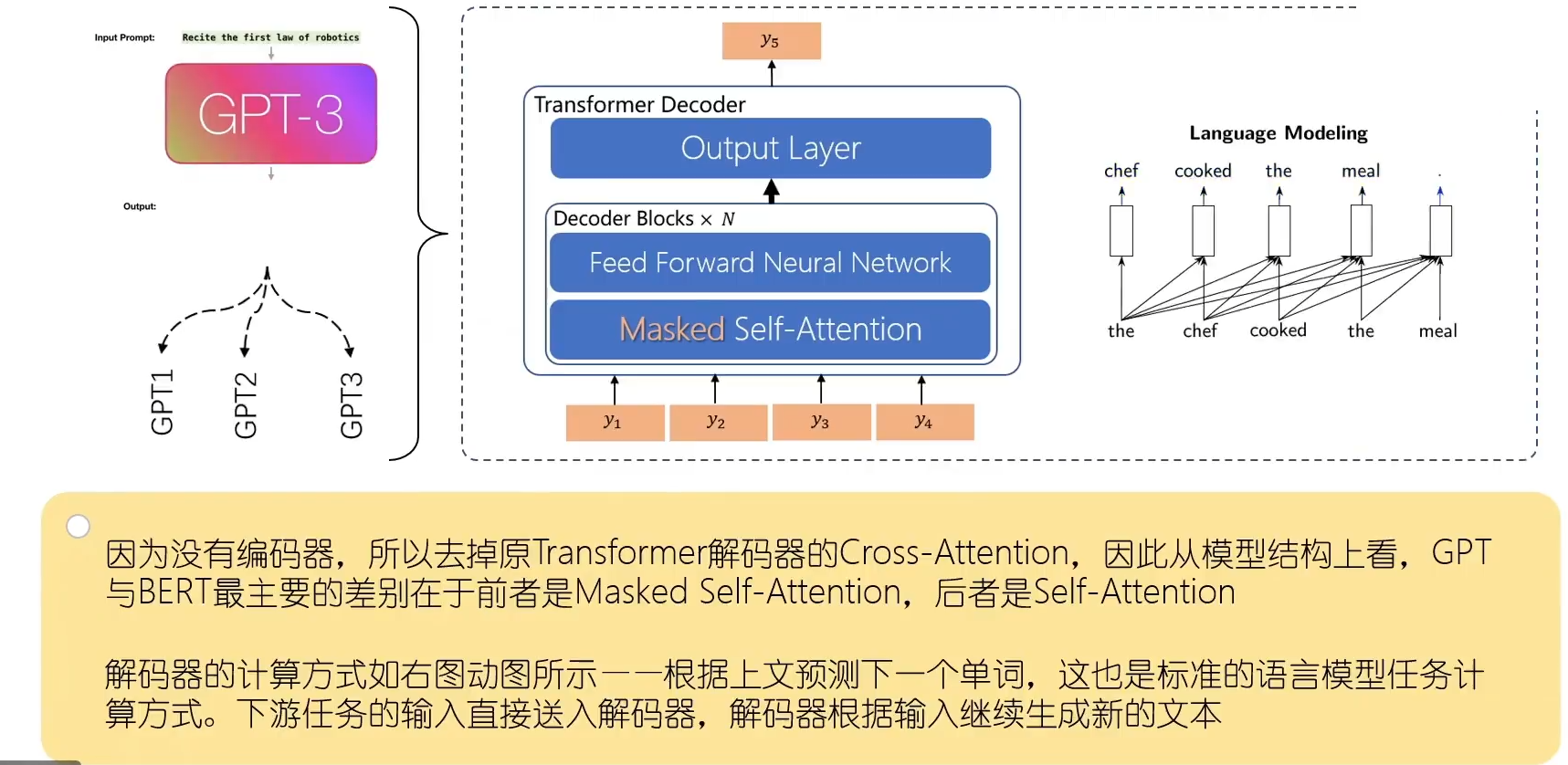
Decoder-only的decoder层跟encoder相似,不过在位置position上用到了mask,使用了一种“掩码MASK”技术,阻止模型关注位置 i 之后的位置,这意味着,在进行解码器的self-attention运算时,位置 i 的注意力分布(即注意力权重)只会在位置 i 及其之前的位置上,不会在位置 i 之后的位置上。这样,我们就可以确保位置 i 的输出只依赖于位置 i 之前的已知输出。
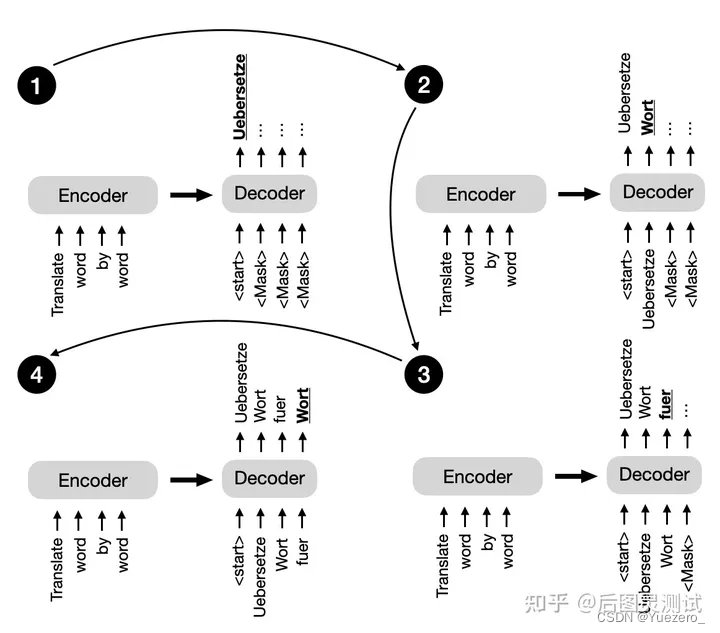
Decoder-only架构的2种预训练任务:
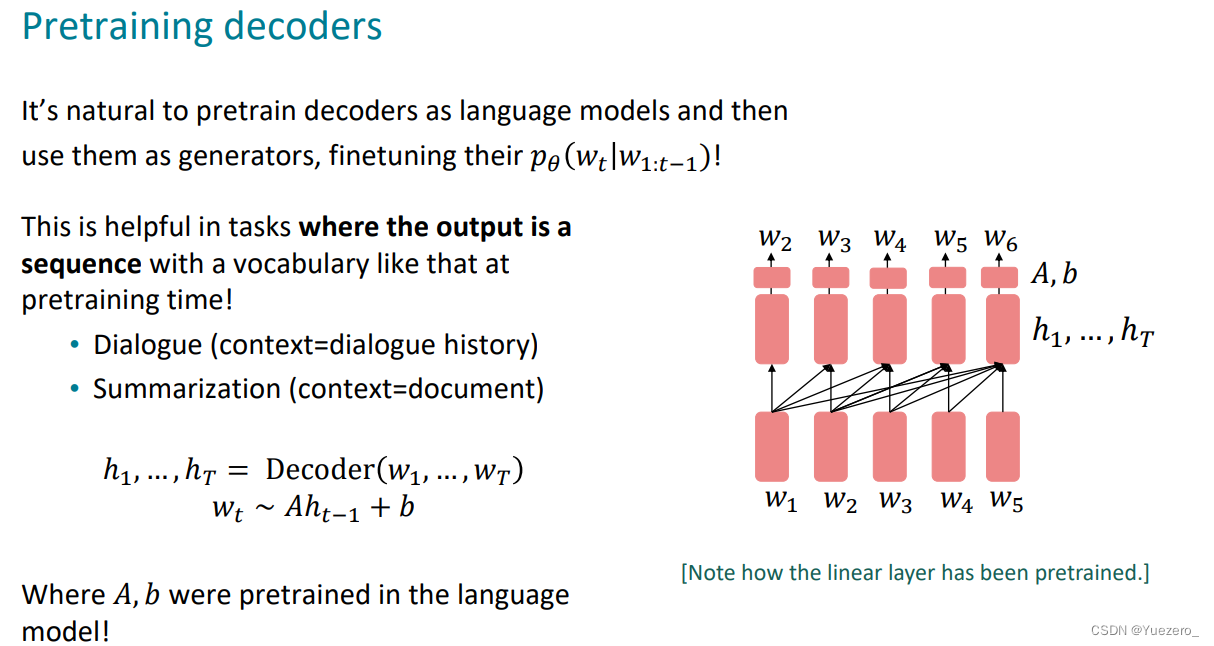
- 标准语言模型LM式(生成):
sequnence-to-sequnence生成式预训练任务: w t = A h t − 1 + b w_t=Ah_{t-1}+b wt=Aht−1+b
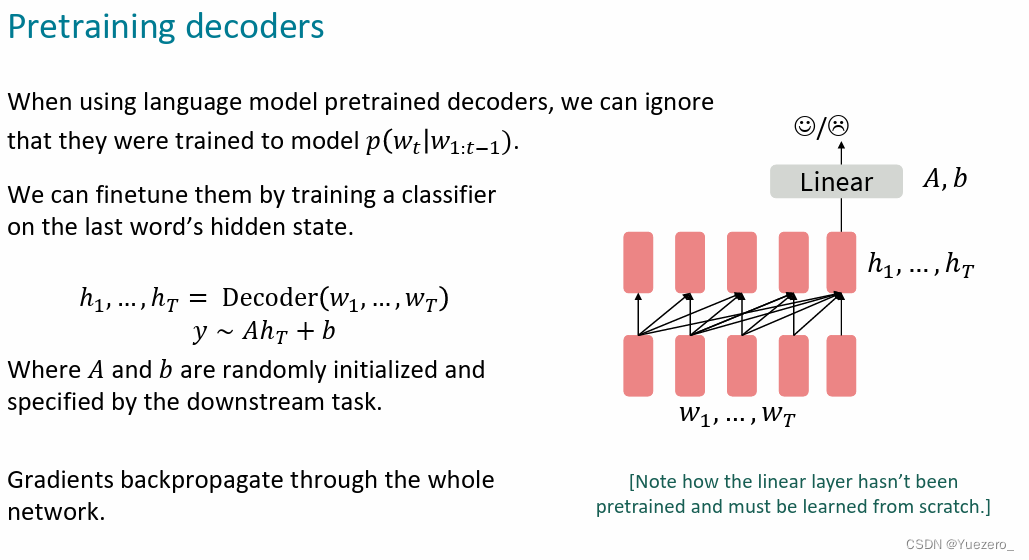
- 通过训练自回归的
最后一个token,(自回归结构中只有最后一个位置才能得到所有输入的注意力汇聚),输入FC层做分类任务: y = A h T + b y = Ah_T+b y=AhT+b。
Decoder-only架构预训练的目标函数:

Encoder-Decoder
encoder-only就是所有输出token都能看到过去和未来的所有输入token,这个对于NLU任务天然友好,但是对于seq2seq任务,如机器翻译,这个结构就不是特别匹配,因为难以直接用做seq2seq的任务。一种直接的办法就是在encoder后加上decoder做生成,这就形成了encoder-decoder架构。主要代表就是T5和BART系列,将所有下游任务转化为文本生成的任务(Text2Text),这样以来,预训练生成模型就可以完成各种下游任务,不需要进行微调。
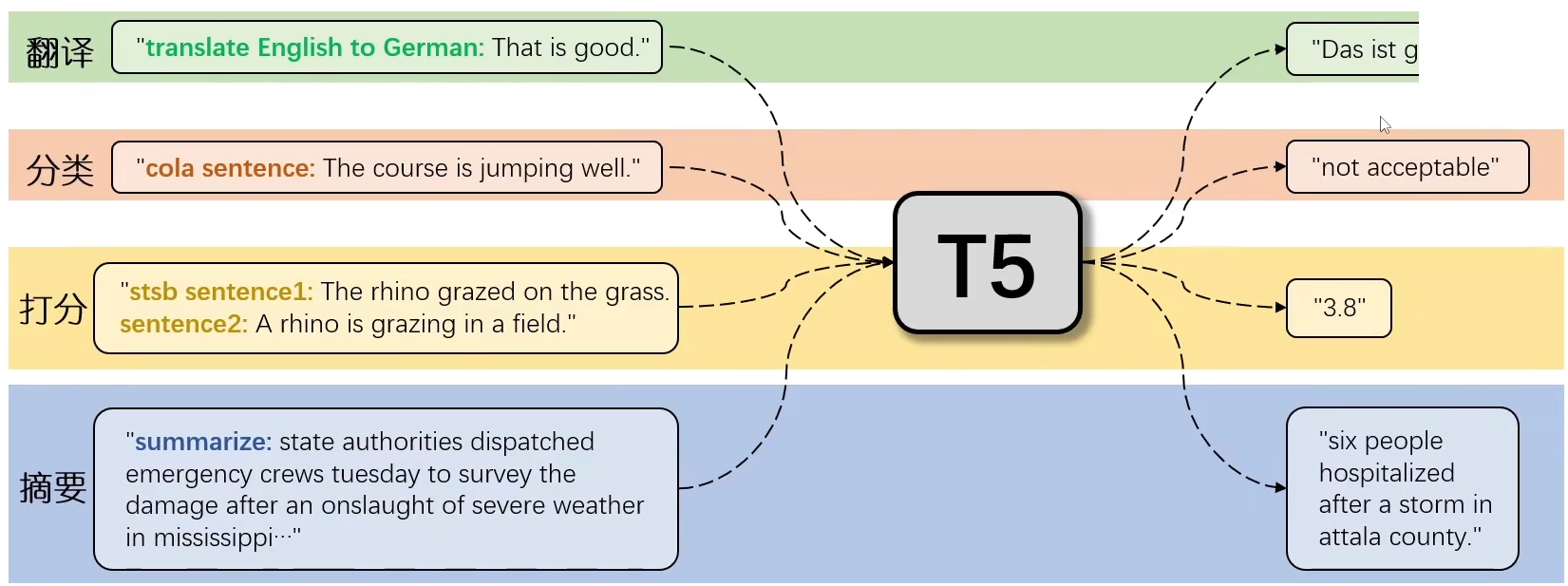
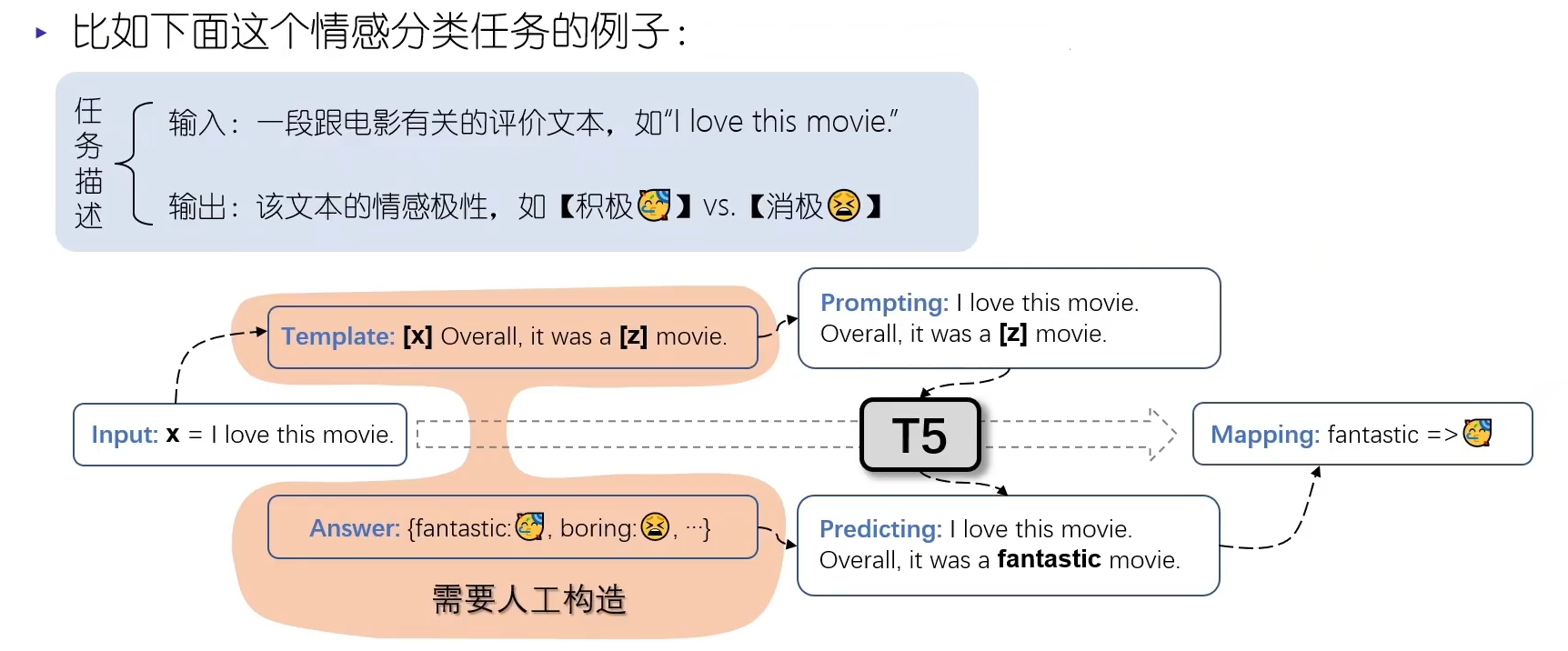
T5的预训练时,使用大规模预料数据进行text2text的预训练,得到训练好的encoder-decoder就具有了文本的理解和生成能力。而在应用于下游任务时不需要微调,结合具体 task 的 prompt template,将具体的任务转换为文本生成任务即可。
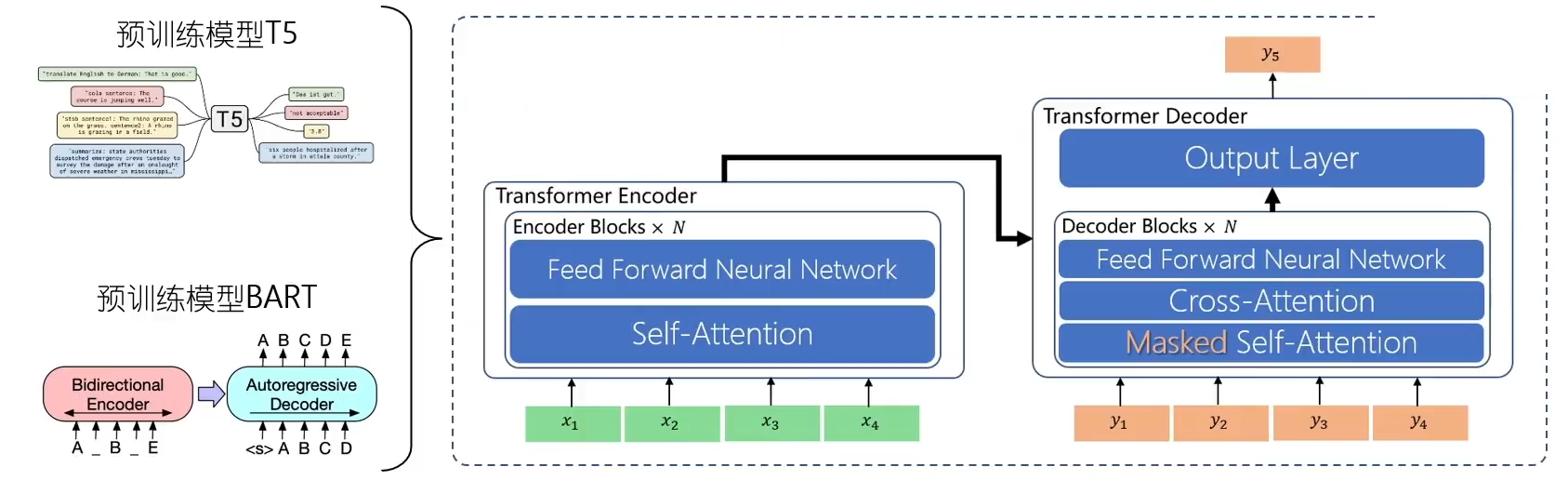
Encoder-Decoder架构预训练任务都是text2text,具体方式可以是各种各样的:
- 标准语言模型LM式(生成):
已知上半句,预测下半句。例如:Thank you for inviting|me to your party last week. - 掩码-预测MLM式(理解):
掩盖一部分词,还原被掩盖的词。例如:Thank you for<MASK>me to your party<MASK>week | Thank you for inviting me to your party last week. - 乱序还原式(理解):
将文本顺序打乱,还原正确的语序。例如:party me for your to.last you inviting week Thank|Thank you for inviting me to your party last week. - 带噪文本重构式(理解):
先对文本加噪(打乱单词、删除、填充...),再掩盖一部分单词,还原句子正确的语序和单词。是乱序还原式、掩码-预测MLM式的结合。
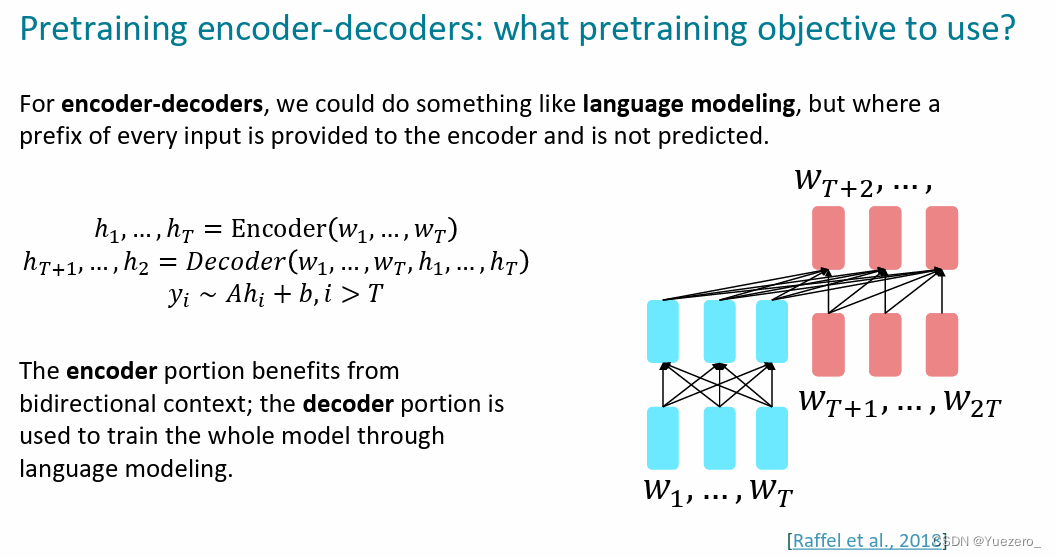
这种架构的LLM通常充分利用了上面2种类型的优势,采用新的技术和架构调整来优化表现。Encoder即能享受双向context理解输入的内容NLU,又能用Decoder处理并生成内容NLG,尤其擅长处理输入和输出序列之间存在复杂映射关系的任务,以及捕捉两个序列中元素之间关系至关重要的任务。
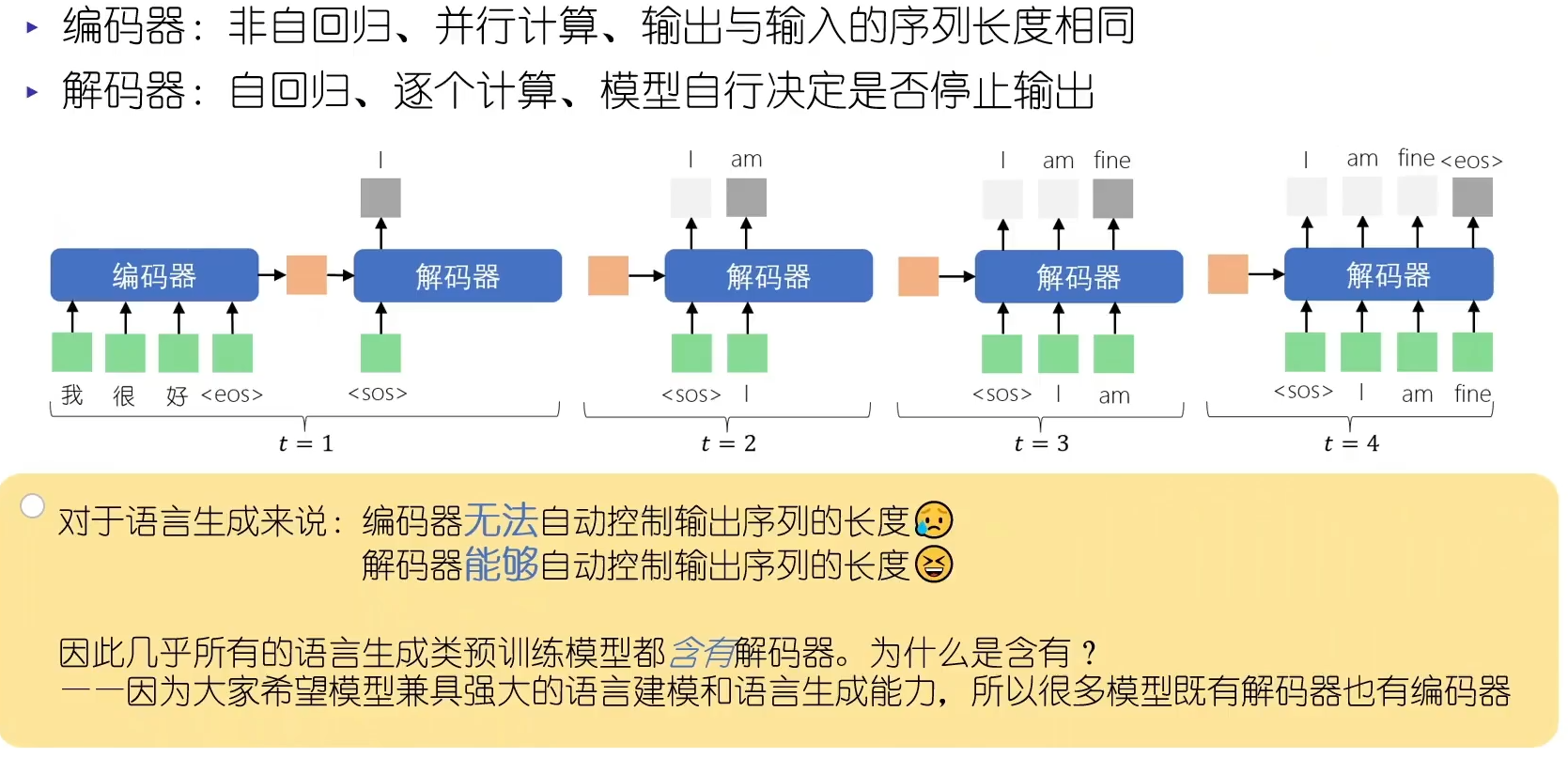
Transformer Decoder和Encoder的区别:Encoder是self-attention,Decoder是masked-self-attention和cross-attention。
- decoder第一个MHA变成masked-MHA,使用的是前文casual的attention mask的方式,这样每个当前输出token只能看到过去生成的token
- decoder新增第二个MHA,并且K和V来自于encoder的输出,这样就实现了看到原始输入的全文
至此我们可以梳理一下encoder-decoder的两种方式:
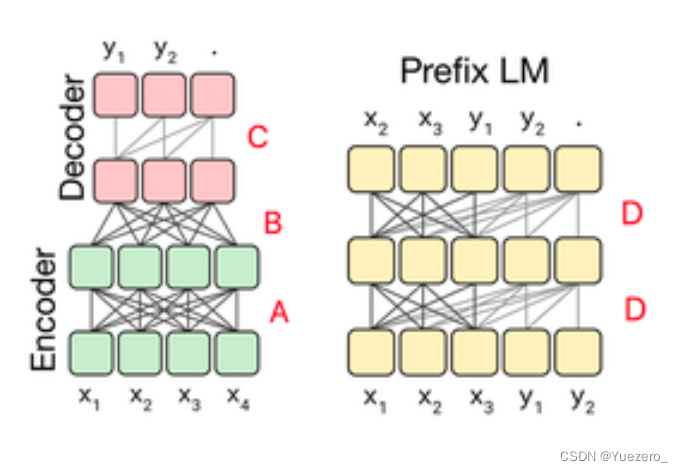
- 两者分离,标准的原始结构。其中A和B用的是fully-visible的attention mask,C是casusal的attention mask
- 两者融合,前半部分是fully-visible的,后半部分是casual的。其中D就是casual with prefix的attention mask。
为什么最新的LLMs主要都用Decoder-only架构,而不是Encoder-Decoder架构?
除了训练效率和工程实现上的优势外,在理论上是因为Encoder的双向注意力会存在低秩问题,这可能会削弱模型表达能力,就生成任务而言,引入双向注意力并无实质好外。而Encoder-Decoder架构之所以能够在某些场景下表现更好,大概只是因大它多了一倍参数。所以,在同等参数量、同等推理成本下,Decoder-only架构就是最优选择了。
Finetuning
经过预训练后的LLM(如GPT等Decoder-only),虽然可以使用prompt直接完成下游任务,但因为预训练数据无法完全适应某些具体任务的特征和要求,而且生成的text不能很好的对齐人类的prompt,还需要在高质量数据上进一步指令微调Finetuning。但其生成的内容是没有约束的,可能会生成与人类价值观不符的内容,所以还需要通过强化学习RLHF的方式不断优化训练。
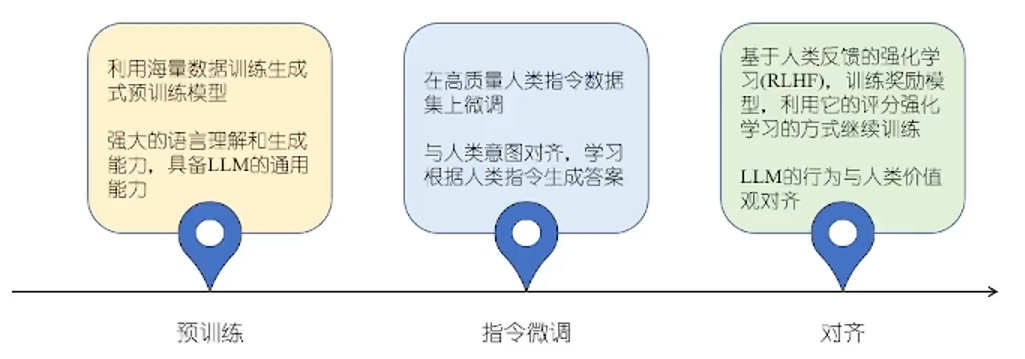
具体微调的方式:全参数微调、部分参数微调/高效参数微调PEFT(Parameter-Efficient Fine-Tuning :Adapter-Tuning、Prefix-Tuning、Prompt-Tuning、LORA等)
Adapter-Tuning微调额外添加到预训练模型中的小型网络层,这些适配器独立于模型的主体结构,如在self-attention和ffn直接插入adapter-layer。Prefix-Tuning在每个任务前增加前缀单词,比如翻译任务,可以在每句话的前面加上“翻译:”来引导模型进行翻译功能,即增加 Learnable 的 Prefix tokens embedding。更多地用于提供输入数据的直接上下文信息,这些前缀作为模型内部表示的一部分,可以影响整个模型的行为。Prompt-Tuning增加 Learnable 的 Prompt tokens embedding。被设计为引导模型针对特定任务生成特定类型的输出。这些向量通常被看作是任务指导信息的一部分,倾向于用更少量的向量模仿传统的自然语言提示。LORA:通过在模型的权重矩阵中引入低秩矩阵(通常是两个小的矩阵的乘积)来实现对模型的微调。这些低秩矩阵作为原有权重矩阵的修改项,使得原有的权重矩阵在实际计算时得到调整。

一文辨析清楚LORA、Prompt Tuning、P-Tuning、Adapter 、Prefix等大模型微调方法
Instruction-Tuning
预训练的LLM不能很好的理解 prompt中 task 的意思,Instruction-Tuning就是收集更加详细准确的 task instruct 扩充 prompt,对模型进行有监督微调,可以增强模型对 task 的理解能力。代表模型就是FLAN系列。

让我们先抛开脑子里的一切概念,把自己当成一个模型。我给你两个任务:
- 带女朋友去了一家餐厅,她吃的很开心,这家餐厅太__了!
- 判断这句话的情感:带女朋友去了一家餐厅,她吃的很开心。选项:A=好,B=一般,C=差
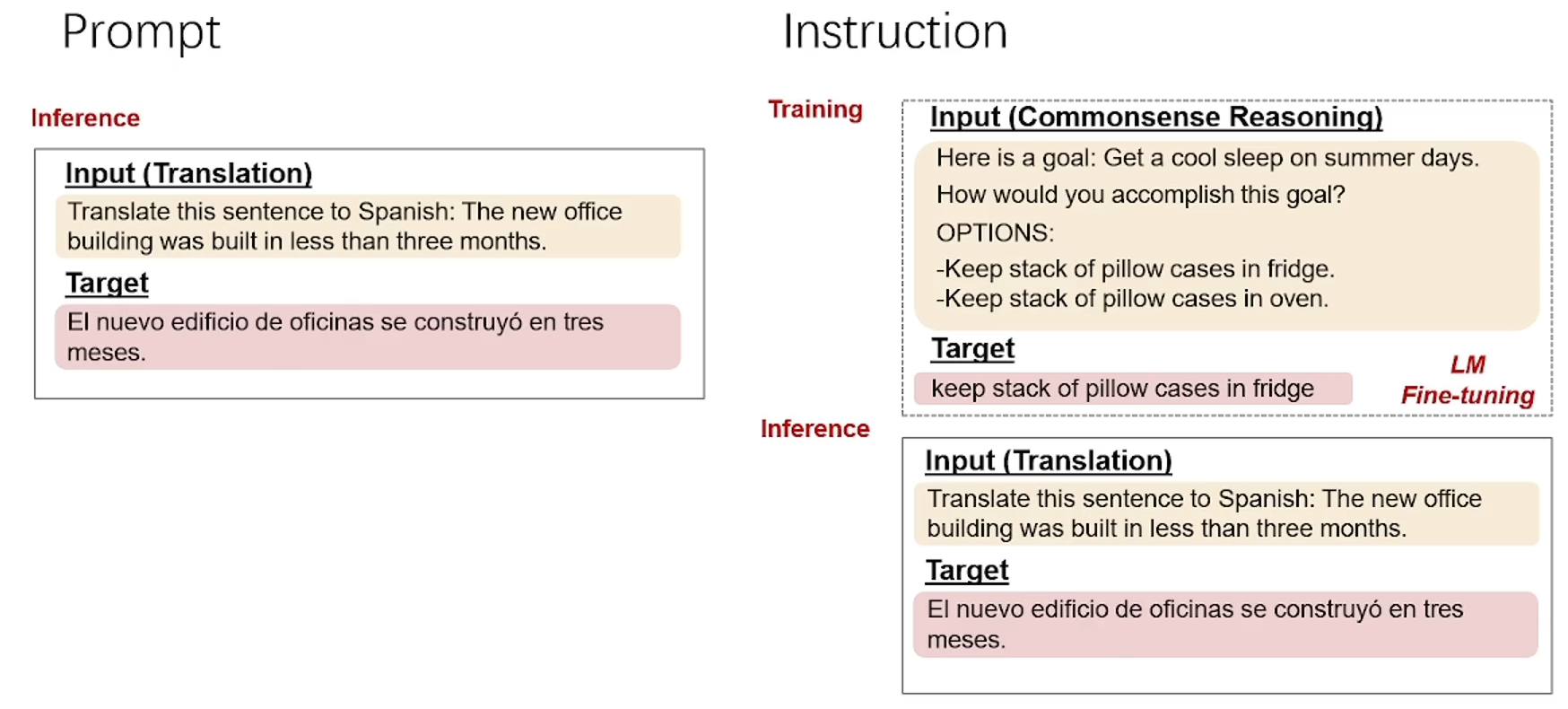
你觉得哪个任务简单?请把序号打在公屏上。做判别是不是比做生成要容易?Prompt就是第一种模式,Instruction就是第二种。
Instruction Tuning和Prompt的核心一样,就是去发掘语言模型本身具备的知识。而他们的不同点就在于,Prompt是去激发语言模型的补全能力,比如给出上半句生成下半句、或者做完形填空,都还是像在做language model任务,而Instruction Tuning则是激发语言模型的理解能力,通过给出更明显的指令+指示,让模型去理解并做出正确的action。

具体的 Instruction 训练数据包含3部分:Task Description(任务描述)、Demonstrations(例子,可选的)、Input&Output(问题和答案)。数据收集使用如下三种方式:NLP任务的数据集、人类手工构造、LLM辅助生成self-instruct。
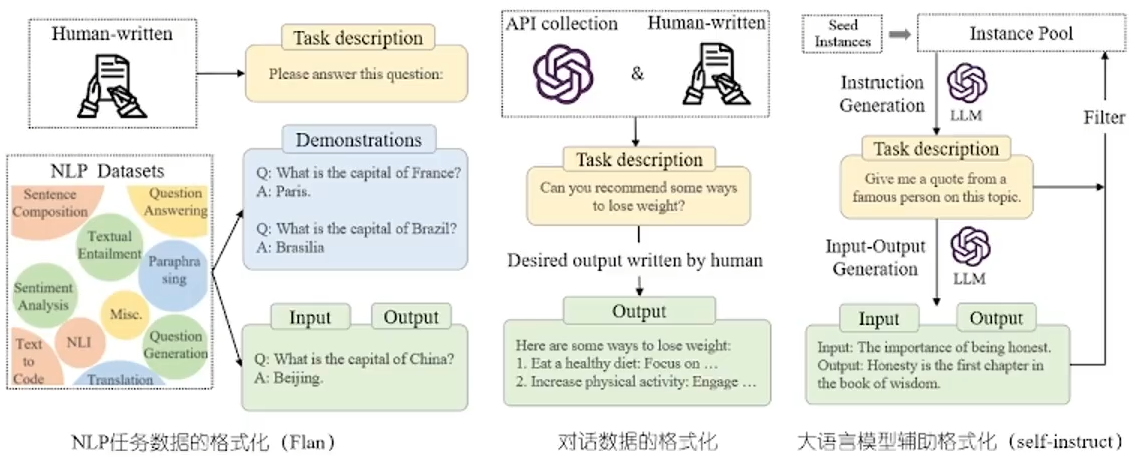

还有一个不同点,就是Prompt在没微调的模型上也能有一定效果,而Instruction Tuning则必须对模型微调,让模型知道这种指令模式,然后和Prompt一样进行推理,就能实现更好的性能。
但是,Prompt也有精调呀,经过Prompt tuning之后,模型也就学习到了这个Prompt模式,精调之后跟Instruction Tuning有啥区别呢?
这就是Instruction Tuning巧妙的地方了,Prompt tuning都是针对一个任务的,比如做个情感分析任务的prompt tuning,精调完的模型只能用于情感分析任务。而经过Instruction Tuning多任务精调后,可以用于其他任务的zero-shot !
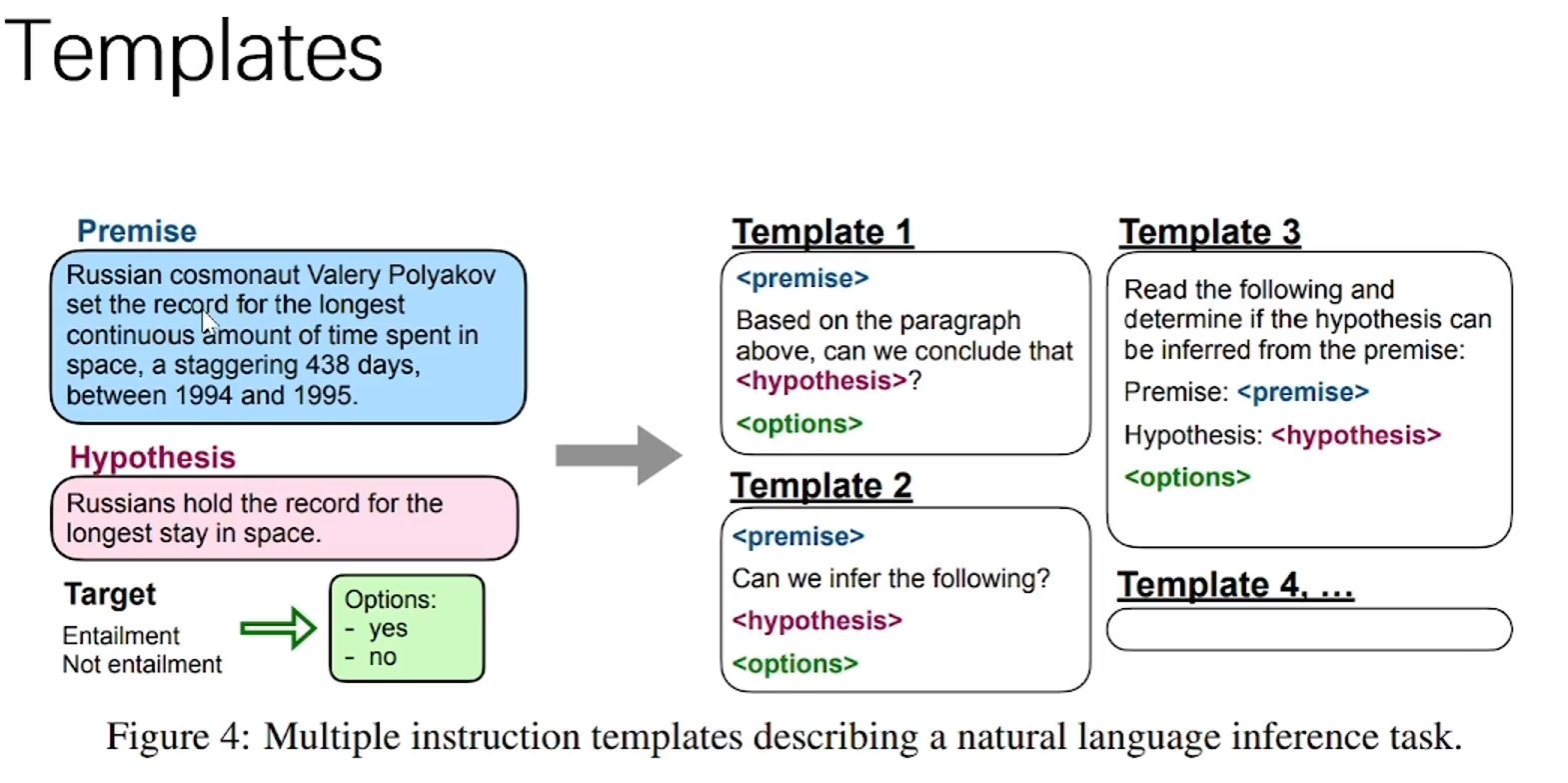
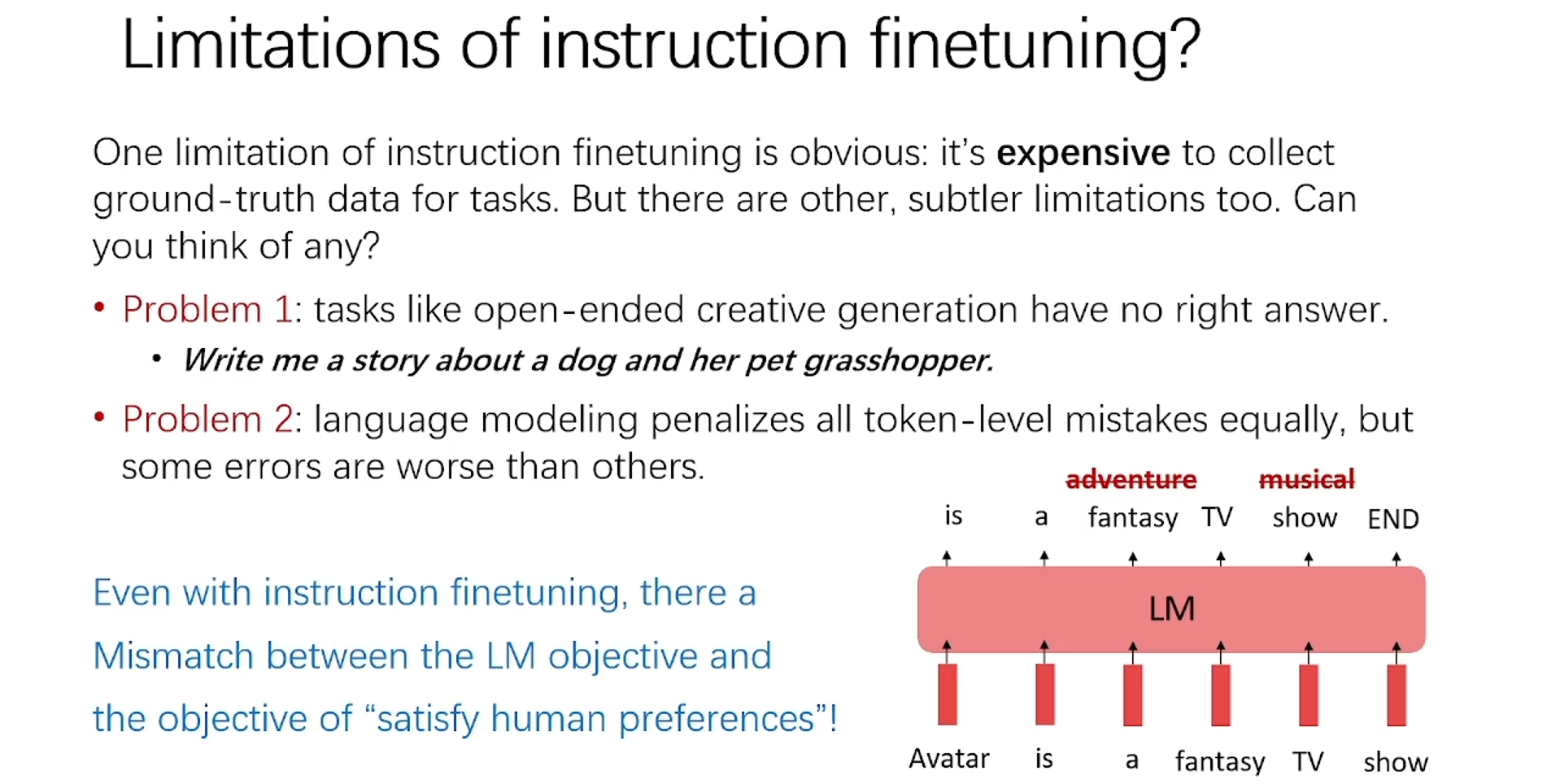
再往深想,Instruction和Prompt一样存在手工设计模版的问题,怎样把模版参数化、或者自动挖掘大量模版从而提升指令精调的效果,也是一个方向。同时,对于创造性的task用具体的instruction来描述可能会限制模型的创造性。对token-level的错误作同样的惩罚,这其实是LM的通病。
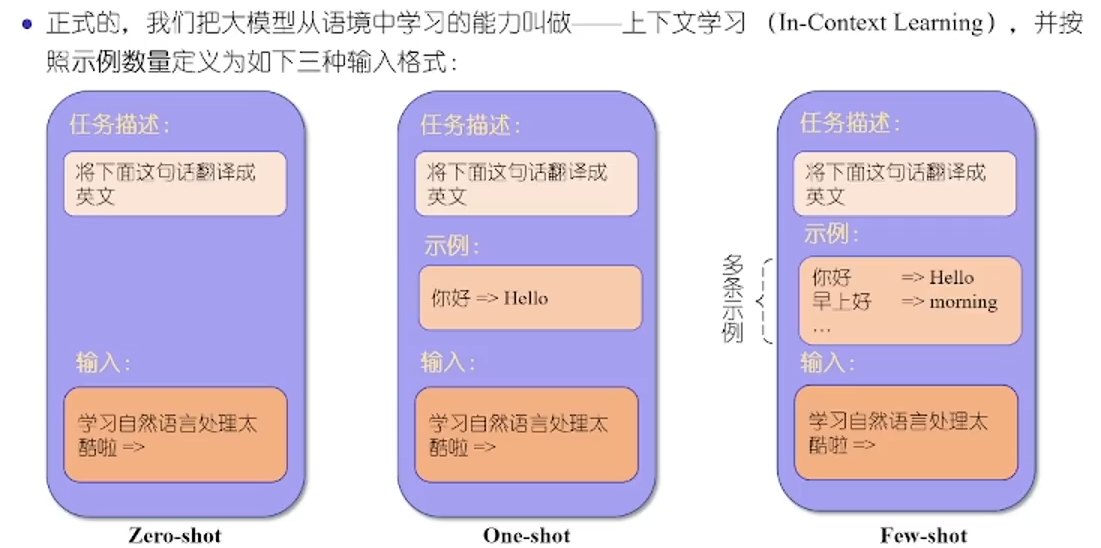
In-Context Learning
只用Prompt让LLM进行zero-shot生成答案时是没有限制的,可能会胡乱生成,如果能够给一些示例,让LLM模仿这些示例进行one/few-shot生成就会准确很多。因为Decoder-only LM的生成范式为
P
(
x
t
∣
x
<
t
)
P(x_t|x_{<t})
P(xt∣x<t),我们输入的prompt,就是
x
<
t
x_{<t}
x<t,其中包含的示例作为生成的先验。
除了直接提供最终答案的Q&A的示例,针对需要step-by-step解决的数学问题,我们可以使用Chain-of-Thoughts思维链(CoT)的方式,给出按step回答的Q&A示例,来启发LLM产生更好的结果。

除了CoT,Self-Consistency CoT取多次生成的结果中字数最多的作为答案;Tree-of-Thoughts(ToT)可以对每次的结果评估之后在树中搜索一种最优答案路径。
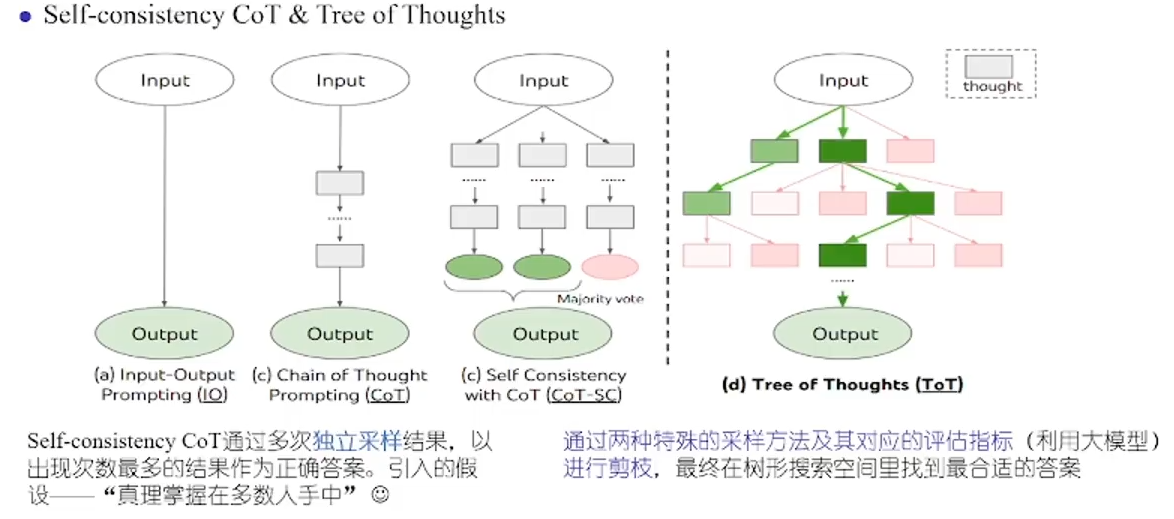
RLFH
基于人类反馈的强化学习 RLHF (Reinforcement Learning from Human Feedback) ,用来优化语言模型。
如果我们 用生成文本的人工反馈作为性能衡量标准,或者更进一步用该反馈作为损失来优化模型,那不是更好吗?这就是 RLHF 的思想:使用强化学习的方式直接优化带有人类反馈的语言模型。RLHF 使得在一般文本数据语料库上训练的语言模型能和复杂的人类价值观对齐,避免有害内容生成。
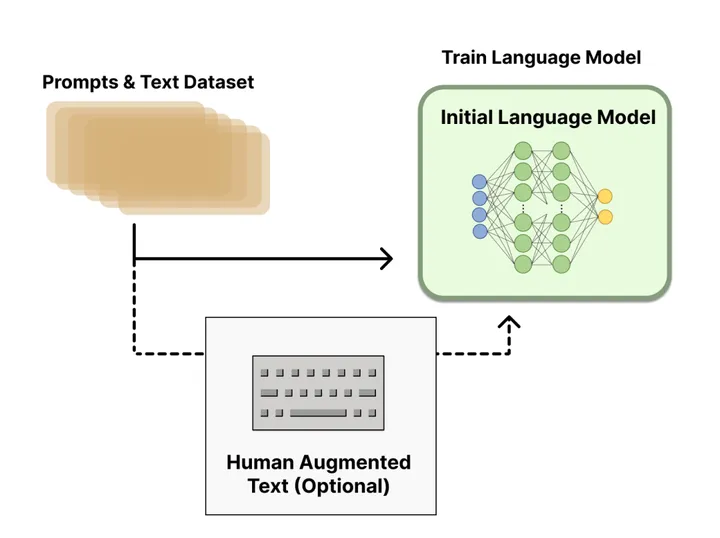
三个步骤分解:
- 预训练一个语言模型 (LM) ;
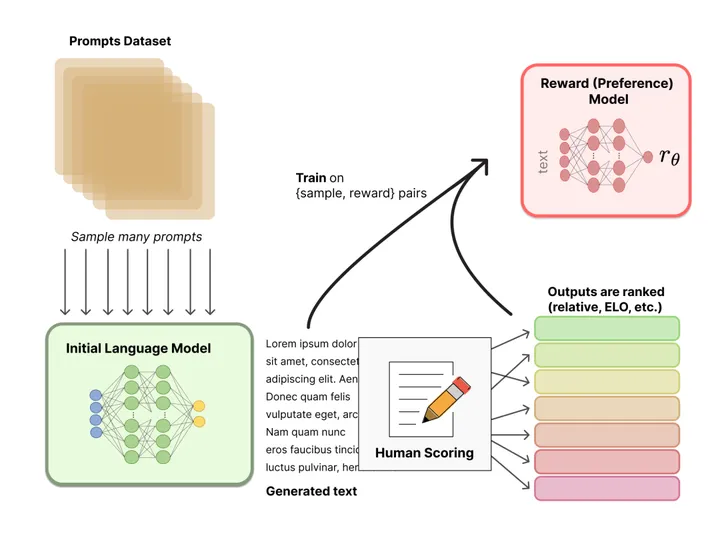
-
聚合问答数据,并训练一个奖励模型 (Reward Model,RM) ;
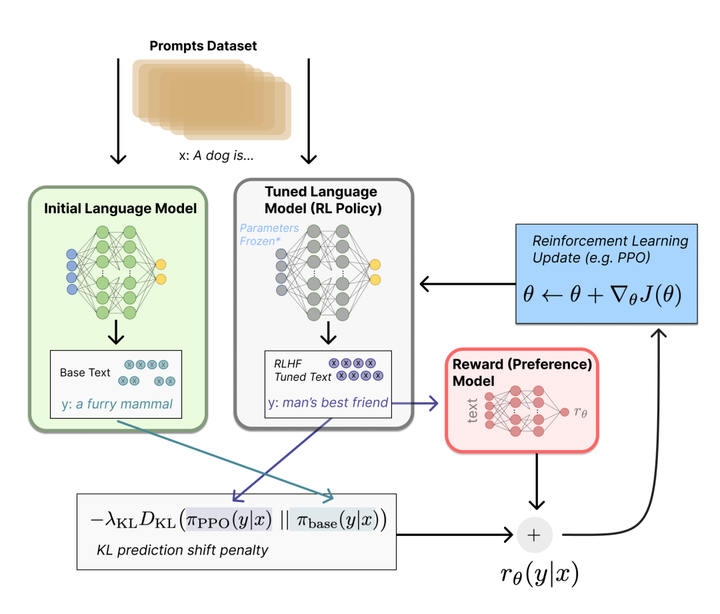
-
用强化学习 (RL) 方式微调 LM。

















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











