







非关系型数据库和关系型数据库
传统关系型数据库的缺陷
随着互联网Web 2.0的兴起,传统的关系数据库在应付Web 2.0网站,特别是超大规模和高并发的SNS类型动态网站时已经力不从心,暴露了很多难以克服的问题。
1)高并发读写的瓶颈
Web 2.0网站要根据用户个性化信息来实时生成动态页面和提供动态信息,所以基本上无法使用静态化技术,因此数据库并发负载非常高,可能峰值会达到每秒上万次读写请求。关系型数据库应付上万次SQL查询还勉强顶得住,但是应付上万次SQL写数据请求,硬盘I/O却无法承受。其实对于普通的BBS网站,往往也存在相对高并发写请求的需求,例如,人人网的实时统计在线用户状态,记录热门帖子的点击次数,投票计数等,这是一个相当普
遍的业务需求。
2)可扩展性的限制
在基于Web的架构中,数据库是最难以进行横向扩展的,当应用系统的用户量和访问量与日俱增时,数据库系统却无法像Web Server和App Server那样简单地通过添加更多的硬件和服务节点来扩展性能和负载能力。对于很多需要提供24小时不间断服务的网站来说,对数据库系统进行升级和扩展是非常痛苦的事情,往往需要停机维护和数据迁移,而不能通过横向添加节点的方式实现无缝扩展。
3)事务一致性的负面影响
事务执行的结果必须是使数据库从一个一致性状态变到另一个一致性状态。保证数据库一致性是指当事务完成 时,必须使所有数据都具有一致的状态。在关系型数据库中,所有的规则必须应用到事务的修改上,以便维护所有数据的完整性,这随之而来的是性能的大幅度下降。很多Web系统并不需要严格的数据库事务,对读一致性的要求很低,有些场合对写一致性要求也不高。因此数据库事务管理成了高负载下的一个沉重负担。
4)复杂SQL查询的弱化
任何大数据量的Web系统都非常忌讳几个大表间的关联查询,以及复杂的数据分析类型的SQL查询,特别是SNS类型的网站,从需求以及产品设计角度就避免了这种情况的产生。更多的情况往往只是单表的主键查询,以及单表的简单条件分页查询,SQL的功能被极大地弱化了,所以这部分功能不能得到充分发挥。
NoSQL数据库的优势
1)扩展性强
NoSQL数据库种类繁多,但是一个共同的特点就是去掉关系型数据库的关系特性,若数据之间是弱关系,则非常容易扩展。一般来说,NoSql数据库的数据结构都是Key-Value字典式存储结构。例如,HBase、Cassandra等系统的水平扩展性能非常优越,非常容易实现支撑数据从TB到PB级别的过渡。
2)并发性能好
NoSQL数据库具有非常良好的读写性能,尤其在大数据量下,同样表现优秀。当然这需要有优秀的数据结构和算法做支撑。
3)数据模型灵活
NoSQL无须事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系型数据库中,增删字段是一件非常麻烦的事情。对于数据量非常大的表,增加字段简直就是一场噩梦。NoSQL允许使用者随时随地添加字段,并且字段类型可以是任意格式。
总结
HBase作为NoSQL数据库的一种,当然也具备上面提到的种种优势。
Hadoop最适合的应用场景是离线批量处理数据,其离线分析的效率非常高,Hadoop针对数据的吞吐量做了大量优化,能在分钟级别处理TB级的数据,但是Hadoop不能做到低延迟的数据访问,所以一般的应用系统并不适合批量模式访问,更多的还是用户的随机访问,就类似访问关系型数据库中的某条记录一样。
比如Google这个搜索引擎,存储了海量的网页数据,当我们通过搜索引擎检索一个网页时,之所以Google能够快速的响应结果,核心的技术就是利用了BigTable,可以实现低延迟的数据访问。
HBase的列式存储的特性支撑它实时随机读取、基于KEY的特殊访问需求。当然,HBase还有不少新特性,其中不乏有趣的特性,在接下来的内容中将会详细介绍。
BigTable介绍
BigTable是Google设计的分布式数据存储系统,用来处理海量的数据的一种非关系型的数据库。
BigTable是非关系的数据库,是一个稀疏的、分布式的、持久化存储的多维度排序Map。Bigtable的设计目的是可靠的处理PB级别的数据,并且能够部署到上千台机器上。Bigtable已经实现了下面的几个目标:适用性广泛、可扩展、高性能和高可用性。Bigtable已经在超过60个Google的产品和项目上得到了应用,包括Google
Analytics、GoogleFinance、Orkut、Personalized Search、Writely和GoogleEarth。这些产品对Bigtable提出了迥异的
需求,有的需要高吞吐量的批处理,有的则需要及时响应,快速返回数据给最终用户。它们使用的Bigtable集群的配置也有很大的差异,有的集群只有几台服务器,而有的则需要上千台服务器、存储几百TB的数据。
Bigtable的用三维表来存储数据,分别是行键(row key)、列键(column key)和时间戳(timestamp),
本质上说,Bigtable是一个键值(key-value)映射。按作者的说法,Bigtable是一个稀疏的,分布式的,持久化的,多维的排序映射。可以用(row:string, column:string, time:int64)→string 来表示一条键值对记录。
HBase概述
1.HBase概述
基于Hadoop数据库工具
来源于Google三篇论文之一 BIGTABLE,APACHE做了开源的实现就是 HBASE 技术
是一种NoSQL的 非关系型数据库 不符合关系型数据库的范式适合存储半结构化非结构化的数据
适合存储稀疏的数据 空的数据不占用空间面向列(族)进行存储
提供实时的增删改查的能力 是一种真正的数据库产品
可以存储海量数据 性能非常优良可以实现上亿条记录的毫秒级别的查询但是不支持严格的事务控制 只能在行级别保证事务
是一个高可靠 高性能 面向列 可伸缩的分布式存储系统 利用hbase技术可以在廉价的PC上搭建起大规模结构化存储集群。
HBase利用HadoopHDFS作为其文件存储系统,利用Hadoop的MapReduce来处理HBase中的海量数据,利用Zookeeper作为协调工具。
2.HBase的逻辑结构
HBase使用表来存储数据 但是表的结构和特点和传统的关系型数据库有非常大的区别
行键 - RowKey
就相当于是HBase表中的主键,HBase中的所有的表都要有行键
HBase中的所有的数据都要按照行键的字典顺序排序后存储对HBase表中的数据的查询 只有三种方式:
根据指定行键查询
根据指定的行键范围查询全表扫描查询
列族(簇) - ColumnFamily
是HBase表中垂直方向保存数据的结构,列族是HBase表的元数据的一部分,需 要在定义HBase表时就指定好表具有哪些个列族,列族中可以包含一个或多个列
列- Column
HBase表中列族里可以包含一个或多个列,列并不是HBase表的元数据的一部 分,不需要在创建表时预先定义,而是可以在后续使用表时随时为表的列族动 态的增加列。
单元格和时间戳 - Cell TimeStamp
在HBase表中,水平方向的行 和 垂直方向的列 交汇 就得到了HBase中的一个存储单元,而在这个存储单元中,可以存储数据,并且可以保存数据的多个版 本,这些个版本之间通过时间戳来进行区分。
所以在HBase中 可以通过 行键 列族 列 时间戳 来确定一个最小的存储数据的单元,这个单元就称之为单元格 Cell。
单元格中的数据都以二进制形式存储,没有数据类型的区别。
HBase的安装配置
1.安装前提
JDK Hadoop Zookeeper
2.下载安装包
访问HBase官网下载安装包
http://hbase.apache.org/
要注意下载的版本必须和 JDK Hadoop的版本相匹配

3.HBase安装 - 单机模式
a.前提条件,安装jdk 和 hadoop,并配置了环境变量
b.解压安装包
1 tar -zxvf xxxxx.tar.gz
c.修改HBase的配置文件conf/hbase-site.xml
hbase.rootdir 这个选项指定了Hbase底层存储数据的磁盘位置,如果不配置默认在/tmp/hbase-[username],而/tmp是linux的临时目录,其中的数据随时有可能被清 空,所以必须修改
d.在单机模式下,此路径配置为磁盘路径,HBase将会基于普通的磁盘文件来进行工作,也即 不使用HDFS作为底层存储,优点是方便,缺点是底层数据不是分布式存储,性能和可靠性 没有保证,主要用作开发测试,不应用在生产环境下。
4.HBase安装 - 伪分布式
a.前提条件,安装jdk 和 hadoop,并配置了环境变量
b.解压安装包
tar -zxvf xxxxx.tar.gz
c.修改conf/hbase-env.sh修改JAVA_HOME
export JAVA_HOME=xxxx
d.修改hbase-site.xml
hbase.rootdir
file:///
hbase.rootdir:指定底层存储位置
在伪分布式模式下,底层使用HDFS存储数据,所以此处配置的是一个HDFS地址
dfs.replication:指定底层HDFS的副本存储数量
配置了副本数据,明确告知了HBase底层HDFS保存数据时的版本数量
e.此种模式下,HBase采用hdfs作为存储具有完整的功能,但是只有一个节点工作,没有性能 的提升,可以用作开发测试,不可用作生产环境下。
5.HBase安装 - 完全分布式
a.前提条件,安装jdk 和 hadoop,并配置了环境变量
b.解压安装包
tar -zxvf xxxxx.tar.gz
c.修改conf/hbase-env.sh修改JAVA_HOME
export JAVA_HOME=xxxx
d.修改hbase-site.xml


hbase.rootdir:指定底层存储位置dfs.replication:指定底层HDFS的副本存储数量hbase.cluster.distributed:是否开启集群模式
hbase.zookeeper.quorum:完全分布式模式下需要使用zk作为集群协调工具, 通过这个选项配置使用的zk
e.修改conf/hbase-env.sh
export HBASE_MANAGES_ZK false
hbase默认HBASE_MANAGES_ZK为true,则HBase会自动管理zk,当HBase启动时,会自 动去启动zk,在HBase关闭时,会自动关闭zk。
而在很多的场景下,zk不是转为HBase服务器,不希望HBase在关闭时连带着关闭zk,此 时需要 将此选项改为false
f.修改conf/regionservers文件 在其中配置所有hbase主机每个主机名独占一行
hbase启动或关闭时会按照该配置顺序启动或关闭对应主机中的HBase进程
g.将配置好的hbase拷贝到其他机器中

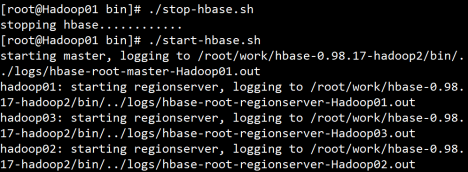
6.启动关闭管理Hbase
启动zookeeper
启动hadoop
启动hbase
start-hbase.sh
通过浏览器访问指定地址管理hbase:
http://xxxxx:60010
通过hbase shell脚本来访问hbase
hbase shell
启动备用master实现高可用
hbase-daemon.sh start master
关闭Hbase
stop-hbase.sh
HBase的shell命令行操作
1.HBase的shell操作
HBase提供了shell命令行工具,便于使用者通过命令操作Hbase
进入命令行:
hbase shell
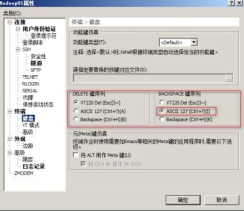
**在hbase shell中,发现无法通过删除键删除数据 必须ctrl+删除键 才可以,用起来很不便利,此时可以修改xshell的配置,解决此问题:
2.HBase的shell命令
a.help命令
查看帮助信息

b.general命令组
查看hbase当前状态

查看hbase的版本信息

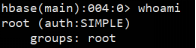
查看当前登录用户信息
c.ddl命令组
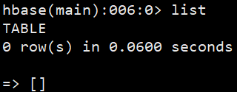
list 查看所有表
create 创建表
用来创建表,必须制定表明和列族的名称,列族至少要有一个,列族可以直接指定一个名字,或者可以通过一个至少包含NAME属性的字典来定义
创建指定名称空间指定表明的表:

创建默认名称空间default下的表

简写列族声明:

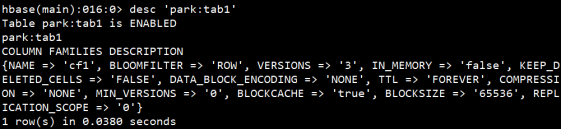
describe 查看表信息
查看表的基本信息,也可以简写为desc
disable禁用表禁用指定表
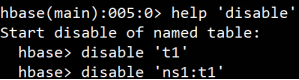
enable启用表
启用已经禁用的表
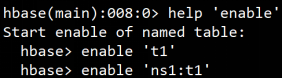
drop删除表
删除指定名称的表,表必须先禁用才可以删除

d.dml命令组
put新增数据、修改数据
存入指定的值到指定的表 行列和可选的时间戳确定的单元格中

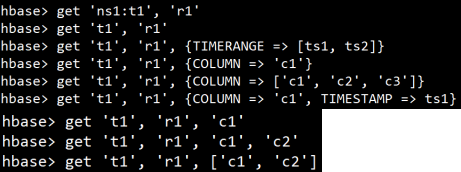
get获取数据
获取整行或指定单元格中的数据
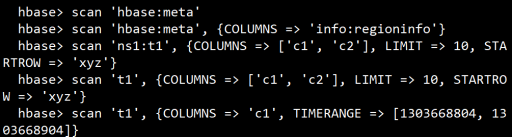
scan扫描表
扫描整表数据,可以直接扫描整张表,也可以带上参数实现高级扫描可选的参数包括:
TIMERANGE, FILTER, LIMIT, STARTROW, STOPROW, TIMESTAMP, MAXLENGTH, COLUMNS, CACHE ,RAW, VERSIONS
delete删除数据
删除指定单元格中的数据

truncate
摧毁并重建表,表中的数据经全部摧毁,可以实现删除全表数据的效果
e.名称空间相关操作
list_namespace列出所有名称空间列出所有的名称空间
create_namespace创建名名称空间创建指定名称的名称空间

list_namespace_tables列出指定名称空间中的所有表
列出指定名称空间中的所有表

drop_namespace删除指定名称的名称空间
删除指定名称的名称空间

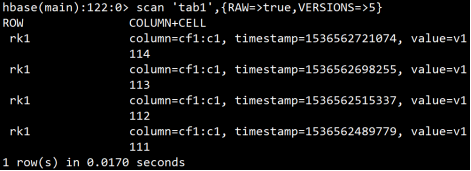
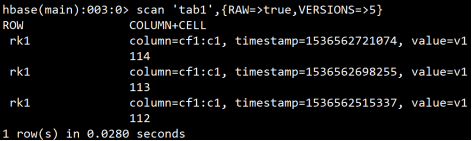
**实验:验证hbase表中可以存储数据的多个版本
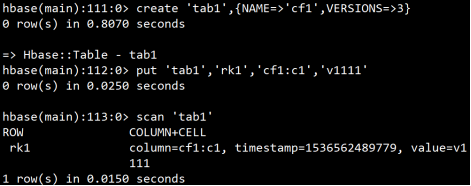
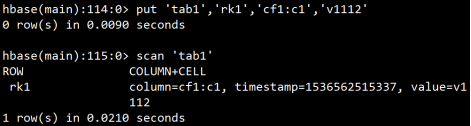
**注意:scan命令默认只查询最新版本的数据
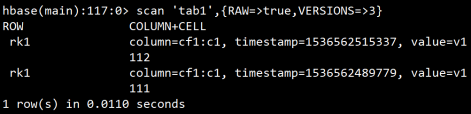

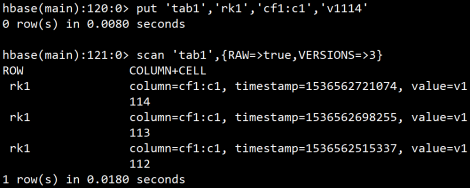
进一步实验,查询更多数量的版本,发现能够查询到大于之前定义的3个版本的 数据,这是hbase在内存中存在缓存,查询到的多出来的数据其实是在内存缓存中存在的,并不会真的持久化在HDFS存储中,只需重启hbase就会发现,此数据其实并不存在
HBase原理
1.在Hadoop生态圈中的位置

2.HRegion的分裂
HBase表中的数据按照行键的字典顺序进行排列
HBase表最初只有一个HRegion保存数据,随着数据写入,HRegion越来越大,达到一定的阈值后 会自动分裂为两个Hregion,随着这个过程不停的进行,HBase表中的数据会被划分为若干个HRegion进行管理
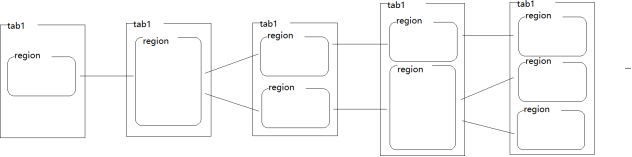
HRegion是HBase表中的数据分布式存储和负载均衡的基本单元
HBase表中的数据会以HRegion为单位分布式的存放在集群的HRegionServer服务器中,从而实现 分布式存储和负载均衡

3.HRegion内部结构
在Region内部存在复杂的结构,Region内部划分出若干个Store,有几个Store取决于HBase表有
几个列族,一个列族对应一个Store,在Store内部又有一个memStore和0个或若干个storeFile, 而storeFile本质上是存在于HDFS中的称为HFile的文件

4.HBase的写数据流程
当客户端联系HBase要写入一条数据时,根据表名和行键确定要操作的是哪个HRegion,找到存储 着该HRegion的HRegionServer,对该HRegion进行操作,根据要操作的列族确定要操作的store, 向该sotre中的memStore中写入当前数据,并在HLog中记录操作日志,之后返回表示写入成功。 写入过程基本是基于内存实现的,性能非常好。
问题1:内存满了怎么办
当不停的写入数据,将store中的memStore填满时,HBase会重新生成一个新的memStore继续 工作,而不再对旧的memStore写入数据,此时HBase会启动一个独立的线程,将旧的 memStore中的数据写入到HDFS中的一个新的HFile中,最终将数据持久化保存在了HDFS中。
在不停的产生HFile过程中,同一个Store的先后产生的多个HFile中可能存在对同一个数据 的多个不同的版本,其中旧的版本的数据很可能已经是失效的垃圾数据了,但是由于HDFS只 能一次写入多次读取不支持行级别的增删改,这些垃圾数据无法及时清理。最终造成浪费存 储空间,降低查询性能。
因此当HFile的数量达到一定的量,或达到一定的时间间隔,HBase将会触发HFile的合并操 作,将同一个Store的先后产生的多个HFile合并成一个HFile,在合并的过程中,会将垃圾 数据清理掉。而当不停的合并产生了达到一定大小的HFile后,HFile还会被拆分为若干个小 的HFile,防止HFile过大。
这个过程中看似先合并又拆分,小到大大到小,其实在这个过程集中,垃圾数据就被 清理掉了。
问题2:内存断电丢数据怎么办
在HBase的HRegionServer中存在名为HLog的日志文件,在向memStore写入数据时,数据需要 同时写入HLog中记录操作日志。
这个HLog文件本质上是存在于HDFS中的一个文件,通过对HDFS中的这个文件不停的追加数据 记录操作日志。
而在memStore满了溢写到HFile中完成后,HBase会将最后一条持久化到HFile中的日志的编 号记录到Zookeeper中redo point。
这样一旦断电丢失内存数据,只需要到Zookeeper中找到最后一条持久化的日志的编号,再 从HLog中将这个编号之后的数据恢复到内存中即可以找回所有的数据。
为了防止HLog文件过多,分摊写入性能,HBase中一个HRegionServer一个HLog,这个HRegionServer中的所有的HRegion的日志都会记在这同一个HLog文件中。

HBase的写可以认为是基于内存来实现的,速度非常的块,最终通过溢写到HFile中数据持久化高 可靠的保存在HDFS中,保证了数据可靠。
5.HFile的文件结构

一个StoreFile分为DataBlock MetaBlock FileInfo DataIndex MetaIndex Trailer
其中:
Data Blocks
保存表中的数据,这部分可以被压缩
DataBlocks中存放了大量的DataBlock,其中以键值对的形式保存着表中的数据,其中 键是行键,值是该行的某一个列的值,所以一个HBase表中的一个行可能在底层存在多键 值对保存
Meta Blocks (可选的)
保存用户自定义的kv对,可以被压缩。
File Info
Hfile的元信息,不被压缩,用户也可以在这一部分添加自己的元信息。
Data Block Index
Data Block的索引。Meta Block Index (可选的)
Meta Block的索引。
Trailer
这一段是定长的。保存了每一段的偏移量,读取一个HFile时,会首先 读取Trailer,
Trailer保存了每个段的起始位置
6.HBase的读数据流程
当客户端联系HBase表示要读取某一张表时,HBase根据表和行键确定出HRegion,找到存有该HRegion的HRegionServer,找到HRegion,根据要 查找的列族,确定出要查询的Store,首先在memStore中寻找要查询的数据,如果能查到,直接返回查询到的数据,查询结束。如果在 memStore中找不到要查询的数据,要查询该store对应的所有的storeFile,在这个过程中,解析storeFile,先读取storeFile中的Trailer块,找到DataBlockIndex,根据索引判断要找的数据在 当前storeFile中是否存在,如果不存在直接返回空 ,如果存在则根据索引快速找到对应的DataBlocks中的DataBlock返回。这样多个storeFile可能返回了多个DataBlock,其中包含着多 个版本的查询的数据结果,之后在内存中将这些DataBlock信息合并,得到最新的数据返回,完 成查询。
在理想的情况下,HBase的查询可以基于内存完成,效率很高,在最不理想的情况下,需要大量 的查询底层的HDFS文件,性能会有所下降,但是,由于这些storeFile都增加了索引,所以查询 的速度仍然是有保证的,但是仍然会比最理想的情况慢大概一个数量级。

7.HBase的HRegion寻址
在Hbase中存在一张特殊的hbase:meta表,其中存放着HBase的元数据信息,包括,HBase中有哪些表, 表中有哪些HRegion,每个HRegion分布在哪个HRegionServer中。
meta表很特殊,永远有且仅有一个HRegion,这个HRegion存放在某一个HRegionServer中,并且会 将这个持有meta表的Region的HRegionServer的地址存放在Zookeeper中meta-region-server节点下 下。
所以当在进行HBase表的读写操作时,需要先根据表名 和 行键确 定位到HRegion,这个过程就是HRegion的寻址过程。
HRgion的寻址过程首先由客户端开始,访问zookeeper 得到其中meta-region-server的值,根据该值找到meta表唯一的HRegion存储的HRegionServer,得到meta表唯一的HRegion,从中读取 真正要查询的表和行键 对应的HRgion的地址,再根据该地址,找到真正的操作的HRegionServer 和HRegion,完成HRgion的定位,继续读写操作.
客户端会缓存之前已经查找过的HRegion的地址信息,之后的HRgion定位中,如果能在本地缓存中的 找到地址,就直接使用该地址提升性能。

8.三种常见存储系统
a.hash存储
哈希存储引擎 是哈希表的持久化实现,支持增、删、改以及随机读取操作,但不支持顺序扫描,对应的存储系统为key-value存储系统。
对于key-value的插入以及查询,哈希表的复杂度都是O(1),明显比树的操作O(n)快,如果不 需要有序的遍历数据,哈希表就是最好的方案。
案例:HashMap
b.B树存储
B树存储引擎是B树的持久化实现,不仅支持单条记录的增、删、读、改操作,还支持顺序扫 描(B+树的叶子节点之间的指针)。
案例:MySql
c.LSM树存储
LSM树(Log-Structured Merge Tree)存储引擎和B树存储引擎一样,同样支持增、删、读、改、顺序扫描操作。而且通过批量存储技术规避磁盘随机写入问题。当然凡事有利有 弊,LSM树和B+树相比,LSM树牺牲了部分读性能,用来大幅提高写性能。
LSM树的设计思想非常朴素:将对数据的修改增量保持在内存中,达到指定的大小限制后将 这些修改操作批量写入磁盘,不过读取的时候稍微麻烦,需要合并磁盘中历史数据和内存中 最近修改操作,所以写入性能大大提升,读取时可能需要先看是否命中内存,否则需要访问 较多的磁盘文件。极端的说,基于LSM树实现的HBase的写性能比Mysql高了一个数量级, 读性能低了一个数量级。
案例:Hbase
9.Hbase的系统结构

HBase中的老大叫HMaster 小弟叫HRegionServer 客户端叫Client
Zookeepr为hbase提供集群协调
a.Client客户端
访问hbase 保留一些缓存信息提升效率
b.zookeeper
保证任何时候集群只有一个HMaster
监控regionServer的状态 将其上线下线信息通知mater
存储meta表Region的地址
存储hbase的元数据信息 包括 有哪些表 有哪些列族等等
c.HMater
为RegionServer分配Region
为RegionServer进行负载的均衡
GFS上的垃圾回收
处理对Schema数据的更新请求
d.HRegionServer
维护Master分配给它的region,处理对这些region的IO请求负责切分在运行过程中变得过大的region
10.HBase总结
为什么hbase可以很快:
内部有memStore做缓冲,读写都是有限基于内存实现的效率高
数据按照行键排序 查询效率高
数据从水平方向上切分为若干个HRegion 分布式是的存储 提高效率
为什么hbase可以存储很多数据:
数据最终存储到HDFS上,而HDFS是分布式的存储系统,可以动态扩容,基本可以认为容量没有限制 空的数据不占用空间,当数据比较稀疏时,不会浪费空间
hbase按列存储数据,而同一个列中的数据数据结构往往类似,可以实现高下率的数据压缩,节省空 间
为什么hbase的是可靠的:
数据最终存储在HDFS中,而HDFS自带多副本机制保证高可靠
存在多个HRegionServer,即使某些HRegionServer宕机,HBase也可以恢复数据到其他
HRegionServer继续工作
HMaster提供了备用机制,自动在HMaster 和 BackUpHMaster之间切换
hbase和hive和传统的关系型数据库的比较:
比起传统的关系型数据库,可以存储半结构化非结构化的数据,可以存储和处理更大级别的数 据,提供高效的查询,对于稀疏数据的处理更好,具有更好的横向扩展性,免费开源性价比很 高。但是不能支持非常好的事务特性,只支持行级的事务。只能通过行键来查询,表设计时难度 更高。而mysql用来存储结构化的数据提供更好的事务控制查询数据更加灵活。
比起hive,hive只是在mapreduce上包了一层壳,本质上还是离线数据的处理的工具,实时查询性 能有限,本质上是一个基于hadoop的数据仓库工具,不能支持行级别的新增修改和删除。hbase 可以提供实时的数据的处理能力,具有完整的增删改查的能力,本质上是一种数据库工具。
HBase的JavaAPI操作
1.创建项目,并导入相关开发包
将hbase安装包中lib下包导入java项目
2.相关API
a.HBaseConfiguration
关 系 :org.apache.hadoop.hbase.HBaseConfiguration 作用:对HBase进行配置
| 返回值 | 函数 | 描述 |
|---|---|---|
| void | addResource(Path file) | 通过给定的路径所指的文件来添加资源 |
| void | clear() | 清空所有已设置的属性 |
| string | get(String name) | 获取属性名对应的值 |
| String | getBoolean(String name, boolean defaultValue) | 获取为boolean类型的属性值,如果其属性值类型部位boolean,则返回默认属性 值 |
| void | set(String name, String value) | 通过属性名来设置值 |
| void | setBoolean(String name, boolean value) | 设置boolean类型的属性值 |
HBaseConfiguration conf = new HBaseConfiguration();
Configuration conf = HBaseConfiguration.create();
b.HBaseAdmin
关系:org.apache.hadoop.hbase.client.HBaseAdmin
作用:提供了一个接口来管理HBase数据库的表信息。它提供的方法包括:创建表,删除表,列出表项,使表有效或无效,以及添加或删 除表列族成员等。
| 返回值 | 函数 | 描述 |
|---|---|---|
| void | addColumn(String tableName, HColumnDescriptor column) | 向一个已经存在的表添加咧 |
| – | checkHBaseAvailable(HBaseConfiguration conf) | 静态函数,查看HBase是否处于运行状态 |
| – | createTable(HTableDescriptor desc) | 创建一个表,同步操作 |
| – | deleteTable(byte[] tableName) | 删除一个已经存在的表 |
| – | enableTable(byte[] tableName) | 使表处于有效状态 |
| – | disableTable(byte[] tableName) | 使表处于无效状态 |
| HTableDescriptor[] | listTables() | 列出所有用户控件表项 |
| void | modifyTable(byte[] tableName, HTableDescriptor htd) | 修改表的模式,是异步的操作,可能需要花费一定的时间 |
| boolean | tableExists(String tableName) | 检查表是否存在 |
HBaseAdmin admin = new HBaseAdmin(conf);
c.HTableDescriptor
关 系 :org.apache.hadoop.hbase.HTableDescriptor 作用:包含了表的名字极其对应表的列族
| 返回值 | 函数 | 描述 |
|---|---|---|
| void | addFamily(HColumnDescriptor) | 添加一个列族 |
| HColumnDescriptor | removeFamily(byte[] column) | 移除一个列族 |
| byte[] | getName() | 获取表的名字 |
| byte[] | getValue(byte[] key) | 获取属性的值 |
| void | setValue(String key, String value) | 设置属性的值 |
HTableDescriptor htd = new HTableDescriptor(table);
d.HTable
关系:org.apache.hadoop.hbase.client.HTable
作用:可以用来和HBase表直接通信。此方法对于更新操作来说是非线程安全的。

HTable tab = new HTable(conf, "tabx1");
e.Put
关 系 :org.apache.hadoop.hbase.client.Put 作用:用来对单个行执行添加操作

Put p = new Put(rk);
f.Get
关 系 :org.apache.hadoop.hbase.client.Get 作用:用来获取单个行的相关信息
Get g = new Get(Bytes.toBytes(row));
g.Result
关系:org.apache.hadoop.hbase.client.Result
作用:存储Get或者Scan操作后获取表的单行值。使用此类提供的方法可以直接获取值或者各种Map结构(key-value对)

3.HBase的JavaAPI操作
基本的增删改查

4.HBase的JavaAPI操作
全表扫描数据 范围扫描数据

5.HBase的JavaAPI操作 - 过滤器的使用
HBase中只能按照指定行键 行键范围 或 全表扫描来查询数据,而除此之外,HBase还提供了过滤器机制,可以在原有的查询结果的基础上 在服务器端实现进一步的过滤,返回符合过滤条件的数据
HBase支持自定义过滤器,但也同时提供了大量内置的过滤器,可以直接使用
a.RowFilter - 重要
行过滤器,可以筛选出匹配的所有的行

b.KeyOnlyFilter
这个过滤器唯一的功能就是只返回每行的行键,值全部为空,这对于只关注于行键的 应用场景来说非常合适,这样忽略掉其值就可以减少传递到客户端的数据量,能起到 一定的优化作用
Filter filter = new KeyOnlyFilter();

c.RandomRowFilter
本过滤器的作用就是按照一定的几率(<=0会过滤掉所有的行,>=1会包含所有的
行)来返回随机的结果集,对于同样的数据集,多次使用同一个RandomRowFilter会 返回不通的结果集,对于需要随机抽取一部分数据的应用场景,可以使用此过滤器
1 Filter filter = new RandomRowFilter(0.5f);
d.CloumnPrefixFiler
按照列名的前缀来筛选单元格的,如果我们想要对返回的列的前缀加以限制的话,可 以使用这个过滤器
Filter filter = new ColumnPrefixFilter("c2".getBytes());
e.ValueFilter - 重要
按照具体的值来筛选单元格的过滤器,这会把一行中值不能满足的单元格过滤掉
Filter filter = new ValueFilter(CompareOp.EQUAL, new RegexStringComparator("^v[^2].*2.*$"));
f.SingleColumnValueFilter - 重要
按照指定列的值 决定整行是否返回
Filter filter = new SingleColumnValueFilter("cf1".getBytes(), "c1".getBytes(), CompareOp.EQUAL, new RegexStringComparator("^[\\w&&[^2]]*$"));
g.Filter List - 重要
用于综合使用多个过滤器。其有两种关系:FilterList.Operator.MUST_PASS_ONE和FilterList.Operator.MUST_PASS_ALL,默认的是FilterList.Operator.MUST_PASS_ALL,顾名思义,它们分别是AND和OR的关系
Filter f1 = new KeyOnlyFilter();
Filter f2 = new RandomRowFilter(0.5f);
Filter flist = new FilterList(FilterList.Operator.MUST_PASS_ALL,f1,f2);
scan.setFilter(flist);
ResultScanner rs = tab.getScanner(scan);


HBase表设计
1.HBase表设计概述
HBase的表设计将会直接影响 HBase表使用的效率和 便利性 并且 HBase的表的结构一旦确立下来之后很难更改,所以HBase的表是需要设计的。
HBase中的表设计 主要包括 行键设计 和 列族设计。
2.HBase表中的列族设计
a.在设计HBase表时,列族不宜过多,越少越好,官方推荐不要超过3个
列族过多,会造成Hregion中Store的数量很多,造成memStore过多,耗费大量内存空间。
b.经常要一起查询的数据不要放在不同的列族中,尽量减少跨列族的数据访问
跨列族查询数据,意味着底层的查询过程,需要经历多个Store,浪费时间
c.如果真的要设计多个列族,要提前考虑好列族数据不均匀的问题
防止由于列族之间的数据量不均匀,造成在region分裂的过程中,某些region越切越小, 影响后续查询效率
3.HBase表中的行键的设计
hbase表中行键是唯一标识一个表中行的字段,所以行键设计的好不好将会直接影响未来对hbase的查询的性能和查询的便利性
行键设计的基本原则:
1)行键必须唯一
必须唯一才能唯一标识数据
2)行键必须有意义
这样才能方便数据的查询
3)行键最好是字符串类型
因为数值类型在不同的系统中处理的方式可能不同
4)行键最好具有固定的长度
不同长度的数据可能会造成自然排序时排序的结果和预期不一致
5)行键不宜过长
行键最多可以达到64KB,但是最好是在10~100字节之间,最好不要超过16字节,越 短越好,最好是8字节的整数倍。
行键设计的最佳实践:
1)散列原则:
行键的设计将会影响数据在hbase表中的排序方式,这会影响region切分后的结果,要 注意,在设计行键时应该让经常被查询的热点数据分散在不同的region中,防止某一 个或某几个regionserver成为热点。
2)有序原则:
行键的设计将会影响数据在hbase表中的排序方式,所以一种策略是通过设计行键将 将经常连续查询的数据排列在一起,这样一来可以方便批量查询
4.案例
行键的设计将会影响数据在hbase表中的排序方式,这会影响region切分后的结果,要 注意,在设计行键时应该让经常被查询的热点数据分散在不同的region中,防止某一 个或某几个regionserver成为热点。
2)有序原则:
行键的设计将会影响数据在hbase表中的排序方式,所以一种策略是通过设计行键将 将经常连续查询的数据排列在一起,这样一来可以方便批量查询

a.列族设计:
一个列族
b.行键设计:
i.唯一
rand
ii.有意义
rand time host age
iii.最好是字符串
“rand time host age”
iv.具有固定长度
“rand[28-8]_time[10]_host[5-25]_age[2]”
v.行键不宜过程
10<48<100 且是8的倍数
vi.散列原则 有序原则
“time[10]_host[5-25]_age[2]_rand[28-8]”
c.最终结果
















 1599
1599











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









