







Neural Networks: Representation
碎碎念:神经网络是11周的网课中最难理解的一节,没有之一。。。为了看懂这一节我打满了好几张草稿,被各种符号参数绕晕了一次又一次才终于理出了点头绪。不过凭良心讲,Ng讲的真的很浅显了,多研究几遍,还是能搞懂的。一定要耐心!课后练习一定得好好做!!
这一节会涉及到神经网络必备的基础知识,下一节再讲一些简单的应用。
相关机器学习概念:
1. 输入层(input layer)、隐藏层(hidden layer)、输出层(output layer)
2. 偏置单元(bias unit)
3. 激励(activation)、激励函数(activation function)
4. 权重(weight)
5. 前向传播算法(forward propagation)
一、复杂的非线性分类问题
在前面几节我们已经学习了线性回归和逻辑回归,为什么还要学习神经网络?
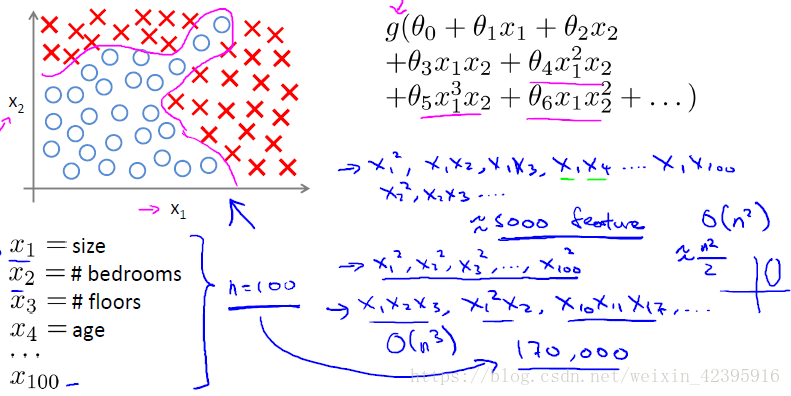
对于下图中n=100的非线性分类问题,如果想要包含所有的二次项,最终会得到5000(100^2/2)个二次项。随着特征个数n的增加,二次项的个数大约以
n2
n
2
的量级增长。因此要包含所有的二次项并不是一个好的方法,而且由于项数过多,最后的结果很可能是过拟合的。此外,在处理这么多项时,也存在运算量过大的问题。
当然,我们也可以减少二次项的个数,但由于忽略了太多相关项,在处理下图的非线性分类问题时不可能得到理想的结果。
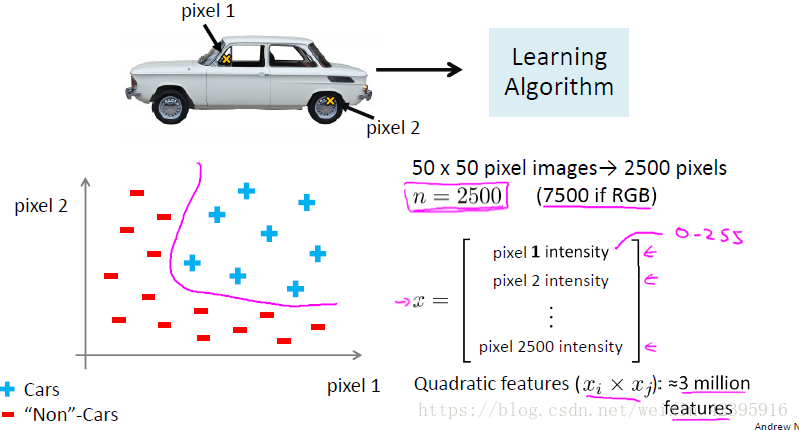
对于许多实际的机器学习问题,特征个数n是很大的。如计算机视觉中的汽车识别问题,对于我们来说这是一目了然的事情,但计算机看到的是一个数据矩阵,每个数字代表了图像中每个像素的亮度值。对于一张50*50像素的图片,计算机看到的就是一个50*50的亮度值矩阵。
为了让分类器识别出汽车,我们需要在训练样本中放入一些汽车图片和一些非汽车图片,从每幅图中挑出一组像素点,比如下面的pixel1和pixel2,接下来,我们可以在坐标系中将汽车样本用“+”,非汽车样本用“-”标注出来。这又是一个非线性分类问题。那么在实际中,这个分类问题特征空间的维度是多少?
假设我们用50*50像素的图片,这就是2500个像素点,如果计算机储存的是每个像素点的灰度值(介于0~255之间),特征向量的元素数量n=2500,而如果我们用的是RGB彩色图像,每个像素点包含红绿蓝三个子像素,那么n=7500。对于前一种情况,如果我们要包含所有的二次项,那么我们会得到大约300万个项,计算成本非常之高。
一句话总结,对于复杂的非线性分类问题,逻辑分类存在以下几个问题:
1、难以确定相关项
2、容易过拟合
3、计算成本高
而神经网络在解决复杂问题上是一种好得多的算法,即使特征维数n很大也能轻松搞定。
二、神经网络基础
(一)模型表示:术语解释
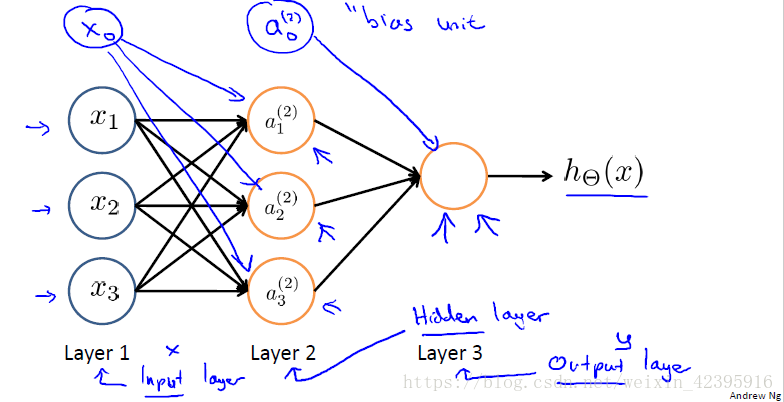
下图是一个三层的神经网络模型,第一层到第三层分别有3、3、1个节点。
第一层,也叫输入层(input layer),我们在这一层输入我们的特征项;
最后一层,也叫输出层(output layer),这一层会输出我们的分类结果;
任何介于输入层和输出层的层都被称作隐藏层(hidden layer),在下面这个模型中,第二层就是隐藏层。
在绘制神经网络时,有时还会在每一层增加一个额外的节点(下图中的 x0 x 0 , a(2)0 a 0 ( 2 ) ),它们被称为偏置单位(bias unit),或偏置神经元(bias neuron),它的值总是等于1,其作用和线性回归以及逻辑回归中的 x0 x 0 项是相同的。是否将偏置单位绘制出来取决于具体问题的方便。
神经网络在工作时,首先由输入层经过一系列非线性运算映射到隐藏层,以此类推,最终得到输出层结果。这个非线性函数,在神经网络中被称作激励函数(activation function),通常它就是我们之前学过的逻辑函数。神经模型的参数有时也被称为权重(weight)。
(二)模型表示:符号表示
sj
s
j
:第
j
j
层节点数
:第
j
j
层的第个神经元/单元输出的值,称作激励(activation)
Θ(j)
Θ
(
j
)
:参数/权重矩阵,它控制了从第
j
j
层各个单元到第各个单元的映射
Θ(j)
Θ
(
j
)
的维度为
sj+1×(sj+1)
s
j
+
1
×
(
s
j
+
1
)
。
下图中,从输入层的三个单元到隐藏层的三个单元的参数矩阵为
Θ(1)
Θ
(
1
)
,它是一个3x4的矩阵,因为第一层还有一个没有绘制出来的偏置单元。
Θ(1)10
Θ
10
(
1
)
表示映射到第二层第1个单元时,输入层偏置单元前的参数。

(三)模型表示:前向传播算法(forward propagation)的向量化表示
前向传播(forward propagation)是一种从输入层到隐藏层,再从隐藏层到输出层的过程,前向传播的角度有助于我们理解神经网络的原理。
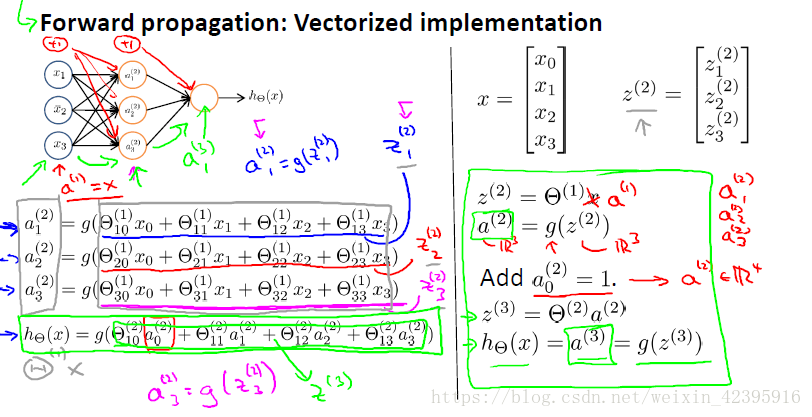
首先,从输入层到隐藏层。
Θ(1)
Θ
(
1
)
是一个3x4的矩阵,x是一个4x1的列向量,它代表了包含偏置单元在内的全体特征向量的特征值。为了符号表示的一致性,我们用
a(1)
a
(
1
)
替代x。定义额外项
z(2)=Θ(1)a(1)
z
(
2
)
=
Θ
(
1
)
a
(
1
)
,它是一个3x1的列向量,将其输入激励函数
g(z)
g
(
z
)
,即可得到隐藏层三个单元的激励值。
得到新的特征项
a(2)
a
(
2
)
后,我们把它作为新的输入,来计算输出层的激励。需要注意的是,我们需要人工加上偏置单元,使
a(2)
a
(
2
)
变为一个四维变量。接下来的计算步骤和前面相同。最后得到的
a(3)
a
(
3
)
就是模型的输出
hΘ(x)
h
Θ
(
x
)
,根据我们对逻辑函数的了解,我们知道这是一个介于0~1间的实数。
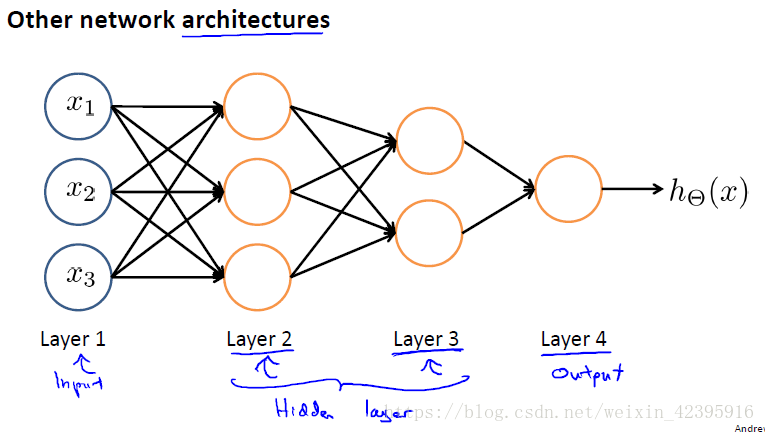
(四)模型表示:神经网络的其他架构
神经网络有多种架构,前面提到的是最简单的一种,它只有一层隐藏层。下面展示了一个四层的神经网络,它有两层隐藏层,其计算也会更加复杂。














 2208
2208











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









